







1.如果mysql安装目录下,有后缀名为:.ini的配置文件,复制一份,修改为my.ini
2.如果mysql安装目录下,没有.ini文件,则创建一个普通txt文件,修改为:my.ini(注意,修改前应该可以看到.txt)
3.修改配置文件如下:
[client]
default-character-set=utf8
[mysqld]
character-set-server=utf8
[mysql]
default-character-set=utf8
//重启mysql
//修改后,查看编码,正确的应该为:
mysql> show variables like “char%”;
±-------------------------±--------------------------------------------------------+
| Variable_name | Value |
±-------------------------±--------------------------------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | C:\Program Files\MySQL\MySQL Server 5.7\share\charsets\ |
±-------------------------±--------------------------------------------------------+
8 rows in set, 1 warning (0.00 sec)
如果不修改编码格式,mysql可能无法插入或者查询汉字字段,即便在mysql中可以使用汉字,在java程序中,也可能出现乱码。
====================================================================
//查询系统的数据库
mysql> show databases;
±-------------------+
| Database |
±-------------------+
| information_schema | //information_schema 数据字典。从此可以很简单的用SQL语句来检索需要的系统元数据了
| mysql | //存储了系统的用户权限信息及帮助信息。
| performance_schema | //performance_schema 性能字典。 但是这个字典比较专业,非专业人员勿动
| sakila | //数据库设计官方样例
| sys | // sys系统数据库。 sys数据库里面包含了一系列的存储过程、自定义函数以及视图
| test | //测试库可以删除 可以删除
| world | //mysql自带的测试数据库 可以删除
±-------------------+
6 rows in set (0.00 sec)
//[ ] 在计算机帮助信息中,方括号内内容,一般指可选,即:选择丰富操作内涵,不选择使用基本操作
//1.创建数据库 create database[ if not exists] 数据库名 数据库选项
mysql> create database demo;
Query OK, 1 row affected (0.00 sec)
//2.删除数据库 drop database[ if exists] 数据库名
mysql> drop database if exists demo;
Query OK, 0 rows affected (0.00 sec)
//3.库信息修改
alter database 库名 选项信息
//修改数据库名称
不建议操作,可能会影响数据,有些管理工具提供数据库改名,其做法多是:创建新库,复制数据,删除旧库。
//4.显示数据库信息
mysql> show create database demo;
±---------±--------------------------------------------------------------+
| Database | Create Database |
±---------±--------------------------------------------------------------+
| demo | CREATE DATABASE demo /*!40100 DEFAULT CHARACTER SET utf8 */ |
±---------±--------------------------------------------------------------+
1 row in set (0.00 sec)
//5.选中要操作的数据库
use demo
MySql数据库管理系统下面,可以操作数据库,而操作表格,应该选中某一数据库
如:不选中数据库,进行表操作,会出现如下错误:
mysql> show tables;
ERROR 1046 (3D000): No database selected
//1.选中数据库 这个操作的特殊之处在于,分号可以省略。
mysql> use demo
Database changed
//2.创建表 create [temporary] table[ if not exists] [库名.]表名 ( 表的结构定义 )[ 表选项]
//对于字段的定义:字段名 数据类型 [NOT NULL | NULL] [DEFAULT default_value] [AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY] [COMMENT ‘string’]
mysql> create table if not exists t_user (
-> id int,
-> name varchar(20),
-> address varchar(20));
Query OK, 0 rows affected (0.03 sec)
//-- Normal Format, NF 建表基本规范
// - 每个表保存一个实体信息
// - 每个具有一个ID字段作为主键
// - ID主键 + 原子表
//3.1.查看表结构(掌握)
mysql> show create table t_user;
//3.2.查看表结构(重点掌握)
mysql> desc t_user;
±--------±------------±-----±----±--------±------+
| Field | Type | Null | Key | Default | Extra |
±--------±------------±-----±----±--------±------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
| address | varchar(20) | YES | | NULL | |
±--------±------------±-----±----±--------±------+
3 rows in set (0.00 sec)
//3.3.查看表结构(了解)
SHOW TABLE STATUS like “t_user”;
//4.删除表
mysql> drop table if exists t_user;
Query OK, 0 rows affected (0.02 sec)
//5.插入数据
mysql> insert into t_user values (1,“张三”,“河北邯郸”);
mysql> insert into t_user (id ,name) values (2,“李四”);
//6.查询表格中数据
mysql> select * from t_user;
±-----±-------±-------------+
| id | name | address |
±-----±-------±-------------+
| 1 | 张三 | 河北邯郸 |
| 2 | 李四 | NULL |
±-----±-------±-------------+
2 rows in set (0.00 sec)
//表别名,表连接时候会用
mysql> select u.* from t_user u;
±-----±-------±-------------+
| id | name | address |
±-----±-------±-------------+
| 1 | 张三 | 河北邯郸 |
| 2 | 李四 | NULL |
±-----±-------±-------------+
2 rows in set (0.00 sec)
mysql> select id,name from t_user;
±-----±-------+
| id | name |
±-----±-------+
| 1 | 张三 |
| 2 | 李四 |
±-----±-------+
2 rows in set (0.00 sec)
//7.删除数据
mysql> delete from t_user; //删除全部数据,谨慎使用
mysql> delete from t_user where id=2 //主键删除,推荐采用
//8.修改表数据
mysql> update t_user set name=“lucy”; //修改全部字段name为lucy一般不用
mysql> update t_user set name=“lucy” where id=1; //主键修改,一般采用
mysql> update t_user set name=“王五”,address=“USA”; //多字段修改
---------数值型:整型 ----------
tinyint 1字节 -128 ~ 127 无符号位:0 ~ 255
smallint 2字节 -32768 ~ 32767
mediumint 3字节 -8388608 ~ 8388607
int 4字节
bigint 8字节
int(M) M表示总位数
// - 默认存在符号位,可用unsigned 属性修改
//- 0补填,zerofill 例:int(5) 插入一个数’123’,补填后为’00123’
// MySQL没有布尔类型,通过整型0和1表示。常用bit表示布尔型。 - 1表示bool值真,0表示bool值假。
--------- 数值型:浮点型 ----------
float(单精度) 4字节
double(双精度) 8字节
//浮点型支持符号位 unsigned 属性,也支持显示宽度 zerofill 属性。 不同于整型的前补0,前后均会补填0.
//定义浮点型时,需指定总位数和小数位数 float(M, D) double(M, D) M表示总位数,D表示小数位数。
--------- 数值型:定点数 ----------
decimal //类型是适合财务和货币计算的
decimal(M, D) // M表示总位数,D表示小数位数。
//保存一个精确的数值,不会发生数据的改变,不同于浮点数的四舍五入。
// 将浮点数转换为字符串来保存,每9位数字保存为4个字节。
//float f = 345.98756f;–结果显示为345.9876,只显示7个有效位,对最后一位数四舍五入。
//double d=345.975423578631442d;–结果显示为345.975423578631,只显示15个有效位,对最后一位四舍五入。
//float和double的相乘操作,数字溢出不会报错,会有精度的损失。
//decimal dd=345.545454879…–可以支持28位,对最后一位四舍五入。
--------- 字符串类型:char\varchar\text ----------
char 定长字符串,速度快,但浪费空间
varchar 变长字符串,速度慢,但节省空间
//M表示能存储的最大长度,此长度是字符数,非字节数。 不同的编码,所占用的空间不同。
//char,最多255个字符,与编码无关。 varchar,最多65535字符,与编码有关(注意这里是有关,整体最大长度是65,532字节)。
text (字符字符串)//tinytext, text, mediumtext, longtext
---------字符串类型:二进制字符blob, textbinary, varbinary ----------
binary, varbinary //类似于char和varchar,用于保存二进制字符串,也就是保存字节字符串而非字符字符串。
blob 二进制字符串(字节字符串)
tinyblob, blob, mediumblob, longblob
//char, varchar, text 对应 binary, varbinary, blob.
---------日期时间型 ----------
datetime 8字节 日期及时间 1000-01-01 00:00:00 到 9999-12-31 23:59:59
date 3字节 日期 1000-01-01 到 9999-12-31
timestamp 4字节 时间戳 1970-01-01 00:00:00 到 2038-01-19 03:14:07
time 3字节 时间 -838:59:59 到 838:59:59
year 1字节 年份 1901 - 2155
-----------1. 主键-------------------
//用 primary key 标识。
mysql> create table t_user (
-> id int primary key auto_increment,
-> name varchar(20) not null
-> );
//主键 不为空 唯一 任何一个表格都应该有主键
mysql> create table t_user (
-> id int auto_increment,
-> name varchar(20) not null,
-> primary key(id)
-> );
//组合主键声明 成绩表以学号和课程号为组合主键
mysql> create table course(
-> stu_id int ,
-> cou_id int,
-> score float(5,2),
-> primary key(stu_id,cou_id)
-> );
-----------2. unique(唯一约束)-------------------
mysql> create table t_user (
-> id int primary key auto_increment,
-> name char(10) not null unique);
-----------3. null 约束-------------------
//null不是数据类型,是列的一个属性。
//表示当前列是否可以为null,表示什么都没有。
//null, 允许为空。默认。
//not null, 不允许为空。
insert into tab values (null, ‘val’);
//-- 此时表示将第一个字段的值设为null, 取决于该字段是否允许为null
-----------4. default 默认值属性-------------------
mysql> create table t_user (
-> id int primary key auto_increment,
-> address varchar(20) default “安徽” );
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t_user (id) values (null);
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_user;
±—±--------+
| id | address |
±—±--------+
| 1 | 安徽 |
±—±--------+
1 row in set (0.00 sec)
// create table tab ( add_time timestamp default current_timestamp );
// 表示将当前时间的时间戳设为默认值。
-----------5. auto_increment 自动增长约束-------------------
//自动增长必须为索引(主键或unique)
//只能存在一个字段为自动增长。
//默认为1开始自动增长。可以通过表属性 auto_increment = x进行设置,或 alter table tbl auto_increment = x;
-----------6. comment 注释-------------------
mysql> create table t_user ( id int ) comment ‘这是一点注释’;
Query OK, 0 rows affected (0.02 sec)
mysql> show create table t_user;
±-------±---------------------------------------------------
| Table | Create Table
±-------±---------------------------------------------------
| t_user | CREATE TABLE t_user (
id int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=‘这是一点注释’
±-------±---------------------------------------------------
1 row in set (0.00 sec)
-----------7. foreign key 外键约束-------------------
//用于限制主表与从表数据完整性。
create table t_user(
id int primary key auto_increment,
name char(10) not null);
Query OK, 0 rows affected (0.01 sec)
create table t_order(
id int primary key auto_increment,
u_id int not null,
createtime datetime,
foreign key(id) references t_user(id));
Query OK, 0 rows affected (0.02 sec)
//alter table t1 add constraint t1_t2_fk foreign key (t1_id) references t2(id);
// – 将表t1的t1_id外键关联到表t2的id字段。
//存在外键的表,称之为从表(子表),外键指向的表,称之为主表(父表)。
//外键只被InnoDB存储引擎所支持。其他引擎是不支持的。
create table stu (id int primary key auto_increment,name char(10));
//添加字段 sex bit not null
alter table stu add sex bit not null;
//删除字段 name
alter table stu drop name;
//修改字段 将sex 字段名 修改为 xingbie 可以为空
alter table stu change sex xingbie bit null;
//修改字段 将xingbie字段修改为类型 int 不为空;
alter table stu change xingbie xingbie int not null;
alter table stu change name name char(10) default “lucy”;
//添加删除自增
alter table stu change id id int;
//删除主键约束 (删除自增后才可以删除主键)
alter table stu drop primary key;
//添加主键
alter table stu change id id int primary key;
alter table stu add constraint primary key(id);
//添加外键
alter table score2 add constraint sc_stu_fk foreign key(s_id) references stu(id);
//删除外键
//如果不知道外键的名字,需要用show create table table_name 查找外键名称
alter table score2 drop foreign key sc_stu_fk;
==================================================================
1.创建student和score表
CREATE TABLE student (
id INT(10) PRIMARY KEY ,
name VARCHAR(20) NOT NULL ,
sex VARCHAR(4) ,
birth YEAR,
department VARCHAR(20) ,
address VARCHAR(50)
);
创建score表。SQL代码如下:
CREATE TABLE score (
id INT(10) PRIMARY KEY AUTO_INCREMENT ,
stu_id INT(10) NOT NULL ,
c_name VARCHAR(20) ,
grade INT(10)
);
ysql> alter table score add constraint foreign key(stu_id) references student(id);
);
向student表插入记录的INSERT语句如下:
INSERT INTO student VALUES( 901,‘张老大’, ‘男’,1985,‘计算机系’, ‘北京市海淀区’);
INSERT INTO student VALUES( 902,‘张老二’, ‘男’,1986,‘中文系’, ‘北京市昌平区’);
INSERT INTO student VALUES( 903,‘张三’, ‘女’,1990,‘中文系’, ‘湖南省永州市’);
INSERT INTO student VALUES( 904,‘李四’, ‘男’,1990,‘英语系’, ‘辽宁省阜新市’);
INSERT INTO student VALUES( 905,‘王五’, ‘女’,1991,‘英语系’, ‘福建省厦门市’);
INSERT INTO student VALUES( 906,‘王六’, ‘男’,1988,‘计算机系’, ‘湖南省衡阳市’);
向score表插入记录的INSERT语句如下:
INSERT INTO score VALUES(NULL,901, ‘计算机’,98);
INSERT INTO score VALUES(NULL,901, ‘英语’, 80);
INSERT INTO score VALUES(NULL,902, ‘计算机’,65);
INSERT INTO score VALUES(NULL,902, ‘中文’,88);
INSERT INTO score VALUES(NULL,903, ‘中文’,95);
INSERT INTO score VALUES(NULL,904, ‘计算机’,70);
INSERT INTO score VALUES(NULL,904, ‘英语’,92);
INSERT INTO score VALUES(NULL,905, ‘英语’,94);
INSERT INTO score VALUES(NULL,906, ‘计算机’,90);
INSERT INTO score VALUES(NULL,906, ‘英语’,85);
1、where 型查询子句
select * from student where sex=“男”;
select * from student where sex=“男” and birth=1985;
select * from student where birth >=1990;
select * from student where birth between 1990 and 1995; //[1990,1995]
select * from student where birth =1990 or birth=1991;
select * from student where birth in (1990,1991,1995);
select *from student where name like “张%”;
select *from student where name like “张_”;
select *from student where name like “%张%”;
select * from student where birth&2=1; //年龄是奇数
2、Order by 查询
select *from student order by birth; //默认升序排列
select *from student order by birth asc;
select *from student order by birth desc;
select *from student order by birth desc,name asc;
3.limit 子句
//查询 年龄最小的学生 select * from student order by birth desc limit M,N;
//M指偏移量 N指 查询数量
select * from student order by birth desc limit 0,1;
//查询年龄最大的 3个
select * from student order by birth asc limit 0,5;
//查询第5名到第十名
select * from student order by birth asc limit 5,5;
//limit的分页应用 select * from score limit M,N;
//参数1 页 码 index
//参数2 页面容量 size()
//注意 sql端不支持limit后参数运算
select * from score limit (index-1)*size,size;
select * from score limit (3-1)*5,5;
//java模拟
List getScores(int index,int size){
String sql=“select * from score limit ?,?;”
psmt.set(1,(index-1)*size)
psmt.set(2,size);
}
4.group by
//聚合函数 一般无法跟其他字段一起查询
//全班最高分
select max(grade) from score;
//全班平均分
select avg(grade) from score;
//全班最低分
select min(grade) from score;
//统计个数
select count(*) from score;
select count(id) from score;
//查询每个专业的最高分、平均分、最低分
select c_name,avg(grade) from score group by c_name ;
select c_name,max(grade) from score group by c_name ;
select c_name,min(grade) from score group by c_name ;
5、having子句
//查询成绩大于平均分的成绩表
select * from score where grade > (select avg(grade) from score);
//alter table score add common int ;
//update score set common=90;
//查询成绩表加成绩合计
select * ,(grade+common) from score;
//查询成绩大于成绩合计平均((grade+common)/2)分的同学
select * ,(grade+common)/2 from score where grade > (grade+common)/2;
select * ,(grade+common)/2 as avgs from score having grade > avgs;
//INSERT INTO student VALUES( 111,‘王五’, ‘女’,1991,‘英语系’, ‘福建省厦门市’);
//INSERT INTO student VALUES( 112,‘王六’, ‘男’,1988,‘计算机系’, ‘湖南省衡阳市’);
//统计学生大于2个的专业
select department,count(*) as countd from student group by department having countd>2;
select department,count() as countd from student group by department having count()>2;
//where后面无法使用聚合函数 也无法引用前面的运算结果,此时应该用having
1、union
CREATE TABLE score2 (
id INT(10) NOT NULL UNIQUE PRIMARY KEY AUTO_INCREMENT ,
stu_id INT(10) NOT NULL ,
c_name VARCHAR(20) ,
grade INT(10)
);
INSERT INTO score2 VALUES(NULL,901, ‘计算机’,98);
INSERT INTO score2 VALUES(NULL,901, ‘英语’, 80);
INSERT INTO score2 VALUES(NULL,902, ‘计算机’,65);
INSERT INTO score2 VALUES(NULL,902, ‘中文’,88);
INSERT INTO score2 VALUES(NULL,903, ‘中文’,95);
//查询score 和 score2的成绩
//union查询结果的纵向罗列 如果有两条数据是重复的 会去重复
select id,stu_id,c_name,grade from score
union
select * from score2 ;
//如果不想去重复 应该使用union all
select id,stu_id,c_name,grade from score
union all
select * from score2 ;
//使用union的最重要的注意点的是 列数目相等
2.笛卡尔积
//多表查询,如果没有查询条件,默认得到的结果就是多表的笛卡尔积 数据条数=各表条数的乘积
select * from student,score;
//一般会添加查询条件
mysql> select *from student;
±----±----------±-----±------±-------------±-------------------+
| id | name | sex | birth | department | address |
±----±----------±-----±------±-------------±-------------------+
| 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 |
| 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 |
| 903 | 张三 | 女 | 1990 | 中文系 | 湖南省永州市 |
±----±----------±-----±------±-------------±-------------------+
3 rows in set (0.00 sec)
mysql> select *from score;
±—±-------±----------±------±-------+
| id | stu_id | c_name | grade | common |
±—±-------±----------±------±-------+
| 1 | 901 | 计算机 | 98 | 90 |
| 2 | 901 | 英语 | 80 | 90 |
| 3 | 902 | 计算机 | 65 | 90 |
| 4 | 902 | 中文 | 88 | 90 |
| 5 | 903 | 中文 | 95 | 90 |
±—±-------±----------±------±-------+
5 rows in set (0.00 sec)
//如果想要查询score 让stu_id具体化
select * from score ,student where score.stu_id=student.id;
//查询 哪些学生参加了考试
select distinct student.* from score ,student where score.stu_id=student.id;
//User
create table t_user (
id int primary key auto_increment,
name char(10),
pwd char(64));
insert into t_user values (null,“tom0”,“ok”);
insert into t_user values (null,“tom1”,“ok”);
insert into t_user values (null,“tom2”,“ok”);
insert into t_user values (null,“tom3”,“ok”);
insert into t_user values (null,“tom4”,“ok”);
insert into t_user values (null,“tom5”,“ok”);
//friend
create table friend (id int primary key auto_increment,u_id int,f_id int);
insert into friend values (null,1,2);
insert into friend values (null,1,3);
insert into friend values (null,1,4);
insert into friend values (null,2,1);
insert into friend values (null,2,4);
insert into friend values (null,3,1);
//查询 1号用户的好友信息
select t_user.* from t_user,friend where u_id=1 and friend.f_id=t_user.id ;
3.Join连接
select * from student join student;
select * from student join score on student.id=score.stu_id; //两个表中都有对应的数据才会显示
//1.内连接 两个表中都有对应的数据才会显示
select * from student inner join score on student.id=score.stu_id;
//2.左连接 左表数据完全展示 右表如果没有相应的数据,显示null;
select * from student left join score on student.id=score.stu_id;
//3.右连接 右表数据完全展示
select * from score right join student on student.id=score.stu_id;
4.用户购物问题
create database if not exists shopping;
use shopping
//t_user用户表
create table t_user (id int primary key auto_increment ,name char(10));
//商品表
create table t_goods(id int primary key auto_increment,g_name char(20),g_count int);
//t_order订单表
create table t_order (id int primary key auto_increment,u_id int,foreign key(u_id) references t_user(id) );
//销售明细
create table itme (id int primary key auto_increment,o_id int,g_id int,foreign key(o_id) references t_order(id) ,foreign key(g_id) references t_goods(id) );
insert into t_user values (null,“lucy”);
insert into t_user values (null,“tom”);
insert into t_goods values(null,“苹果”,20);
insert into t_goods values(null,“香蕉”,20);
insert into t_goods values(null,“橘子”,20);
insert into t_order values (null,1);
insert into t_order values (null,1);
insert into t_order values (null,2);
insert into itme values (null,1,1);
insert into itme values (null,2,1);
insert into itme values (null,3,1);
insert into itme values (null,3,2);
insert into itme values (null,2,2);
insert into itme values (null,2,3);
//1.查询用户的所有订单信息
mysql> select t_user.*, t_order.id oid from t_user ,t_order where t_order.u_id=t_user.id;
±—±-----±----+
| id | name | oid |
±—±-----±----+
| 1 | lucy | 1 |
| 1 | lucy | 2 |
| 2 | tom | 3 |
±—±-----±----+
3 rows in set (0.00 sec)
//2.查询 用户所有的购物item
select t_user.*, t_order.id oid ,itme.id itid, itme.g_id from t_user ,t_order,itme where t_order.u_id=t_user.id and itme.o_id=t_order.id;
//查询每个用户购买了哪些商品
select t_user.*, t_order.id oid ,itme.id itid, itme.g_id , t_goods.g_name, t_goods.g_count from t_user ,t_order,itme,t_goods where t_order.u_id=t_user.id and itme.o_id=t_order.id and t_goods.id= itme.g_id;
select distinct t_user.*, t_goods.g_name from t_user ,t_order,itme,t_goods where t_order.u_id=t_user.id and itme.o_id=t_order.id and t_goods.id= itme.g_id;
//
User {int id,String name,List orders }
Order{int id,User user,List items }
1、Where型子查询:将后面的查询结果 作为前面的查询条件
//1.查询哪些同学的计算机成绩考到了90分以上 返回的列(student.*)
select * from score where grade >90 and c_name=“计算机”;
//表连接解决
select student.* from score join student on score.stu_id=student.id where score.grade >90 and score.c_name=“计算机”;
//子查询解决
select * from student where id in(select stu_id from score where grade >90 and c_name=“计算机”);
//2.哪些同学的计算机的成绩大于全部成绩的平均分
select * from score where grade > (select avg(grade) from score) and c_name=“计算机”;
select * from student where id in(select stu_id from score where grade > (select avg(grade) from score) and c_name=“计算机” );
2、from 型子查询:把后面的查询结果当做前面的查询范围
//哪些同学参加了中文考试
select * from student where id in (select stu_id from score where c_name=“中文”);
select student.* from score join student on student.id=score.stu_id where score.c_name=“中文”;
//各门课成绩的第一名
select * from student where id in(select stu_id from score where grade in(select sc from (select c_name,max(grade) as sc from score group by c_name) as aa) and c_name in (select c_name from (select c_name,max(grade) as sc from score group by c_name) as aa));
//select c_name,max(grade) as sc from score group by c_name; 查询各门课的最高分 、课程名称
//select sc from (select c_name,max(grade) as sc from score group by c_name) as sco; //各科最高分
//select stu_id from score where grade in(select sc from (select c_name,max(grade) as sc from score group by c_name) as sco); //分数满足最高分的同学ID
//select * from student where id in(select stu_id from score where grade in(select sc from (select c_name,max(grade) as sc from score group by c_name) as sco));
3、exists型子查询//NOT EXISTS
mysql> select * from student; //主查询
±----±----------±-----±------±-------------±-------------------+
| id | name | sex | birth | department | address |
±----±----------±-----±------±-------------±-------------------+
| 901 | 张老大 | 男 | 1985 | 计算机系 | 北京市海淀区 |
| 902 | 张老二 | 男 | 1986 | 中文系 | 北京市昌平区 |
| 903 | 张三 | 女 | 1990 | 中文系 | 湖南省永州市 |
| 904 | 李四 | 男 | 1990 | 英语系 | 辽宁省阜新市 |
| 905 | 王五 | 女 | 1991 | 英语系 | 福建省厦门市 |
| 906 | 王六 | 男 | 1988 | 计算机系 | 湖南省衡阳市 |
±----±----------±-----±------±-------------±-------------------+
select * from student where exists (select * from score where score.stu_id=student.id);
//将主查询的数据,放到子查询中做条件验证,根据验证结果(TRUE 或 FALSE)来决定主查询的数据结果是否得以保留。
//复制表
create table score2 select * from score;
create table score_youxiu select * from score where grade >90;
//应用:分表办法(按业务需要,取模(id%4),取偏移量)
create table score_youxiu select * from score where id%4=0;
//复制表结构
create table score3 select * from score where 1<>1;
//从score 表复制数据到score3
insert into score3 select * from score;
//复制部分列数据到score
insert into ss (id,stu_id) select id,stu_id from score;
insert into score3 (id,stu_id,c_name) select id,stu_id,c_name from score;
//修改字段位置
alter table ss add ssx bit after id;
alter table ss change sex sex bit first;
//注意点: 表格的复制 外键约束 、主键约束、唯一约束不会被复制
1、什么视图
视图是一个虚拟的表
作用: 简化查询、权限控制、大数据分表的整合
//创建语法: create view view_name as select …
//查询计算机成绩
select stu_id from score where c_name=“计算机” order by grade desc;
select * from student where id in(select stu_id from score where c_name=“计算机” order by grade desc );
//创建视图
create view jsj as select * from student where id in(select stu_id from score where c_name=“计算机” order by grade desc );
//查询视图
show tables;
select * from jsj;
select * from jsj where id=901;
//删除
drop view jsj;
//视图和原表数据
create view ss as select * from score;
//1、修改原表数据 视图会修改
//2、修改视图数据 原表也会修改 一般 如果不是一一对应的映射 不会进行修改
insert into score (id,stu_id ) values (22,901);
//algorithm(算法) [merge,temptable,undefined]
//create algorithm=merge view view_name as select …
创造的是一个sql语句
create algorithm=merge view ss as selcet * from score;
select *from ss where grede >90;
create algorithm=merge view ss as selcet * from score where grade >90;
//create algorithm=temptable view view_name as select …
create algorithm=merge view ss as selcet * from score;
//查询时候 会创建一个临时表
select *from ss where grede >90;
==================================================================
使用工具:mysql 自带的WorkBench
1、下载mysql-workbench-community-6.3.10-winx64.msi
2、安装可能需要以下支持
vc_redist.x64.exe (提示C++ 2015)
Microsoft.NET Framework_4.6.2.exe
3、登录界面
4、点击File–>new Model
5、点击 Add Diagram进入EER Diagram
6、点击database -->Reverser engineer database
7、选择要绘制的数据库,进入下个界面,右侧出现选择的数据库
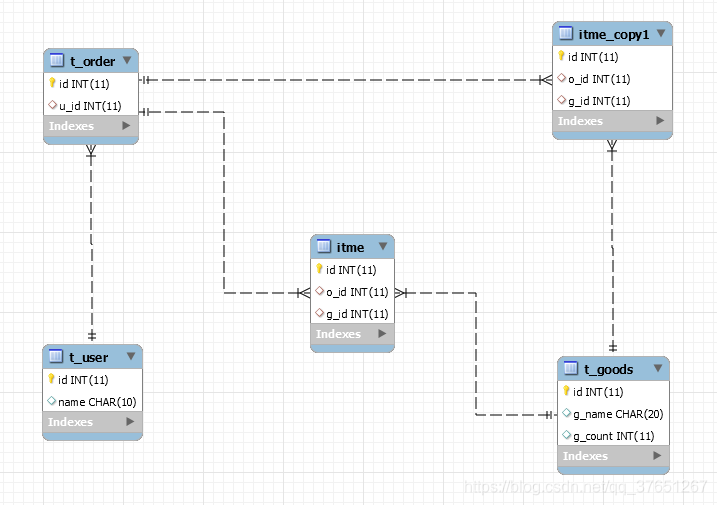
8、展开tables 将表格拖到右侧空白
=======================================================================
1、什么是字符集(字典)
2、mysql字符集
数据库系统–>数据库–>表–>字段均可设置字符集,如果下级每指定,使用上级的
如果表使用UTF-8存储文件必然是UTF-8
//查看mysql字符集
mysql> show char set;
mysql> show variables like “char%” \G
±-------------------------±--------------------------------------------------------+
| Variable_name | Value |
±-------------------------±--------------------------------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | C:\Program Files\MySQL\MySQL Server 5.7\share\charsets\ |
±-------------------------±--------------------------------------------------------+
mysql> show variables like “char%”;
±-------------------------±--------------------------------------------------------+
| Variable_name | Value |
±-------------------------±--------------------------------------------------------+
| character_set_client | gbk |//客户端向数据库发送数据时采用的编码
| character_set_connection | gbk |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | gbk |//返回客户端采用的编码格式
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | C:\Program Files\MySQL\MySQL Server 5.7\share\charsets\ |
±-------------------------±--------------------------------------------------------+
//[character_set_system]
The server sets the [character_set_system] system variable to the name of the metadata character set: 官方文档说明:默认要求UTF-8
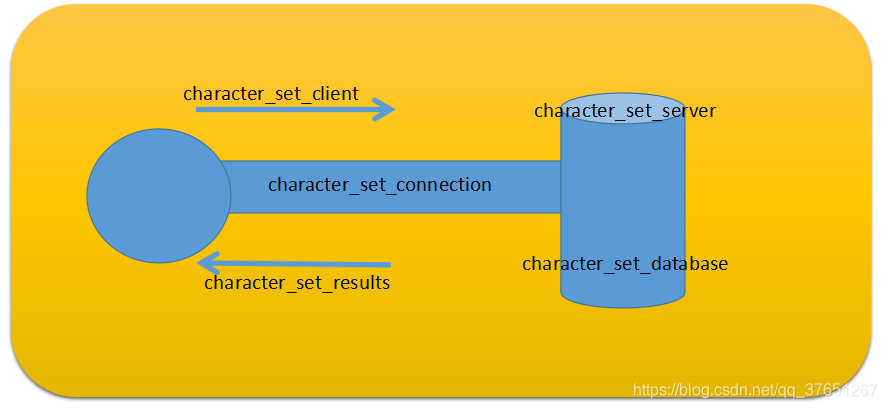 connection类似一个字符转换器,负责客户端写入与数据库编码的翻译以及数据库和返回视图的翻译(client------>connection—>database)(database–>connection–>result)
connection类似一个字符转换器,负责客户端写入与数据库编码的翻译以及数据库和返回视图的翻译(client------>connection—>database)(database–>connection–>result)
//创建表格指定字符集gbk
mysql> create table demo.chart (id int primary key auto_increment ,name char(10) ) charset=gbk;
Query OK, 0 rows affected (0.03 sec)
mysql> show create table chart;
//什么时候会数据丢失
//为什么set names gbk
set character_set_client=gbk;
set character_set_connection = gbk ;
set character_set_database =gbk;
set character_set_results =gbk;
set character_set_server=gbk;
show variables like “char%”;
set names gbk;
show variables like “char%”;
set character_set_client=gbk;
set character_set_connection = gbk ;
set character_set_results =gbk;
1、什么是较对集合: 编码的排序规则
show collection;
show collation like “utf8%”;
insert into bb values (“a”);
insert into bb values (“A”);
insert into bb values (“b”);
insert into bb values (“B”);
collate utf8_bin;
==================================================================
事务(Transaction):ts,一般是指要做的或所做的事情
mysql> create table ac (id int primary key auto_increment,
-> ac_name char(10),ac_money int);
Query OK, 0 rows affected (0.06 sec)
mysql> desc ac;
±---------±---------±-----±----±--------±---------------+
| Field | Type | Null | Key | Default | Extra |
±---------±---------±-----±----±--------±---------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| ac_name | char(10) | YES | | NULL | |
| ac_money | int(11) | YES | | NULL | |
±---------±---------±-----±----±--------±---------------+
3 rows in set (0.09 sec)
mysql> insert into ac values (null,“lucy”,5000);
Query OK, 1 row affected (0.05 sec)
mysql> insert into ac values (null,“tom”,2000);
Query OK, 1 row affected (0.01 sec)
mysql> select * from ac;
±—±--------±---------+
| id | ac_name | ac_money |
±—±--------±---------+
| 1 | lucy | 5000 |
| 2 | tom | 2000 |
±—±--------±---------+
2 rows in set (0.00 sec)
//转账 lucy —>tom 1000
update ac set ac_money=ac_money-1000 where id=1;
update ac set ac_money=ac_money+1000 where id=2;
//事务的四个特性(ACID)(掌握和理解)
原子性(atomicity) 要么都成功,要么都失败
一致性(consistency)数据的正确性
隔离性(isolation)。一个事务的执行不能被其他事务干扰。(隔离级别)
持久性(durability)。持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。
//mysql 事务的操作
//1.开启事务
mysql> begin;
Query OK, 0 rows affected (0.05 sec)
//2.事务的提交(关闭)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
//3.事务的回滚(关闭)
mysql> rollback;
Query OK, 0 rows affected (0.00 sec)
//4.保存点
mysql> savepoint c;
Query OK, 0 rows affected (0.00 sec)
//5.回滚到保存点
mysql> rollback to savepoint c;
Query OK, 0 rows affected (0.00 sec)
//6.自动提交的设置
mysql> set autocommit=0;
Query OK, 0 rows affected (0.05 sec)
mysql> set autocommit=1;
Query OK, 0 rows affected (0.00 sec)
----------------------------存在的问题-----------
脏读:事务T1将某一值修改,然后事务T2读取该值,此后T1因为某种原因撤销对该值的修改,这就导致了T2所读取到的数据是无效的。
不可重复读:事务1第一次读 A,事务2修改A为B,事务1 第二次读到B
幻读:事务B以插入或删除行等方式来修改事务A的结果集,然后再提交。
//事务的隔离级别
read uncommitted | 0 未提交读 不解决问题
read committed | 1 已提交读 可以解决脏读
repeatable read | 2 可重复读 避免脏读,不可重复读,
serializable | 3 可序列化 解决一切问题(并发)
===================================================================
create table goods (
g_id int primary key auto_increment,
g_name char(10),
g_count int);
create table sale (
s_id int primary key auto_increment,
s_time datetime,
g_id int,
s_num int);
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

总结
在这里,由于面试中MySQL问的比较多,因此也就在此以MySQL为例为大家总结分享。但是你要学习的往往不止这一点,还有一些主流框架的使用,Spring源码的学习,Mybatis源码的学习等等都是需要掌握的,我也把这些知识点都整理起来了


《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
OK, 0 rows affected (0.00 sec)
----------------------------存在的问题-----------
脏读:事务T1将某一值修改,然后事务T2读取该值,此后T1因为某种原因撤销对该值的修改,这就导致了T2所读取到的数据是无效的。
不可重复读:事务1第一次读 A,事务2修改A为B,事务1 第二次读到B
幻读:事务B以插入或删除行等方式来修改事务A的结果集,然后再提交。
//事务的隔离级别
read uncommitted | 0 未提交读 不解决问题
read committed | 1 已提交读 可以解决脏读
repeatable read | 2 可重复读 避免脏读,不可重复读,
serializable | 3 可序列化 解决一切问题(并发)
===================================================================
create table goods (
g_id int primary key auto_increment,
g_name char(10),
g_count int);
create table sale (
s_id int primary key auto_increment,
s_time datetime,
g_id int,
s_num int);
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。[外链图片转存中…(img-Mz1GCUxK-1713381852745)]
[外链图片转存中…(img-kJhalWT9-1713381852745)]
[外链图片转存中…(img-0Jvw6PzQ-1713381852745)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)
总结
在这里,由于面试中MySQL问的比较多,因此也就在此以MySQL为例为大家总结分享。但是你要学习的往往不止这一点,还有一些主流框架的使用,Spring源码的学习,Mybatis源码的学习等等都是需要掌握的,我也把这些知识点都整理起来了
[外链图片转存中…(img-T8KMs5uE-1713381852746)]
[外链图片转存中…(img-8IJREPL2-1713381852746)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









