







最后
文章到这里就结束了,如果觉得对你有帮助可以点个赞哦
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】

+ [`14、请你说说各数据类型 sizeof 是多少,sizeof 指针是多少,sizeof 原理`](#14_sizeof_sizeof_sizeof__132)
+ [`15、说说 const 和 define 的区别`](#15_const__define__138)
+ [`16、请你说说 Redis 如何与数据库保持双写一致性`](#16_Redis__147)
+ [`17、请你说说C++引用的概念`](#17C_152)
+ [`18、请你说说迭代器失效原因,有哪些情况`](#18_161)
+ [`19、请你说说动态库静态库的区别和优缺点`](#19_168)
+ [`20、请你说说虚函数可以是内联函数吗`](#20_177)
1、请你说说 GET 和 POST 的区别?
简述:post采用隐式传参,get采用显示传参。get传输数据有长度的现实,而post没有长度的限制。get常用来获取数据,post常用来提交数据。get请求会被浏览器主动缓存,post请求不会被浏览器主动缓存,可手动设置缓存。get请求只支持url编码,post请求支持多种编码方式(img,text,application等等)
得分点 用法不一样、参数显隐式、参数长度。 标准回答 get主要用来获取数据,而post是提交或修改数据。get有长度限制(2048字节)而post没有。get的参数是显式的,而post是隐式的。加分回答- get主要用来获取数据,post主要用来提交数据。 - get的参数有长度限制,最长2048字节,而post没有限制。 - get的参数会附加在url之 ,以 " ? "分割url和传输数据,多个参数用 "&"连接,而post会把参数放在http请求体中。 - get是明文传输,可以直接通过url看到参数信息,post是放在请求体中,除非用工具才能看到。 - get请求会保存在浏览器历史记录中,也可以保存在web服务器日志中。 - get在浏览器回退时是无害的,而post会再次提交请求。 - get请求会被浏览器主动缓存,而post不会,除非手动设置。 - get请求只能进行url编码,而post支持多种编码方式。 - get请求的参数数据类型只接受ASCII字符,而post没有限制。 |
|---|
2、简述一下 C++ 中的多态?
简述:多态分为静态多态和动态多态。静态多态是在编译期间完成的,编译器会根据实参类型选择合适的函数调用,如果存在就调用,不存在就报错。静态多态有函数重载,运算符重载,泛型编程等。动态多态是根据基类指针或引用指向的对象,来确定调用哪个函数的过程,比如父类指针指向父类对象,则调用父类对象的虚函数;父类指针指向子类对象,则调用子类对象中的虚函数。动态多态的条件,要有继承关系,函数重写,父类指针指向子类对象。动态多态的原理是,当对象中声明了虚函数,就会在类中生成一个虚函数表,这个是有编译器自动生成和维护的。虚函数表中存放虚函数指针,每个对象都会有一个虚指针,虚指针会根据这个对象在对应类中的虚函数表里查找被调用的函数,进行调用。
得分点 静态多态、动态多态、多态的实现原理、虚函数、虚函数表 标准回答 在现实生活中,多态是同一个事物在不同场景下的多种形态。在面向对象中,多态是指通过基类的指针或者引用,在运行时动态调用实际绑定对象函数的行为,与之相对应的编译时绑定函数称为静态绑定。所以多态分为静态多态和动态多态。 1.静态多态 静态多态是编译器在编译期间完成的,编译器会根据实参类型来选择调用合适的函数,如果有合适的函数就调用,没有的话就会发出警告或者报错。静态多态有函数重载、运算符重载、泛型编程等。 2. 动态多态 动态多态是在程序运行时根据基类的引用(指针)指向的对象来确定自己具体该调用哪一个类的虚函数。当父类指针(引用)指向 父类对象时,就调用父类中定义的虚函数;即当父类指针(引用)指向 子类对象时,就调用子类中定义的虚函数。 加分回答 1. 动态多态行为的表现效果为:同样的调用语句在实际运行时有多种不同的表现形态。 2. 实现动态多态的条件: - 要有继承关系 - 要有虚函数重写(被 virtual 声明的函数叫虚函数) - 要有父类指针(父类引用)指向子类对象 3. 动态多态的实现原理 当类中声明虚函数时,编译器会在类中生成一个虚函数表,虚函数表是一个存储类虚函数指针的数据结构, 虚函数表是由编译器自动生成与维护的。virtual 成员函数会被编译器放入虚函数表中,存在虚函数时,每个对象中都有一个指向虚函数表的指针(vptr 指针)。在多态调用时, vptr 指针就会根据这个对象在对应类的虚函数表中查找被调用的函数,从而找到函数的入口地址。 |
|---|
3、说一说进程有多少种状态,如何转换?
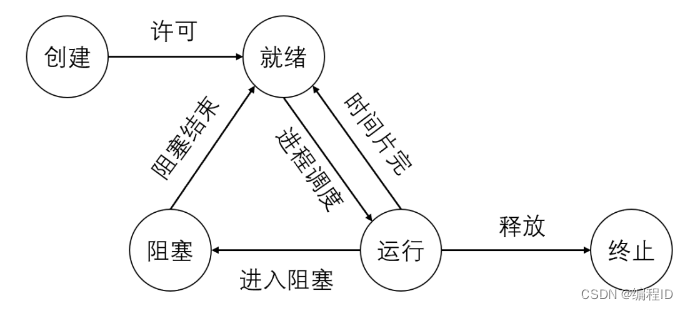
得分点
创建、就绪、执行、阻塞、终止
标准回答
- 进程有五种状态:创建、就绪、执行、阻塞、终止:
- 创建:一个进程启动,首先进入创建状态,需要获取系统资源创建进程管理块(PCB:Process Control Block)完成资源分配。
- 就绪状态:在创建状态完成之后,进程已经准备好,处于就绪状态,但是还未获得处理器资源,无法运行。
- 运行状态:获取处理器资源,被系统调度,当具有时间片开始进入运行状态。如果进程的时间片用完了就进入就绪状态。
- 阻塞状态:在运行状态期间,如果进行了阻塞的操作,此时进程暂时无法操作就进入到了阻塞状态,在这些操作完成后就进入就绪状态。等待再次获取处理器资源,被系统调度,当具有时间片就进入运行状态。
- 终止状态:进程结束或者被系统终止,进入终止状态。
3、请你说说指针和引用的区别
标准回答 指针和引用的区别有:
-
- 定义和性质不同。指针是一种数据类型,用于保存地址类型的数据,而引用可以看成是变量的别名。指针定义格式为:数据类型 *;而引用的定义格式为:数据类型 &;
-
- 引用不可以为空,当被创建的时候必须初始化,而指针变量可以是空值,在任何时候初始化;
-
- 指针可以有多级,但引用只能是一级;
-
- 引用使用时无需解引用(*),指针需要解引用;
-
- 指针变量的值可以是 NULL,而引用的值不可以为 NULL;
-
- 指针的值在初始化后可以改变,即指向其它的存储单元,而引用在进行初始化后就不会再改变了;
-
- sizeof 引用得到的是所指向的变量(对象)的大小,而 sizeof 指针得到的是指针变量本身的大小;
-
- 指针作为函数参数传递时传递的是指针变量的值,而引用作为函数参数传递时传递的是实参本身,而不是拷贝副本;
-
- 指针和引用进行++运算意义不一样。
4、简述一下虚函数的实现原理
简述:
虚函数的作用:主要是实现了动态多态的机制。用父类型的指针指向其子类的实例,然后通过父类指针调用实际子类的成员函数。
实现原理:编译器在处理虚函数时,给每个对象添加一个虚函数指针,指向虚函数表。虚函数表中存储的是类中虚函数的地址。如果派生类重写了基类的虚函数,则派生类对象的虚函数表中保存的是派生类的虚函数地址,如果没有重写,则派生类对象的虚函数表中保存的是父类的虚函数地址。
消耗成本:使用虚函数时,对于内存和执行速度方面有一定的成本消耗。
1.每个对象都会变大,变大的量为存储虚函数表指针;
2.对于每个类,编译器都会创建一个虚函数表;
3.每次调用虚函数,都要有查表操作,增加了时间开销
得分点 多态、虚函数表、虚函数表指针 标准回答 1. 虚函数的作用 C++ 中的虚函数的作用主要是实现了动态多态的机制。动态多态,简单的说就是用父类型的指针指向其子类的实例,然后通过父类的指针调用实际子类的成员函数。这种技术可以让父类的指针有“多种形态”,这是一种泛型技术。 2. 虚函数实现原理 编译器处理虚函数时,给每个对象添加一个隐藏的成员。隐藏的成员是一个指针类型的数据,指向的是函数地址数组,这个数组被称为虚函数表(virtual function table,vtbl)。虚函数表中存储的是类中的虚函数的地址。如果派生类重写了基类中的虚函数,则派生类对象的虚函数表中保存的是派生类的虚函数地址,如果派生类没有重写基类中的虚函数,则派生类对象的虚函数表中保存的是父类的虚函数地址。 加分回答 使用虚函数时,对于内存和执行速度方面会有一定的成本:1.每个对象都会变大,变大的量为存储虚函数表指针; 2. 对于每个类,编译器都会创建一个虚函数表; 3. 对于每次调用虚函数,都需要额外执行一个操作,就是到表中查找虚函数地址。` |
|---|
5、说一说 vector 和 list 的区别,分别适用于什么场景?
解题思路
得分点 低层数据结构、内存顺序、是否支持随机访问
标准回答
-
- 区别 - vector 底层实现是数组,list 是双向链表 - vector 支持随机访问,list 不支持 - vector 是顺序内存,list 不是 - vector 在中间节点进行插入删除会导致内存拷贝,list 不会 - vector 一次性分配好内存,不够时才进行扩容,list 每次插入新节点都会进行内存申请 - vector 随机访问性能好,插入删除性能差,list 随机访问性能差,插入删除性能好
-
- 适用场景 - vecto r拥有一段连续的内存空间,因此支持随机访问,如果需要高效的随即访问,而不在乎插入和删除的效率,使用 vector。 - list 拥有一段不连续的内存空间,如果需要高效的插入和删除,而不关心随机访问,则应使用list。
6、什么是孤儿进程,什么是僵尸进程,如何解决僵尸进程
得分点 父进程先结束、占用系统资源、wt()、wtpid()
标准回答
-
- 孤儿进程 孤儿进程是指一个父进程退出后,而它的一个或多个子进程还在运行,那么这些子进程将成为孤儿进程。孤儿进程将被 init 进程(进程号为1)所收养,并且由 init 进程对它们完整状态收集工作,孤儿进程一般不会产生任何危害。
-
- 僵尸进程 僵尸进程是指一个进程使用 fork() 函数创建子进程,如果子进程退出,而父进程并没有调用 wt() 或者wtpid() 系统调用取得子进程的终止状态,那么子进程的进程描述符仍然保存在系统中,占用系统资源,这种进程称为僵尸进程。
-
- 解决僵尸进程 一般,为了防止产生僵尸进程,在 fork() 子进程之后我们都要及时在父进程中使用 wt() 或者 wtpid() 系统调用,等子进程结束后,父进程回收子进程 PCB 的资源。 同时,当子进程退出的时候,内核都会给父进程一个 SIGCHLD 信号,所以可以建立一个捕获 SIGCHLD 信号的信号处理函数,在函数体中调用 wt() 或 wtpid(),就可以清理退出的子进程以达到防止僵尸进程的目的。
7、请你说说 C++ Lambda 表达式用法及实现原理
答案字数太多,必免看了烦,建议自行查询!!!
8、请你说说 innodb 和 myisam 的区别
简述:
InnoDB:支持事务、行锁和外键,批量插入慢,空间、内存消耗高。 MyIsAM:不支持事务、不支持行锁,只支持表锁,不支持外键,批量插入快,空间、内存消耗较低。
得分点 事务、锁、读写性能、存储结构 标准回答 InnoDB是具有事务、回滚和崩溃修复能力的事务安全型引擎,它可以实现行级锁来保证高性能的大量数据中的并发操作;MyISAM是具有默认支持全文索引、压缩功能及较高查询性能的非事务性引擎。具体来说,可以在以下角度上形成对比: 事务:InnoDB支持事务;MyISAM不支持。 数据锁:InnoDB支持行级锁;MyISAM只支持表级锁。 读写性能:InnoDB增删改性能更优;MyISAM查询性能更优。 全文索引:InnoDB不支持(但可通过插件等方式支持);MyISAM默认支持。 外键:InnoDB支持外键;MyISAM不支持。 存储结构:InnoDB在磁盘存储为一个文件;MyISAM在磁盘上存储成三个文件(表定义、数据、索引)。 存储空间:InnoDB需要更多的内存和存储;MyISAM支持支持三种不同的存储格式:静态表(默认)、动态表、压缩表。 移植:InnoDB在数据量小时可通过拷贝数据文件、备份 binlog、mysqldump工具移植,数据量大时比较麻烦;可单独对某个表通过拷贝表文件移植。 崩溃恢复:InnoDB有崩溃恢复机制;MyISAM没有。 默认推荐:InnoDB是MySQL5.5之后的默认引擎。 加分回答 InnoDB中行级锁是怎么实现的? InnoDB行级锁是通过给索引上的索引项加锁来实现的。只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁。 当表中锁定其中的某几行时,不同的事务可以使用不同的索引锁定不同的行。另外,不论使用主键索引、唯一索引还是普通索引,InnoDB都会使用行锁来对数据加锁。 |
|---|
9、请你说说数据库的索引是什么结构,为什么不用哈希表?
得分点 B+树、内存资源
标准回答 MySQL中的索引B+树实现的; 哈希表的查询效率的确最高,时间复杂度O(1),但是它要求将所有数据载入内存,而数据库存储的数据量级可能会非常大,全部载入内存基本上是不可能实现的; B+树可以分段加载需要的节点数据,可以在内存资源有限的前提下,极大提高查询效率
10、虚析构函数有什么作用?
得分点 概念、防止内存泄露
标准回答
-
- 概念 虚析构函数,是将基类的析构函数声明为 virtual class Base { public: Base() { } // 虚析构函数 virtual ~Base() { } }
-
- 作用 虚析构函数的主要作用是为了防止遗漏资源的释放,防止内存泄露。如果基类中的析构函数没有声明为虚函数,基类指针指向派生类对象时,则当基类指针释放时不会调用派生类对象的析构函数,而是调用基类的析构函数,如果派生类析构函数中做了某些释放资源的操作,则这时就会造成内存泄露。
11、说一说常用的 Linux 命令?(常见)
标准回答 常用的 Linux 命令有:
cd:切换当前目录
ls:查看当前文件与目录
grep:通常与管道命令一起使用,用于对一些命令的输出进行筛选加工
cp:复制文件或文件夹
mv:移动文件或文件夹
rm:删除文件或文件夹
ps:查看进程情况
kill:向进程发送信号
tar:对文件进行打包
cat:查看文件内容
top:查看操作系统的信息,如进程、CPU占用率、内存信息等(实时) free:查看内存使用情况
pwd:显示当前工作目录
12、简述一下堆和栈的区别
得分点 管理方式、空间大小、是否产生内存碎片、生长方向、分配方式、分配效率
标准回答 堆和栈主要有如下几点区别:管理方式、空间大小、是否产生内存碎片、生长方向、分配方式、分配效率。
-
- 管理方式 对于栈来讲,是由编译器自动管理,无需手动控制;对于堆来说,分配和释放都是由程序员控制的。
-
- 空间大小 总体来说,栈的空间是要小于堆的。堆内存几乎是没有什么限制的;但是对于栈来讲,一般是有一定的空间大小的。
-
- 碎片问题 对于堆来讲,由于分配和释放是由程序员控制的(利用new/delete 或 malloc/free),频繁的操作势必会造成内存空间的不连续,从而造成大量的内存碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的数据结构,在某一数据弹出之前,它之前的所有数据都已经弹出。
-
- 生长方向 对于堆来讲,生长方向是向上的,也就是沿着内存地址增加的方向,对于栈来讲,它的生长方式是向下的,也就是沿着内存地址减小的方向增长。
-
- 分配方式 堆都是动态分配的,没有静态分配的堆。栈有两种分配方式:静态分配和动态分配,静态分配是编译器完成的,比如局部变量的分配;动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,它的动态分配是由编译器实现的,无需我们手工实现。
-
- 分配效率 栈是机器系统提供的数据结构,计算机会在底层对栈提供支持,分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率很高。堆则是 C/C++ 函数提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率要比栈底的多。
13、请你说说重载,复写,隐藏的区别
得分点
定义、作用域、有无 virtual、函数名、形参列表、返回值类型
算法刷题
大厂面试还是很注重算法题的,尤其是字节跳动,算法是问的比较多的,关于算法,推荐《LeetCode》和《算法的乐趣》,这两本我也有电子版,字节跳动、阿里、美团等大厂面试题(含答案+解析)、学习笔记、Xmind思维导图均可以分享给大家学习。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
写在最后
最后,对所以做Java的朋友提几点建议,也是我的个人心得:
-
疯狂编程
-
学习效果可视化
-
写博客
-
阅读优秀代码
-
心态调整
4304bb5a486d4c3ab8389e65ecb71ac0)**
写在最后
最后,对所以做Java的朋友提几点建议,也是我的个人心得:
-
疯狂编程
-
学习效果可视化
-
写博客
-
阅读优秀代码
-
心态调整
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









