






 文章讲述了内存重叠情况下memcpy和memmove的区别,以及在不确定地址是否重叠时使用memmove以确保安全。强调了持续学习和系统化知识在IT行业的重要性。
文章讲述了内存重叠情况下memcpy和memmove的区别,以及在不确定地址是否重叠时使用memmove以确保安全。强调了持续学习和系统化知识在IT行业的重要性。
当内存发生重叠时
#include <stdio.h>
#include <string.h>
int main() {
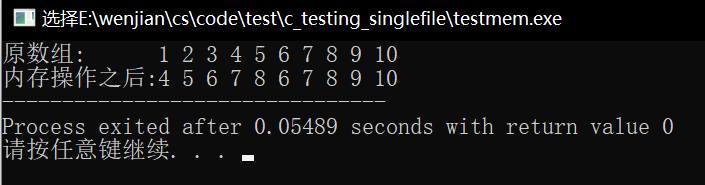
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int i;
printf("原数组: ");
for(i = 0; i < 10; i++) {
printf("%d ",arr[i]);
}
printf("\n内存操作之后:");
memcpy(arr, arr + 3, sizeof(int)*5);//memmove(arr, arr + 3, sizeof(int)*5)
for(i = 0; i < 10; i++) {
printf("%d ",arr[i]);
}
}
我么用一张图来说明上面的情况

我们很容易知道,当原地址和目标地址没有发生内存重叠时,memcpy和memmove的效果是一样的。当原地址和目标地址有内存重叠时,那就存在一个内存复制顺序,我们知道内存复制的过程是一般读取一个字节到寄存器中进行操作,复制到目的地址,那是先从低地址开始还是高地址开始呢?
即是先从arr+3复制到arr,还是先从arr+7复制到arr+4呢?
因为存在内存重叠,所以两种不同的复制顺序会影响最后的结果。如下图所示

理论上是存在这样两种情况的。
实际上我们是不确定memcpy会采用哪种方法的。
而memmove是会以从低地址开始的。
总结:当我们确定我们的源地址和目标地址是没有重叠时,我们可以用memcpy,一般来说memcpy会更快一些。如果不能确定源地址和目标地址是否有重叠时,建议用memmove,这样会更安全。
实际上现在memcpy在源地址和目标地址是否有重叠时,结果也是正常的,只是这个结果会依赖编译器,我们不能让结果依赖编译器的处理。
写在最后
在结束之际,我想重申的是,学习并非如攀登险峻高峰,而是如滴水穿石般的持久累积。尤其当我们步入工作岗位之后,持之以恒的学习变得愈发不易,如同在茫茫大海中独自划舟,稍有松懈便可能被巨浪吞噬。然而,对于我们程序员而言,学习是生存之本,是我们在激烈市场竞争中立于不败之地的关键。一旦停止学习,我们便如同逆水行舟,不进则退,终将被时代的洪流所淘汰。因此,不断汲取新知识,不仅是对自己的提升,更是对自己的一份珍贵投资。让我们不断磨砺自己,与时代共同进步,书写属于我们的辉煌篇章。
需要完整版PDF学习资源私我
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 3420
3420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









