







还有兄弟不知道网络安全面试可以提前刷题吗?费时一周整理的160+网络安全面试题,金九银十,做网络安全面试里的显眼包!
王岚嵚工程师面试题(附答案),只能帮兄弟们到这儿了!如果你能答对70%,找一个安全工作,问题不大。
对于有1-3年工作经验,想要跳槽的朋友来说,也是很好的温习资料!
【完整版领取方式在文末!!】
93道网络安全面试题



内容实在太多,不一一截图了
黑客学习资源推荐
最后给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
😝朋友们如果有需要的话,可以联系领取~
1️⃣零基础入门
① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:

2️⃣视频配套工具&国内外网安书籍、文档
① 工具

② 视频

③ 书籍

资源较为敏感,未展示全面,需要的最下面获取


② 简历模板

因篇幅有限,资料较为敏感仅展示部分资料,添加上方即可获取👆
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
num_classes = 1000,
t2t_layers = ((7, 4), (3, 2), (3, 2)) # tuples of the kernel size and stride of each consecutive layers of the initial token to token module
)
img = torch.randn(1, 3, 224, 224)
preds = v(img) # (1, 1000)
## CCT
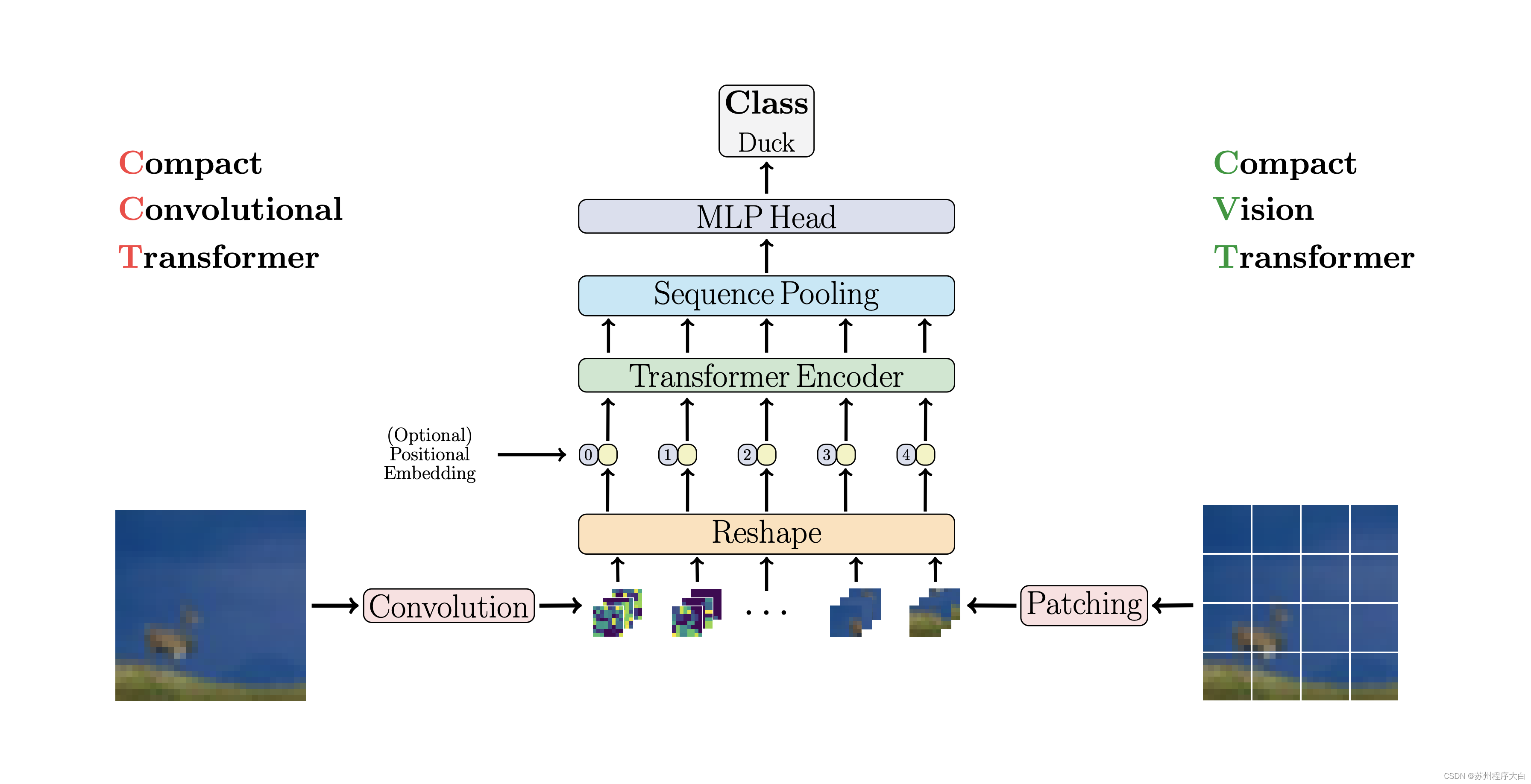
CCT通过使用卷积而不是修补和执行序列池来提出紧凑型转换器。这使得 CCT 具有高精度和少量参数。
您可以通过两种方法使用它:
import torch
from vit_pytorch.cct import CCT
model = CCT(
img_size=224,
embedding_dim=384,
n_conv_layers=2,
kernel_size=7,
stride=2,
padding=3,
pooling_kernel_size=3,
pooling_stride=2,
pooling_padding=1,
num_layers=14,
num_heads=6,
mlp_radio=3.,
num_classes=1000,
positional_embedding=‘learnable’, # [‘sine’, ‘learnable’, ‘none’]
)
或者,您可以使用多个预定义模型之一,这些模型`[2,4,6,7,8,14,16]` 预定义了层数、注意力头数、mlp 比率和嵌入维度。
import torch
from vit_pytorch.cct import cct_14
model = cct_14(
img_size=224,
n_conv_layers=1,
kernel_size=7,
stride=2,
padding=3,
pooling_kernel_size=3,
pooling_stride=2,
pooling_padding=1,
num_classes=1000,
positional_embedding=‘learnable’, # [‘sine’, ‘learnable’, ‘none’]
)
[官方存储库](https://bbs.csdn.net/topics/618540462)包括到经过训练的模型检查点的链接。
## 交叉 ViT
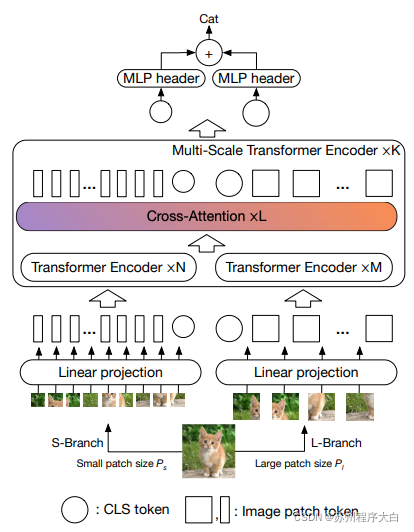
[本文](https://bbs.csdn.net/topics/618540462)建议让两个视觉转换器处理不同尺度的图像,每隔一段时间交叉处理一个。他们展示了在基础视觉转换器之上的改进。
import torch
from vit_pytorch.cross_vit import CrossViT
v = CrossViT(
image_size = 256,
num_classes = 1000,
depth = 4, # number of multi-scale encoding blocks
sm_dim = 192, # high res dimension
sm_patch_size = 16, # high res patch size (should be smaller than lg_patch_size)
sm_enc_depth = 2, # high res depth
sm_enc_heads = 8, # high res heads
sm_enc_mlp_dim = 2048, # high res feedforward dimension
lg_dim = 384, # low res dimension
lg_patch_size = 64, # low res patch size
lg_enc_depth = 3, # low res depth
lg_enc_heads = 8, # low res heads
lg_enc_mlp_dim = 2048, # low res feedforward dimensions
cross_attn_depth = 2, # cross attention rounds
cross_attn_heads = 8, # cross attention heads
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
pred = v(img) # (1, 1000)
## PiT
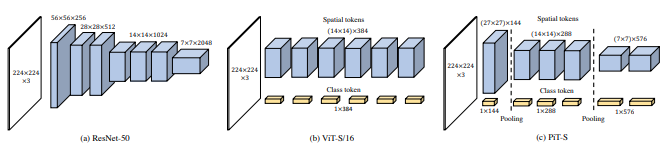
[本文](https://bbs.csdn.net/topics/618540462)建议通过使用深度卷积的池化过程对令牌进行下采样。
import torch
from vit_pytorch.pit import PiT
v = PiT(
image_size = 224,
patch_size = 14,
dim = 256,
num_classes = 1000,
depth = (3, 3, 3), # list of depths, indicating the number of rounds of each stage before a downsample
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
forward pass now returns predictions and the attention maps
img = torch.randn(1, 3, 224, 224)
preds = v(img) # (1, 1000)
## LeViT
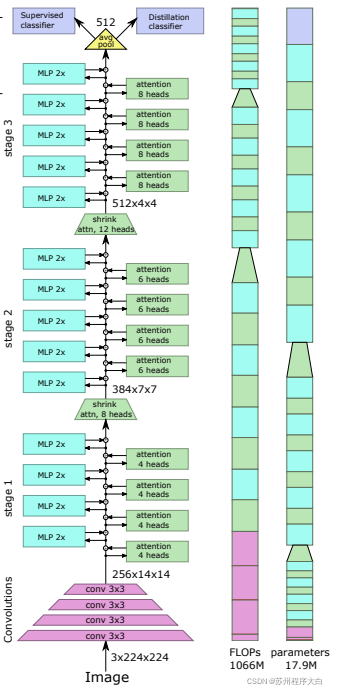
这篇[论文](https://bbs.csdn.net/topics/618540462)提出了一些变化,包括(1)卷积嵌入而不是逐块投影(2)阶段中的下采样(3)注意力中的额外非线性(4)二维相对位置偏差而不是初始绝对位置偏差(5 ) 批范数代替层范数。
[官方仓库](https://bbs.csdn.net/topics/618540462)
import torch
from vit_pytorch.levit import LeViT
levit = LeViT(
image_size = 224,
num_classes = 1000,
stages = 3, # number of stages
dim = (256, 384, 512), # dimensions at each stage
depth = 4, # transformer of depth 4 at each stage
heads = (4, 6, 8), # heads at each stage
mlp_mult = 2,
dropout = 0.1
)
img = torch.randn(1, 3, 224, 224)
levit(img) # (1, 1000)
## CvT
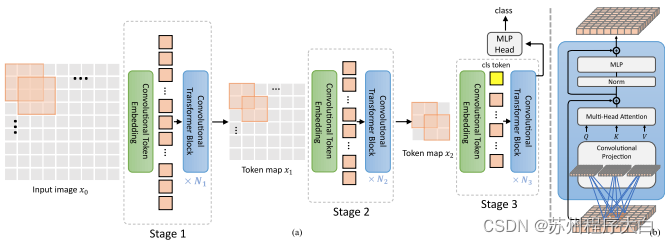
[本文](https://bbs.csdn.net/topics/618540462)提出混合卷积和注意力。具体来说,卷积用于分三个阶段嵌入和下采样图像/特征图。深度卷积还用于投影查询、键和值以引起注意。
import torch
from vit_pytorch.cvt import CvT
v = CvT(
num_classes = 1000,
s1_emb_dim = 64, # stage 1 - dimension
s1_emb_kernel = 7, # stage 1 - conv kernel
s1_emb_stride = 4, # stage 1 - conv stride
s1_proj_kernel = 3, # stage 1 - attention ds-conv kernel size
s1_kv_proj_stride = 2, # stage 1 - attention key / value projection stride
s1_heads = 1, # stage 1 - heads
s1_depth = 1, # stage 1 - depth
s1_mlp_mult = 4, # stage 1 - feedforward expansion factor
s2_emb_dim = 192, # stage 2 - (same as above)
s2_emb_kernel = 3,
s2_emb_stride = 2,
s2_proj_kernel = 3,
s2_kv_proj_stride = 2,
s2_heads = 3,
s2_depth = 2,
s2_mlp_mult = 4,
s3_emb_dim = 384, # stage 3 - (same as above)
s3_emb_kernel = 3,
s3_emb_stride = 2,
s3_proj_kernel = 3,
s3_kv_proj_stride = 2,
s3_heads = 4,
s3_depth = 10,
s3_mlp_mult = 4,
dropout = 0.
)
img = torch.randn(1, 3, 224, 224)
pred = v(img) # (1, 1000)
## Twins SVT

该[文](https://bbs.csdn.net/topics/618540462)提出了混合本地和全球的关注,与位置编码发生器(中提出沿[CPVT](https://bbs.csdn.net/topics/618540462))和全球平均水平池,以达到相同的结果[斯文](https://bbs.csdn.net/topics/618540462),没有转移的窗户,CLS令牌,也不是位置的嵌入的额外的复杂性。
import torch
from vit_pytorch.twins_svt import TwinsSVT
model = TwinsSVT(
num_classes = 1000, # number of output classes
s1_emb_dim = 64, # stage 1 - patch embedding projected dimension
s1_patch_size = 4, # stage 1 - patch size for patch embedding
s1_local_patch_size = 7, # stage 1 - patch size for local attention
s1_global_k = 7, # stage 1 - global attention key / value reduction factor, defaults to 7 as specified in paper
s1_depth = 1, # stage 1 - number of transformer blocks (local attn -> ff -> global attn -> ff)
s2_emb_dim = 128, # stage 2 (same as above)
s2_patch_size = 2,
s2_local_patch_size = 7,
s2_global_k = 7,
s2_depth = 1,
s3_emb_dim = 256, # stage 3 (same as above)
s3_patch_size = 2,
s3_local_patch_size = 7,
s3_global_k = 7,
s3_depth = 5,
s4_emb_dim = 512, # stage 4 (same as above)
s4_patch_size = 2,
s4_local_patch_size = 7,
s4_global_k = 7,
s4_depth = 4,
peg_kernel_size = 3, # positional encoding generator kernel size
dropout = 0. # dropout
)
img = torch.randn(1, 3, 224, 224)
pred = model(img) # (1, 1000)
## RegionViT
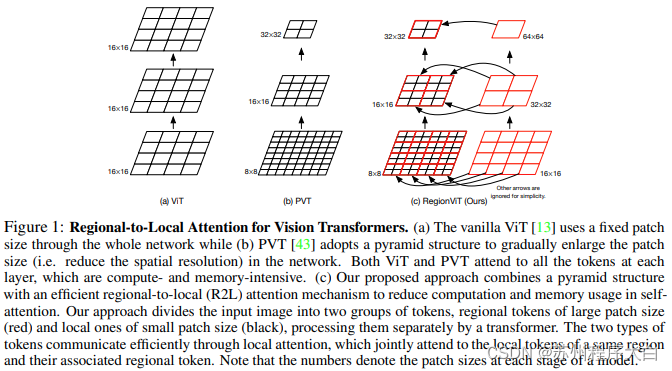
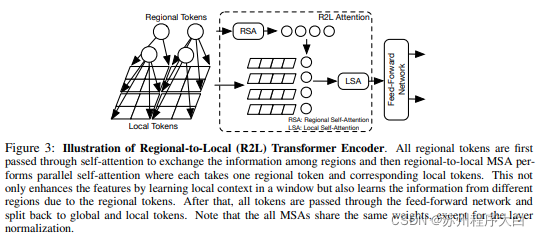
本[文](https://bbs.csdn.net/topics/618540462)提出将特征图划分为局部区域,从而使局部标记相互协调。每个本地区域都有自己的区域令牌,然后处理其所有本地令牌以及其他区域令牌。
您可以按如下方式使用它:
import torch
from vit_pytorch.regionvit import RegionViT
model = RegionViT(
dim = (64, 128, 256, 512), # tuple of size 4, indicating dimension at each stage
depth = (2, 2, 8, 2), # depth of the region to local transformer at each stage
window_size = 7, # window size, which should be either 7 or 14
num_classes = 1000, # number of output classes
tokenize_local_3_conv = False, # whether to use a 3 layer convolution to encode the local tokens from the image. the paper uses this for the smaller models, but uses only 1 conv (set to False) for the larger models
use_peg = False, # whether to use positional generating module. they used this for object detection for a boost in performance
)
img = torch.randn(1, 3, 224, 224)
pred = model(img) # (1, 1000)
## CrossFormer
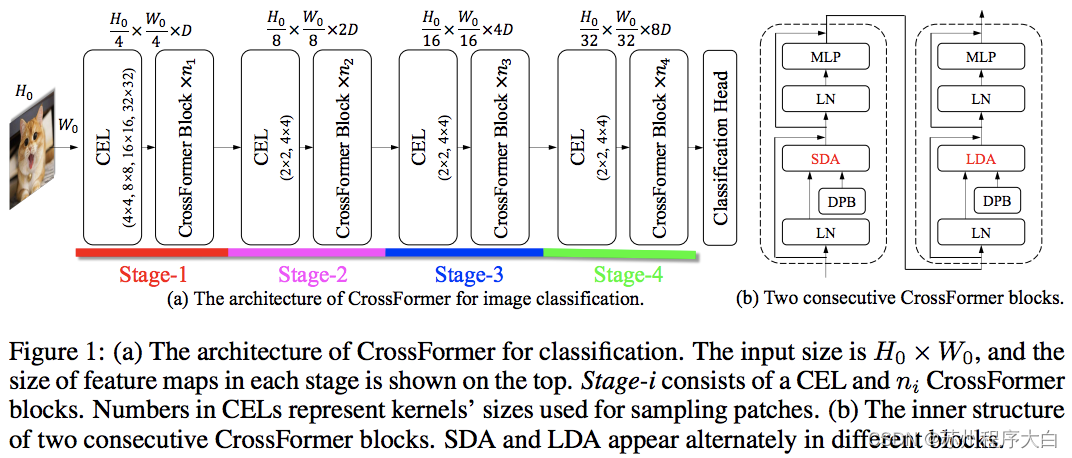
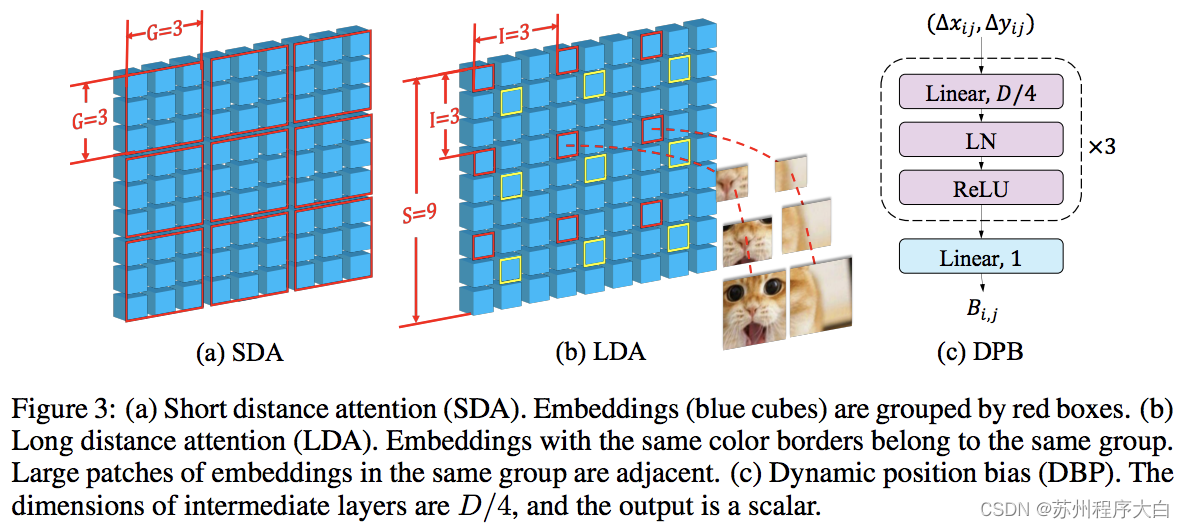
这[纸](https://bbs.csdn.net/topics/618540462)PVT和欧亚交替使用本地和全球的关注甘拜下风。全局注意力是跨窗口维度完成的,以降低复杂性,就像用于轴向注意力的方案一样。
他们还有跨尺度嵌入层,他们证明这是一个可以改进所有视觉转换器的通用层。还制定了动态相对位置偏差,以允许网络推广到更高分辨率的图像。
import torch
from vit_pytorch.crossformer import CrossFormer
model = CrossFormer(
num_classes = 1000, # number of output classes
dim = (64, 128, 256, 512), # dimension at each stage
depth = (2, 2, 8, 2), # depth of transformer at each stage
global_window_size = (8, 4, 2, 1), # global window sizes at each stage
local_window_size = 7, # local window size (can be customized for each stage, but in paper, held constant at 7 for all stages)
)
img = torch.randn(1, 3, 224, 224)
pred = model(img) # (1, 1000)
## NesT
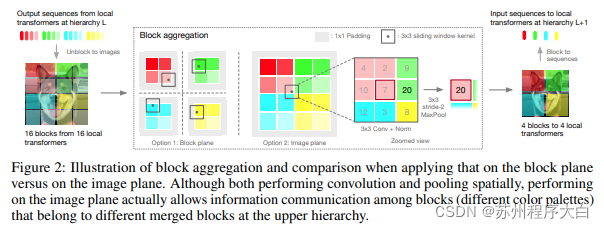
这[纸](https://bbs.csdn.net/topics/618540462)决定来处理分层级的图像,注意力只在局部块,其中聚集因为它移动了层次结构的令牌。聚合是在图像平面中完成的,并包含一个卷积和后续的 maxpool,以允许它跨边界传递信息。
您可以使用以下代码(例如 NesT-T)
import torch
from vit_pytorch.nest import NesT
nest = NesT(
image_size = 224,
patch_size = 4,
dim = 96,
heads = 3,
num_hierarchies = 3, # number of hierarchies
block_repeats = (8, 4, 1), # the number of transformer blocks at each heirarchy, starting from the bottom
num_classes = 1000
)
img = torch.randn(1, 3, 224, 224)
pred = nest(img) # (1, 1000)
## MobileViT

这个纸介绍MobileViT,重量轻的和通用的视觉变压器用于移动设备。MobileViT 为使用转换器对信息进行全局处理提供了不同的视角。
您可以使用以下代码(例如 mobilevit\_xs)
import torch
from vit_pytorch.mobile_vit import MobileViT
mbvit_xs = MobileViT(
image_size = (256, 256),
dims = [96, 120, 144],
channels = [16, 32, 48, 48, 64, 64, 80, 80, 96, 96, 384],
num_classes = 1000
)
img = torch.randn(1, 3, 256, 256)
pred = mbvit_xs(img) # (1, 1000)
## 简单的蒙版图像建模

这个纸提出了一种简单的掩蔽图像的建模(SimMIM)方案,仅使用一个线性投影断掩蔽令牌为像素空间后跟一个L1损失与掩蔽贴片的像素值。结果与其他更复杂的方法相比具有竞争力。
您可以按如下方式使用它:
import torch
from vit_pytorch import ViT
from vit_pytorch.simmim import SimMIM
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 8,
mlp_dim = 2048
)
mim = SimMIM(
encoder = v,
masking_ratio = 0.5 # they found 50% to yield the best results
)
images = torch.randn(8, 3, 256, 256)
loss = mim(images)
loss.backward()
that’s all!
do the above in a for loop many times with a lot of images and your vision transformer will learn
torch.save(v.state_dict(), ‘./trained-vit.pt’)
## 屏蔽自编码器

Kaiming He 的一篇新论文提出了一种简单的自动编码器方案,其中视觉转换器处理一组未屏蔽的补丁,而较小的解码器尝试重建屏蔽的像素值。
DeepReader 快速论文审查
与 Letitia 的 AI Coffeebreak
您可以通过以下代码使用它
import torch
from vit_pytorch import ViT, MAE
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 8,
mlp_dim = 2048
)
mae = MAE(
encoder = v,
masking_ratio = 0.75, # the paper recommended 75% masked patches
decoder_dim = 512, # paper showed good results with just 512
decoder_depth = 6 # anywhere from 1 to 8
)
images = torch.randn(8, 3, 256, 256)
loss = mae(images)
loss.backward()
that’s all!
do the above in a for loop many times with a lot of images and your vision transformer will learn
save your improved vision transformer
torch.save(v.state_dict(), ‘./trained-vit.pt’)
## 💫点击直接资料领取💫

**这里有各种学习资料还有有有趣好玩的编程项目,更有难寻的各种资源。**
**❤️关注苏州程序大白公众号❤️**
**👇 👇👇**
## 学习路线:
这个方向初期比较容易入门一些,掌握一些基本技术,拿起各种现成的工具就可以开黑了。不过,要想从脚本小子变成黑客大神,这个方向越往后,需要学习和掌握的东西就会越来越多以下是网络渗透需要学习的内容:
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/topics/618540462)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









