







目录
- 标签(题目类型):链表
题目描述
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:
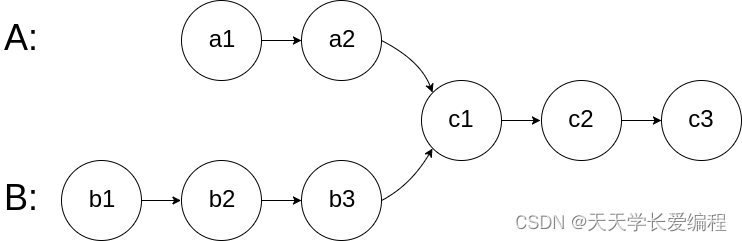
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0
listA - 第一个链表
listB - 第二个链表
skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数
skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
示例 1:
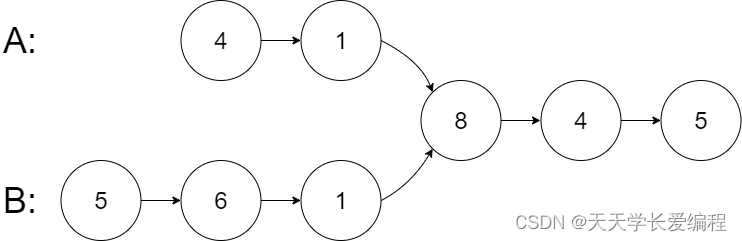
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at ‘8’
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
— 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。
示例 2:
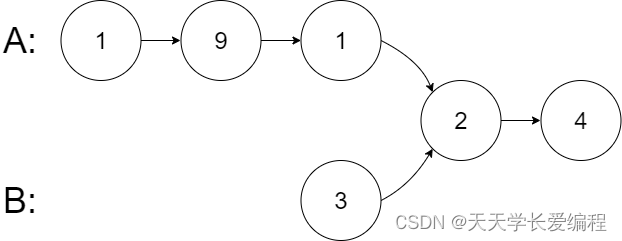
输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at ‘2’
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [1,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
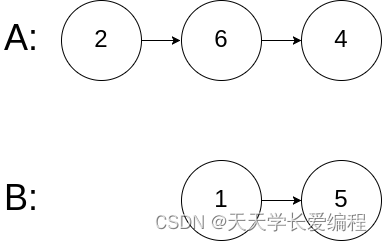
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
提示:
listA 中节点数目为 m
listB 中节点数目为 n
1 <= m, n <= 3 * 104
1 <= Node.val <= 105
0 <= skipA <= m
0 <= skipB <= n
如果 listA 和 listB 没有交点,intersectVal 为 0
如果 listA 和 listB 有交点,intersectVal == listA[skipA] == listB[skipB]
进阶:你能否设计一个时间复杂度 O(m + n) 、仅用 O(1) 内存的解决方案?
思路及实现
方式一:哈希表
思路
使用哈希表来存储链表中的节点。遍历第一个链表的所有节点,将它们存储在哈希表中。然后遍历第二个链表,如果某个节点已经在哈希表中,那么这个节点就是两个链表的相交点。
代码实现
Java版本
public class ListNode {
int val;
ListNode next;
ListNode(int x) { val = x; }
}
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
Set<ListNode> set = new HashSet<>();
ListNode nodeA = headA;
while (nodeA != null) {
set.add(nodeA);
nodeA = nodeA.next;
}
ListNode nodeB = headB;
while (nodeB != null) {
if (set.contains(nodeB)) {
return nodeB;
}
nodeB = nodeB.next;
}
return null;
}
}
说明:使用
HashSet来存储链表A的节点,然后遍历链表B,检查每个节点是否在HashSet中出现过。如果出现过,则返回该节点;否则返回null。
C语言版本
#include <stdio.h>
#include <stdlib.h>
typedef struct ListNode {
int val;
struct ListNode *next;
} ListNode;
ListNode* getIntersectionNode(ListNode *headA, ListNode *headB) {
// C语言中没有内置的哈希表,需要使用其他数据结构(如数组、链表)来实现类似功能
// 这里为了简化,不给出完整实现
// ...
return NULL; // 示例返回,实际需要根据具体实现返回结果
}
说明:C语言中没有内置的哈希表,需要自行实现或使用其他数据结构(如链表)来模拟哈希表的功能。这里为了简化,不给出完整实现。
Python3版本
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:
setA = set()
while headA:
setA.add(headA)
headA = headA.next
while headB:
if headB in setA:
return headB
headB = headB.next
return None
说明:使用Python的
set数据结构来存储链表A的节点,然后遍历链表B,检查每个节点是否在setA中出现过。
Golang版本
package main
import (
"fmt"
)
type ListNode struct {
Val int
Next *ListNode
}
func getIntersectionNode(headA, headB *ListNode) *ListNode {
setA := make(map[*ListNode]bool)
for node := headA; node != nil; node = node.Next {
setA[node] = true
}
for node := headB; node != nil; node = node.Next {
if _, ok := setA[node]; ok {
return node
}
}
return nil
}
func main() {
// 示例代码,未完整实现链表创建和测试
// ...
}
说明:使用Golang的
map数据结构来存储链表A的节点,然后遍历链表B,检查每个节点是否在setA中出现过。
复杂度分析
- 时间复杂度:O(m + n),其中m和n分别为两个链表的长度。因为需要遍历两个链表各一次。
- 空间复杂度是O(m),其中m是链表A的长度。
说明
在方式一中,我们使用了一个哈希表(通常是哈希集合或哈希映射)来存储链表A中的节点。假设链表A的长度为m,链表B的长度为n,那么在最坏的情况下,我们需要将链表A中的所有m个节点都存储到哈希表中。
因此,哈希表将占用O(m)的空间(假设哈希表的空间复杂度是线性的,这取决于具体的哈希表实现)。除了哈希表之外,我们没有使用额外的数据结构,因此总的空间复杂度是O(m)。
*注意,这里我们没有考虑哈希表内部可能存在的空间开销(如哈希函数的计算、哈希冲突的解决等),因为这些通常与节点数量m成常数比例或对数比例,并且对于分析算法的空间复杂度来说,通常可以忽略不计。
方式二:双指针
思路
我们可以使用双指针法来解决这个问题。首先,让两个指针pA和pB分别指向两个链表的头节点headA和headB。然后,让它们同时遍历两个链表。当指针pA到达链表A的尾部时,让它指向链表B的头节点headB;当指针pB到达链表B的尾部时,让它指向链表A的头节点headA。这样,如果两个链表相交,两个指针最终会在交点处相遇;如果两个链表不相交,两个指针最终都会指向null。
代码实现
Java版本
public class ListNode {
int val;
ListNode next;
ListNode(int x) { val = x; }
}
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) {
return null;
}
ListNode pA = headA, pB = headB;
while (pA != pB) {
pA = pA == null ? headB : pA.next;
pB = pB == null ? headA : pB.next;
}
return pA;
}
}
说明:使用两个指针
pA和pB同时遍历两个链表。如果pA到达链表A的尾部,则将其指向headB;如果pB到达链表B的尾部,则将其指向headA。当两个指针相遇或都为null时,遍历结束。
C语言版本
#include <stdio.h>
#include <stdlib.h>
typedef struct ListNode {
int val;
struct ListNode *next;
} ListNode;
ListNode* getIntersectionNode(ListNode *headA, ListNode *headB) {
if (headA == NULL || headB == NULL) {
return NULL;
}
ListNode *pA = headA, *pB = headB;
while (pA != pB) {
pA = pA == NULL ? headB : pA->next;
pB = pB == NULL ? headA : pB->next;
}
return pA;
}
说明:C语言版本的实现与Java版本类似,只是语法和类型定义有所不同。
Python3版本
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:
if not headA or not headB:
return None
pA, pB = headA, headB
while pA != pB:
pA = pA.next if pA else headB
pB = pB.next if pB else headA
return pA
说明:Python版本的实现使用了类和方法,但核心逻辑与Java和C语言版本相同。
Golang版本
package main
type ListNode struct {
Val int
Next *ListNode
}
func getIntersectionNode(headA, headB *ListNode) *ListNode {
if headA == nil || headB == nil {
return nil
}
pA, pB := headA, headB
for pA != pB {
if pA == nil {
pA = headB
} else {
pA = pA.Next
}
if pB == nil {
pB = headA
} else {
pB = pB.Next
}
}
return pA
}
func main() {
// 示例代码,未完整实现链表创建和测试
// ...
}
说明:Golang版本的实现使用了结构体和指针,核心逻辑与其他版本相同。
复杂度分析
- 时间复杂度:O(m + n),其中m和n分别为两个链表的长度。因为最多遍历两个链表各两次(当两个链表不相交时)。
- 空间复杂度:O(1),因为只使用了常数个额外变量。
总结
| 方式 | 优点 | 缺点 | 时间复杂度 | 空间复杂度 |
|---|---|---|---|---|
| 方式一(哈希表) | 不依赖链表结构,灵活性强 | 需要额外的哈希表空间 | O(m + n) | O(m) |
| 方式二(双指针) | 代码简洁,空间复杂度低 | 需要处理两个链表可能不相交的情况 | O(m + n) | O(1) |
相似题目
| 相似题目 | 难度 | 链接 |
|---|---|---|
| leetcode 160 相交链表 | 简单 | 力扣-160 |
| leetcode 349 两个数组的交集 | 简单 | 力扣-349 |
| leetcode 350 两个数组的交集 II | 简单 | 力扣-350 |
| 面试题 16.07 交集 | 中等 | 面试题 16.07 |
请注意,上述链接均为中文版的力扣链接,如果需要英文版的链接,请将leetcode-cn.com替换为leetcode.com。
此外,虽然这些题目在表面上看似不同(例如,有的是关于链表,有的是关于数组),但它们的核心思路都是寻找两个集合(链表或数组)的交集。在处理这些题目时,可以考虑使用哈希表、双指针等不同的方法来优化算法的性能。
欢迎一键三连(关注+点赞+收藏),技术的路上一起加油!!!代码改变世界
关于我:阿里非典型程序员一枚 ,记录在大厂的打怪升级之路。 一起学习Java、大数据、数据结构算法(公众号同名),回复暗号,更能获取学习秘籍和书籍等
—⬇️欢迎关注下面的公众号:
进朱者赤,认识不一样的技术人。⬇️—















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









