







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Golang全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

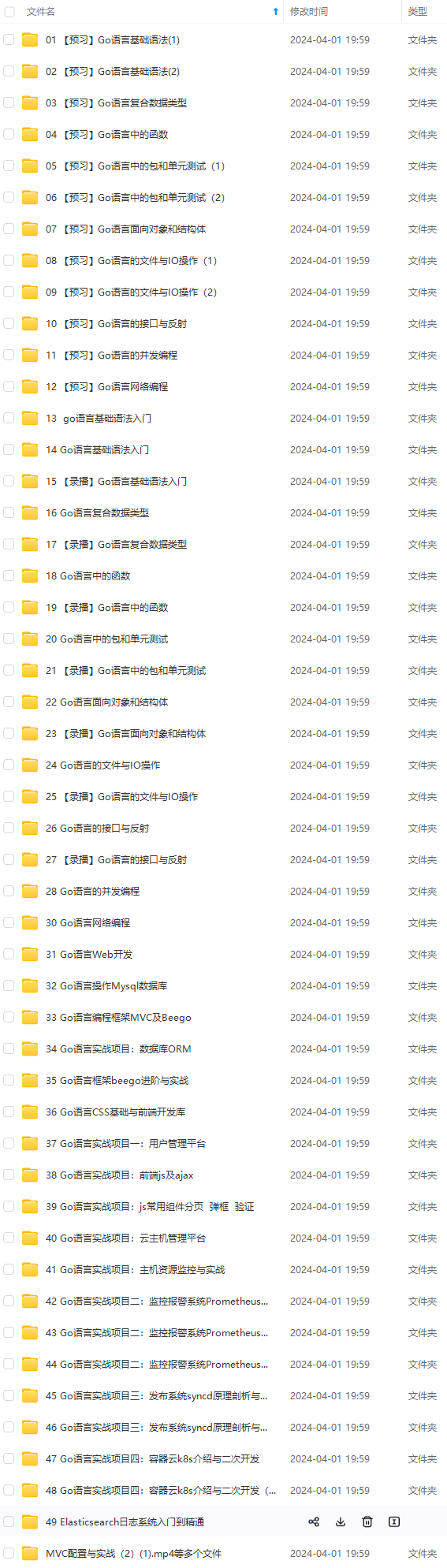
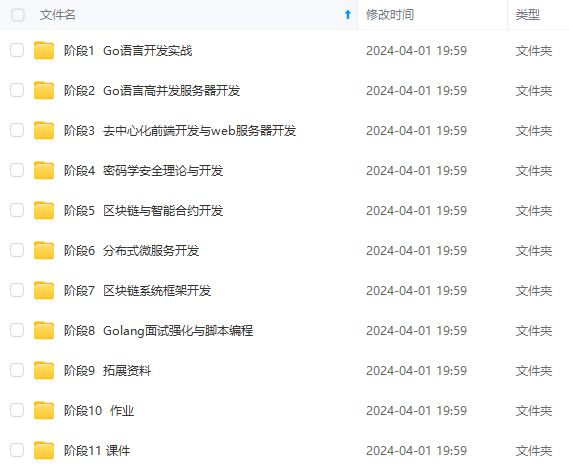
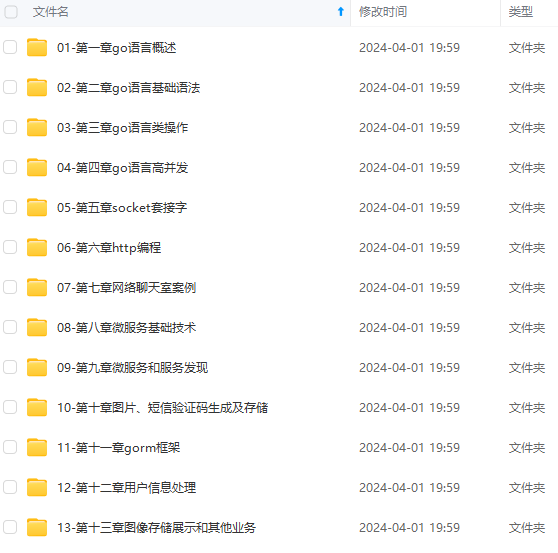
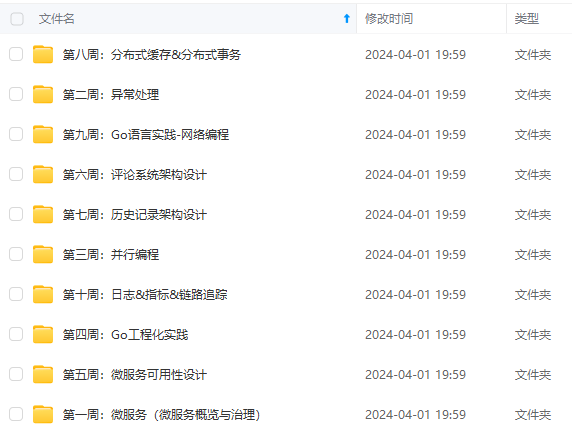
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注go)

正文
近年来,微服务已经成为一种非常流行的构建软件的方法。微服务用于构建可伸缩、灵活的软件。然而,跨多团队随机构建微服务可能会带来很大的挫折和复杂性。不久前我还没有听说过领域驱动设计——DDD,但现在无论走到哪里似乎每个人都在谈论它。
在本文,我将从头开始构建一个在线酒店应用来一步步地探索DDD的各种概念。希望每实现一部分,对理解DDD会更容易。采用这种方法的原因是,每次我在阅读DDD资料时都很头疼。有这么多的概念,很宽泛和不清楚,不清楚什么是什么。如果你不知道为什么我在研究DDD时头疼,下面的图可能会让你认识到这一点。

从上面的图片可以看得出来,为什么Eric Evans在他的《领域驱动设计:解决软件核心的复杂性》要用500页来解释什么是领域驱动设计。如果你对学习DDD有兴趣可以阅读本书。
首先,我想指出的是,本文描述了我对DDD的理解,我在本文中展示的实现是基于我对go相关项目的经验得出的最佳实践。我们将创建的实现绝不是社区所接受的最佳实践。我还将在项目中以DDD方法命名文件夹,以使其易于理解,但我不确定这是否是我想要的代码框架的样子。基于此,我将创建另一个分支来修正代码结构,这个重构将在其他文章解释。
我在网上看到很多关于DDD和如何正确实现的激烈讨论。让我印象深刻的是,多数时候人们似乎忘记了DDD背后的目的,都以讨论一些小的实现细节而告终。我认为重要的是遵循Evan提出的方法,而不是命名为X或Y。
DDD是一个很大的领域,我们将主要关注它的实现,但在我们实现任何东西之前,我将对DDD中的一些概念做一个快速的概述。
什么是DDD?
领域驱动设计是在软件所属领域之后对软件进行结构化和建模的一种方法。这意味着必须首先考虑所编写的软件的领域。领域是软件将处理的主题或问题。软件的编写应该反映该领域。
DDD主张工程团队必须与主题专家(SME)交谈,他们是领域内的专家。这样做的原因是SME拥有关于领域的知识,这些知识应该反映在软件中。想想看,如果我要做一个股票交易平台,作为一名工程师,我对这个领域的了解够不够去做一个好的股票交易平台?如果我能和沃伦·巴菲特谈谈这个领域,这个平台可能会好得多。
代码中的架构也应该反映领域。当我们开始编写我们的酒店应用时,我们将体会到领域内涵。
Gopher的DDD之路

让我们开始学习如何实现DDD,在开始之前我将给你讲述一个Gopher和Dante的故事,他们想创建一个在线酒店应用。Dante知道如何写代码,但是对如何运营一个酒店一无所知。
在Dante决定开始创建酒店应用的那天,他遇到了一个问题,从哪里开始,如何开始?他出去散步,思考这个问题。在公交站标志前等待的时候,一个戴大礼帽的男人走近Dante说:
“看起来你好像在担心什么事情,年轻人,需要帮忙建一个酒店应用吗?”
Dante和大礼帽男一起散步,他们讨论了酒店以及如何经营。Dante问如何处理酒徒(drinker),大礼帽男纠正说是客户(Customer)不是酒徒(drinker)。大礼帽男还向Dante解释了酒店还需要一些东西来运作,比如顾客、员工、银行和供应商。
领域、模型、统一语言和子领域
我希望你们喜欢Dante的故事,我写它是有原因的。我们可以用这个故事来解释DDD中使用的一些概念,这些词如果没有上下文很难解释,比如一个短篇故事。
Dante和大礼帽男已经讨论了一个领域模型会话。大礼帽男作为该方面的专家而Dante作为工程师讨论了领域空间并找到了共同点。这样做是为了学习模型,模型是处理领域所需组件的抽象。当Dante和大礼帽男在讨论酒店,他们正是在讨论相关领域。该领域是软件运行的关注点,我将把酒店(Tavern)称为核心/根领域。
大礼帽男还指出,它不叫饮酒徒,而叫顾客。这说明了在SMO和开发人员之间找到一种通用语言是多么重要。如果不是项目中的每个人都有通用语言,那将会非常令人困惑。我们还得到了一些子领域,这是大礼帽男提到的酒店应用所需要的东西。子领域是一个单独的领域,用于解决根领域内的相关东西。
使用Go编写一个DDD应用-Entities(实体)和Value Object(值对象)

我们已经了解了酒店应用的相关东西,是时候编写酒店系统代码了。通过创建go module来配制本项目。
mkdir ddd-go
go mod init github.com/percybolmer/ddd-go
我们将创建一个domain目录,存放所有的子领域,但在实现领域之前,我们需要在根目录下创建另一个目录。出于说明的目的,我们将其命名为entity,因为它将保存DDD方法中所谓的实体。一个实体是一个结构体包含标志符,其状态可能会变,改变状态的意思是实体的值可以改变。
首先我们将创建两个实体,Person和Item。我喜欢将实体保存在一个单独的包中,以便它们可以被所有其他领域使用。

为了保持代码整洁,我喜欢小文件,并使文件夹结构易于浏览。因此,我建议创建两个文件,每个文件对应一个实体,并以实体命名。现在,仅仅包含结构体定义,稍后会添加一些其他逻辑。
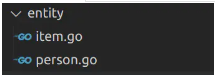
为领域创建第一个实体
//entities包保存所有子领域共享的所有实体
package entity
import (
“github.com/google/uuid”
)
// Person 在所有领域中代表人
type Person struct {
// ID是实体的标识符,该ID为所有子领域共享
ID uuid.UUID json:"id" bson:"id"
//Name就是人的名字
Name string json:"name" bson:"name"
// 人的年龄
Age int json:"age" name:"age"
}
package entity
import “github.com/google/uuid”
// Item表示所有子领域的Item
type Item struct {
ID uuid.UUID json:"id" bson:"id"
Name string json:"name" bson:"name"
Description string json:"description" bson:"description"
}
ok,现在我们已经定义了一些实体并了解了什么是实体。一个结构体具有唯一标识符来引用,状态可变。
有些结构体是不可变的,不需要唯一标识符,这些结构体被称为值对象。所以结构体在创建后没有标识符和持久化值。值对象通常位于领域内,用于描述该领域中的某些方面。我们现在将创建一个值对象,它是Transaction,一旦事务被执行,它就不能改变状态。
在真实的应用程序中,通过ID跟踪事务是一个好主意,这里只是为了演示
package valueobject
import (
“time”
)
// Transaction表示双方用于支付
type Transaction struct {
Amount int json:"amount" bson:"amount"
From uuid.UUID json:"from" bson:"from"
To uuid.UUID json:"to" bson:"to"
CreatedAt time.Time json:"createdAt" bson:"createdAt"
}
聚合(Aggregates)—组合实体(Entities)和值对象(Value Objects)
现在我们来看看DDD的下一个组件,聚合。聚合是一组实体和值对象的组合。因此,在本例中,我们可以首先创建一个新的聚合,即Customer。
DDD聚合是领域概念(例如订单、诊所访问、播放列表)——Martin Fowler
聚合(aggregate)的原因是业务逻辑将应用于Customer聚合,而不是每个持有该逻辑的实体。聚合不允许直接访问底层实体。在现实生活中,也经常需要多个实体来正确表示数据,例如Customer。它是一个Person,但是他/她可以持有Products并执行事务。
DDD聚合中的一个重要规则是,它们应该只有一个实体作为根实体。这意味着根实体的引用也用于引用聚合。对于我们的customer聚合,这意味着Person ID是惟一标识符。
让我们创建一个aggregate文件夹,然后在里面创建一个名为customer.go的文件。
mkdir aggregate
cd aggregate
touch customer.go
在该文件中,我们将添加一个名为Customer的新结构,它将包含表示Customer所需的所有实体。注意,所有字段都以大写字母开头,这在Go中使它们可以从包外部访问。这与我们所说的聚合不允许访问底层实体的说法相违背,但是我们需要它来使聚合可序列化。另一种方法是添加自定义序列化,但我发现有时跳过一些规则是有意义的。
// Package aggregates holds aggregates that combines many entities into a full object
package aggregate
import (
“github.com/percybolmer/ddd-go/entity”
“github.com/percybolmer/ddd-go/valueobject”
)
// Customer 聚合包含了代表一个客户所需的所有实体
type Customer struct {
// Person是客户的根实体
// person.ID是聚合的主标识符
Person *entity.Person bson:"person"
//一个客户可以持有许多产品
Products []*entity.Item bson:"products"
// 一个客户可以执行许多事务
Transactions []valueobject.Transaction bson:"transactions"
}
我将所有实体设置为指针,这是因为实体可以改变状态,我想让它反映在运行时所有访问它的实例中。值对象被保存为非指针,因为它们不能改变状态。
工厂函数-封装复杂的逻辑

到目前为止,我们只定义了不同的实体、值对象和聚合。现在开始实现一些实际业务逻辑,我们从工厂函数开始。工厂模式是一种设计模式,用于在创建所需实例的函数中封装复杂逻辑,调用者不知道任何实现细节。
工厂模式是一种非常常见的模式,您甚至可以在DDD应用程序之外使用它,而且您可能已经使用过很多次了。官方Go Elasticsearch客户端就是一个很好的例子。您将一个配置传入到NewClient函数中,该函数是一个工厂函数,返回客户端连接到弹性集群,可以插入/删除文档。对于其他开发人员来说很容易使用,在NewClient中做了很多事情:
func NewClient(cfg Config) (*Client, error) {
var addrs []string
if len(cfg.Addresses) == 0 && cfg.CloudID == “” {
addrs = addrsFromEnvironment()
} else {
if len(cfg.Addresses) > 0 && cfg.CloudID != “” {
return nil, errors.New(“cannot create client: both Addresses and CloudID are set”)
}
if cfg.CloudID != “” {
cloudAddr, err := addrFromCloudID(cfg.CloudID)
if err != nil {
return nil, fmt.Errorf(“cannot create client: cannot parse CloudID: %s”, err)
}
addrs = append(addrs, cloudAddr)
}
if len(cfg.Addresses) > 0 {
addrs = append(addrs, cfg.Addresses…)
}
}
urls, err := addrsToURLs(addrs)
if err != nil {
return nil, fmt.Errorf(“cannot create client: %s”, err)
}
if len(urls) == 0 {
u, _ := url.Parse(defaultURL) // errcheck exclude
urls = append(urls, u)
}
// TODO(karmi): Refactor
if urls[0].User != nil {
cfg.Username = urls[0].User.Username()
pw, _ := urls[0].User.Password()
cfg.Password = pw
}
tp, err := estransport.New(estransport.Config{
URLs: urls,
Username: cfg.Username,
Password: cfg.Password,
APIKey: cfg.APIKey,
ServiceToken: cfg.ServiceToken,
Header: cfg.Header,
CACert: cfg.CACert,
RetryOnStatus: cfg.RetryOnStatus,
DisableRetry: cfg.DisableRetry,
EnableRetryOnTimeout: cfg.EnableRetryOnTimeout,
MaxRetries: cfg.MaxRetries,
RetryBackoff: cfg.RetryBackoff,
CompressRequestBody: cfg.CompressRequestBody,
EnableMetrics: cfg.EnableMetrics,
EnableDebugLogger: cfg.EnableDebugLogger,
DisableMetaHeader: cfg.DisableMetaHeader,
DiscoverNodesInterval: cfg.DiscoverNodesInterval,
Transport: cfg.Transport,
Logger: cfg.Logger,
Selector: cfg.Selector,
ConnectionPoolFunc: cfg.ConnectionPoolFunc,
})
if err != nil {
return nil, fmt.Errorf(“error creating transport: %s”, err)
}
client := &Client{Transport: tp}
client.API = esapi.New(client)
if cfg.DiscoverNodesOnStart {
go client.DiscoverNodes()
}
return client, nil
}
DDD建议使用工厂来创建复杂的聚合、仓库和服务。我们将实现一个工厂函数,该函数将创建一个新的Customer实例。将创建一个名为NewCustomer的函数,它接受一个name参数,函数内部发生的事情不需要创建新customer的领域所知。
NewCustomer将验证输入是否包含创建Customer所需的所有参数:
在实际的应用程序中,我可能会建议在领域/客户中包含聚合的Customer和工厂。
package aggregate
import (
“errors”
“github.com/google/uuid”
“github.com/percybolmer/ddd-go/entity”
“github.com/percybolmer/ddd-go/valueobject”
)
var (
// 当person在newcustom工厂中无效时返回ErrInvalidPerson
ErrInvalidPerson = errors.New(“a customer has to have an valid person”)
)
type Customer struct {
// Person是客户的根实体
// person.ID是aggregate的主标志符
Person *entity.Person bson:"person"
// 一个客户可以持有许多产品
Products []*entity.Item bson:"products"
// 一个客户可以执行许多事务
Transactions []valueobject.Transaction bson:"transactions"
}
// NewCustomer是创建新的Customer聚合的工厂
// 它将验证名称是否为空
func NewCustomer(name string) (Customer, error) {
// 验证Name不是空的
if name == “” {
return Customer{}, ErrInvalidPerson
}
// 创建一个新person并生成ID
person := &entity.Person{
Name: name,
ID: uuid.New(),
}
// 创建一个customer对象并初始化所有的值以避免空指针异常
return Customer{
Person: person,
Products: make([]*entity.Item, 0),
Transactions: make([]valueobject.Transaction, 0),
}, nil
}
customer工厂函数现在帮助验证输入、创建新ID并确保正确初始化所有值。
现在我们已经有了一些业务逻辑,可以开始添加单元测试了。我将在aggregate包中创建一个customer_test.go,在其中测试与Customer相关的逻辑。
package aggregate_test
import (
“testing”
“github.com/percybolmer/ddd-go/aggregate”
)
func TestCustomer_NewCustomer(t *testing.T) {
// 构建我们需要的测试用例数据结构
type testCase struct {
test string
name string
expectedErr error
}
//创建新的测试用例
testCases := []testCase{
{
test: “Empty Name validation”,
name: “”,
expectedErr: aggregate.ErrInvalidPerson,
}, {
test: “Valid Name”,
name: “Percy Bolmer”,
expectedErr: nil,
},
}
for _, tc := range testCases {
// Run Tests
t.Run(tc.test, func(t *testing.T) {
//创建新的customer
_, err := aggregate.NewCustomer(tc.name)
//检查错误是否与预期的错误匹配
if err != tc.expectedErr {
t.Errorf(“Expected error %v, got %v”, tc.expectedErr, err)
}
})
}
}
我们不会在创造新customer方面深入,现在开始寻找我所知道的最佳设计模式的时候了。
仓库-仓库模式

DDD描述了应该使用仓库来存储和管理聚合。这是其中一种模式,一旦我学会了,我就知道我永远不会停止使用它。这种模式依赖于通过接口隐藏存储/数据库解决方案的实现。这允许我们定义一组必须使用的方法,如果它们被实现了,就可以被用作一个仓库。
这种设计模式的优点是,它允许我们在不破坏任何东西的情况下切换解决方案。我们可以在开发阶段使用内存存储,然后在生产阶段将其切换到MongoDB存储。它不仅有助于在不破坏任何利用仓库的东西的情况下更改所使用的底层技术,而且在测试中也非常有用。您可以简单地为单元测试等实现一个新的仓库。
我们将首先创建一个名为repository的文件。进入domain/customer包。在该文件中,我们将定义仓库所需的函数。我们需要Get、Add和Update函数处理customers。我们不会删除任何客户,一旦有客户在酒店,就永远是客户。我们还将在客户包中实现一些通用错误,不同的仓库实现可以使用这些错误。
// Customer包保存了客户领域的所有域逻辑
import (
“github.com/google/uuid”
“github.com/percybolmer/ddd-go/aggregate”
)
var (
// 当没有找到客户时返回ErrCustomerNotFound。
ErrCustomerNotFound = errors.New(“the customer was not found in the repository”)
// ErrFailedToAddCustomer在无法将客户添加到存储库时返回。
ErrFailedToAddCustomer = errors.New(“failed to add the customer to the repository”)
// 当无法在存储库中更新客户时,将返回ErrUpdateCustomer。
ErrUpdateCustomer = errors.New(“failed to update the customer in the repository”)
)
// CustomerRepository是一个接口,它定义了围绕客户仓库的规则
// 必须实现的函数
type CustomerRepository interface {
Get(uuid.UUID) (aggregate.Customer, error)
Add(aggregate.Customer) error
Update(aggregate.Customer) error
}
接下来,我们需要实现接口的实际业务逻辑,我们将从内存存储方式开始。在本文的最后,我们将了解如何在不破坏其他任何东西的情况下将其更改为MongoDB存储方案。
我喜欢将每个实现保存在它的目录中,只是为了让团队中的新开发人员更容易找到正确的代码位置。让我们创建一个名为memory的文件夹,表示仓库将内存用作存储。
另一种方式是在customer包中创建memory.go, 但我发现在更大的系统中,它会很快变得混乱
mkdir memory
touch memory/memory.go
让我们首先在memory.go文件中设置正确的结构,我们希望创建一个具有实现CustomerRepository接口的结构,并且不要忘记创建新仓库的工厂函数。
// memory包是客户仓库的内存中实现
package memory
import (
“sync”
“github.com/google/uuid”
“github.com/percybolmer/ddd-go/aggregate”
)
// MemoryRepository实现了CustomerRepository接口
type MemoryRepository struct {
customers map[uuid.UUID]aggregate.Customer
sync.Mutex
}
// New是一个工厂函数,用于生成新的客户仓库
func New() *MemoryRepository {
return &MemoryRepository{
customers: make(map[uuid.UUID]aggregate.Customer),
}
}
// Get根据ID查找Customer
func (mr *MemoryRepository) Get(uuid.UUID) (aggregate.Customer, error) {
return aggregate.Customer{}, nil
}
// Add将向存储库添加一个新Customer
func (mr *MemoryRepository) Add(aggregate.Customer) error {
return nil
}
// Update将用新的客户信息替换现有的Customer信息
func (mr *MemoryRepository) Update(aggregate.Customer) error {
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
)
// MemoryRepository实现了CustomerRepository接口
type MemoryRepository struct {
customers map[uuid.UUID]aggregate.Customer
sync.Mutex
}
// New是一个工厂函数,用于生成新的客户仓库
func New() *MemoryRepository {
return &MemoryRepository{
customers: make(map[uuid.UUID]aggregate.Customer),
}
}
// Get根据ID查找Customer
func (mr *MemoryRepository) Get(uuid.UUID) (aggregate.Customer, error) {
return aggregate.Customer{}, nil
}
// Add将向存储库添加一个新Customer
func (mr *MemoryRepository) Add(aggregate.Customer) error {
return nil
}
// Update将用新的客户信息替换现有的Customer信息
func (mr *MemoryRepository) Update(aggregate.Customer) error {
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)
[外链图片转存中…(img-33EsBjlo-1713316194902)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 905
905











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









