







学习路线:
这个方向初期比较容易入门一些,掌握一些基本技术,拿起各种现成的工具就可以开黑了。不过,要想从脚本小子变成黑客大神,这个方向越往后,需要学习和掌握的东西就会越来越多以下是网络渗透需要学习的内容:
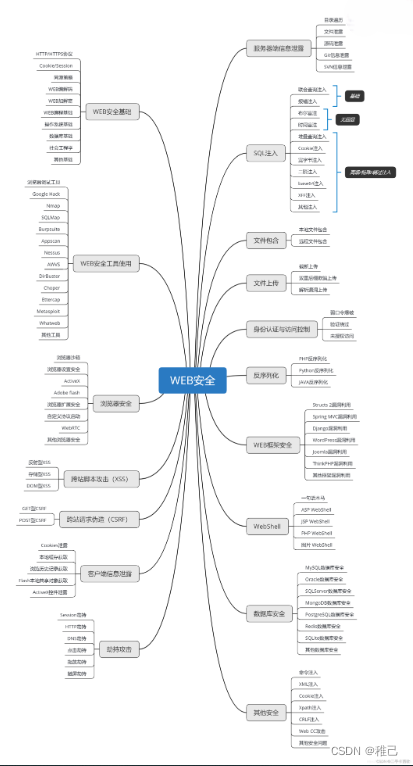
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
res = eval(“{‘name’: ‘Python’}”)
type(res)
| output:dict |
| --- |
#### str.capitalize()
`capitalize()` 返回字符串中的首字母大写,其余小写的字符串
cap_str = ‘python新视野’.capitalize()
cap_str
| output:‘Python新视野’ |
| --- |
#### str.center()
`center()` 返回一个指定宽度的居中字符串,左右部分空余部分用指定字符填充。
* `width`:长度
* `fillchar`:空余部分填充的字符,默认使用空格
center_str = ‘Python新视野’.center(15, “!”)
center_str
| output:’!!!Python新视野!!!’ |
| --- |
#### str.count()
`str.count(sub, start, end)` 返回 `sub` 在 `str` 中出现的次数,可以通过 `[start, end]` 指定范围,若不指定,则默认查找整个字符串。
* **sub:** 子串
* **start:** 开始的索引,默认为 0
* **end:** 结束的索引,默认为字符串的长度
name = ‘python python’
第一次按默认范围统计’p’出现的次数,
第二次指定start=1,即从第二个字符开始统计。
name.count(‘p’), name.count(‘p’, 1)
| output:(2, 1) |
| --- |
#### str.find() & str.rfind()
1️⃣ `find()` 从左往右扫描字符串,返回 `sub` 第一次出现的下标。可以通过 `[start, end]` 指定范围,若不指定,则默认查找整个字符串。如最后未找到字符串则返回 -1。
* **sub:** 子串
* **start:** 开始检索的位置,默认为 0
* **end:** 结束检索的位置,默认为字符串的长度
name = ‘Python’
第一次按默认范围查找’Py’第一次出现的下标
第二次指定start=1,即从第二个字符开始查找。
name.find(‘Py’), name.find(‘Py’, 1)
| output:(0, -1) |
| --- |
2️⃣ `rfind` 与 `find()` 的用法相似,只是**从右往左**开始扫描,即从字符串末尾向字符串首部扫描。
name = ‘Python’
name.rfind(‘Py’), name.rfind(‘Py’, 1)
| output:(0, -1) |
| --- |
#### str.index() & str.rindex()
1️⃣ `index()` 和 `find()` 用法相同,唯一的不同是如果找不到 `sub` 会报错。
**示例** 🅰️
name = ‘Python’
name.index(‘Py’, 0)
| output:0 |
| --- |
**示例** 🅱️
name = ‘Python’
name.index(‘Py’, 1)
| output:ValueError: substring not found |
| --- |
2️⃣ `rindex()` 和 `index()` 用法相同,不过是从**右边**开始查,它的查询与 `index()` 相同。
name = ‘Python’
name.rindex(‘Py’, 0)
| output:0 |
| --- |
#### str.isalnum()
`isalnum()` 判断字符串中是否所有字符都是字母(可以为汉字)或数字,是 `True` ,否 `False`,空字符串返回 `False`。
**示例** 🅰️
‘Python新视野’.isalnum()
| output:True |
| --- |
**示例** 🅱️
‘Python-sun’.isalnum()
| output:False |
| --- |
`'-'` 是符号,所以返回 `False`。
#### str.isalpha()
`isalpha()` 判断字符串中是否所有字符都是字母(可以为汉字),是 `True` ,否 `False`,空字符串返回 `False`。
**示例** 🅰️
‘Python新视野’.isalpha()
| output:True |
| --- |
**示例** 🅱️
‘123Python’.isalpha()
| output:False |
| --- |
其中包含了数字,返回 `False`
#### str.isdigit()
`isdigit()` 判断字符串中是否所有字符都是数字(Unicode数字,byte数字(单字节),全角数字(双字节),罗马数字),是 `True` ,否 `False`,空字符串返回 `False`。
**示例** 🅰️
‘四123’.isdigit()
| output:False |
| --- |
其中包含了汉字数字,返回 `False`
**示例** 🅱️
b’123’.isdigit()
| output:True |
| --- |
`byte` 数字返回 `True` 。
#### str.isspace()
字符串中只包含空格(`\n`、`\r`、`\f`、`\t`、`\v`),是 `True` ,否 `False`,空字符串返回 `False`。
| 符号 | 含义 |
| --- | --- |
| \n | 换行 |
| \r | 回车 |
| \f | 换页 |
| \t | 横向制表符 |
| \v | 纵向制表符 |
’ \n\r\f\t\v’.isspace()
| output:True |
| --- |
#### str.join()
`join(iterable)` 以指定字符串作为分隔符,将 `iterable` 中所有的元素(必须是字符串)合并为一个新的字符串。
‘,’.join([‘Python’, ‘Java’, ‘C’])
| output:‘Python,Java,C’ |
| --- |
#### str.ljust() & str.rjust()
1️⃣ `ljust()` 返回一个指定宽度左对齐的字符串
* `width`:长度
* `fillchar`:右部空余部分填充的字符,默认使用空格
ljust_str = ‘Python新视野’.ljust(15, “!”)
ljust_str
| output:‘Python新视野!!!!!!’ |
| --- |
2️⃣ `rjust()` 返回一个指定宽度右对齐的字符串,与 `ljust` 操作正好相反。
* `width`:长度
* `fillchar`:左部空余部分填充的字符,默认使用空格
rjust_str = ‘Python新视野’.rjust(15, “!”)
rjust_str
| output:’!!!!!!Python新视野’ |
| --- |
#### str.lower() & str.islower()
1️⃣ `lower()` 将指定字符串转换为小写。
lower_str = ‘Python新视野’.lower()
lower_str
| output:‘python新视野’ |
| --- |
2️⃣ `islower()` 判断字符串所有区分大小写的字符是否都是小写形式,是 `True` ,否 `False`,空字符串或字符串中没有区分大小写的字符返回 `False` 。
‘python-sun’.islower()
| output:True |
| --- |
`'python-sun'` 区分大小写的字符有 `'pythonsun'`,并且都是小写,所以返回 `True` 。
#### str.lstrip() & str.rstrip() & str.strip()
1️⃣ `lstrip()` 会在字符串左侧根据指定的字符进行截取,若未指定默认截取左侧空余(空格,\r,\n,\t等)部分。
name = ‘+++Python新视野+++’
name.lstrip(‘+’)
| output:‘Python新视野+++’ |
| --- |
2️⃣ `rstrip()` 与 `lstrip()` 用法相似,只是截取右侧的内容。
name = ‘+++Python新视野+++’
name.rstrip(‘+’)
| output:’+++Python新视野’ |
| --- |
3️⃣ `strip()` 实际是 `lstrip()` 与 `rstrip()` 的结合,它会截取字符串两边指定的字符。
name = ‘+++Python新视野+++’
name.strip(‘+’)
| output:‘Python新视野’ |
| --- |
#### str.split() & str.splitlines()
1️⃣ `str.split(sep=None, maxsplit=-1)` 使用 `sep` 作为分隔符将字符串进行分割,返回字符串中的单词列表。
* **seq:** 用来分割字符串的分隔符。`None`(默认值)表示根据任何空格进行分割,返回结果中不包含空格。
* **maxsplit:** 指定最大分割次数。-1(默认值)表示不限制。
split_str = ‘P y t h o n 新 视 野’
split_str.split(maxsplit=2)
| output:[‘P’, ‘y’, ‘t h o n 新 视 野’] |
| --- |
使用默认的空格进行分割,设置最大的分割次数为2
2️⃣ `str.splitlines` 返回字符串中的行列表,它按照行 `('\r',\n','\r\n')` 分隔,返回分隔后的列表。它只有一个参数 `keepends` 表示是否在结果中保留换行符,`False` (默认)不保留,`True` 保留。
**示例** 🅰️
split_str = ‘P\ny\r t h o n 新 视 野’
split_str.splitlines()
| output:[‘P’, ‘y’, ’ t h o n 新 视 野’] |
| --- |
**示例** 🅱️
split_str = ‘P\ny\r t h o n 新 视 野’
split_str.splitlines(keepends=True)
| output:[‘P\n’, ‘y\r’, ’ t h o n 新 视 野’] |
| --- |
#### str.startswith() & str.endswith
1️⃣ `startswith(prefix[, start[, end]])` 检查字符串是否是以指定子字符串 `substr` 开头,是 `True` ,否 `False`,空字符串会报错。如果指定 `start` 和 `end` ,则在指定范围内检查。
startswith_str = ‘Python新视野’
startswith_str.startswith(‘thon’, 2)
| output:True |
| --- |
从第 3 个字符开始检测
2️⃣ `str.endswith(suffix[, start[, end]])` 与 `startswith` 用法相同,不同之处是检查字符串是否以指定子字符串结尾,是 `True` ,否 `False`,空字符串会报错。
endswith_str = ‘Python新视野’
endswith_str.endswith(‘thon’, 0, 6)
| output:True |
| --- |
从第 1 个字符开始检测,到第 7 个字符结束(不包含第 7 个),注意这里的范围和字符串切片其实是一样的道理,都是前闭后开。
#### str.title() & str.istitle()
1️⃣ `title()` 返回字符串中每一个单词首字母大写。
title_str = ‘python新视野 python新视野’.title()
title_str
| output:‘Python新视野 Python新视野’ |
| --- |
2️⃣ `istitle()` 判断字符串是否满足每一个单词首字母大写,是 `True` ,否 `False`,空字符串返回 `False`。
'Abc Def '.istitle()
| output:True |
| --- |
#### str.upper() & str.isupper()
1️⃣ `upper()` 将指定字符串中字母转换为大写。
upper_str = ‘Python新视野’.upper()
upper_str
| output:‘PYTHON新视野’ |
| --- |
2️⃣ `isupper()` 判断字符串所有区分大小写的字符是否都是大写形式,是 `True` ,否 `False`,空字符串或字符串中没有区分大小写的字符返回 `False` 。
‘PYTHON-SUN’.isupper()
| output:True |
| --- |
---
### 列表操作
#### list()
`list()` 将可迭代对象转成列表。
**示例** 🅰️
list((0,1,2)) + list({0,1,2}) + list(‘012’)
| output:[0, 1, 2, 0, 1, 2, ‘0’, ‘1’, ‘2’] |
| --- |
将元组、集合、字符串转换成列表并通过运算符连接。
**示例** 🅱️
list(range(3))
| output:[0, 1, 2] |
| --- |
将可迭代对象转换成列表
#### list.append()
lst = [‘Python’, ‘Java’]
lst.append(‘C’)
lst
| output:[‘Python’, ‘Java’, ‘C’] |
| --- |
#### list.extend()
`extend()` 在列表的末尾添加可迭代对象(**列表、元组、字典、字符串**)中的元素来扩展列表。
1️⃣ **追加列表**
lst = [‘Python’, ‘Java’, ‘C’]
lst.extend([1, 2, 3])
lst
| output:[‘Python’, ‘Java’, ‘C’, 1, 2, 3] |
| --- |
2️⃣ **追加字符串**
lst = [‘Python’, ‘Java’, ‘C’]
lst.extend(‘123’)
lst
| output:[‘Python’, ‘Java’, ‘C’, ‘1’, ‘2’, ‘3’] |
| --- |
将字符串中的每一个字符当做一个元素追加到原列表末尾
3️⃣ **追加集合**
lst = [‘Python’, ‘Java’, ‘C’]
lst.extend({1,2,3})
lst
| output:[‘Python’, ‘Java’, ‘C’, 1, 2, 3] |
| --- |
4️⃣ **追加字典**
lst = [‘Python’, ‘Java’, ‘C’]
lst.extend({1: ‘b’, 2: ‘a’})
lst
| output:[‘Python’, ‘Java’, ‘C’, 1, 2] |
| --- |
只将字典的 key 值追加到原列表末尾
#### list.insert()
`insert(index, object)` 将指定对象插入到列表的 `index` 位置,原本 `index` 位置上及 `> index` 的元素的元素整体后移。
**示例** 🅰️
lst = [‘Python’, ‘Java’, ‘C’]
lst.insert(1, ‘C++’)
lst
| output:[‘Python’, ‘C++’, ‘Java’, ‘C’] |
| --- |
**示例** 🅱️
lst = [‘Python’, ‘Java’, ‘C’]
lst.insert(6, ‘C++’)
lst
| output:[‘Python’, ‘Java’, ‘C’, ‘C++’] |
| --- |
当 `index` 的值大于列表长度时,会在列表末尾添加。
#### list.pop()
`pop(index=-1)` 移除列表中指定位置元素(默认最后一个),并且返回移除元素的值。若指定的 `index` 值超过列表长度则会报错。
lst = [‘Python’, ‘Java’, ‘C’]
lst.pop(1), lst
| output:(‘Java’, [‘Python’, ‘C’]) |
| --- |
#### list.remove(元素)
`lst.remove(value)` 移除列表中第一次出现的 `value` ,无返回值,直接修改列表;如果 `value` 不在列表中则报错。
**示例** 🅰️
lst = [‘Python’, ‘Java’, ‘C’, ‘Python’]
lst.remove(‘Python’)
lst
| output:[‘Java’, ‘C’, ‘Python’] |
| --- |
只删除了第一次出现的 `Python`
**示例** 🅱️
lst = [‘Python’, ‘Java’, ‘C’, ‘Python’]
lst.remove(‘HTML’)
lst
| output:ValueError: list.remove(x): x not in list |
| --- |
`HTML` 不在列表中,发生错误
#### list.clear()
`list.clear()` 移除列表中所有的元素,无返回值。
lst = [‘Python’, ‘Java’, ‘C’]
lst.clear()
lst
| output:[] |
| --- |
#### list.index()
`index(value, start, stop)` 返回列表中查找的第一个与value匹配的元素下标,可通过 `[start, stop)` 指定查找范围。
**示例** 🅰️
lst = [‘Python’, ‘Java’, ‘C’,
‘Python’, ‘Python’]
lst.index(‘Python’)
| output:0 |
| --- |
不指定范围,在列表全部元素中查找
**示例** 🅱️
lst = [‘Python’, ‘Java’, ‘C’,
‘Python’, ‘Python’]
lst.index(‘Python’, 1, 3)
| output:ValueError: ‘Python’ is not in list |
| --- |
指定范围 [1, 3) ,即在[‘Java’, ‘C’]中查找 `Python` 很明显不存在,发生报错
#### list.count()
`count(value)` 返回 `value` 在列表中出现的次数。若未在列表中找到 `value` 则返回 0 。
**示例** 🅰️
lst = [‘Python’, ‘Java’, ‘C’,
‘Python’, ‘Python’]
lst.count(‘Python’)
| output:3 |
| --- |
**示例** 🅱️
lst = [‘Python’, ‘Java’, ‘C’,
‘Python’, ‘Python’]
lst.count(‘Py’)
| output:0 |
| --- |
列表中无元素 `'Py'`,返回 0 。
#### list.reverse()
`reverse()` 将列表逆序排列,无返回值。
lst = [1, 5, 9, 2]
lst.reverse()
lst
| output:[2, 9, 5, 1] |
| --- |
#### list.sort()
`sort()` 对列表进行指定方式的排序,修改原列表,该排序是稳定的(即两个相等元素的顺序不会因为排序而改变)。
* **key:** 指定可迭代对象中的每一个元素来按照该函数进行排序
* **reverse:** `False` 为升序,`True` 为降序。
**示例** 🅰️
lst = [1, 5, 9, 2]
lst.sort()
lst
| output:[1, 2, 5, 9] |
| --- |
**示例** 🅱️
lst = [‘Python’, ‘C’, ‘Java’]
lst.sort(key=lambda x:len(x), reverse=False)
lst
| output:[‘C’, ‘Java’, ‘Python’] |
| --- |
指定 `key` 计算列表中每个元素的长度,并按照长度进行升序排序
#### list.copy()
`copy()` 对列表进行拷贝,返回新生成的列表,这里的拷贝是**浅拷贝**,下面会说明为什么特意说它是**浅拷贝**。
**示例** 🅰️
lst = [[1,2,3], ‘a’ ,‘b’]
lst_copy = lst.copy()
lst_copy.pop()
lst, lst_copy
| output:([[1, 2, 3], ‘a’, ‘b’], [[1, 2, 3], ‘a’]) |
| --- |
对 `lst` 进行 `copy` ,然后删除列表 `lst_copy` 的最后一个元素,此时的 `lst` 的最后一个元素并未被删除,说明两个列表指向的地址确实不一样。
**示例** 🅱️
lst = [[1,2,3], ‘a’ ,‘b’]
lst_copy = lst.copy()
lst_copy[0].pop()
lst_copy.pop()
lst, lst_copy
| output:([[1, 2], ‘a’, ‘b’], [[1, 2], ‘a’, ‘b’]) |
| --- |
这里执行和上一个示例一样的操作,只是这次再删除一个数据,即列表嵌套的子列表中最后一个元素,观察结果,发现这时不仅仅是 `lst_copy` 的列表发生改变,原列表 `lst` 中嵌套的字列表也发生了改变。说明两个列表指向的地址不一样,但子列表中指向的地址是相同的。
#### 扩展:直接赋值、浅拷贝、深拷贝
(1)直接赋值,传递对象的引用而已。原始列表改变,被赋值的对象也会做相同改变。
(2)浅拷贝,没有拷贝子对象,所以原始数据子对象改变,拷贝的子对象也会发生变化。
(3)深拷贝,包含对象里面的子对象的拷贝,所以原始对象的改变不会造成深拷贝里任何子元素的改变,二者完全独立。
1️⃣ 先看直接赋值
lst = [1,2,3,[1,2]]
list1 = lst
–直接赋值–
lst.append(‘a’)
list1[3].append(‘b’)
print(lst,‘地址:’,id(lst))
print(list1,‘地址:’,id(list1))
[1, 2, 3, [1, 2, ‘b’], ‘a’] 地址: 2112498512768
[1, 2, 3, [1, 2, ‘b’], ‘a’] 地址: 2112498512768
无论 `lst` 还是 `list1` 发生改变,二者都会受到影响。
2️⃣ 浅拷贝需要用到 `copy` 模块,或者用 `list.copy()` 效果一样
from copy import copy
lst = [1, 2, 3, [1, 2]]
list2 = copy(lst)
–浅拷贝–
lst.append(‘a’)
list2[3].append(‘b’)
print(lst,‘地址:’,id(lst))
print(list2,‘地址:’,id(list2))
[1, 2, 3, [1, 2, ‘b’], ‘a’] 地址: 2112501949184
[1, 2, 3, [1, 2, ‘b’]] 地址: 2112495897728
`lst` 与 `list2` 地址不同,但子列表的地址仍是相同的,修改子列表中的元素时,二者都会受到影响。
3️⃣ 深拷贝需要用到 `copy` 模块中的 `deepcopy` ,此时两个列表完全独立。
from copy import deepcopy
lst = [1, 2, 3, [1, 2]]
list3 = deepcopy(lst)
–深拷贝–
lst.append(‘a’)
list3[3].append(‘b’)
print(lst,‘地址:’,id(lst))
print(list3,‘地址:’,id(list3))
[1, 2, 3, [1, 2], ‘a’] 地址: 2112506144192
[1, 2, 3, [1, 2, ‘b’]] 地址: 2112499460224
根据结果可以看到修改子列表中的值时,原列表未发生改变。
---
### 元组
#### tuple()
`tuple()` 将可迭代对象转换成元组。
tuple([0,1,2]) + tuple(range(3)) + tuple({0,1,2}) + tuple(‘012’)
| output:(0, 1, 2, 0, 1, 2, 0, 1, 2, ‘0’, ‘1’, ‘2’) |
| --- |
将可迭代对象转换成列表并通过运算符连接。
---
### 字典
#### dict.clear()
`clear()` 清除字典的所有内容。
dic = {‘CSDN’: ‘Dream丶killer’,
‘公众号’: ‘Python新视野’}
dic.clear()
dic
| output:{} |
| --- |
#### dict.fromkeys()
`fromkeys()` 创建一个新字典,以序列 `iterable` 中元素做字典的键,`value` 为字典所有键对应的初始值。
* **iterable:** 可迭代对象,新字典的键。
* **value:** 可选参数, 设置键序列对应的值,默认为 `None`。
dict.fromkeys([‘CSDN’, ‘公众号’],
‘Python新视野’)
| output:{‘CSDN’: ‘Python新视野’, ‘公众号’: ‘Python新视野’} |
| --- |
#### dict.get()
`get(key, default=None)` 根据指定的 `key` 值查找,如果 `key` 在字典中,则返回 `key` 的值,否则为 `None`。
**示例** 🅰️
dic = {‘CSDN’: ‘Dream丶killer’,
‘公众号’: ‘Python新视野’}
dic.get(‘CSDN’)
| output:‘Dream丶killer’ |
| --- |
**示例** 🅱️
dic = {‘CSDN’: ‘Dream丶killer’,
‘公众号’: ‘Python新视野’}
print(dic.get(‘微信’))
| output:None |
| --- |
字典中没有 `key` 等于 `'微信'`,返回 `None`,jupyter notebook 对于 `None` 如果不加 `print` 默认不输出,所以这里加上`print` 来打印结果
#### dict.items()
`items()` 返回视图对象,是一个可遍历的 `key/value` 对,可以使用 `list()` 将其转换为列表。
**示例** 🅰️
dic = {‘CSDN’: ‘Dream丶killer’,
‘公众号’: ‘Python新视野’}
list(dic.items())
| output:[(‘CSDN’, ‘Dream丶killer’), (‘公众号’, ‘Python新视野’)] |
| --- |
**示例** 🅱️
dic = {‘CSDN’: ‘Dream丶killer’,
‘公众号’: ‘Python新视野’}
for key, value in dic.items():
print('key: ', key, 'value: ', value)
key: CSDN value: Dream丶killer
key: 公众号 value: Python新视野
#### dict.keys()
`keys()` 返回一个视图对象,值为字典的 `key` ,可将其转换成列表。
dic = {‘CSDN’: ‘Dream丶killer’,
‘公众号’: ‘Python新视野’}
dic.keys()
| output:dict\_keys([‘CSDN’, ‘公众号’]) |
| --- |
#### dict.setdefault()
`setdefault(key, default=None)` 如果键不在字典中,则插入值为 `None` 的键。如果键在字典中,则返回键的值。
**示例** 🅰️
dic = {‘CSDN’: ‘Dream丶killer’,
‘公众号’: ‘Python新视野’}
dic.setdefault(‘CSDN’, ‘python-sun’)
| output:‘Dream丶killer’ |
| --- |
字典中有 `CSDN` 这个 `key` 值,返回 `CSDN` 对应的值,不需要插入
**示例** 🅱️
dic = {‘CSDN’: ‘Dream丶killer’,
‘公众号’: ‘Python新视野’}
dic.setdefault(‘微信’, ‘python-sun’)
dic
| output:{‘CSDN’: ‘Dream丶killer’, ‘公众号’: ‘Python新视野’, ‘微信’: ‘python-sun’} |
| --- |
字典中没有 `微信` 这个 `key` 值,返回 `None` ,执行插入,并根据设置的参数 `python-sun` 来进行赋值。
#### dict.update()
`dict.update(dict1)` 把字典 `dict1` 的 `key/value` 对更新到 `dict` 里,当 `dict1` 的 `key` 出现在 `dict` 中则修改 `dict` 中的值,如果 `key` 没有出现在 `dict` 中,则添加这一对 `key/value` 。
### 给大家的福利
**零基础入门**
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









