







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
// getAndUpdate 如果在 lambda 中引用了外部的局部变量,要保证该局部变量是 final 的
// getAndAccumulate 可以通过 参数1 来引用外部的局部变量,但因为其不在 lambda 中因此不必是 final
System.out.println(i.getAndAccumulate(10, (p, x) -> p + x));
// 计算并获取(i = 10, p 为 i 的当前值, x 为参数1, 结果 i = 0, 返回 0)
// 其中函数中的操作能保证原子,但函数需要无副作用
System.out.println(i.accumulateAndGet(-10, (p, x) -> p + x));
4-1 原子引用的使用
为什么需要原子引用类型?
-
AtomicReference -
AtomicMarkableReference -
AtomicStampedReference
有如下方法:
public interface DecimalAccount {
BigDecimal getBalance();
void withdraw(BigDecimal amount);
/**
-
方法内会启动 1000 个线程,每个线程做 -10 元 的操作
-
如果初始余额为 10000 那么正确的结果应当是 0
*/
static void demo(DecimalAccountImpl account) {
List ts = new ArrayList<>();
long start = System.nanoTime();
for (int i = 0; i < 1000; i++) {
ts.add(new Thread(() -> {
account.withdraw(BigDecimal.TEN);
}));
}
ts.forEach(Thread::start);
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.nanoTime();
System.out.println(account.getBalance() + " cost: " + (end - start) / 1000_000 + " ms");
}
}
class DecimalAccountImpl implements DecimalAccount {
//原子引用,泛型类型为小数类型
AtomicReference balance;
public DecimalAccountImpl(BigDecimal balance) {
this.balance = new AtomicReference(balance);
}
@Override
public BigDecimal getBalance() {
return balance.get();
}
@Override
public void withdraw(BigDecimal amount) {
while(true) {
BigDecimal pre = balance.get();
BigDecimal next = pre.subtract(amount);
if(balance.compareAndSet(pre, next)) {
break;
}
}
}
public static void main(String[] args) {
DecimalAccount.demo(new DecimalAccountImpl(new BigDecimal(“10000”)));
}
}
4-2 ABA 问题及解决
ABA问题
因为CAS需要在操作值的时候,检查值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加1,那么A→B→A就会变成1A→2B→3A
从 Java 1.5开始,JDK的Atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法的作用是首先检查当前引用是否等于预期引用,并且检查当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值
AtomicStampedReference
@Slf4j
public class Test3 {
static AtomicStampedReference ref = new AtomicStampedReference<>(“A”, 0);
public static void main(String[] args) {
log.debug(“main start…”);
// 获取值 A
String prev = ref.getReference();
// 获取版本号
int stamp = ref.getStamp();
log.debug(“版本 {}”, stamp);
// 如果中间有其它线程干扰,发生了 ABA 现象
other();
sleep(1);
// 尝试改为 C
log.debug(“change A->C {}”, ref.compareAndSet(prev, “C”, stamp, stamp + 1));
}
private static void other() {
ref.compareAndSet(ref.getReference(), “B”, ref.getStamp(), ref.getStamp() + 1);
ref.compareAndSet(ref.getReference(), “A”, ref.getStamp(), ref.getStamp() + 1);
}
}
22:48:31 DEBUG [main] (Test3.java:16) - main start…
22:48:31 DEBUG [main] (Test3.java:21) - 版本 0
22:48:32 DEBUG [main] (Test3.java:26) - change A->C false
AtomicStampedReference 可以给原子引用加上版本号,追踪原子引用整个的变化过程,如: A -> B -> A -> C ,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了几次。
但是有时候,并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了 AtomicMarkableReference
AtomicMarkableReference
class GarbageBag {
String desc;
public GarbageBag(String desc) {
this.desc = desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
@Override
public String toString() {
return super.toString() + " " + desc;
}
}
@Slf4j
public class TestABAAtomicMarkableReference {
public static void main(String[] args) throws InterruptedException {
GarbageBag bag = new GarbageBag(“装满了垃圾”);
// 参数2 mark 可以看作一个标记,表示垃圾袋满了
AtomicMarkableReference ref = new AtomicMarkableReference<>(bag, true);
log.debug(“主线程 start…”);
GarbageBag prev = ref.getReference();
log.debug(prev.toString());
new Thread(() -> {
log.debug(“打扫卫生的线程 start…”);
bag.setDesc(“空垃圾袋”);
while (!ref.compareAndSet(bag, bag, true, false)) {}
log.debug(bag.toString());
}).start();
Thread.sleep(1000);
log.debug(“主线程想换一只新垃圾袋?”);
boolean success = ref.compareAndSet(prev, new GarbageBag(“空垃圾袋”), true, false);
log.debug(“换了么?” + success);
log.debug(ref.getReference().toString());
}
}
22:50:57 DEBUG [main] (Test5.java:14) - start…
22:50:57 DEBUG [main] (Test5.java:16) - xpp.day3.GarbageBag@ffa5d 装满了垃圾
22:50:57 DEBUG [保洁阿姨] (Test5.java:18) - start…
22:50:57 DEBUG [保洁阿姨] (Test5.java:21) - xpp.day3.GarbageBag@ffa5d 空垃圾袋
22:50:58 DEBUG [main] (Test5.java:24) - 想换一只新垃圾袋?
22:50:58 DEBUG [main] (Test5.java:26) - 换了吗?false
22:50:58 DEBUG [main] (Test5.java:27) - xpp.day3.GarbageBag@ffa5d 空垃圾袋
-
AtomicIntegerArray -
AtomicLongArray -
AtomicReferenceArray
注意:
对函数式接口不熟悉的小伙伴可以参考👉Java—函数式接口
/**
参数1,提供数组、可以是线程不安全数组或线程安全数组
参数2,获取数组长度的方法
参数3,自增方法,回传 array, index
参数4,打印数组的方法
*/
// supplier 提供者 无中生有 ()->结果
// function 函数 一个参数一个结果 (参数)->结果 , BiFunction (参数1,参数2)->结果
// consumer 消费者 一个参数没结果 (参数)->void, BiConsumer (参数1,参数2)->
private static void demo(
Supplier arraySupplier,
Function<T, Integer> lengthFun,
BiConsumer<T, Integer> putConsumer,
Consumer printConsumer ) {
List ts = new ArrayList<>();
T array = arraySupplier.get();
int length = lengthFun.apply(array);
for (int i = 0; i < length; i++) {
// 每个线程对数组作 10000 次操作
ts.add(new Thread(() -> {
for (int j = 0; j < 10000; j++) {
putConsumer.accept(array, j%length);
}
}));
}
ts.forEach(t -> t.start()); // 启动所有线程
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}); // 等所有线程结束
printConsumer.accept(array);
}
不安全的数组
demo(
()->new int[10],
(array)->array.length,
(array, index) -> array[index]++,
array-> System.out.println(Arrays.toString(array))
);
输出:
[9870, 9862, 9774, 9697, 9683, 9678, 9679, 9668, 9680, 9698]
安全的数组
demo(
()-> new AtomicIntegerArray(10),
(array) -> array.length(),
(array, index) -> array.getAndIncrement(index),
array -> System.out.println(array)
);
输出:
[10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000, 10000]
-
AtomicReferenceFieldUpdater// 域 字段 -
AtomicIntegerFieldUpdater -
AtomicLongFieldUpdater
利用字段更新器,可以针对对象的某个域(Field)进行原子操作,只能配合 volatile 修饰的字段使用,否则会出现异常
Exception in thread “main” java.lang.IllegalArgumentException: Must be volatile type
栗子1:
public class Test5 {
private volatile int field;
public static void main(String[] args) {
AtomicIntegerFieldUpdater fieldUpdater =AtomicIntegerFieldUpdater.newUpdater(Test5.class, “field”);
Test5 test5 = new Test5();
fieldUpdater.compareAndSet(test5, 0, 10);
// 修改成功 field = 10
System.out.println(test5.field);
// 修改成功 field = 20
fieldUpdater.compareAndSet(test5, 10, 20);
System.out.println(test5.field);
// 修改失败 field = 20
fieldUpdater.compareAndSet(test5, 10, 30);
System.out.println(test5.field);
}
}
//输出:
10
20
20
栗子2:
public class Test7 {
public static void main(String[] args) {
Student student = new Student();
//参数1: 持有属性的类
//参数2:被更新的属性的class
//参数3:属性的名称
AtomicReferenceFieldUpdater<Student, String> updater = AtomicReferenceFieldUpdater.newUpdater(Student.class, String.class, “name”);
updater.compareAndSet(student, null, “xpp”);//更新成功
System.out.println(student);
updater.compareAndSet(student, “xp”, “mzz”);//更新失败
System.out.println(student);
}
}
@ToString
class Student {
volatile String name;
}
累加器性能比较
private static void demo(Supplier adderSupplier, Consumer action) {
T adder = adderSupplier.get();
long start = System.nanoTime();
List ts = new ArrayList<>();
// 4 个线程,每人累加 50 万
for (int i = 0; i < 40; i++) {
ts.add(new Thread(() -> {
for (int j = 0; j < 500000; j++) {
action.accept(adder);
}
}));
}
ts.forEach(t -> t.start());
// 等所有线程结束
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long end = System.nanoTime();
System.out.println(adder + " cost:" + (end - start) / 1000_000);
}
比较 AtomicLong 与 LongAdder
for (int i = 0; i < 5; i++) {
demo(() -> new LongAdder(), adder -> adder.increment());
}
for (int i = 0; i < 5; i++) {
demo(() -> new AtomicLong(), adder -> adder.getAndIncrement());
}
//输出
1000000 cost:43
1000000 cost:9
1000000 cost:7
1000000 cost:7
1000000 cost:7
1000000 cost:31
1000000 cost:27
1000000 cost:28
1000000 cost:24
1000000 cost:22
可以看出LongAdder效率更高
性能提升的原因很简单,就是在有竞争时,设置多个累加单元,Therad-0 累加 Cell[0],而 Thread-1 累加 Cell[1]… 最后将结果汇总。这样它们在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能。
LongAdder 类有几个关键域:
// 累加单元数组, 懒惰初始化
transient volatile Cell[] cells;
// 基础值, 如果没有竞争, 则用 cas 累加这个域
transient volatile long base;
// 在 cells 创建或扩容时, 置为 1, 表示加锁
transient volatile int cellsBusy;
8-1 cas 锁
// 不要用于实践!!!
@Slf4j
public class LockCas {
//0 没加锁
//1 加锁
private AtomicInteger state = new AtomicInteger(0);
public void lock() {
while (true) {
//当为0时,加锁,state变为1,此时其他线程想获得锁就会一直循环cas
if (state.compareAndSet(0, 1)) {
break;
}
}
}
public void unlock() {
log.debug(“unlock…”);
state.set(0);
}
public static void main(String[] args) {
LockCas lock = new LockCas();
new Thread(() -> {
log.debug(“begin…”);
lock.lock();
System.out.println(lock.state);
try {
log.debug(“lock…”);
Sleeper.sleep(1);
} finally {
lock.unlock();
}
}).start();
new Thread(() -> {
log.debug(“begin…”);
lock.lock();
try {
log.debug(“lock…”);
} finally {
lock.unlock();
}
}).start();
}
}
17:11:26 DEBUG [Thread-1] (LockCas.java:42) - begin…
17:11:26 DEBUG [Thread-0] (LockCas.java:35) - lock…
17:11:27 DEBUG [Thread-0] (LockCas.java:24) - unlock…
17:11:27 DEBUG [Thread-1] (LockCas.java:45) - lock…
17:11:27 DEBUG [Thread-1] (LockCas.java:24) - unlock…
8-2 原理之伪共享
// 防止缓存行伪共享
@sun.misc.Contended
static final class Cell {
volatile long value;
Cell(long x) { value = x; }
// 最重要的方法, 用来 cas 方式进行累加, prev 表示旧值, next 表示新值
final boolean cas(long prev, long next) {
return UNSAFE.compareAndSwapLong(this, valueOffset, prev, next);
}
// 省略不重要代码
}
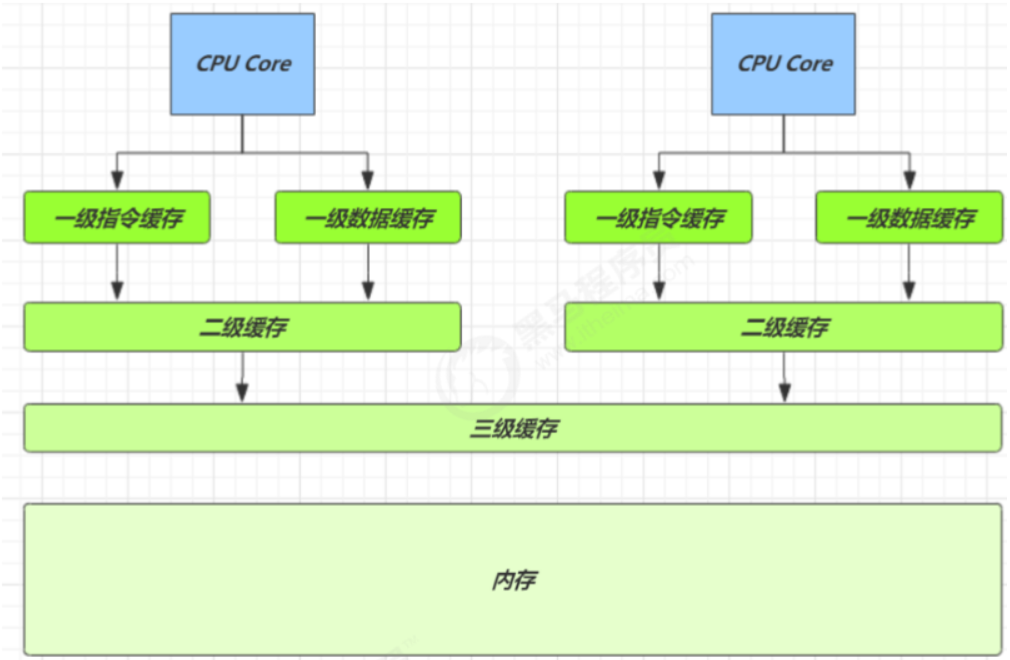
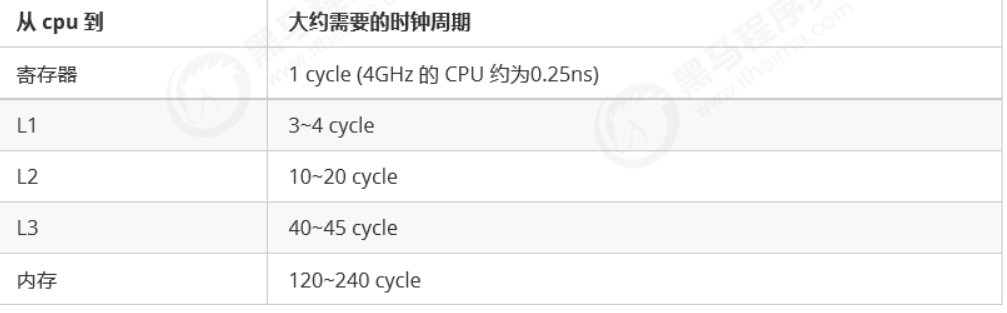
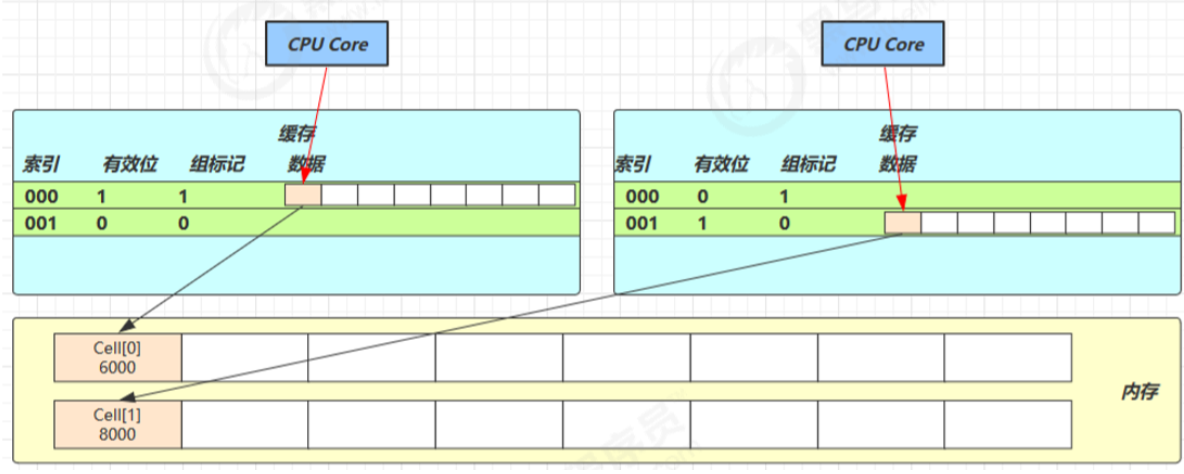
得从缓存说起,缓存与内存的速度比较
-
因为 CPU 与 内存的速度差异很大,需要靠预读数据至缓存来提升效率。
-
而缓存以缓存行为单位,每个缓存行对应着一块内存,一般是 64 byte(8 个 long)
-
缓存的加入会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中
-
CPU 要保证数据的一致性,如果某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效
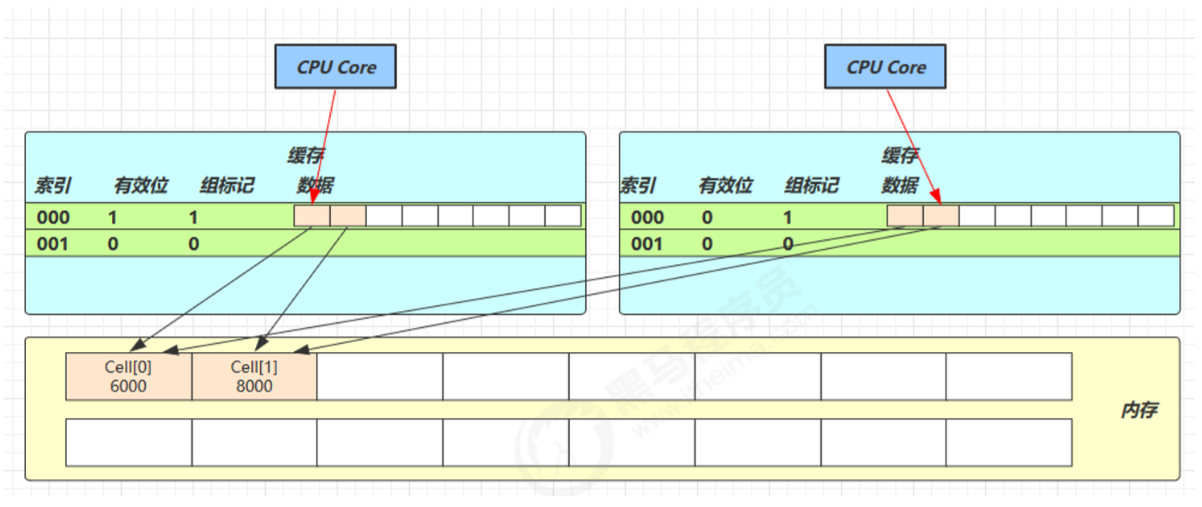
因为 Cell 是数组形式,在内存中是连续存储的,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),因 此缓存行可以存下 2 个的 Cell 对象。这样问题来了:
-
Core-0 要修改 Cell[0]
-
Core-1 要修改 Cell[1]
无论谁修改成功,都会导致对方 Core 的缓存行失效,比如 Core-0 中Cell[0]=6000, Cell[1]=8000 要累加 Cell[0]=6001, Cell[1]=8000 ,这时会让 Core-1 的缓存行失效
@sun.misc.Contended 用来解决这个问题,它的原理是在使用此注解的对象或字段的前后各增加 128 字节大小的 padding(空白),从而让 CPU 将对象预读至缓存时占用不同的缓存行,这样,不会造成对方缓存行的失效
累加主要调用下面的方法
public void add(long x) {
// as 为累加单元数组
学习分享,共勉
这里是小编拿到的学习资源,其中包括“中高级Java开发面试高频考点题笔记300道.pdf”和“Java核心知识体系笔记.pdf”文件分享,内容丰富,囊括了JVM、锁、并发、Java反射、Spring原理、微服务、Zookeeper、数据库、数据结构等大量知识点。同时还有Java进阶学习的知识笔记脑图(内含大量学习笔记)!
资料整理不易,读者朋友可以转发分享下!
Java核心知识体系笔记.pdf

中高级Java开发面试高频考点题笔记300道.pdf

架构进阶面试专题及架构学习笔记脑图

Java架构进阶学习视频分享
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Cell[1]=8000 ,这时会让 Core-1 的缓存行失效
@sun.misc.Contended 用来解决这个问题,它的原理是在使用此注解的对象或字段的前后各增加 128 字节大小的 padding(空白),从而让 CPU 将对象预读至缓存时占用不同的缓存行,这样,不会造成对方缓存行的失效
累加主要调用下面的方法
public void add(long x) {
// as 为累加单元数组
学习分享,共勉
这里是小编拿到的学习资源,其中包括“中高级Java开发面试高频考点题笔记300道.pdf”和“Java核心知识体系笔记.pdf”文件分享,内容丰富,囊括了JVM、锁、并发、Java反射、Spring原理、微服务、Zookeeper、数据库、数据结构等大量知识点。同时还有Java进阶学习的知识笔记脑图(内含大量学习笔记)!
资料整理不易,读者朋友可以转发分享下!
Java核心知识体系笔记.pdf
[外链图片转存中…(img-0u19eUem-1713667171750)]
中高级Java开发面试高频考点题笔记300道.pdf
[外链图片转存中…(img-JMlBOJ0y-1713667171751)]
架构进阶面试专题及架构学习笔记脑图
[外链图片转存中…(img-DLJZni1X-1713667171751)]
Java架构进阶学习视频分享
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-H3jFatZi-1713667171752)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 147
147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









