







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Golang全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注go)

正文
可以看到,创建索引之前搜索name为蝉沐风的记录花费时间为0.96秒,为name字段创建索引后,搜索时间仅为0.03秒,可见索引的作用之大。
但是我们没有显式为主键创建索引,为什么主键查询也这么快?我在上一篇文章中解释了主键查询快的原因,但是只解释了一半,现在我来解释另一半。
虽然我希望每一篇文章都讲述一个独立的知识点,但是对于MySQL这种复杂的软件,各种细节之间盘根错节,想深入理解一个知识点很多时候需要其他知识点的加持,在继续阅读之前,强烈推荐你花10分钟先读一下这篇文章。
如果你实在不想看,我会简单总结一下之前讲的内容。
强烈推荐阅读:图解|12张图解释MySQL主键查询为什么这么快
2. 前置知识
现在我们已经知道了,InnoDB存储引擎为我们提供了4种不同的行格式来保存我们向MySQL中插入的数据,在这里我们统一称之为记录。
记录是保存在InnoDB页中的,InnoDB存储引擎将数据划分为若干个页,以页作为磁盘和内存之间交互的最小单位。InnoDB中页的大小默认为16KB。也就是默认情况下,一次最少从磁盘中读取16KB的数据到内存中,一次最少把内存中16KB的内容刷新到磁盘上。存储用户记录的页我们统一叫做数据页,它只是众多类型的InnoDB页中的一种而已,其他类型的页我们无需关注。
非常非常重要的一点是,在一个数据页中,用户记录是按照主键由小到大的顺序串联而成的单向链表。
但是一个数据页中的记录可能非常多,为了逃避低效的遍历,InnoDB引擎的设计者想出了一种绝妙的搜索方法,把数据页中的所有记录(包括伪记录)分成若干个小组(并对每个小组内的组员数量做了规定),每个小组选出组内最大的一条记录作为“小组长”,接着把所有小组长的地址拿出来,编成目录。
举个例子,下面的图片展示了一个数据页中的所有记录被分组的情况:
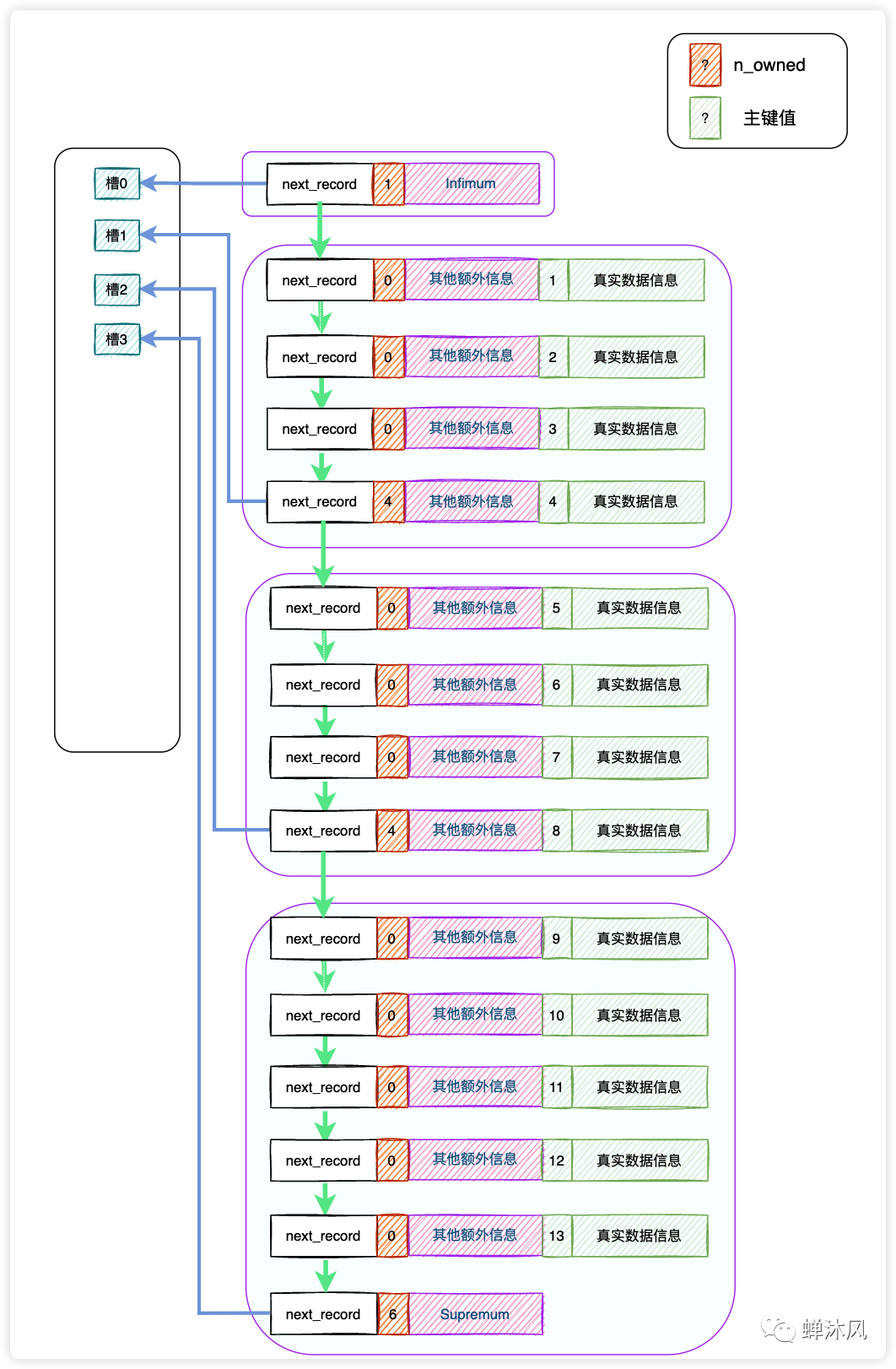
上图中的所有记录(包括伪记录)分成了4个小组,每个小组的“组长”被单独提拔,单独编制成“目录”,InnoDB官方称之为「槽」。槽在物理空间中是连续的,意味着通过一个槽可以很轻松地找到它的上一个和下一个,这一点非常重要。
槽的编号从0开始,我们查找数据的时候先找到对应的槽,然后再到小组中进行遍历即可,因为一个小组内的记录数量并不多,遍历的性能损耗可以忽略。而且每个槽代表的“组长”的主键值也是从小到大进行排列的,所以我们可以用二分法进行槽的快速查找。
图中包含4个槽,分别是0、1、2、3,二分法查找之前,最低的槽low=0,最高的槽high=3。现在我们再来看看在这个数据页中,我们查询id为7的记录,过程是怎样的。
- 使用二分法,计算中间槽的位置,
(0+3)/2=1,查看槽1对应的“组长”的主键值为4,因为4<7,所以设置low=1,high保持不变; - 再次使用二分法,计算中间槽的位置,
(1+3)/2=2,查看槽2对应的“组长”的主键值为8,因为8>7,所以设置high=2,low保持不变; - 现在
high=2,low=1,两者相差1,已经没有必要继续进行二分了,可以确定我们的记录就在槽2中,并且我们也能知道槽2对应的“组长”的主键是8,但是记录之间是单向链表,我们无法向前遍历。上文提到过,我们可以通过槽2找到槽1,进而找到它的“组长”,然后沿着“组长”向下遍历直到找到主键为7的记录就可以了。
当用户记录多到一个数据页装不下的时候,就再申请一个数据页,各个数据页在逻辑上使用双向链表进行连接,因此新分配的数据页编号就没必要非得按照从小到大的顺序进行排列了,如下图所示:
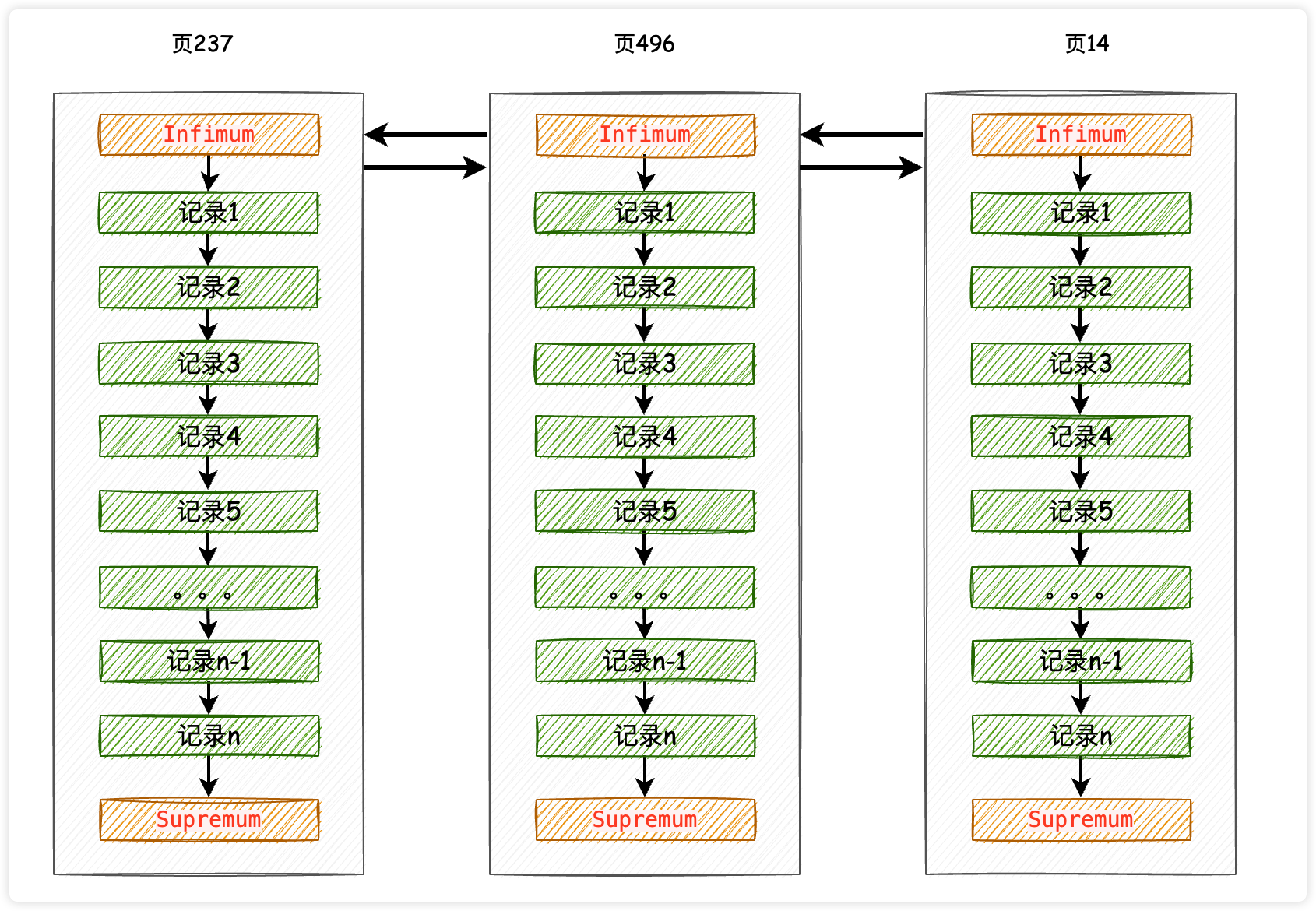
因此,虽然在一个数据页内能够做到主键的快速查询,但是InnoDB存储引擎不知道你要查找的记录所在的页号,那也只能从第一页开始沿着双向链表一直进行查找,遍历每一页,至于在每一个数据页中是怎么查找的,你已经很清楚了。
很显然,InnoDB引擎有办法能够快速定位到你要的主键数据所在的数据页,而不是从第一页开始遍历,否则不可能有例3那样的查询速度。
那么,InnoDB是怎么做到的呢?
3. InnoDB索引
3.1 主键索引登场
为了方便描述,我们假设一个数据页最多只能放3条用户记录,那么user_innodb表的前12条数据的保存形式如下图:
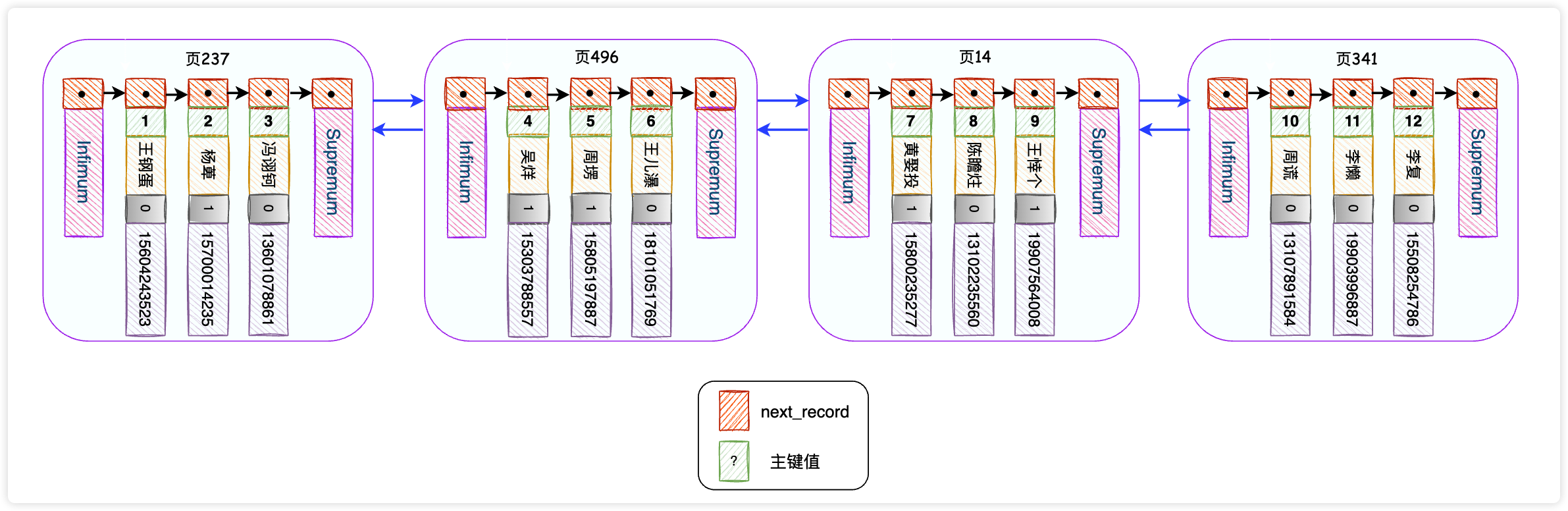
大家看这些连接起来的数据页像不像组成一本书的每一章?自然,数据页中的每一条记录就是章中的每一个小节了。

那么为了加快检索,我们可以模拟书籍章节目录,给数据页添加一个目录。
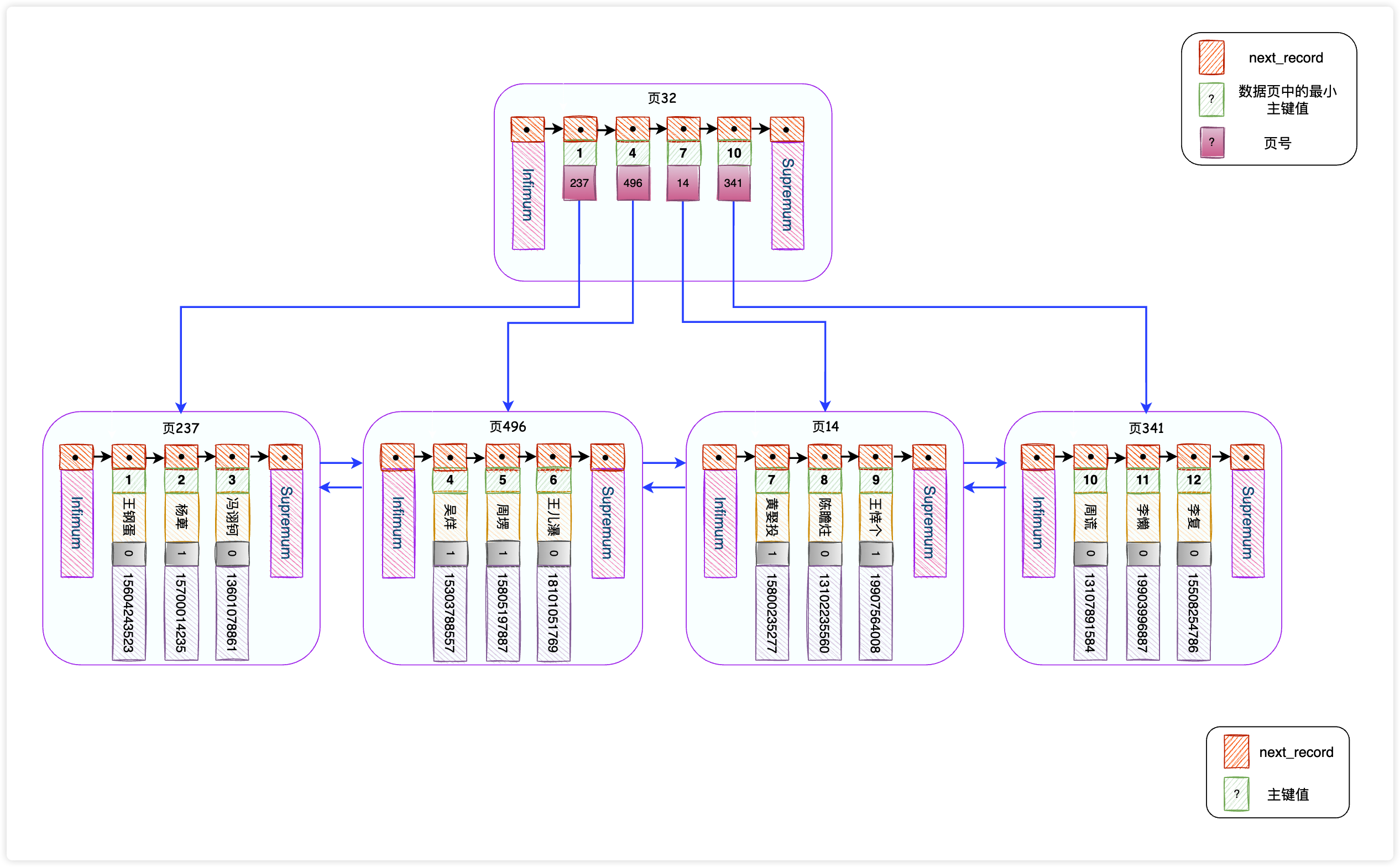
如上图,我们为4个数据页创建了一个目录,每个数据页对应了一条记录,为了区别于用户记录,我们称之为目录项纪录,目录项记录同样是按照主键从小到大的顺序进行单向链接的。
不同于用户记录中包含了完整的数据,目录项记录只包含了数据页的最小主键值和对应的数据页号。既然都是记录,InnoDB的设计者直接用数据页来存储目录项记录了,所以上图中页32的页面结构和其他数据页是完全一样的。
接下来我们看看加了个目录是如何提高我们的查询效率的,以查询主键id为8的记录为例,步骤大致如下:
- 先找到存储目录项的数据页32,通过二分法快速定位到对应的目录项记录,因为
7<8<10,所以定位到对应的记录所在的页应该是页14; - 然后在页14中进行查找就可以了,查找的方法我们之前介绍过了。
目前的页面并不多,所以对查询效率的提升并不十分明显,但是一旦数据页的数量飞速增长,这种通过添加目录的方式带来的查询优势会被无限放大!但是同时有个问题,数据页多了,目录项记录在一个数据页中不够用了怎么办?
再加一个数据页。我们再添加2条用户记录,看一下添加之后的样子:
注:实际上一个页面中能够存放的记录(用户记录/目录项记录)数目是非常多的,为了方便画图,我只是假设了数据页最多存放3条用户记录,最多存放4条目录项记录
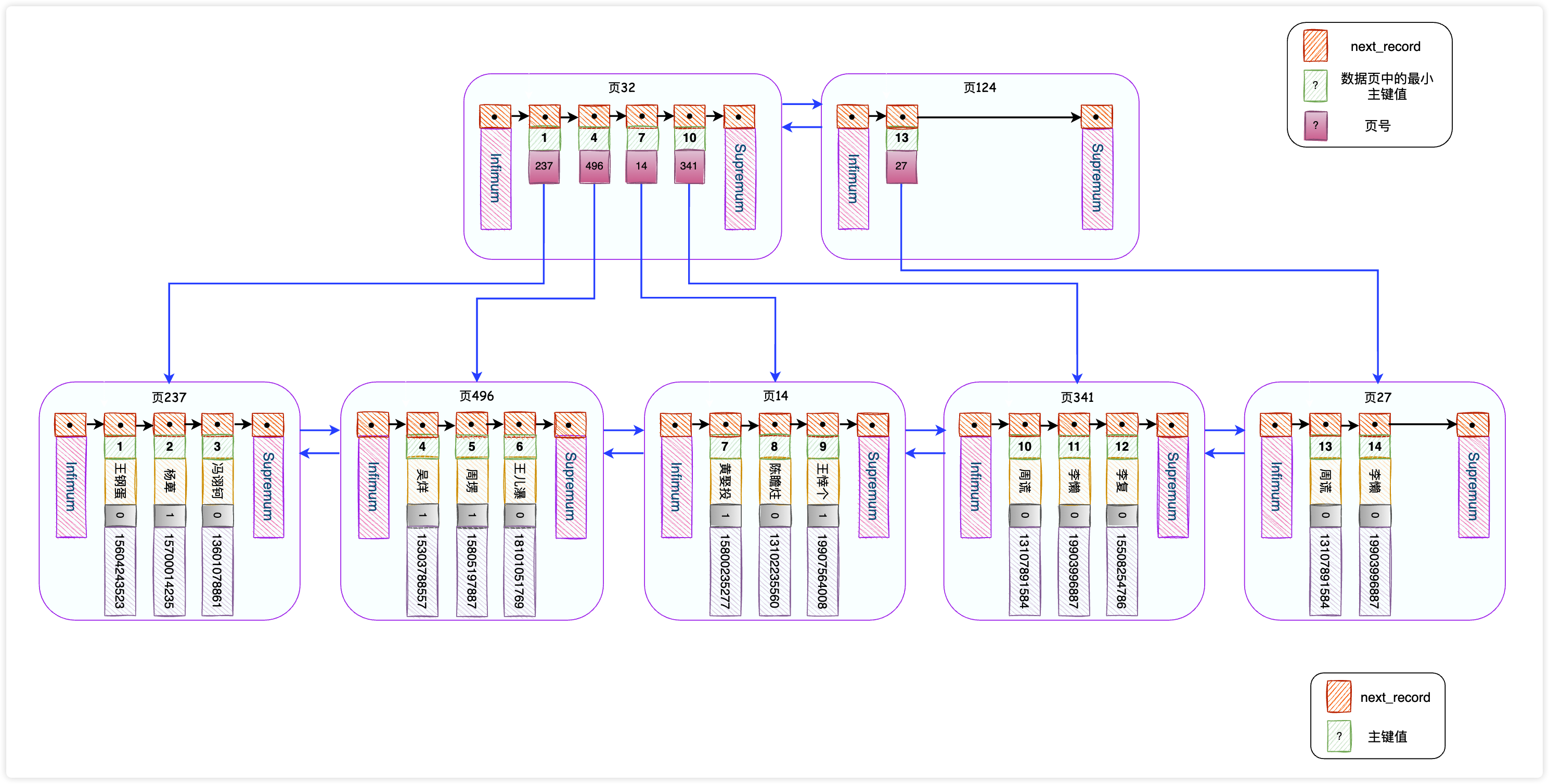
现在假设要查找主键ID为14的记录,我们还是先得找到存储目录项的数据页,可是现在有2个这种数据页,分别是页32、页124,我怎么知道要定位到哪一个目录项数据页呢?从页32开始遍历吗?别开玩笑了,我们做这么多就是为了不想遍历。这样吧,我们为存储目录项的数据页再生成一个目录。我们来捋一捋关系。
前面举过例子,存储用户记录的数据页相当于章,用户记录相当于小节,为章节生成目录就得到了存储目录项记录的数据页(页32和页124),相当于是一本书,然后再为书编一个目录,就相当于是个书架。
对应到存储结构上那就是下图:
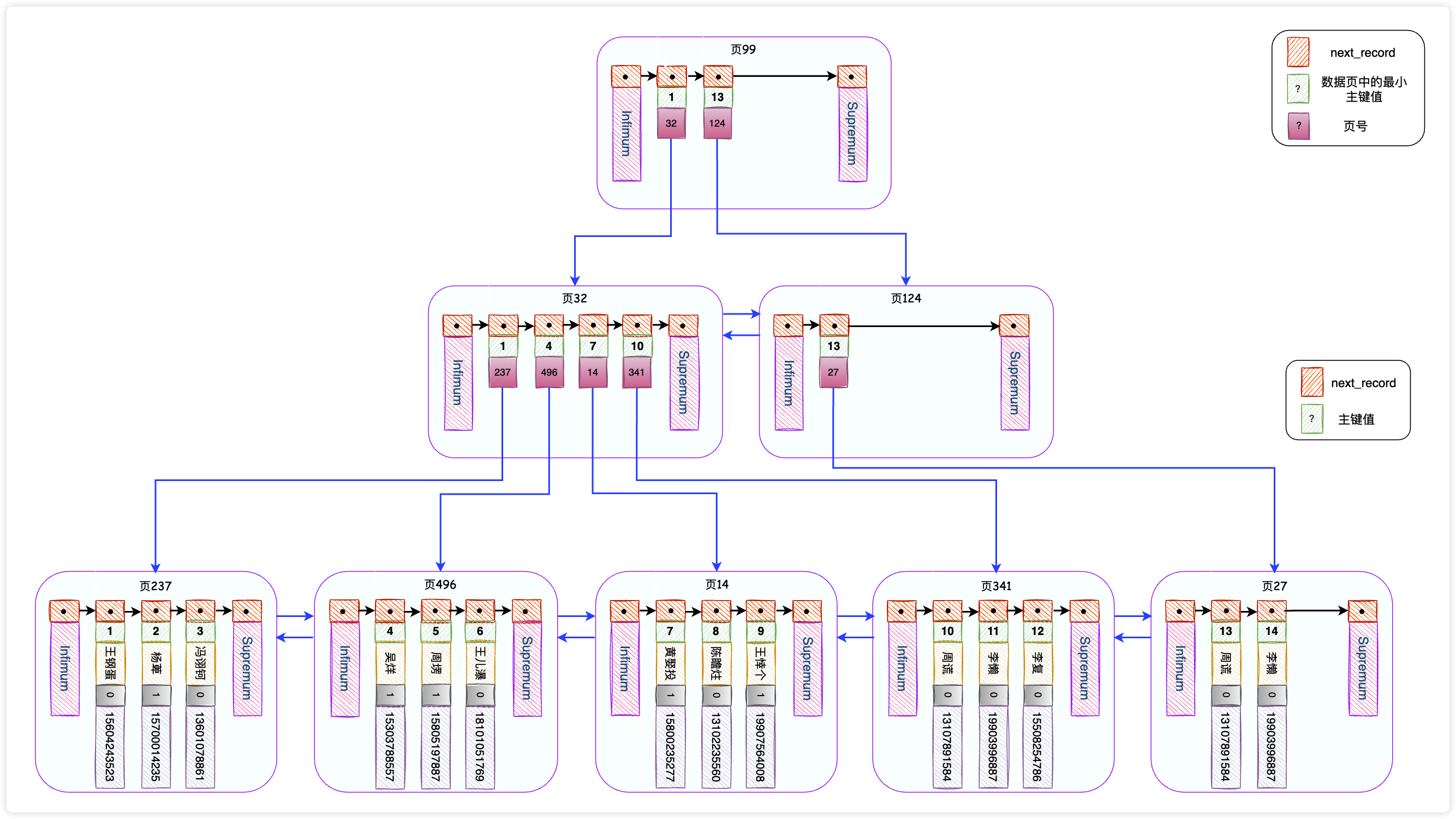
按照上图,我们又添加了一个数据页99,用来保存页32和页124对应的2条目录,现在要查找主键ID为14的记录,需要经历这几个步骤:
- 就从页99中,快速检索到对应的目录项数据页124;
- 在页124中,快速检索到对应的数据页27;
- 在页27中,快速检索到主键为14的记录。
到这里为止,你已经悄悄地掌握了B+树了。没错,上面我们一步步推导出来的搜索结构就是大名鼎鼎的B+树,而MySQL给它起了一个更响亮的名字——索引。
B+树最底层的节点(对应图中存储用户记录的数据页)被称为叶子节点,其他的节点自然叫做非叶子节点了,更特殊地,B+树最顶部的节点叫做根节点。
有一个值得我们关注的细节,这棵B+树的叶子节点存储了我们完整的用户记录(就是我们插入表的所有数据),而且,这是用户记录在InnoDB引擎中的唯一存储方式。也就是所谓的“索引即数据,数据即索引”。
更方便地一点是,这个关于主键的索引完全是由InnoDB存储引擎自动生成的,不需要我们显式地书写创建索引的语句。这个索引叫做主键索引,又叫做聚簇索引。
主键索引有两个特点:
- 按照主键的大小对用户记录和数据页进行排序,记录用单向链表连接,数据页使用双向链表连接;
- B+树的叶子节点保存了用户的完整记录。
现在终于解释完为什么主键查询这么快了,搞明白主键索引之后,普通索引和联合索引就太简单了!
3.2 普通索引
主键索引是在搜索条件为主键的时候才会发挥作用,但是我要以name='蝉沐风'为搜索条件怎么办?通过主键索引的讲解,我们首先会想到这么一个方案:再创建一个B+树(我们称为name索引),其中用户记录和数据页按照name字段进行排序,B+树的叶子节点保留完整的用户数据,这样就可以实现对name列的快速搜索了。
但是如此一来,表中数据就被完整记录了2次(主键索引的叶子节点和name索引的叶子节点),要是我们为其他字段再建立索引,磁盘空间可想而知。因此,我们得想个其他的办法。
我们已经知道根据主键查询用户记录是非常快的了,那我们可以想个办法根据name字段来迅速找到主键,然后再根据主键查找用户记录啊。这个办法同样离不开B+树。
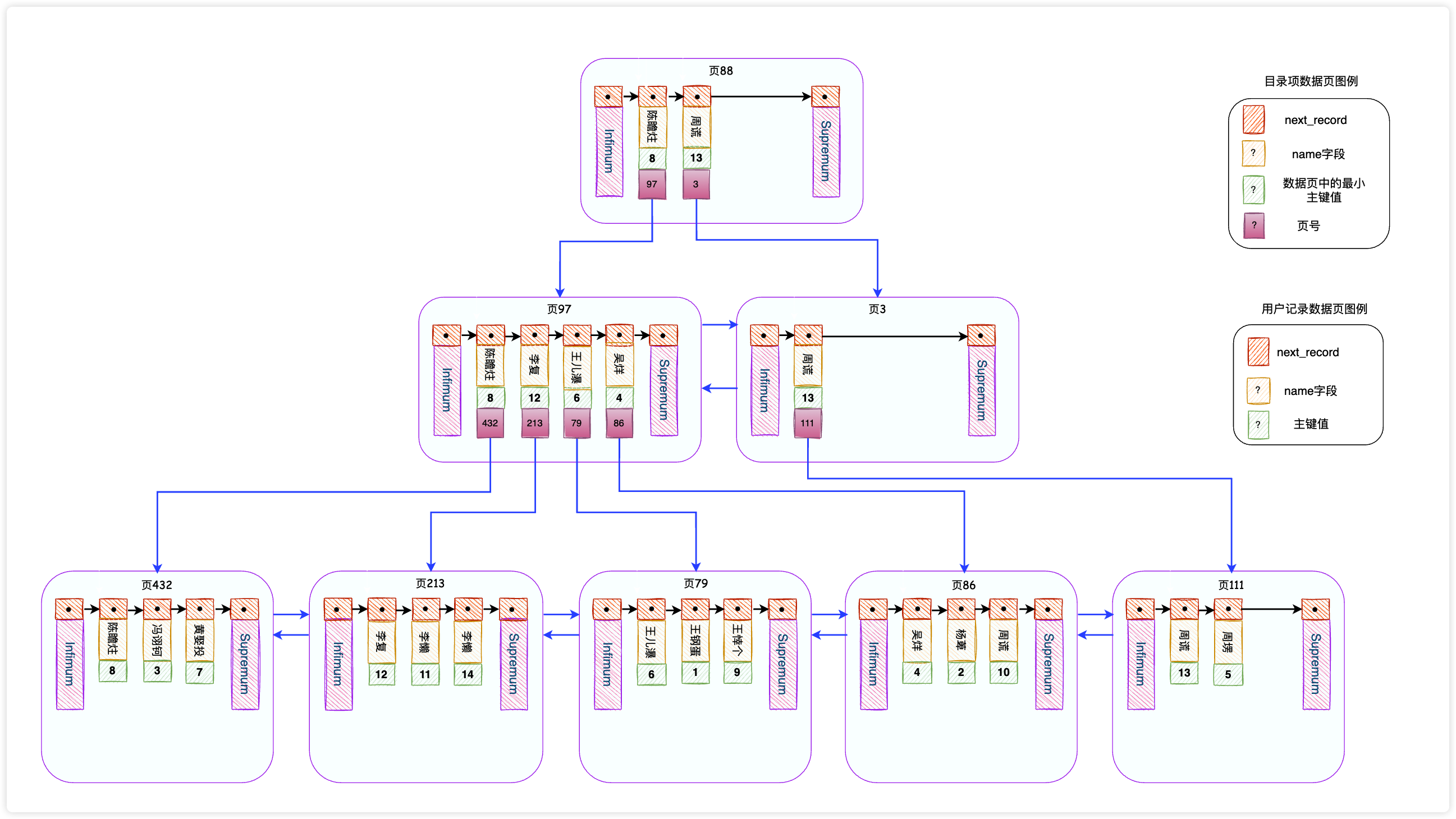
这棵B+树和聚簇索引的B+树有点区别:
- 叶子节点存放的不再是完整的用户记录,而是只记录
name列和主键值; - 数据页中存放的用户记录和目录项记录由原本的按照主键排序变为按照
name列排序; - 目录项记录除了存储索引列(
name)和页号之外,同时还存储了主键值;(大家可以想一想,为什么要存储主键值)
有了这棵B+树,你就可以通过name列快速找到主键值了,查找的方式和根据主键值查找用户记录的方式完全一样,只不过前者查到的是主键值,后者查找到的是一条完整的用户记录罢了。
你可能对字符串进行二分法感到有点奇怪,甚至没有接触过的相关知识的读者连对字符串进行排序都会觉得很诧异。其实在创建表的时候我们可以对字符串字段指定字符集和比较规则,如果你不指定,MySQL会默认给你设置,总之,MySQL总会找到一个方式对字符串进行排序。
现在得到主键的id了,然后根据主键id到主键索引中查找到完整的用户记录,这个过程叫做回表。如果没有为name列设置唯一性约束,那就可能找到多个符合条件的主键id,多回几次表就可以了。
对name这种单个列添加的索引叫做普通索引,也叫二级索引。
如果同时对多个列建立索引,那B+树的存储又会是什么样子呢?这就是联合索引了,理解了上面的内容,再理解联合索引只是水到渠成的事罢了。
3.3 联合索引
假设我们为name列和phone列建立联合索引(注意我描述的顺序),自然也是创建一棵B+树,这棵B+树和之前又稍微有点不同:
- 叶子节点存放的是
name列、phone列和主键值; - 目录项记录除了存储索引列(
name、phone)和页号之外,同时还存储了主键值;(大家可以想一想,为什么要存储主键值) - 数据页中存放的用户记录和目录项记录由原本的按照主键排序变为按照
name列排序,如果name列相同,那就按照phone列排序;(如果phone列再一样呢?你现在明白为什么要存储主键值了吗?)
再画个图吧(有点偷懒了哈,数据页号没换):
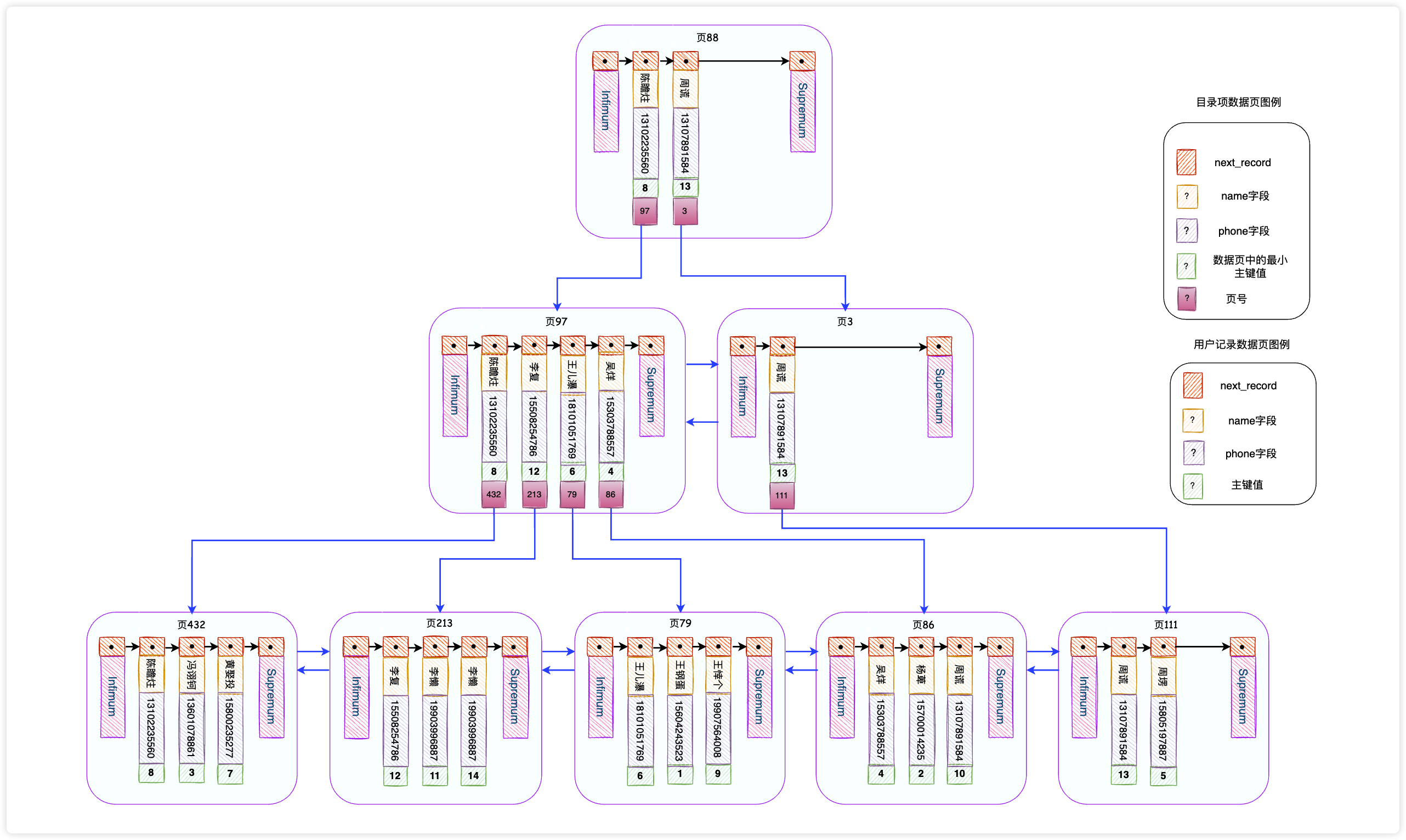
还是和二级索引一样,利用B+树快速定位到数据页,然后页内快速定位到记录,找到记录中的主键id,再回表,如果找到多条符合条件的记录,就多回几次表。
4. InnoDB其他的索引方式
以上介绍的是B+树索引,它其实是InnoDB存储引擎提供的众多索引中的一种而已,但却是使用最多、面试中最常被问到的一种索引。除此之外,还提供了其他的索引方式,例如我的TablePlus工具(Mac上的MySQL连接工具)提供了4种。
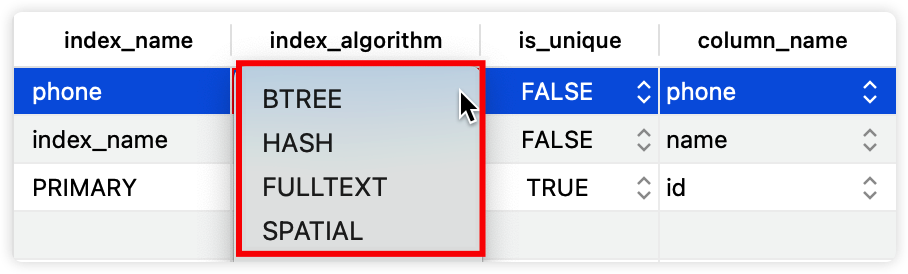
4.1 HASH
如果你用过Java的HashMap或者Python的字典,你对这个概念就应该很清楚了。
哈希表是一种采用键值对(Key-Value)存储数据的结构,它会根据索引字段生成哈希码和指针,指针指向表中的数据。不可避免地,多个索引字段值经过哈希函数的换算,会出现同一个值的情况,处理这种情况的一种方法就是创建一个单向链表。如下图所示,我们为name字段创建HASH索引:
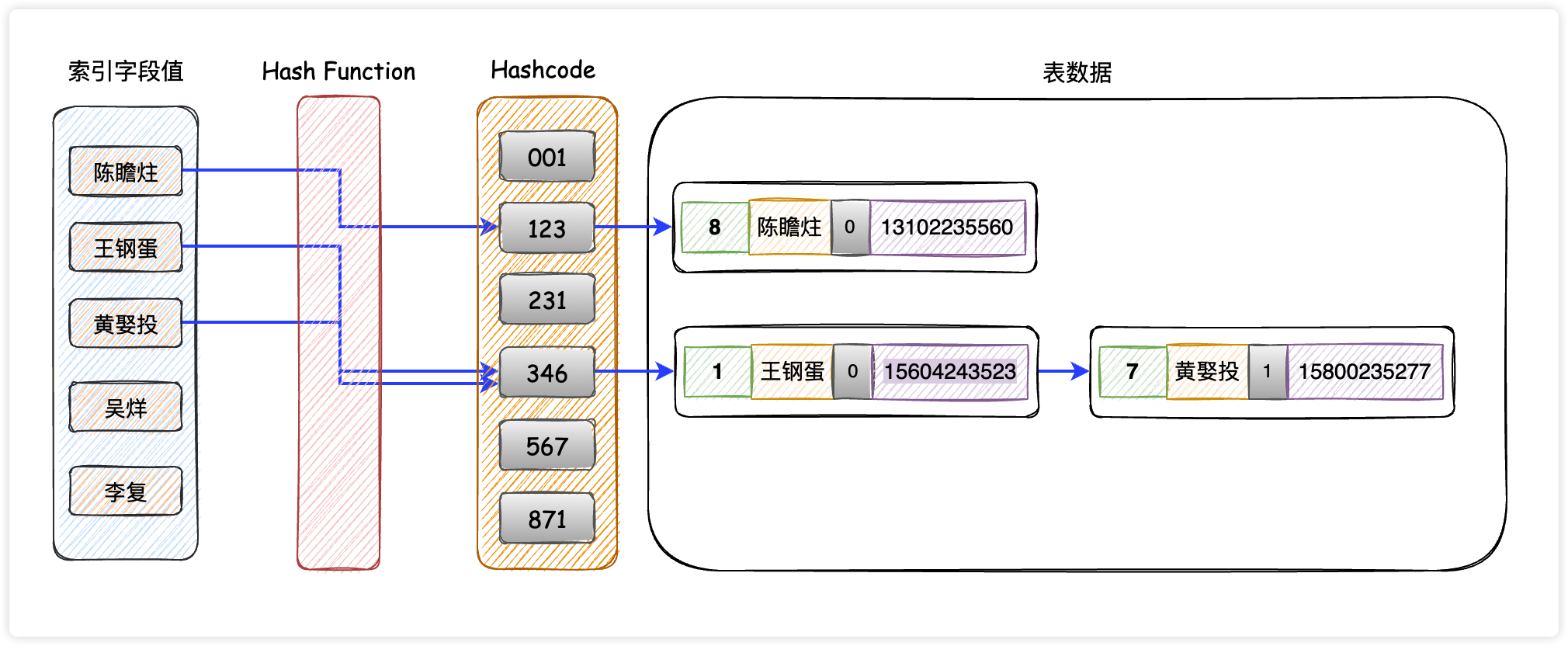
哈希索引有3个重要特点:
- 查询速度非常非常快,时间复杂度是O(1),因为哈希索引中的数据不是按照顺序存储的,所以不能用于排序;
- 查询数据的时候要根据键值计算哈希码,所以它只能支持等值查询(
=、IN),不支持范围查询(>、<、>=、<=、BETWEEN、AND); - 如果哈希冲突,就得采用添加单向链表的方法解决,会造成效率下降。
另外,虽然提供了HASH的索引方法,但是在InnoDB中无法显式创建一个HASH索引,所谓地支持哈希索引其实指的是自适应哈希索引(AHI),是InnoDB自动为BufferPool中的热点页创建的索引。虽然TablePlus在创建索引的时候能够选择HASH,但是实际创建完之后显示类型仍然是BTREE。
4.2 FULLTEXT
如果你的数据表有一个大文本字段,你想查询这个字段中包含「蝉沐风」的所有记录,你可能会采用LIKE '%蝉沐风%'的方式进行查询,但是索引的最左匹配原则告诉你这样的查询效率太低了,这时候全文索引就出现了。
为了说明问题,我们假设一个文本字段存储了这样一段文字:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
就出现了。
为了说明问题,我们假设一个文本字段存储了这样一段文字:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)
[外链图片转存中…(img-M8uyGGv5-1713476109261)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









