







利用好tricks可以有效改善模型精度,下面介绍各种方法
方法一:魔改网络结构
(1)使用resnet的shortcut方法
(2)使用Inception 多尺度卷积核
(3)使用convolution的stride代替pool层
(4)使用正则化方法Batch normalization、Layer normalization、Instance normalization、Group Normalization;如果使用多GPU可以使Synchronized Batch Normalization
(5)对于不规则目标使用deform convolution
(6)轻量化模型使用group convolution
(7)小卷积核大视野使用dilate convolution
(8)去掉线性层使用全卷积层
(9)如果使用线性层,使用一维的Normalization,可以加快收敛并且(此方法其他网络没有)
方法二:模型初始化
(1)如果不使用finetune方法,尽量不使用随机初始化,推荐kaiming方法初始化,是xavier的改进版;
(2)大力推荐finetune方法,少量数据就可达到较高的accuracy;
方法三:损失函数和优化器
(1)一般分类使用softmax+Cross Entropy损失,MSE(均方误差)由于非凸函数,尽量不使用
(2)优化器推荐又快又好的AdaBound(新鲜出炉的算法,比SGD快,比Adam好,反正是又快又好!!!)
方法四:学习率调整
(1)Warmup
(2)Linear scaling learning rate
(3)力荐cosine learning rate或ReduceLROnPlateau learing rate
方法五:激活函数
(1)sigmoid,tanh由于后期梯度消失或者梯度很小,导致收敛比较慢,尽量不使用;
(2)推荐relu及其各种改进版本,Elus、Leaky relu、Slus、PRelu、RRule等;
方法六:数据扩增方法
(1)Random image cropping and patching (RICP)
(2Cutout
(3)Mixup train
(4)随机旋转
(5)上下、左右flip
(6)调整亮度、对比度、饱和度
(7)其他各种裁剪方法
方法七:其他方法
(1)Knowledge distillation
(2)batch size不要设置太大(收敛慢),也不要太小(梯度随机性大),依据经验在224*224图像,在现存不溢出的时候,batch size=64。
(3)使用finetune方法,一般epoch=10左右就可达到很高的accuracy;如果不使用finetune方法,一般epoch=50~100左右(以上是根据工程经验,数据集在几万张,类别小于100的情况下,如果误导,还请指正)
(4)对权重使用L2正则化,可以有效抑制过拟合
(5)Momentum一般设置0.9,根据前10次梯度方向向量的经验来加上此次的梯度方向向量来更新梯度(防止梯度突变;1/(1-0.9)=10)
(6)label smooth
还有兄弟不知道网络安全面试可以提前刷题吗?费时一周整理的160+网络安全面试题,金九银十,做网络安全面试里的显眼包!
王岚嵚工程师面试题(附答案),只能帮兄弟们到这儿了!如果你能答对70%,找一个安全工作,问题不大。
对于有1-3年工作经验,想要跳槽的朋友来说,也是很好的温习资料!
【完整版领取方式在文末!!】
93道网络安全面试题
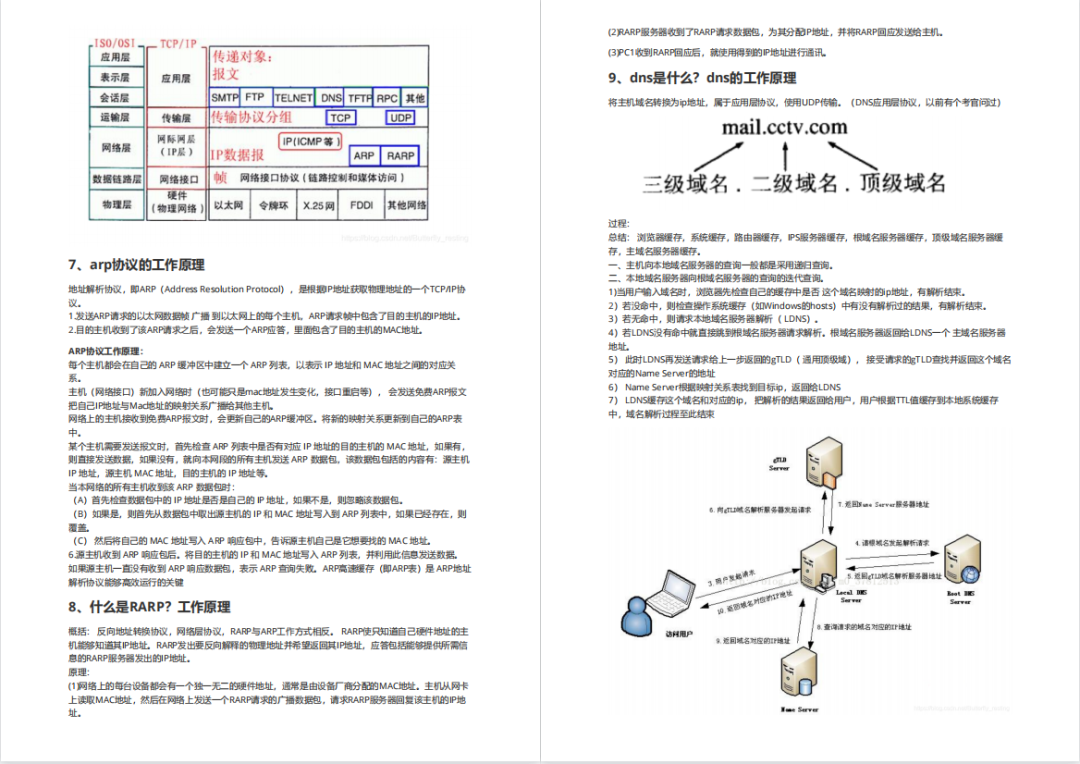


内容实在太多,不一一截图了
黑客学习资源推荐
最后给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
😝朋友们如果有需要的话,可以联系领取~
1️⃣零基础入门
① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
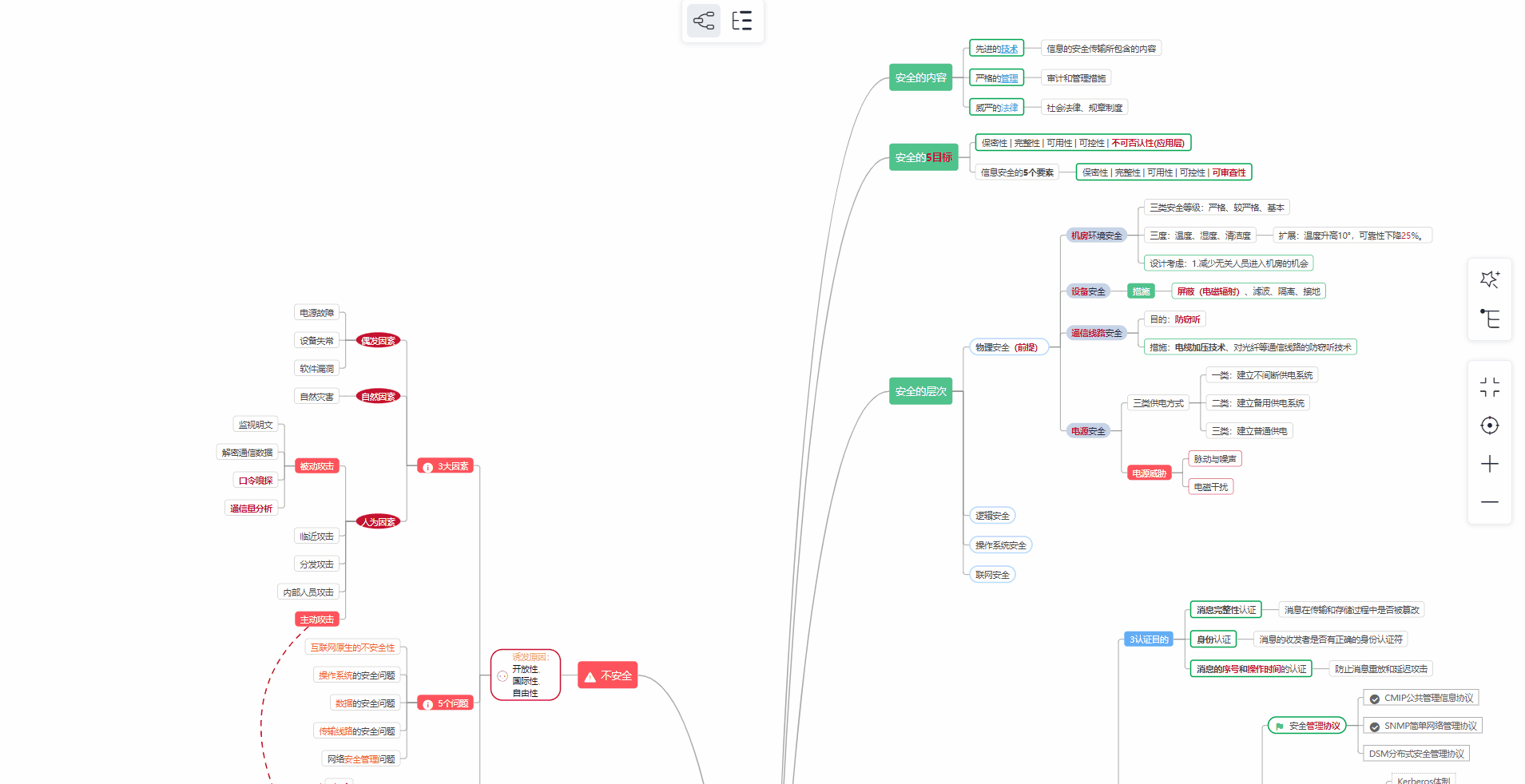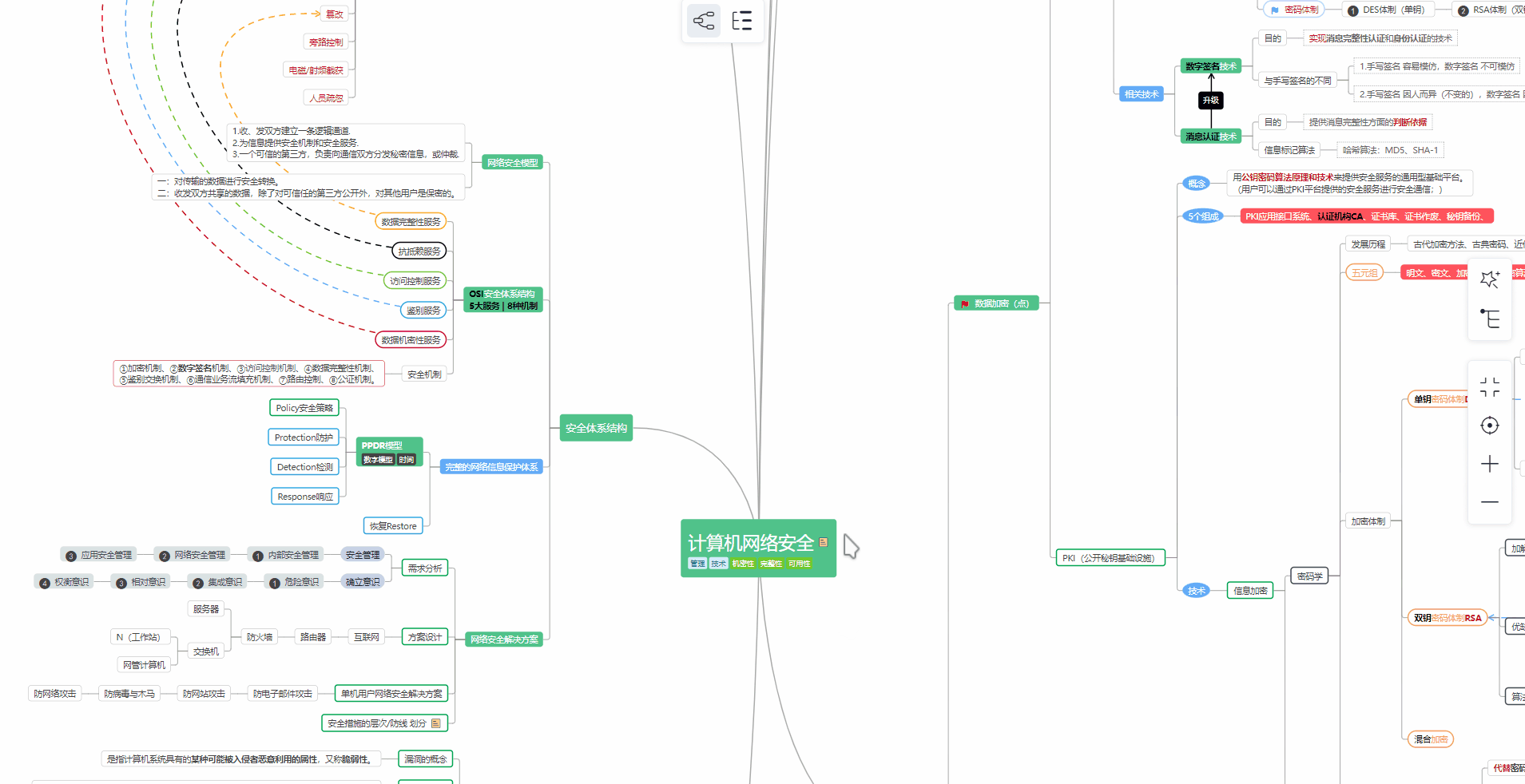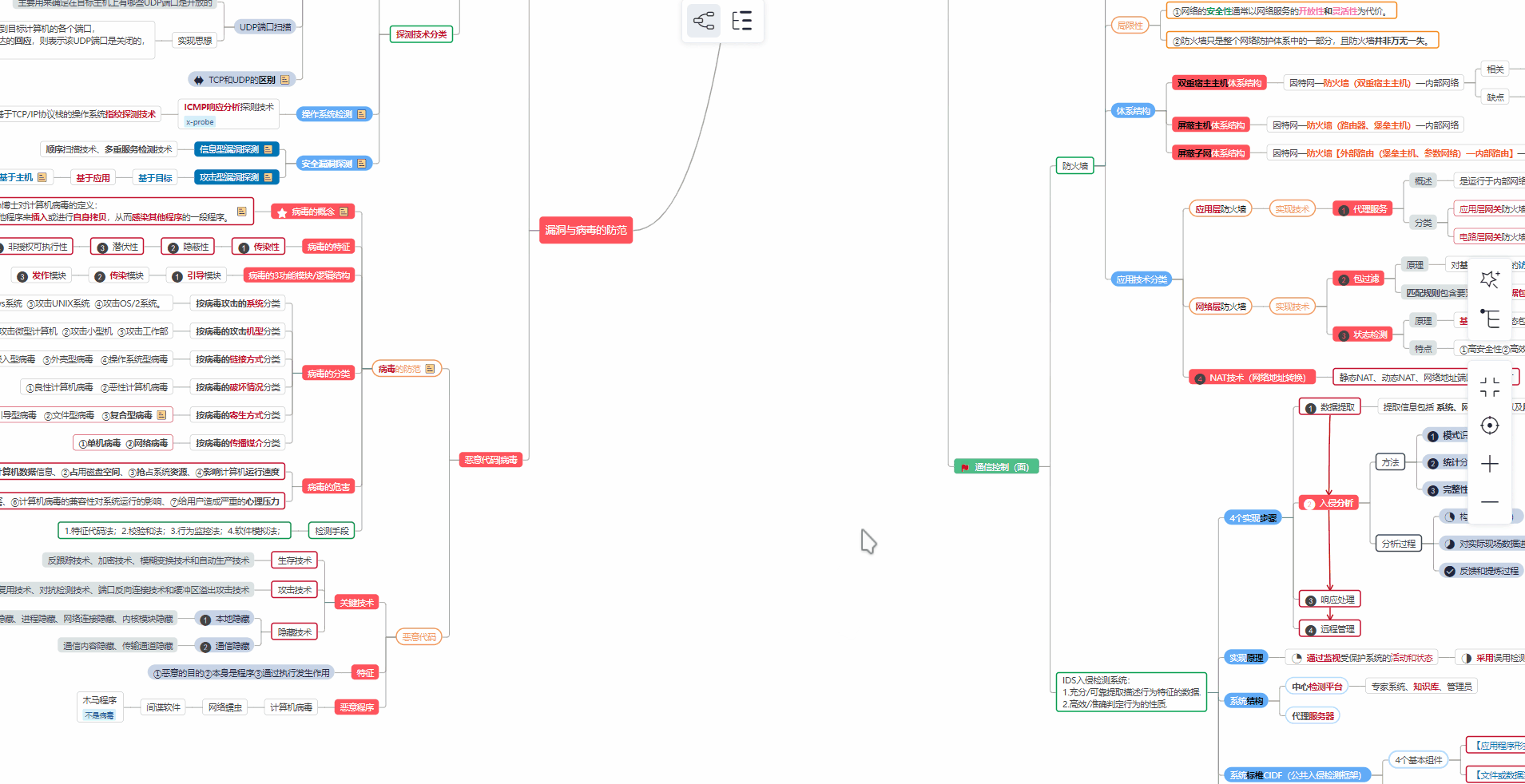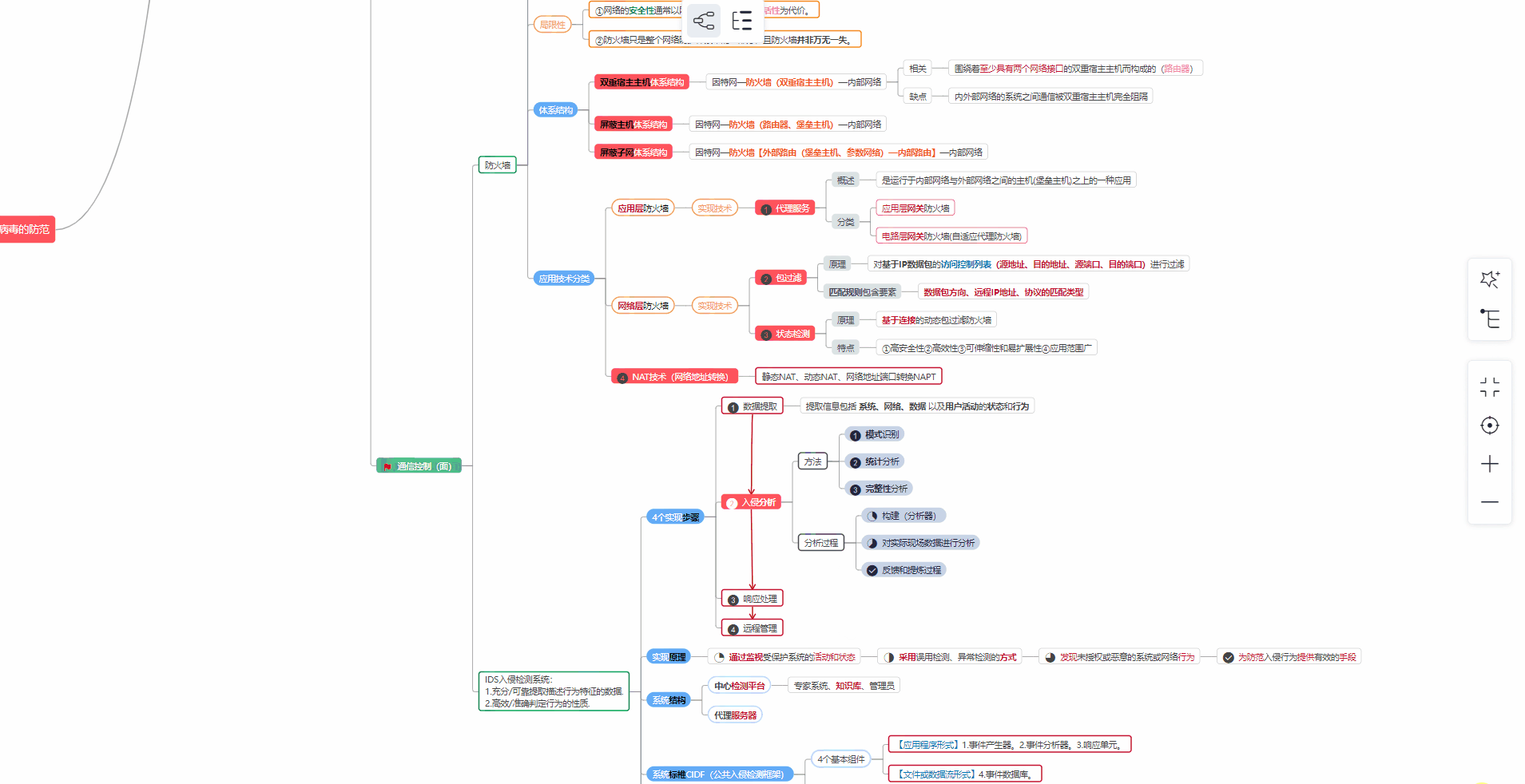
② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:

2️⃣视频配套工具&国内外网安书籍、文档
① 工具

② 视频
③ 书籍
资源较为敏感,未展示全面,需要的最下面获取

② 简历模板
因篇幅有限,资料较为敏感仅展示部分资料,添加上方即可获取👆
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









