







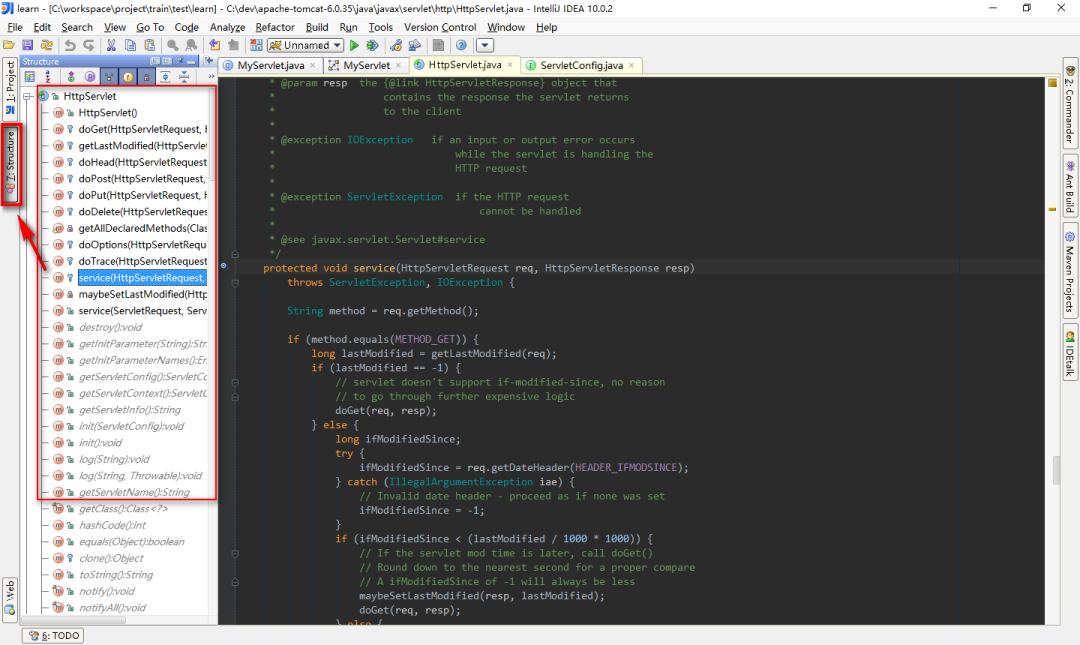
2.1 去掉不关心的类
得到的继承关系图形,有些并不是我们想去了解的,比如上图的Object和Serializable,我们只想关心Servlet重要的那几个继承关系,怎么办?
简单,删掉。点击选择你想要删除的类,然后直接使用键盘上的delete键就行了。清理其他类的关系后图形如下:

2.2 展示类的详细信息
有人说,诶,这怎么够呢,那继承下来的那些方法我也想看啊?简单,IDEA通通满足你。
在页面点击右键,选择 show categories,根据需要可以展开类中的属性、方法、构造方法等等。当然,第二种方法也可以直接使用上面的工具栏:
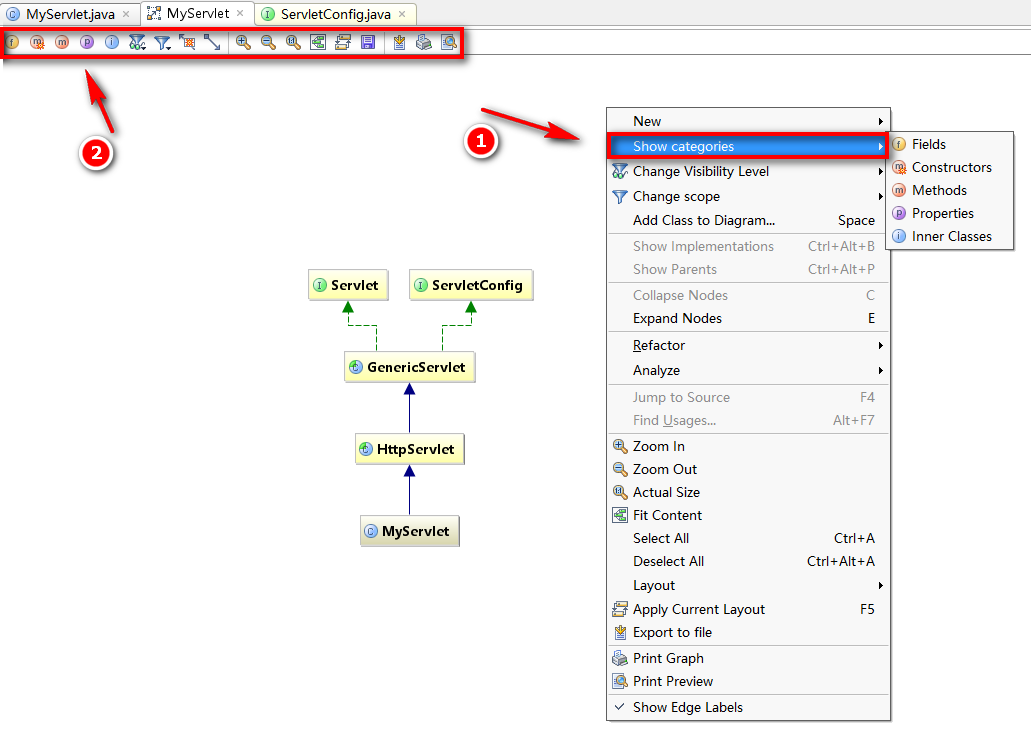
然后你就会得到:

什么,方法里你还想筛选,比如说想看protected权限及以上范围的?简单,右键选择 Change Visibility Level,根据需要调整即可。

什么,你嫌图形太小你看不清楚?IDEA也可以满足你,按住键盘的Alt,竟然出现了放大镜,惊不惊喜,意不意外?
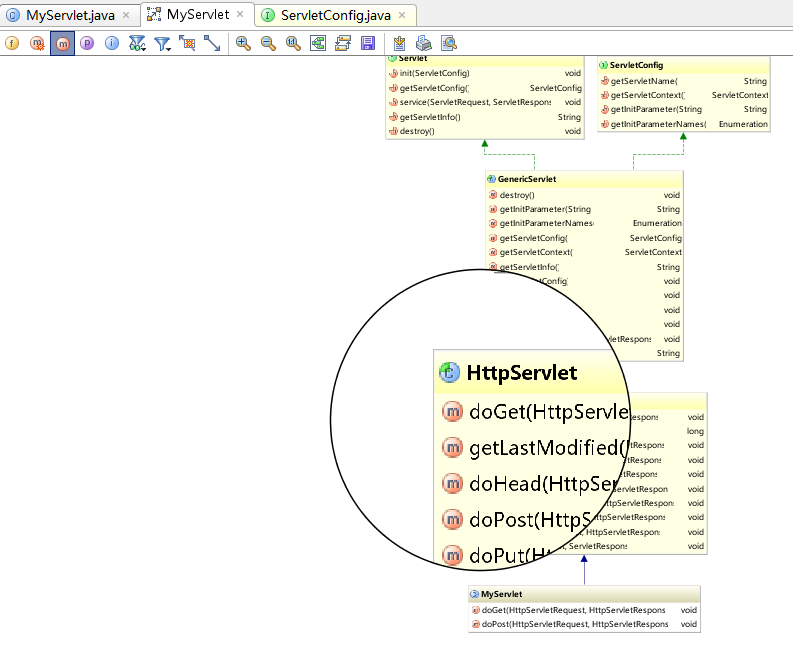
2.3 加入其他类到关系中来
当我们还需要查看其他类和当前类是否有继承上的关系的时候,我们可以选择加其加入到当前的继承关系图形中来。
在页面点击右键,选择 Add Class to Diagram,然后输入你想加入的类就可以了:
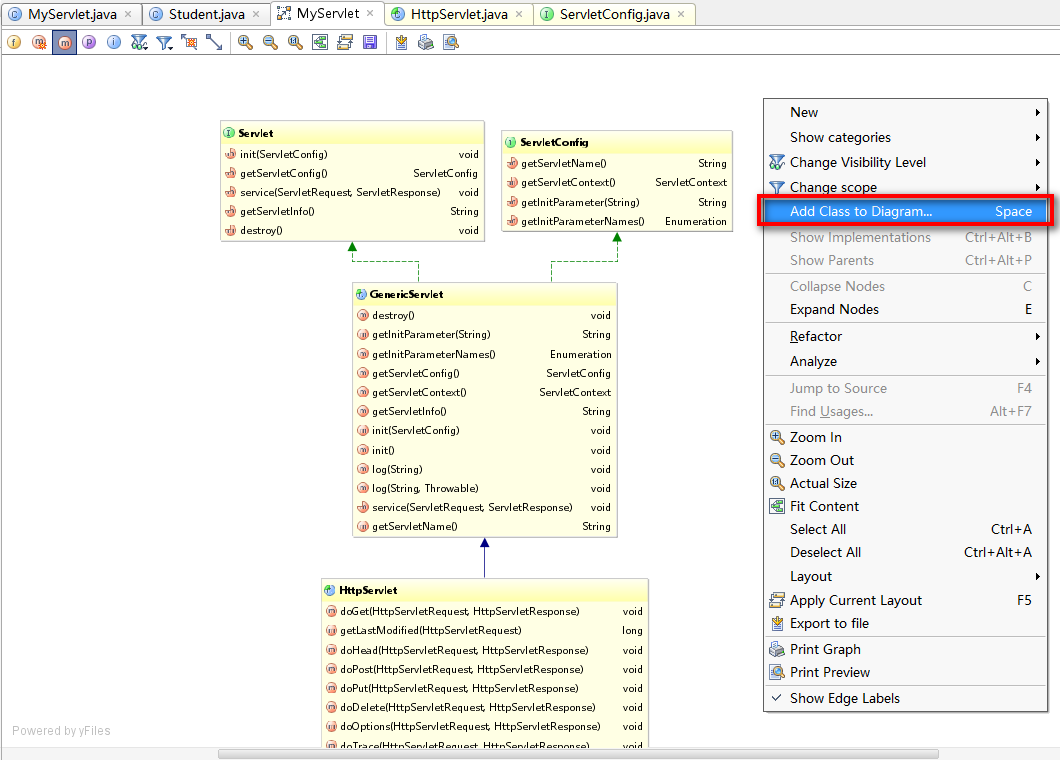
例如我们添加了一个Student类,如下图所示。好吧,并没有任何箭头,看来它和当前这几个类以及接口并没有发生什么不可描述的关系:

2.4 查看具体代码
如果你想查看某个类中,比如某个方法的具体源码,当然,不可能给你展现在图形上了,不然屏幕还不得撑炸?
但是可以利用图形,或者配合IDEA的structure方便快捷地进入某个类的源码进行查看。
双击某个类后,你就可以在其下的方法列表中游走,对于你想查看的方法,选中后点击右键,选择 Jump to Source:
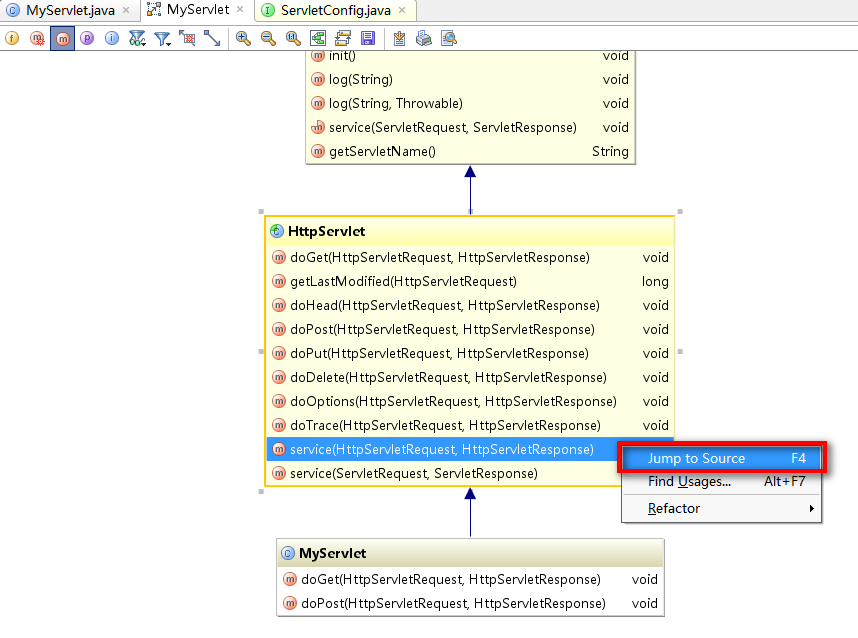

在进入某个类后,如果还想快速地查看该类的其他方法,还可以利用IDEA提供的structure功能:
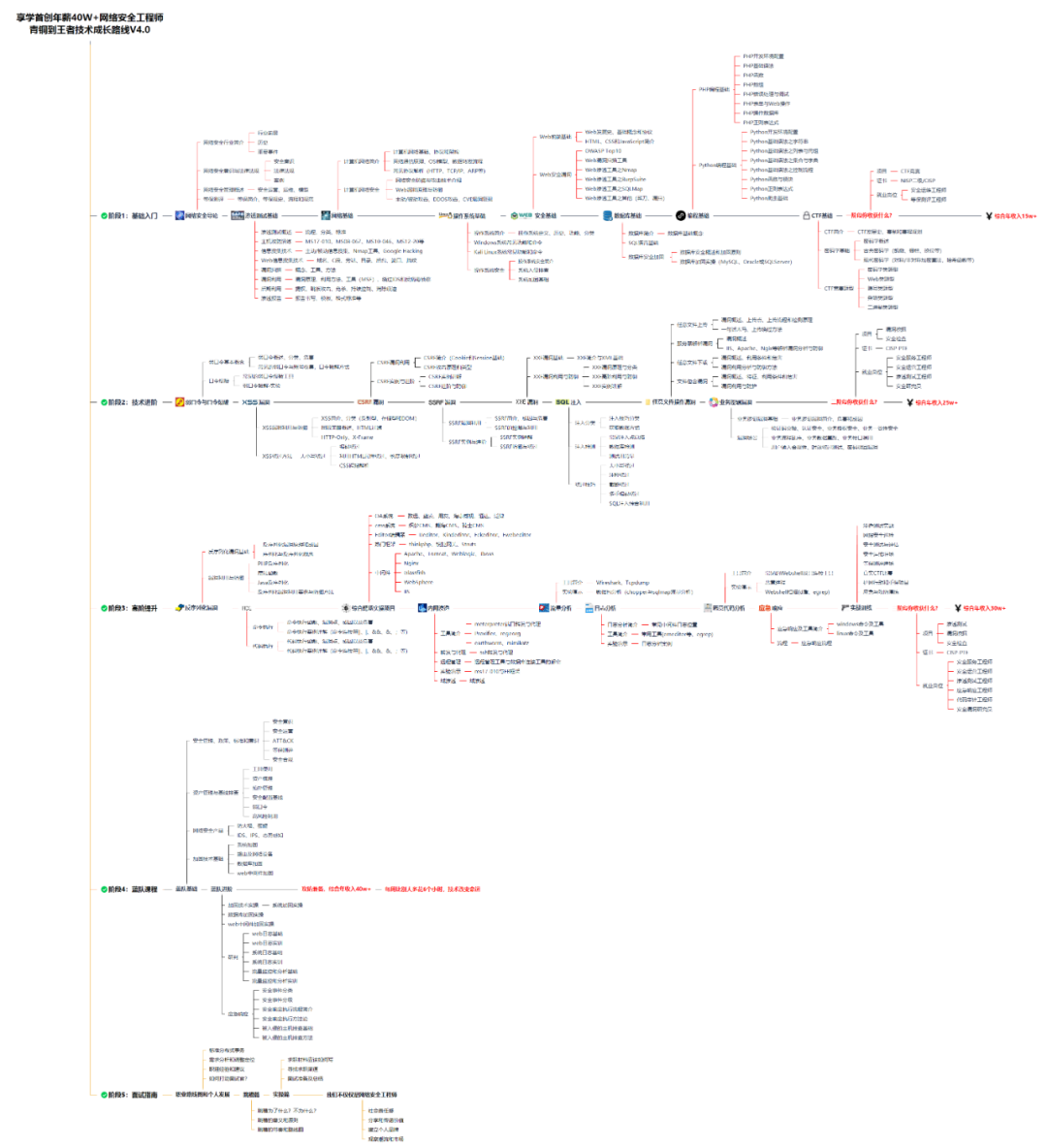
一、网安学习成长路线图
网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、网安视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
三、精品网安学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、网络安全源码合集+工具包
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、网络安全面试题
最后就是大家最关心的网络安全面试题板块
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2497
2497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









