








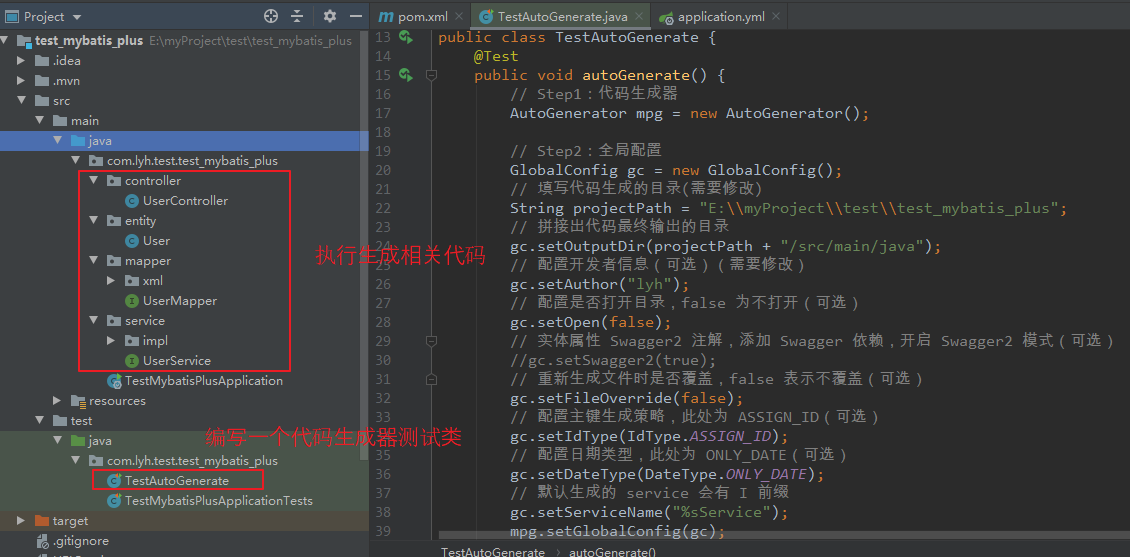
// Step2:全局配置
GlobalConfig gc = new GlobalConfig();
// 填写代码生成的目录(需要修改)
String projectPath = “E:\myProject\test\test_mybatis_plus”;
// 拼接出代码最终输出的目录
gc.setOutputDir(projectPath + “/src/main/java”);
// 配置开发者信息(可选)(需要修改)
gc.setAuthor(“lyh”);
// 配置是否打开目录,false 为不打开(可选)
gc.setOpen(false);
// 实体属性 Swagger2 注解,添加 Swagger 依赖,开启 Swagger2 模式(可选)
//gc.setSwagger2(true);
// 重新生成文件时是否覆盖,false 表示不覆盖(可选)
gc.setFileOverride(false);
// 配置主键生成策略,此处为 ASSIGN_ID(可选)
gc.setIdType(IdType.ASSIGN_ID);
// 配置日期类型,此处为 ONLY_DATE(可选)
gc.setDateType(DateType.ONLY_DATE);
// 默认生成的 service 会有 I 前缀
gc.setServiceName(“%sService”);
mpg.setGlobalConfig(gc);

Step3:
配置数据源信息。用于指定 需要生成代码的 数据仓库、数据表。
setUrl、setDriverName、setUsername、setPassword 均需修改。

// Step3:数据源配置(需要修改)
DataSourceConfig dsc = new DataSourceConfig();
// 配置数据库 url 地址
dsc.setUrl(“jdbc:mysql://localhost:3306/testMyBatisPlus?useUnicode=true&characterEncoding=utf8”);
// dsc.setSchemaName(“testMyBatisPlus”); // 可以直接在 url 中指定数据库名
// 配置数据库驱动
dsc.setDriverName(“com.mysql.cj.jdbc.Driver”);
// 配置数据库连接用户名
dsc.setUsername(“root”);
// 配置数据库连接密码
dsc.setPassword(“123456”);
mpg.setDataSource(dsc);

Step4:
配置包信息。
setParent、setModuleName 均需修改。其余按需求修改.

// Step:4:包配置
PackageConfig pc = new PackageConfig();
// 配置父包名(需要修改)
pc.setParent(“com.lyh.test”);
// 配置模块名(需要修改)
pc.setModuleName(“test_mybatis_plus”);
// 配置 entity 包名
pc.setEntity(“entity”);
// 配置 mapper 包名
pc.setMapper(“mapper”);
// 配置 service 包名
pc.setService(“service”);
// 配置 controller 包名
pc.setController(“controller”);
mpg.setPackageInfo(pc);

Step5:
配置数据表映射信息。
setInclude 需要修改,其余按实际开发修改。

// Step5:策略配置(数据库表配置)
StrategyConfig strategy = new StrategyConfig();
// 指定表名(可以同时操作多个表,使用 , 隔开)(需要修改)
strategy.setInclude(“test_mybatis_plus_user”);
// 配置数据表与实体类名之间映射的策略
strategy.setNaming(NamingStrategy.underline_to_camel);
// 配置数据表的字段与实体类的属性名之间映射的策略
strategy.setColumnNaming(NamingStrategy.underline_to_camel);
// 配置 lombok 模式
strategy.setEntityLombokModel(true);
// 配置 rest 风格的控制器(@RestController)
strategy.setRestControllerStyle(true);
// 配置驼峰转连字符
strategy.setControllerMappingHyphenStyle(true);
// 配置表前缀,生成实体时去除表前缀
// 此处的表名为 test_mybatis_plus_user,模块名为 test_mybatis_plus,去除前缀后剩下为 user。
strategy.setTablePrefix(pc.getModuleName() + “_”);
mpg.setStrategy(strategy);

Step6:
执行代码生成操作。
此处不用修改。
// Step6:执行代码生成操作
mpg.execute();
完整配置如下:

package com.lyh.test.test_mybatis_plus;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.generator.AutoGenerator;
import com.baomidou.mybatisplus.generator.config.DataSourceConfig;
import com.baomidou.mybatisplus.generator.config.GlobalConfig;
import com.baomidou.mybatisplus.generator.config.PackageConfig;
import com.baomidou.mybatisplus.generator.config.StrategyConfig;
import com.baomidou.mybatisplus.generator.config.rules.DateType;
import com.baomidou.mybatisplus.generator.config.rules.NamingStrategy;
import org.junit.jupiter.api.Test;
public class TestAutoGenerate {
@Test
public void autoGenerate() {
// Step1:代码生成器
AutoGenerator mpg = new AutoGenerator();
// Step2:全局配置
GlobalConfig gc = new GlobalConfig();
// 填写代码生成的目录(需要修改)
String projectPath = “E:\myProject\test\test_mybatis_plus”;
// 拼接出代码最终输出的目录
gc.setOutputDir(projectPath + “/src/main/java”);
// 配置开发者信息(可选)(需要修改)
gc.setAuthor(“lyh”);
// 配置是否打开目录,false 为不打开(可选)
gc.setOpen(false);
// 实体属性 Swagger2 注解,添加 Swagger 依赖,开启 Swagger2 模式(可选)
//gc.setSwagger2(true);
// 重新生成文件时是否覆盖,false 表示不覆盖(可选)
gc.setFileOverride(false);
// 配置主键生成策略,此处为 ASSIGN_ID(可选)
gc.setIdType(IdType.ASSIGN_ID);
// 配置日期类型,此处为 ONLY_DATE(可选)
gc.setDateType(DateType.ONLY_DATE);
// 默认生成的 service 会有 I 前缀
gc.setServiceName(“%sService”);
mpg.setGlobalConfig(gc);
// Step3:数据源配置(需要修改)
DataSourceConfig dsc = new DataSourceConfig();
// 配置数据库 url 地址
dsc.setUrl(“jdbc:mysql://localhost:3306/testMyBatisPlus?useUnicode=true&characterEncoding=utf8”);
// dsc.setSchemaName(“testMyBatisPlus”); // 可以直接在 url 中指定数据库名
// 配置数据库驱动
dsc.setDriverName(“com.mysql.cj.jdbc.Driver”);
// 配置数据库连接用户名
dsc.setUsername(“root”);
// 配置数据库连接密码
dsc.setPassword(“123456”);
mpg.setDataSource(dsc);
// Step:4:包配置
PackageConfig pc = new PackageConfig();
// 配置父包名(需要修改)
pc.setParent(“com.lyh.test”);
// 配置模块名(需要修改)
pc.setModuleName(“test_mybatis_plus”);
// 配置 entity 包名
pc.setEntity(“entity”);
// 配置 mapper 包名
pc.setMapper(“mapper”);
// 配置 service 包名
pc.setService(“service”);
// 配置 controller 包名
pc.setController(“controller”);
mpg.setPackageInfo(pc);
// Step5:策略配置(数据库表配置)
StrategyConfig strategy = new StrategyConfig();
// 指定表名(可以同时操作多个表,使用 , 隔开)(需要修改)
strategy.setInclude(“test_mybatis_plus_user”);
// 配置数据表与实体类名之间映射的策略
strategy.setNaming(NamingStrategy.underline_to_camel);
// 配置数据表的字段与实体类的属性名之间映射的策略
strategy.setColumnNaming(NamingStrategy.underline_to_camel);
// 配置 lombok 模式
strategy.setEntityLombokModel(true);
// 配置 rest 风格的控制器(@RestController)
strategy.setRestControllerStyle(true);
// 配置驼峰转连字符
strategy.setControllerMappingHyphenStyle(true);
// 配置表前缀,生成实体时去除表前缀
// 此处的表名为 test_mybatis_plus_user,模块名为 test_mybatis_plus,去除前缀后剩下为 user。
strategy.setTablePrefix(pc.getModuleName() + “_”);
mpg.setStrategy(strategy);
// Step6:执行代码生成操作
mpg.execute();
}
}

4、自动填充数据功能
==========
(1)简介
添加、修改数据时,每次都会使用相同的方式进行填充。比如 数据的创建时间、修改时间等。
Mybatis-plus 支持自动填充这些字段的数据。
给之前的数据表新增两个字段:创建时间、修改时间。

CREATE TABLE test_mybatis_plus_user
(
id BIGINT NOT NULL COMMENT ‘主键ID’,
name VARCHAR(30) NULL DEFAULT NULL COMMENT ‘姓名’,
age INT(11) NULL DEFAULT NULL COMMENT ‘年龄’,
email VARCHAR(50) NULL DEFAULT NULL COMMENT ‘邮箱’,
create_time timestamp NULL DEFAULT NULL COMMENT ‘创建时间’,
update_time timestamp NULL DEFAULT NULL COMMENT ‘最后修改时间’,
PRIMARY KEY (id)
);

并使用 代码生成器生成代码。
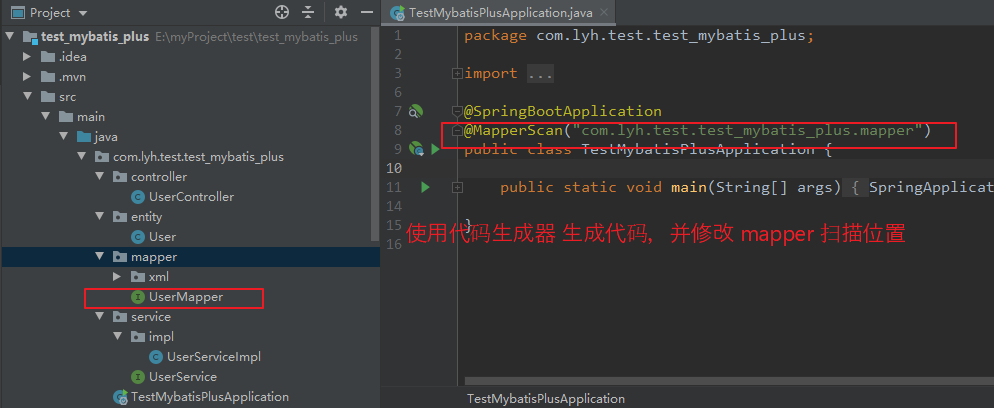
(2)未使用自动填充时
未使用 自动填充时,每次添加、修改数据都可以手动对其进行添加。

@SpringBootTest
class TestMybatisPlusApplicationTests {
@Autowired
private UserService userService;
@Test
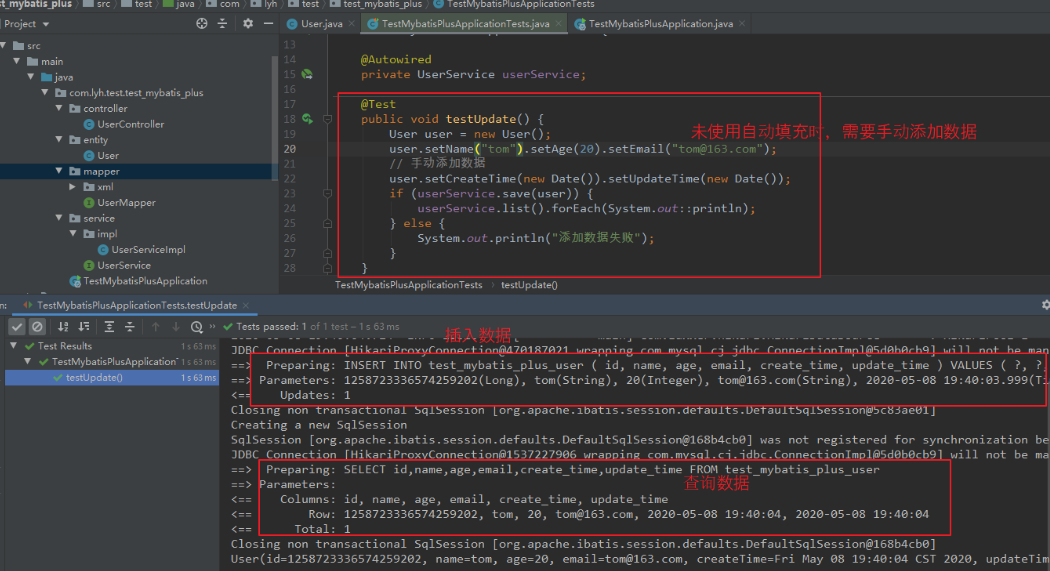
public void testUpdate() {
User user = new User();
user.setName(“tom”).setAge(20).setEmail(“tom@163.com”);
// 手动添加数据
user.setCreateTime(new Date()).setUpdateTime(new Date());
if (userService.save(user)) {
userService.list().forEach(System.out::println);
} else {
System.out.println(“添加数据失败”);
}
}
}

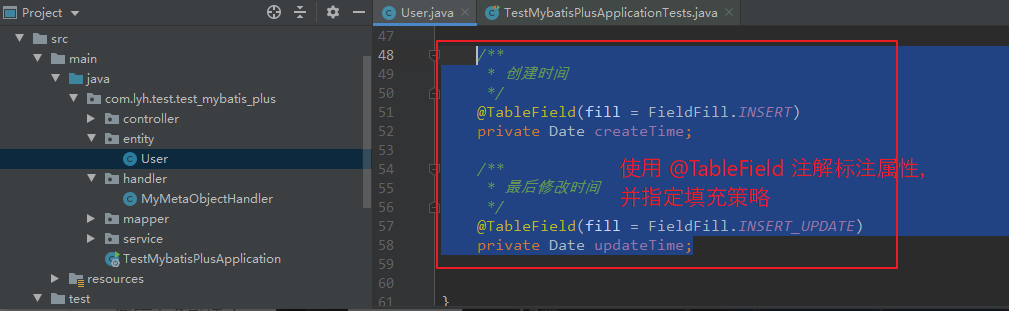
(3)使用自动填充功能。
Step1:
使用 @TableField 注解,标注需要进行填充的字段。

/**
- 创建时间
*/
@TableField(fill = FieldFill.INSERT)
private Date createTime;
/**
- 最后修改时间
*/
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updateTime;

Step2:
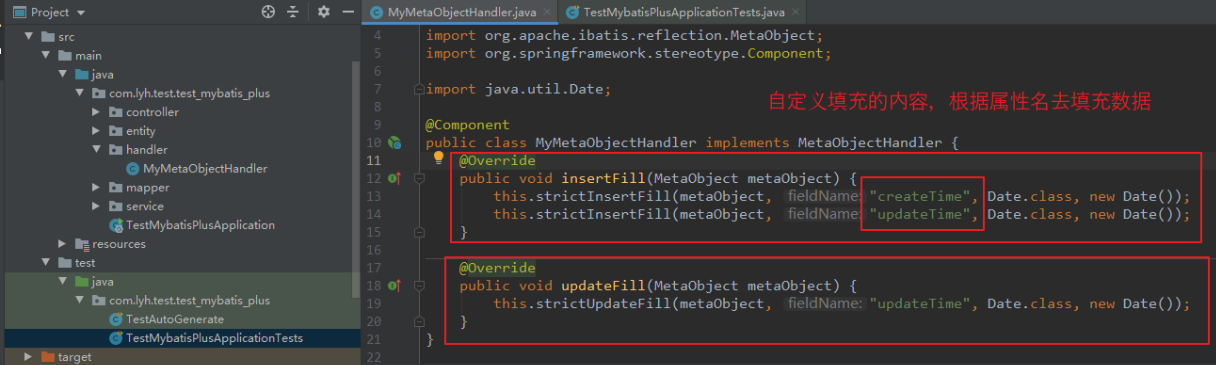
自定义一个类,实现 MetaObjectHandler 接口,并重写方法。
添加 @Component 注解,交给 Spring 去管理。

package com.lyh.test.test_mybatis_plus.handler;
import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;
import org.apache.ibatis.reflection.MetaObject;
import org.springframework.stereotype.Component;
import java.util.Date;
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
this.strictInsertFill(metaObject, “createTime”, Date.class, new Date());
this.strictInsertFill(metaObject, “updateTime”, Date.class, new Date());
}
@Override
public void updateFill(MetaObject metaObject) {
this.strictUpdateFill(metaObject, “updateTime”, Date.class, new Date());
}
}

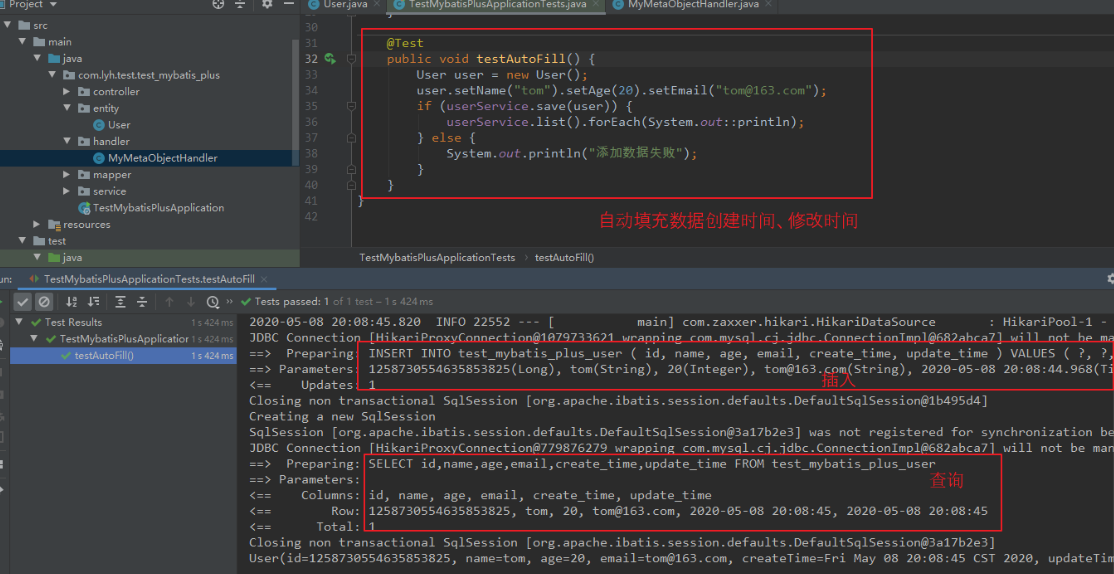
Step3:
简单测试一下。

@Test
public void testAutoFill() {
User user = new User();
user.setName(“tom”).setAge(20).setEmail(“tom@163.com”);
if (userService.save(user)) {
userService.list().forEach(System.out::println);
} else {
System.out.println(“添加数据失败”);
}
}

5、逻辑删除
======
(1)简介
删除数据,可以通过物理删除,也可以通过逻辑删除。
物理删除指的是直接将数据从数据库中删除,不保留。
逻辑删除指的是修改数据的某个字段,使其表示为已删除状态,而非删除数据,保留该数据在数据库中,但是查询时不显示该数据(查询时过滤掉该数据)。
给数据表增加一个字段:delete_flag,用于表示该数据是否被逻辑删除。

CREATE TABLE test_mybatis_plus_user
(
id BIGINT NOT NULL COMMENT ‘主键ID’,
name VARCHAR(30) NULL DEFAULT NULL COMMENT ‘姓名’,
age INT(11) NULL DEFAULT NULL COMMENT ‘年龄’,
email VARCHAR(50) NULL DEFAULT NULL COMMENT ‘邮箱’,
create_time timestamp NULL DEFAULT NULL COMMENT ‘创建时间’,
update_time timestamp NULL DEFAULT NULL COMMENT ‘最后修改时间’,
delete_flag tinyint(1) NULL DEFAULT NULL COMMENT ‘逻辑删除(0 未删除、1 删除)’,
PRIMARY KEY (id)
);

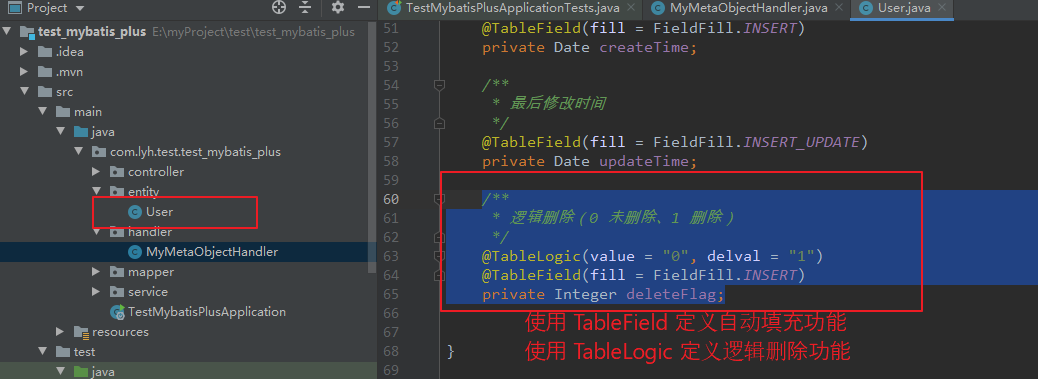
(2)使用逻辑删除。
可以定义一个自动填充规则,初始值为 0。0 表示未删除, 1 表示删除。

/**
- 逻辑删除(0 未删除、1 删除)
*/
@TableLogic(value = “0”, delval = “1”)
@TableField(fill = FieldFill.INSERT)
private Integer deleteFlag;
@Override
public void insertFill(MetaObject metaObject) {
this.strictInsertFill(metaObject, “deleteFlag”, Integer.class, 0);
}

(3)简单测试
使用 mybatis-plus 封装好的方法时,会自动添加逻辑删除的功能。
若是自定义的 sql 语句,需要手动添加逻辑。

@Test
public void testDelete() {
if (userService.removeById(1258924257048547329L)) {
System.out.println(“删除数据成功”);
userService.list().forEach(System.out::println);
} else {
System.out.println(“删除数据失败”);
}
}

现有数据

执行 testDelete 进行逻辑删除。
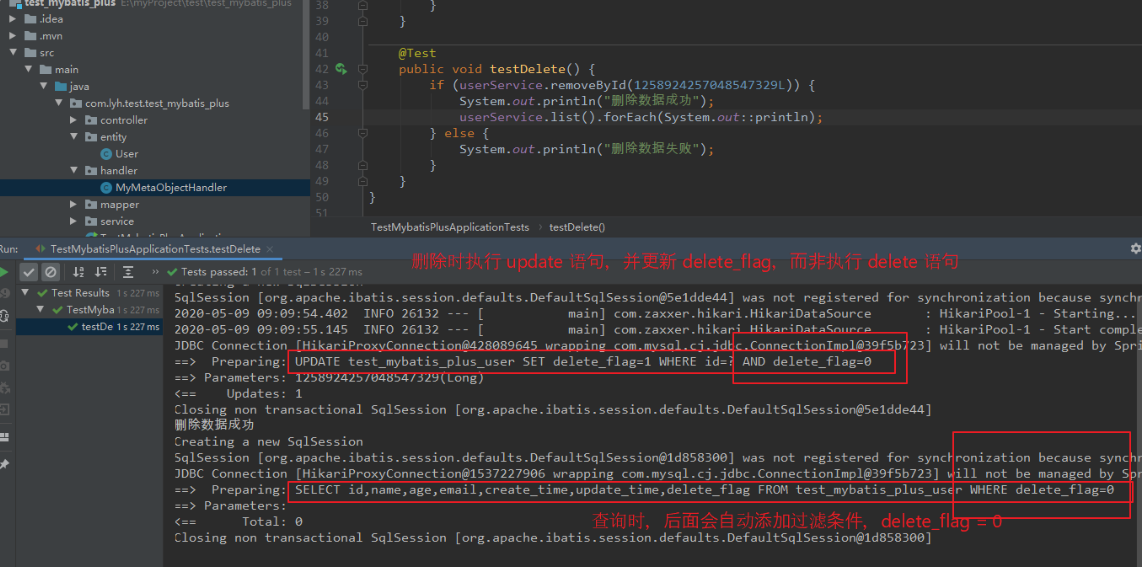

若去除 TableLogic 注解,再执行 testDelete 时进行物理删除,直接删除这条数据。


6、分页插件的使用
=========
(1)简介
与 mybatis 的插件 pagehelper 用法类似。
通过简单的配置即可使用。
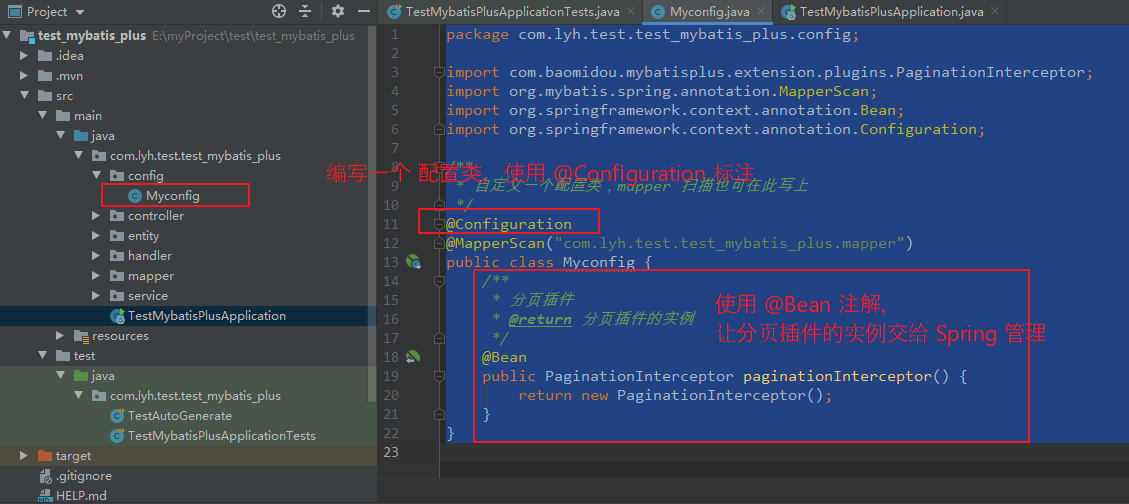
(2)使用
Step1:
配置分页插件。
编写一个 配置类,内部使用 @Bean 注解将 PaginationInterceptor 交给 Spring 容器管理。

package com.lyh.test.test_mybatis_plus.config;
import com.baomidou.mybatisplus.extension.plugins.PaginationInterceptor;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
- 自定义一个配置类,mapper 扫描也可在此写上
*/
@Configuration
@MapperScan(“com.lyh.test.test_mybatis_plus.mapper”)
public class Myconfig {
/**
-
分页插件
-
@return 分页插件的实例
*/
@Bean
public PaginationInterceptor paginationInterceptor() {
return new PaginationInterceptor();
}
}

Step2:
编写分页代码。
直接 new 一个 Page 对象,对象需要传递两个参数(当前页,每页显示的条数)。
调用 mybatis-plus 提供的分页查询方法,其会将 分页查询的数据封装到 Page 对象中。

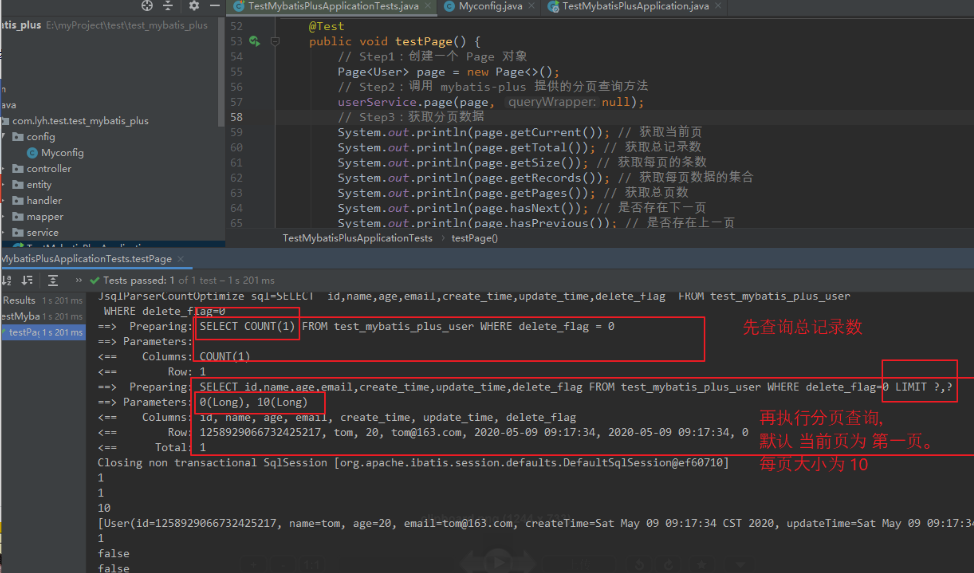
@Test
public void testPage() {
// Step1:创建一个 Page 对象
Page page = new Page<>();
// Page page = new Page<>(2, 5);
// Step2:调用 mybatis-plus 提供的分页查询方法
userService.page(page, null);
// Step3:获取分页数据
System.out.println(page.getCurrent()); // 获取当前页
System.out.println(page.getTotal()); // 获取总记录数
System.out.println(page.getSize()); // 获取每页的条数
System.out.println(page.getRecords()); // 获取每页数据的集合
System.out.println(page.getPages()); // 获取总页数
System.out.println(page.hasNext()); // 是否存在下一页
System.out.println(page.hasPrevious()); // 是否存在上一页
}

7、乐观锁的实现
========
(1)首先认识一下 读问题、写问题?
操作数据库数据时,遇到的最基本问题就是 读问题与写问题。
读问题 指的是从数据库中读取数据时遇到的问题,比如:脏读、幻读、不可重复读。
【脏读、幻读、不可重复读 参考地址:】
https://www.cnblogs.com/l-y-h/p/12458777.html#_label0_3
写问题 指的是数据写入数据库时遇到的问题,比如:丢失更新(多个线程同时对某条数据更新,无论执行顺序如何,都会丢失其他线程更新的数据)
(2)如何解决写问题?
乐观锁、悲观锁就是为了解决 写问题而存在的。
乐观锁:总是假设最好的情况,每次读取数据时认为数据不会被修改(即不加锁),当进行更新操作时,会判断这条数据是否被修改,未被修改,则进行更新操作。若被修改,则数据更新失败,可以对数据进行重试(重新尝试修改数据)。
悲观锁:总是假设最坏的情况,每次读取数据时认为数据会被修改(即加锁),当进行更新操作时,直接更新数据,结束操作后释放锁(此处才可以被其他线程读取)。
(3)乐观锁、悲观锁使用场景?
乐观锁一般用于读比较多的场合,尽量减少加锁的开销。
悲观锁一般用于写比较多的场合,尽量减少 类似 乐观锁重试更新引起的性能开销。
(4)乐观锁两种实现方式
方式一:通过版本号机制实现。
在数据表中增加一个 version 字段。
取数据时,获取该字段,更新时以该字段为条件进行处理(即set version = newVersion where version = oldVersion),若 version 相同,则更新成功(给新 version 赋一个值,一般加 1)。若 version 不同,则更新失败,可以重新尝试更新操作。
方式二:通过 CAS 算法实现。
CAS 为 Compare And Swap 的缩写,即比较交换,是一种无锁算法(即在不加锁的情况实现多线程之间的变量同步)。
CAS 操作包含三个操作数 —— 内存值(V)、预期原值(A)和新值(B)。如果内存地址里面的值 V 和 A 的值是一样的,那么就将内存里面的值更新成B。若 V 与 A 不一致,则不执行任何操作(可以通过自旋操作,不断尝试修改数据直至成功修改)。即 V == A ? V = B : V = V。
CAS 可能导致 ABA 问题(两次读取数据时值相同,但不确定值是否被修改过),比如两个线程操作同一个变量,线程 A、线程B 初始读取数据均为 A,后来 线程B 将数据修改为 B,然后又修改为 A,此时线程 A 再次读取到的数据依旧是 A,虽然值相同但是中间被修改过,这就是 ABA 问题。可以加一个额外的标志位 C,用于表示数据是否被修改。当标志位 C 与预期标志位相同、且 V == A 时,则更新值 B。
(5)mybatis-plus 实现乐观锁(通过 version 机制)
实现思路:
Step1:取出记录时,获取当前version
Step2:更新时,带上这个version
Step3:执行更新时, set version = newVersion where version = oldVersion
Step4:如果version不对,就更新失败
(6)mybatis-plus 代码实现乐观锁
Step1:
配置乐观锁插件。
编写一个配置类(可以与上例的分页插件共用一个配置类),将
OptimisticLockerInterceptor 通过 @Bean 交给 Spring 管理。

/**
-
乐观锁插件
-
@return 乐观锁插件的实例
*/
@Bean
public OptimisticLockerInterceptor optimisticLockerInterceptor() {
return new OptimisticLockerInterceptor();
}


Step2:
定义一个数据库字段 version。

CREATE TABLE test_mybatis_plus_user
(
id BIGINT NOT NULL COMMENT ‘主键ID’,
name VARCHAR(30) NULL DEFAULT NULL COMMENT ‘姓名’,
age INT(11) NULL DEFAULT NULL COMMENT ‘年龄’,
email VARCHAR(50) NULL DEFAULT NULL COMMENT ‘邮箱’,
create_time timestamp NULL DEFAULT NULL COMMENT ‘创建时间’,
update_time timestamp NULL DEFAULT NULL COMMENT ‘最后修改时间’,
delete_flag tinyint(1) NULL DEFAULT NULL COMMENT ‘逻辑删除(0 未删除、1 删除)’,
version int NULL DEFAULT NULL COMMENT ‘版本号(用于乐观锁, 默认为 1)’,
PRIMARY KEY (id)
);

Step3:
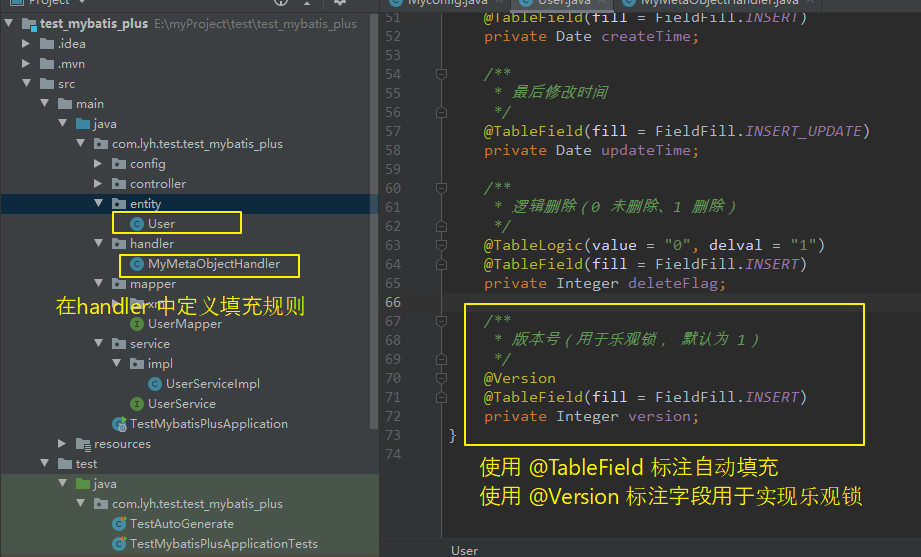
使用 @Version 注解标注对应的实体类。
可以通过 @TableField 进行数据自动填充。

/**
- 版本号(用于乐观锁, 默认为 1)
*/
@Version
@TableField(fill = FieldFill.INSERT)
private Integer version;
@Override
public void insertFill(MetaObject metaObject) {
this.strictInsertFill(metaObject, “version”, Integer.class, 1);
}

Step4:
简单测试一下,可以看一下 控制台 打印的 sql 语句。

@Test
public void testVersion() {
User user = new User();
user.setName(“tom”).setAge(20).setEmail(“tom@163.com”);
userService.save(user);
userService.list().forEach(System.out::println);
user.setName(“jarry”);
userService.update(user, null);
userService.list().forEach(System.out::println);
}


回到顶部
三、Mybatis-Plus CRUD 操作简单了解一下
============================
1、Mapper 接口方法(CRUD)简单了解一下
=========================
(1)简介
使用代码生成器生成的 mapper 接口中,其继承了 BaseMapper 接口。
而 BaseMapper 接口中封装了一系列 CRUD 常用操作,可以直接使用,而不用自定义 xml 与 sql 语句进行 CRUD 操作(当然根据实际开发需要,自定义 sql 还是有必要的)。
此处简单介绍一下 BaseMapper 接口中的常用方法。

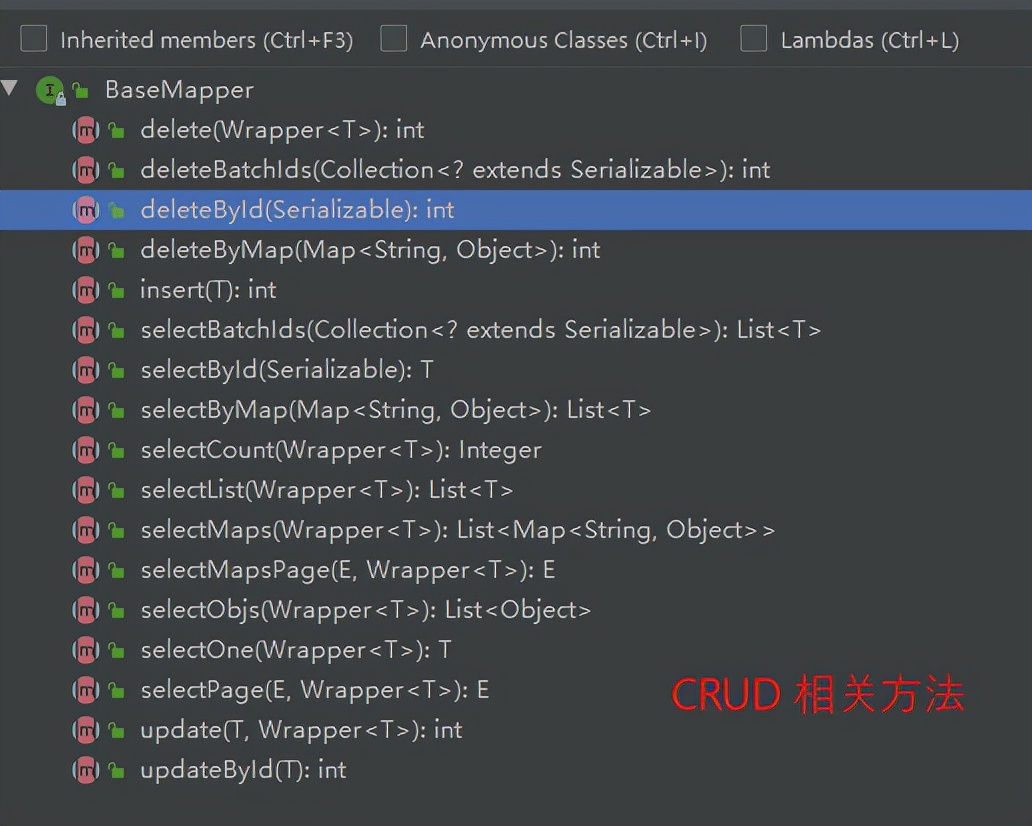
(2)方法介绍
混个眼熟,用多了就记得了。

【添加数据:(增)】
int insert(T entity); // 插入一条记录
注:
T 表示任意实体类型
entity 表示实体对象
【删除数据:(删)】
int deleteById(Serializable id); // 根据主键 ID 删除
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap); // 根据 map 定义字段的条件删除
int delete(@Param(Constants.WRAPPER) Wrapper wrapper); // 根据实体类定义的 条件删除对象
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList); // 进行批量删除
注:
id 表示 主键 ID
columnMap 表示表字段的 map 对象
wrapper 表示实体对象封装操作类,可以为 null。
idList 表示 主键 ID 集合(列表、数组),不能为 null 或 empty
【修改数据:(改)】
int updateById(@Param(Constants.ENTITY) T entity); // 根据 ID 修改实体对象。
int update(@Param(Constants.ENTITY) T entity, @Param(Constants.WRAPPER) Wrapper updateWrapper); // 根据 updateWrapper 条件修改实体对象
注:
update 中的 entity 为 set 条件,可以为 null。
updateWrapper 表示实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句)
【查询数据:(查)】
T selectById(Serializable id); // 根据 主键 ID 查询数据
List selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList); // 进行批量查询
List selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap); // 根据表字段条件查询
T selectOne(@Param(Constants.WRAPPER) Wrapper queryWrapper); // 根据实体类封装对象 查询一条记录
Integer selectCount(@Param(Constants.WRAPPER) Wrapper queryWrapper); // 查询记录的总条数
List selectList(@Param(Constants.WRAPPER) Wrapper queryWrapper); // 查询所有记录(返回 entity 集合)
List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper queryWrapper); // 查询所有记录(返回 map 集合)
List selectObjs(@Param(Constants.WRAPPER) Wrapper queryWrapper); // 查询所有记录(但只保存第一个字段的值)
<E extends IPage> E selectPage(E page, @Param(Constants.WRAPPER) Wrapper queryWrapper); // 查询所有记录(返回 entity 集合),分页
<E extends IPage<Map<String, Object>>> E selectMapsPage(E page, @Param(Constants.WRAPPER) Wrapper queryWrapper); // 查询所有记录(返回 map 集合),分页
注:
queryWrapper 表示实体对象封装操作类(可以为 null)
page 表示分页查询条件

2、Service 接口方法(CRUD)简单了解一下
==========================
(1)简介
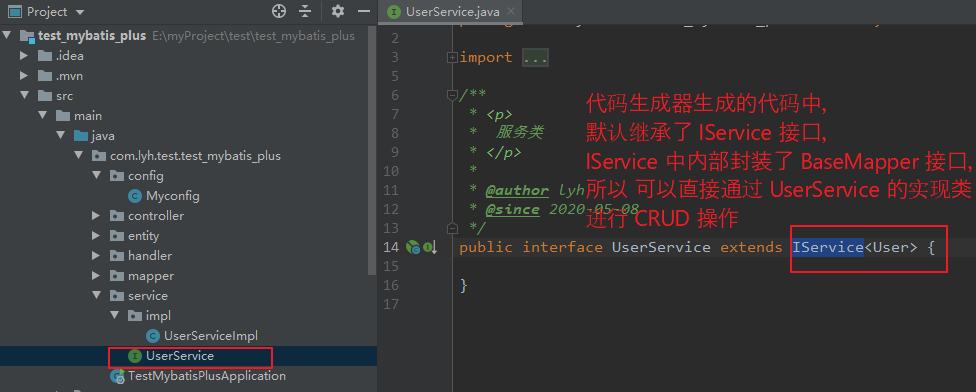
使用 代码生成器 生成的 service 接口中,其继承了 IService 接口。
IService 内部进一步封装了 BaseMapper 接口的方法(当然也提供了更详细的方法)。
使用时,可以通过 生成的 mapper 类进行 CRUD 操作,也可以通过 生成的 service 的实现类进行 CRUD 操作。(当然,自定义代码执行也可)
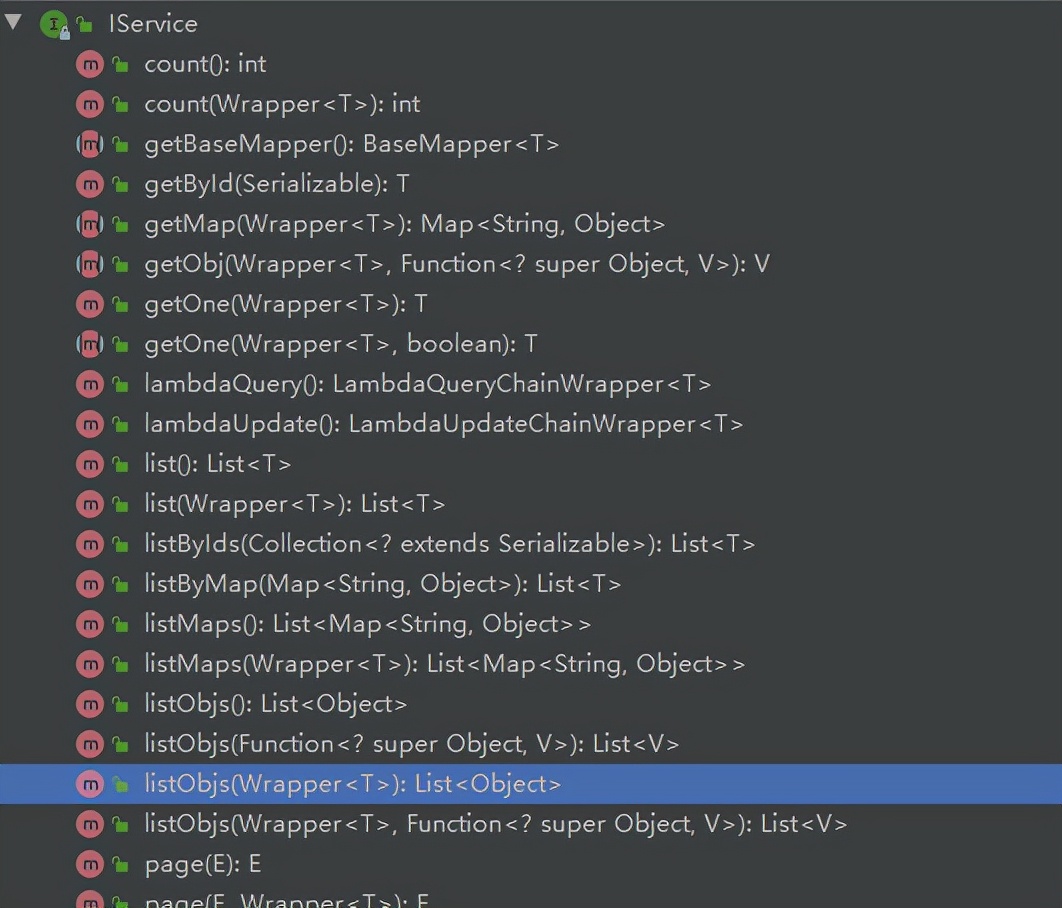
此处简单介绍一下 IService 中封装的常用方法。
(2)方法介绍
混个眼熟,用多了就记得了。
内部封装了 BaseMapper 的方法,也提供了新的方法。
比如:
添加了 批量更新 方法、更新或修改方法等。
对 查询方法 做了细化,使用 get 命名的方法查询一条数据,使用 list 命名的方法查询多条数据等。
增加了链式调用的方法。

【添加数据:(增)】
default boolean save(T entity); // 调用 BaseMapper 的 insert 方法,用于添加一条数据。
boolean saveBatch(Collection entityList, int batchSize); // 批量插入数据
注:
entityList 表示实体对象集合
batchSize 表示一次批量插入的数据量,默认为 1000
【添加或修改数据:(增或改)】
boolean saveOrUpdate(T entity); // id 若存在,则修改, id 不存在则新增数据
default boolean saveOrUpdate(T entity, Wrapper updateWrapper); // 先根据条件尝试更新,然后再执行 saveOrUpdate 操作
boolean saveOrUpdateBatch(Collection entityList, int batchSize); // 批量插入并修改数据
【删除数据:(删)】
default boolean removeById(Serializable id); // 调用 BaseMapper 的 deleteById 方法,根据 id 删除数据。
default boolean removeByMap(Map<String, Object> columnMap); // 调用 BaseMapper 的 deleteByMap 方法,根据 map 定义字段的条件删除
default boolean remove(Wrapper queryWrapper); // 调用 BaseMapper 的 delete 方法,根据实体类定义的 条件删除对象。
default boolean removeByIds(Collection<? extends Serializable> idList); // 用 BaseMapper 的 deleteBatchIds 方法, 进行批量删除。
【修改数据:(改)】
default boolean updateById(T entity); // 调用 BaseMapper 的 updateById 方法,根据 ID 选择修改。
default boolean update(T entity, Wrapper updateWrapper); // 调用 BaseMapper 的 update 方法,根据 updateWrapper 条件修改实体对象。
boolean updateBatchById(Collection entityList, int batchSize); // 批量更新数据
【查找数据:(查)】
default T getById(Serializable id); // 调用 BaseMapper 的 selectById 方法,根据 主键 ID 返回数据。
default List listByIds(Collection<? extends Serializable> idList); // 调用 BaseMapper 的 selectBatchIds 方法,批量查询数据。
default List listByMap(Map<String, Object> columnMap); // 调用 BaseMapper 的 selectByMap 方法,根据表字段条件查询
default T getOne(Wrapper queryWrapper); // 返回一条记录(实体类保存)。
Map<String, Object> getMap(Wrapper queryWrapper); // 返回一条记录(map 保存)。
default int count(Wrapper queryWrapper); // 根据条件返回 记录数。
default List list(); // 返回所有数据。
default List list(Wrapper queryWrapper); // 调用 BaseMapper 的 selectList 方法,查询所有记录(返回 entity 集合)。
default List<Map<String, Object>> listMaps(Wrapper queryWrapper); // 调用 BaseMapper 的 selectMaps 方法,查询所有记录(返回 map 集合)。
default List listObjs(); // 返回全部记录,但只返回第一个字段的值。
default <E extends IPage> E page(E page, Wrapper queryWrapper); // 调用 BaseMapper 的 selectPage 方法,分页查询
default <E extends IPage<Map<String, Object>>> E pageMaps(E page, Wrapper queryWrapper); // 调用 BaseMapper 的 selectMapsPage 方法,分页查询
注:
get 用于返回一条记录。
list 用于返回多条记录。
count 用于返回记录总数。
page 用于分页查询。
【链式调用:】
default QueryChainWrapper query(); // 普通链式查询
default LambdaQueryChainWrapper lambdaQuery(); // 支持 Lambda 表达式的修改
default UpdateChainWrapper update(); // 普通链式修改
default LambdaUpdateChainWrapper lambdaUpdate(); // 支持 Lambda 表达式的修改
注:
query 表示查询
update 表示修改
Lambda 表示内部支持 Lambda 写法。
形如:
query().eq(“column”, value).one();
lambdaQuery().eq(Entity::getId, value).list();
update().eq(“column”, value).remove();
lambdaUpdate().eq(Entity::getId, value).update(entity);

3、条件构造器(Wrapper,定义 where 条件)
============================
(1)简介
上面介绍的 接口方法的参数中,会出现各种 wrapper,比如 queryWrapper、updateWrapper 等。wrapper 的作用就是用于定义各种各样的查询条件(where)。

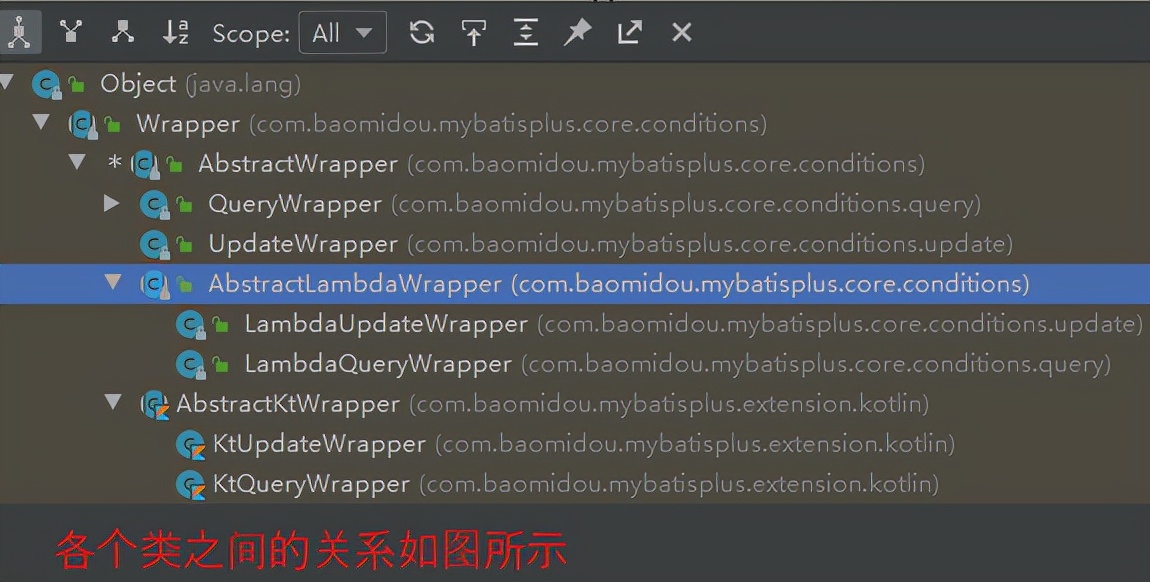
Wrapper 条件构造抽象类
– AbstractWrapper 查询条件封装,用于生成 sql 中的 where 语句。
– QueryWrapper Entity 对象封装操作类,用于查询。
– UpdateWrapper Update 条件封装操作类,用于更新。
– AbstractLambdaWrapper 使用 Lambda 表达式封装 wrapper
– LambdaQueryWrapper 使用 Lambda 语法封装条件,用于查询。
– LambdaUpdateWrapper 使用 Lambda 语法封装条件,用于更新。

(2)常用条件
参考源码以及官方文档总结的,还是一句话,混个眼熟,多用用就熟练了。

【通用条件:】
【比较大小: ( =, <>, >, >=, <, <= )】
eq(R column, Object val); // 等价于 =,例: eq(“name”, “老王”) —> name = ‘老王’
ne(R column, Object val); // 等价于 <>,例: ne(“name”, “老王”) —> name <> ‘老王’
gt(R column, Object val); // 等价于 >,例: gt(“name”, “老王”) —> name > ‘老王’
ge(R column, Object val); // 等价于 >=,例: ge(“name”, “老王”) —> name >= ‘老王’
lt(R column, Object val); // 等价于 <,例: lt(“name”, “老王”) —> name < ‘老王’
le(R column, Object val); // 等价于 <=,例: le(“name”, “老王”) —> name <= ‘老王’
【范围:(between、not between、in、not in)】
between(R column, Object val1, Object val2); // 等价于 between a and b, 例: between(“age”, 18, 30) —> age between 18 and 30
notBetween(R column, Object val1, Object val2); // 等价于 not between a and b, 例: notBetween(“age”, 18, 30) —> age not between 18 and 30
in(R column, Object… values); // 等价于 字段 IN (v0, v1, …),例: in(“age”,{1,2,3}) —> age in (1,2,3)
notIn(R column, Object… values); // 等价于 字段 NOT IN (v0, v1, …), 例: notIn(“age”,{1,2,3}) —> age not in (1,2,3)
inSql(R column, Object… values); // 等价于 字段 IN (sql 语句), 例: inSql(“id”, “select id from table where id < 3”) —> id in (select id from table where id < 3)
notInSql(R column, Object… values); // 等价于 字段 NOT IN (sql 语句)
【模糊匹配:(like)】
like(R column, Object val); // 等价于 LIKE ‘%值%’,例: like(“name”, “王”) —> name like ‘%王%’
notLike(R column, Object val); // 等价于 NOT LIKE ‘%值%’,例: notLike(“name”, “王”) —> name not like ‘%王%’
likeLeft(R column, Object val); // 等价于 LIKE ‘%值’,例: likeLeft(“name”, “王”) —> name like ‘%王’
likeRight(R column, Object val); // 等价于 LIKE ‘值%’,例: likeRight(“name”, “王”) —> name like ‘王%’
【空值比较:(isNull、isNotNull)】
isNull(R column); // 等价于 IS NULL,例: isNull(“name”) —> name is null
isNotNull(R column); // 等价于 IS NOT NULL,例: isNotNull(“name”) —> name is not null
【分组、排序:(group、having、order)】
groupBy(R… columns); // 等价于 GROUP BY 字段, …, 例: groupBy(“id”, “name”) —> group by id,name
orderByAsc(R… columns); // 等价于 ORDER BY 字段, … ASC, 例: orderByAsc(“id”, “name”) —> order by id ASC,name ASC
orderByDesc(R… columns); // 等价于 ORDER BY 字段, … DESC, 例: orderByDesc(“id”, “name”) —> order by id DESC,name DESC
having(String sqlHaving, Object… params); // 等价于 HAVING ( sql语句 ), 例: having(“sum(age) > {0}”, 11) —> having sum(age) > 11
【拼接、嵌套 sql:(or、and、nested、apply)】
or(); // 等价于 a or b, 例:eq(“id”,1).or().eq(“name”,“老王”) —> id = 1 or name = ‘老王’
or(Consumer consumer); // 等价于 or(a or/and b),or 嵌套。例: or(i -> i.eq(“name”, “李白”).ne(“status”, “活着”)) —> or (name = ‘李白’ and status <> ‘活着’)
and(Consumer consumer); // 等价于 and(a or/and b),and 嵌套。例: and(i -> i.eq(“name”, “李白”).ne(“status”, “活着”)) —> and (name = ‘李白’ and status <> ‘活着’)
nested(Consumer consumer); // 等价于 (a or/and b),普通嵌套。例: nested(i -> i.eq(“name”, “李白”).ne(“status”, “活着”)) —> (name = ‘李白’ and status <> ‘活着’)
apply(String applySql, Object… params); // 拼接sql(若不使用 params 参数,可能存在 sql 注入),例: apply(“date_format(dateColumn,‘%Y-%m-%d’) = {0}”, “2008-08-08”) —> date_format(dateColumn,‘%Y-%m-%d’) = ‘2008-08-08’")
last(String lastSql); // 无视优化规则直接拼接到 sql 的最后,可能存若在 sql 注入。
exists(String existsSql); // 拼接 exists 语句。例: exists(“select id from table where age = 1”) —> exists (select id from table where age = 1)
【QueryWrapper 条件:】
select(String… sqlSelect); // 用于定义需要返回的字段。例: select(“id”, “name”, “age”) —> select id, name, age
select(Predicate predicate); // Lambda 表达式,过滤需要的字段。
lambda(); // 返回一个 LambdaQueryWrapper
【UpdateWrapper 条件:】
set(String column, Object val); // 用于设置 set 字段值。例: set(“name”, null) —> set name = null
etSql(String sql); // 用于设置 set 字段值。例: setSql(“name = ‘老李头’”) —> set name = ‘老李头’
lambda(); // 返回一个 LambdaUpdateWrapper

(3)简单使用,测试一下 QueryWrapper

@Test
public void testQueryWrapper() {
// Step1:创建一个 QueryWrapper 对象
QueryWrapper queryWrapper = new QueryWrapper<>();
// Step2: 构造查询条件
queryWrapper
.select(“id”, “name”, “age”)
.eq(“age”, 20)
.like(“name”, “j”);
// Step3:执行查询
userService
.list(queryWrapper)
.forEach(System.out::println);
}

自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

写在最后
可能有人会问我为什么愿意去花时间帮助大家实现求职梦想,因为我一直坚信时间是可以复制的。我牺牲了自己的大概十个小时写了这片文章,换来的是成千上万的求职者节约几天甚至几周时间浪费在无用的资源上。


上面的这些(算法与数据结构)+(Java多线程学习手册)+(计算机网络顶级教程)等学习资源
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
头’") —> set name = ‘老李头’
lambda(); // 返回一个 LambdaUpdateWrapper
(3)简单使用,测试一下 QueryWrapper
@Test
public void testQueryWrapper() {
// Step1:创建一个 QueryWrapper 对象
QueryWrapper queryWrapper = new QueryWrapper<>();
// Step2: 构造查询条件
queryWrapper
.select(“id”, “name”, “age”)
.eq(“age”, 20)
.like(“name”, “j”);
// Step3:执行查询
userService
.list(queryWrapper)
.forEach(System.out::println);
}
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。[外链图片转存中…(img-tIvNCdNL-1713476144460)]
[外链图片转存中…(img-fsFNCUYl-1713476144463)]
[外链图片转存中…(img-ethaBsRX-1713476144465)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)
写在最后
可能有人会问我为什么愿意去花时间帮助大家实现求职梦想,因为我一直坚信时间是可以复制的。我牺牲了自己的大概十个小时写了这片文章,换来的是成千上万的求职者节约几天甚至几周时间浪费在无用的资源上。
[外链图片转存中…(img-tkog8YkH-1713476144466)]
[外链图片转存中…(img-jy65Audf-1713476144468)]
上面的这些(算法与数据结构)+(Java多线程学习手册)+(计算机网络顶级教程)等学习资源
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 4362
4362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









