







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

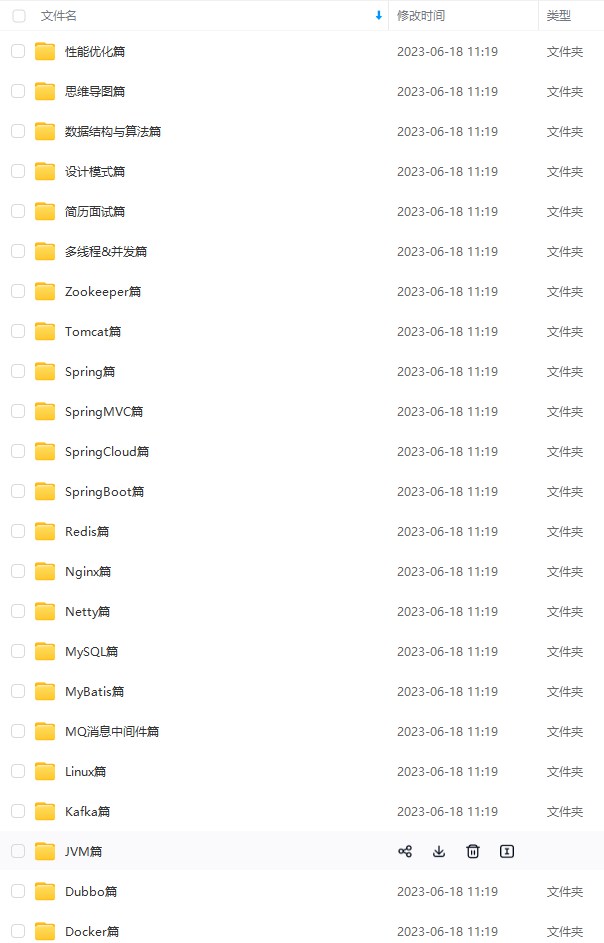
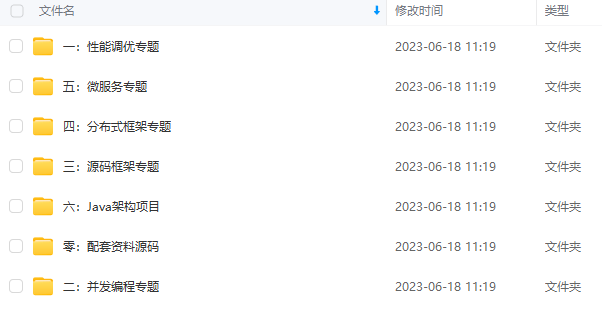
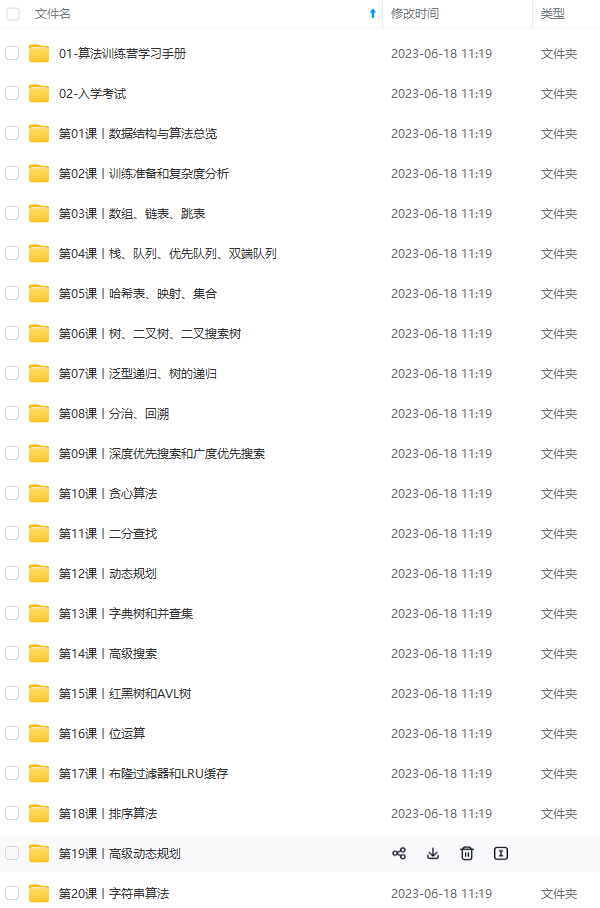

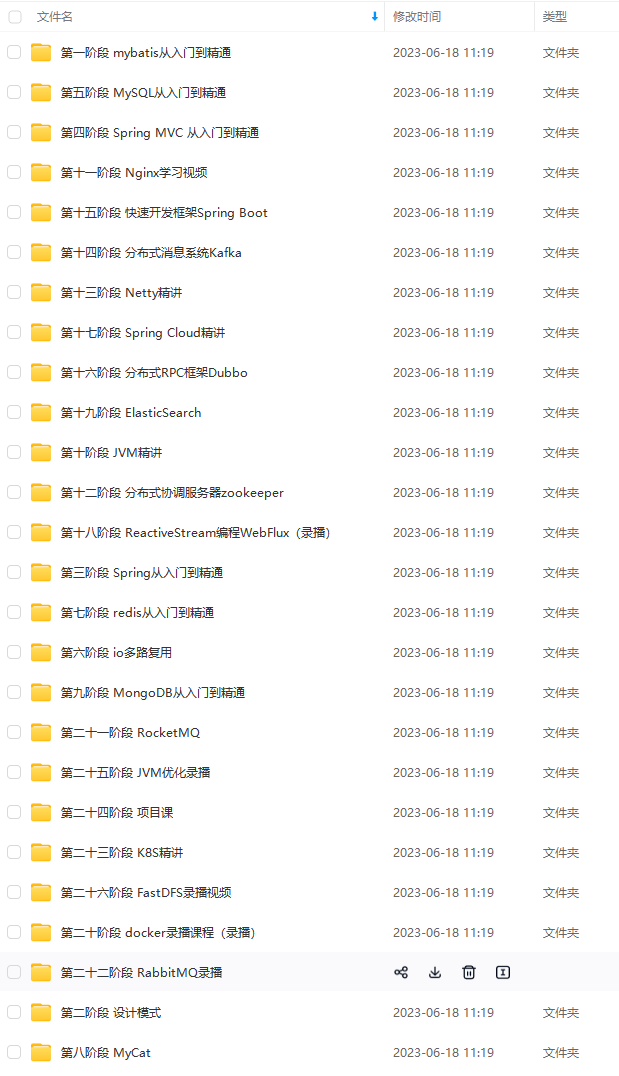
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
该内部Bean是无法提供给外界使用的,所以id属性也就没有意义了,可以省略。
Spring还提供了级联属性注入值,比如:
这里通过car.maxSpeed为Bean的maxSpeed属性赋值(通过级联属性进行注入之前需要先初始化)。
注入集合类型
修改一下Person类的结构:
public class Person {
private String name;
private int age;
private List cars;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public List getCars() {
return cars;
}
public void setCars(List cars) {
this.cars = cars;
}
}
在该类中有一个集合类型的成员变量,在配置的时候如何对该属性进行注入呢?
其实很简单,首先你需要在配置文件中配置Car,然后通过list子节点注入集合,再通过ref子节点指定集合中的子元素(ref子节点中的bean属性值为对应的Bean的id)。
数组的定义和List一样,都使用list子节点,而Set集合的定义方式和List相同,唯一不同的是Map集合。,Map集合的定义如下:
这里使用map子节点定义Map集合,再通过entry子节点定义集合中的子元素,其中key表示键,value-ref表示值引用。
Properties注入
Properties是Map的子类,所以配置方式其实跟Map没有什么区别,但因为Properties的使用还是比较频繁的,所以单独拿出来介绍一下。
比较常见的使用场景便是JDBC的属性配置,先定义一个DataSource类:
public class DataSource {
private Properties properties;
public Properties getProperties() {
return properties;
}
public void setProperties(Properties properties) {
this.properties = properties;
}
@Override
public String toString() {
return “DataSource [properties=” + properties + “]”;
}
}
在配置文件中就可以通过props节点进行注入:
root
123456
jdbc:mysql:///test
com.mysql.jdbc.driver
以上的一些配置都是在Bean的内部进行的,即这些数据只能提供给当前Bean而无法提供给外部Bean使用,为此,Spring提供了一种方式将集合类型抽取到外部供其它Bean使用:
<util:list id=“cars”>
</util:list>
需要注意的是,必须在beans根节点里添加util schema定义:
<beans xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
xmlns:util=“http://www.springframework.org/schema/util”
xsi:schemaLocation=“http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util-4.0.xsd”>
使用p命名空间
为了简化XML文件的配置,越来越多的XML文件采用属性而非子元素配置信息,Spring从2.5版本开始引入一个新的命名空间p,可以通过bean节点元素属性的方式配置Bean的属性,使用p命名空间后,基于XML的配置方式将进一步简化,比如:
自动装配
====
掌握了如何配置Bean之后,我们发现一个问题,就是Bean与Bean之间的关系都需要我们手动建立联系,为此,Spring提供了一种自动装配Bean的方式,我们来了解一下。
SpringIOC容器可以自动装配Bean,需要做的仅仅是在bean的autowire属性里指定自动装配的模式,装配模式有以下几种:
-
byType:根据类型自动装配。若IOC容器中有多个与目标Bean类型一致的Bean,在这种情况下,Spring将无法判定哪个Bean最适合该属性,所以不能执行自动装配
-
byName:根据名称自动装配。必须将目标Bean的名称和属性名设置为完全一致
-
constructor:根据构造器自动装配。当Bean中存在多个构造器时,该方式将会很复杂,不推荐使用
现在有这样一个Person类:
public class Person {
private String name;
private Address address;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
}
该类中的成员变量Address是另外一个Bean:
public class Address {
private String city;
private String street;
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getStreet() {
return street;
}
public void setStreet(String street) {
this.street = street;
}
}
如果让大家按照传统的方式手动引用Bean,相信大家都会写,配置如下:
那么如何实现自动装配呢?即让需要引用的Bean自动注入到另一个Bean的属性中呢?修改一下配置文件:
现在我们就不需要手动引用Bean了,而是在bean节点中配置一个autowire属性,它有三个值,分别有什么作用刚刚已经介绍了。比如这里指定的是byName,则IOC容器将根据名称自动装配,因为这里配置的Address类id为address,而Person类中的setter方法名为setAddress,两者对应,才能实现自动装配。
另外两种方式原理类似,不作讨论。
虽然自动装配能够帮助我们减少一些配置代码,但缺点也是很明显的,主要有以下几点:
-
在Bean配置文件里设置autowire属性进行自动装配将会装配Bean的所有属性,然而,若只是希望装配个别属性时,autowire属性就不够灵活了
-
autowire属性要么根据类型自动装配,要么根据名称自动装配,二者不能混合使用
一般情况下,在实际的项目中很少使用自动装配功能,因为和自动装配功能所带来的好处比起来,明确清晰的配置文档更有说服力一些。
Bean之间的关系
=========
在Spring中Bean之间有两种关系:
-
继承
-
依赖
分别介绍一下。
继承
–
Spring中允许继承Bean的配置,被继承的Bean称为父Bean,继承这个父Bean的Bean称为子Bean;子Bean从父Bean中继承配置,包括Bean的属性配置;子Bean也可以覆盖从父Bean中继承过来的配置;父Bean可以作为配置模板,也可以作为Bean实例,若只想把父Bean作为模板,可以设置bean节点的abstract属性为true,这样Spring将不会实例化该Bean;也可以忽略父Bean中的class属性,让子Bean指定自己的类,而共享相同的属性配置,但此时父Bean的abstract属性值必须为true。
需要注意的是,并不是bean节点中的所有属性都会被继承,比如:autowire、abstract等是不会被子Bean继承的。
在配置文件中使用bean节点中的parent属性指定需要继承的Bean:
依赖
–
Spring允许开发者通过depends-on属性设定Bean前置依赖的Bean,前置依赖的Bean会在本Bean实例化之前创建好,如果前置依赖于多个Bean,则可以通过逗号、空格的方式配置Bean的名称。比如:
这个依赖是什么意思呢?看这段配置,bean节点下的属性depends-on,其值为address,若IOC容器中找不到一个id为address的Bean,则抛出异常,也就是说,该person依赖于address。
Bean的作用域
========
配置文件中配置的Bean都在SpringIOC容器中有对应的作用域,可以通过bean节点中的scope属性设置作用域,若不设置,则默认为singleton。
这里介绍使用较为频繁的两种作用域:
-
singleton:容器初始化时创建Bean实例,在整个容器的生命周期中有且只有一个实例
-
prototype:容器初始化时不创建Bean实例,而在每次获取Bean时创建一个新的实例
配置如下:
使用外部属性文件
========
在配置文件中配置Bean时,有时需要在Bean的配置里混入系统部署的细节信息(比如:文件路径、数据源配置信息等),而这些部署细节实际上需要和Bean配置相分离。
基于此,Spring提供了一个PropertyPlaceHolderConfigurer的BeanFactory后置处理器,该处理器允许开发者将Bean配置的部分内容移植到属性文件中,可以在Bean配置文件中使用形式为${var}的变量,PropertyPlaceHolderConfigurer从属性文件中加载属性,并使用这些属性来替换变量。
Spring来允许在属性文件中使用{propName},以实现属性之间的相互作用。
比如配置JDBC的数据源信息,这里以C3P0数据库连接池为例,先导入C3P0的jar包和mysql的驱动,并作如下配置:
这样虽然也能实现功能,但是将这些信息写死在Spring的配置文件中显然不是一个好办法,当你需要更改应用的运行环境时,你还得在Spring的配置文件中寻找数据源的配置信息并作修改。为了使操作更加方便,我们可以将这些信息移植出去,先创建一个db.properties文件:
user=root
password=123456
driverClass=com.mysql.jdbc.Driver
jdbcUrl=jdbc:mysql:///test
接下来我们就需要在Spring的配置文件中引用这些属性值,在这之前还需要将属性文件导入:
<context:property-placeholder location=“classpath:db.properties”/>
需要导入context命名空间,location属性值为属性文件路径。
SpEL
====
SpEL,即:Spring表达式语言,是一中支持运行时查询和操作对象的强大的表达式语言,语法类似于EL。
SpEL使用#{…}作为定界符,所有在大括号中的字符都将被认为是SpEL,通过SpEL可以实现:
-
通过Bean的d对Bean进行引用
-
调用方法以及引用对象中的属性
-
计算表达式的值
-
正则表达式的匹配
为属性赋字面值
比如:
<property name=“name” value=“#{“tom”}”>
但这样意义不大,简直是多此一举。
引用Bean、属性和方法
我们知道引用Bean可以使用ref属性,你也可以使用SpEL引用Bean,而且功能比ref更加丰富,比如:
计算表达式的值
通过T()可以调用一个类的静态方法或者静态属性,比如这里用T()
正则表达式的匹配
Bean的生命周期
=========
SpringIOC容器可以管理Bean的生命周期,Spring允许在Bean的生命周期的特定点执行指定的任务。
SpringIOC容器对Bean的生命周期进行管理的过程:
-
通过构造器或工厂方法创建Bean的实例
-
为Bean的属性设置值和对其它Bean的引用
-
调用Bean的初始化方法
-
当容器关闭时,调用Bean的销毁方法
可以在Bean的配置中设置init-method和destroy-method属性,为Bean指定初始化和销毁方法。
定义一个类:
public class Car {
private String brand;
public Car() {
System.out.println(“Car’s Constructor…”);
}
public void setBrand(String brand) {
System.out.println(“Car’s setBrand…”);
this.brand = brand;
}
public void init() {
System.out.println(“Car’s init…”);
}
public void destroy() {
System.out.println(“Car’s destroy…”);
}
}
然后在配置文件中进行配置:
初始化方法和销毁方法的方法名可以任意,但是在配置时一定要与类中的方法名对应,此时测试一下便可得知Bean的生命周期,测试代码:
public static void main(String[] args) {
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext(“beans-cycle.xml”);
Car car = (Car) ctx.getBean(“car”);
System.out.println(car);
ctx.close();
}
运行结果:
Car’s Constructor…
Car’s setBrand…
Car’s init…
com.wwj.springdemo.cycle.Car@5c3bd550
三月 08, 2020 3:14:04 下午 org.springframework.context.support.AbstractApplicationContext doClose
信息: Closing org.springframework.context.support.ClassPathXmlApplicationContext@6193b845: startup date [Sun Mar 08 15:14:04 CST 2020]; root of context hierarchy
Car’s destroy…
这里为了能够关闭IOC容器,使用了ClassPathXmlApplicationContext类来进行测试,因为close()方法封装到了ConfigurableApplicationContext接口,而ClassPathXmlApplicationContext是该接口的实现类。
Bean的后置处理器
Bean后置处理器允许在调用初始化方法前后对Bean进行额外的处理,Bean后置处理器对IOC容器中的所有Bean实例逐一处理,而非单一处理,其典型应用是:检查Bean属性的正确性或根据特定的标准更改Bean的属性,Bean后置处理器使得Bean的生命周期变得更加细致。
定义一个类实现BeanPostProcessor接口:
public class MyBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println(“after”);
return bean;
}
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println(“before”);
return bean;
}
}
接着修改配置文件:
只需要在配置文件中新增一个后置处理器的配置即可,该Bean无需指定id,IOC容器会自动寻找到该Bean并对所有Bean起作用。
重新运行一下测试代码,Bean的生命周期就会发生变化:
Car’s Constructor…
Car’s setBrand…
before
Car’s init…
after
com.wwj.springdemo.cycle.Car@6a4f787b
三月 08, 2020 3:31:12 下午 org.springframework.context.support.AbstractApplicationContext doClose
信息: Closing org.springframework.context.support.ClassPathXmlApplicationContext@6193b845: startup date [Sun Mar 08 15:31:12 CST 2020]; root of context hierarchy
Car’s destroy…
通过工厂方法获取Bean
============
通过工厂方法也是获取Bean的一种方式,工厂方法又分为:
-
静态工厂方法
-
实例工厂方法
静态工厂方法
调用静态工厂方法获取Bean是将对象创建的过程封装到静态方法中,当客户端需要对象时,只需要简单地调用静态方法,而不用关心创建对象的细节。
要声明通过静态工厂方法创建的Bean,需要在Bean的class属性里指定拥有该工厂的方法的类,同时在factory-method属性里指定工厂方法的名称。最后,使用constrctor-arg元素为该方法传递方法参数。
先定义一个静态工厂类:
public class StaticCarFactory {
private static Map<String, Car> cars = new HashMap<String, Car>();
static {
cars.put(“Audi”, new Car(“Audi”, 300000));
cars.put(“BMW”,new Car(“BMW”, 500000));
}
public static Car getCar(String brand) {
return cars.get(brand);
}
}
该类有一个静态方法getCar(),在不需要创建这个工厂类的情况下,我们就能通过该静态方法获取到指定的Car实例,在配置文件中配置一下:
配置好后,直接通过id即可获取到Car实例:
Car car = (Car) ctx.getBean(“car”);
实例工厂方法
实例工厂方法是将对象的创建过程封装到另外一个对象实例的方法里,当客户端需要请求对象时,只需要简单地调用一下该实例方法而无需关心对象的创建细节。
要声明通过实例工厂方法创建的Bean,需要在bean节点的factory-bean属性里指定拥有该工厂方法的Bean,在factory-method属性里指定该工厂方法的名称,并使用constructor-arg子节点为工厂方法传递方法参数。
先定义一个实例工厂类:
public class InstanceCarFactory {
private Map<String, Car> cars = null;
public InstanceCarFactory() {
cars = new HashMap<String, Car>();
cars.put(“Audi”, new Car(“Audi”, 300000));
cars.put(“BMW”,new Car(“BMW”, 500000));
}
public Car getCar(String brand) {
return cars.get(brand);
}
}
该类有一个成员方法getCar(),实例工厂与静态工厂的区别就是,实例工厂需要实例化工厂类才能获取到Car,静态工厂则不需要。
配置一下:
然后获取Car实例:
Car car = (Car) ctx.getBean(“car”);
通过FactoryBean获取Bean
===================
我们还可以通过FactoryBean来获取Bean的实例,这是Spring为我们提供的一种方式。
首先定义一个类实现FactoryBean接口:
public class CarFatoryBean implements FactoryBean{
@Override
public Car getObject() throws Exception {
return new Car(“BMW”,500000);
}
@Override
public Class<?> getObjectType() {
return Car.class;
}
@Override
public boolean isSingleton() {
return true;
}
}
getObject()方法返回创建的实例,getObjectType()方法返回实例类型,isSingleton()方法返回一个布尔值,标识是否单例。
配置一下:
这样就可以通过id获取Car实例了:
Car car = (Car) ctx.getBean(“car”);
通过注解配置Bean
==========
前面介绍的都是基本XML文件的配置,当Bean类越来越多,Bean与Bean之间的关系越来越复杂的时候,XML文件就会显得非常臃肿,此时注解的好处就体现出来了,一起来了解一下。
组件扫描
Spring能够从classpath(类路径)下自动扫描,侦测和实例化具有特定注解的组件,特定组件包括:
-
@Component:基本注解,标识了一个受Spring管理的组件
-
@Respository:标识持久层组件
-
@Service:标识服务层组件
-
@Controller:标识控制层组件
对于扫描到的组件,Spring有默认的命名策略:使用非限定类名,第一个字母小写;也可以在注解中通过value属性值设定组件的名称。
这些注解虽然对应着每个业务层次的组件,你也可以随意地使用这些注解,因为Spring是无法知道你的类到底是持久层、服务层还是控制层的,但为了统一规范,也为了项目结构的严谨性,还是建议妥善使用这些注解,将这些注解标注到对应的组件上。
当在组件上使用了特定的注解之后,还需要在Spring的配置文件中声明context:component-scan,需要注意该节点中的属性:
-
base-package:指定一个需要扫描的基类包,Spring容器将会扫描这个基类包及其子包中的所有类
-
resource-pattern:如果仅希望扫描特定的类而非基类包下的所有类,可以使用该属性进行过滤
-
context:include-filter:子节点,表示要包含的目标类
-
context:exclude-filter:子节点,表示要排除的目标类
context:component-scan节点下可以包含若干个context:include-filter和context:exclude-filter子节点。
用法很简单,这样配置:
<context:component-scan base-package=“com.wwj.springdemo.annotation”></context:component-scan>
Spring容器便会扫描com.wwj.springdemo.annotation包和该包下子包的所有类,如果有某个类含有特定的组件注解,Spring容器就会管理该Bean。
在该包下创建一个类:
@Component
public class TestObject {
}
并用@Component标注它,则在获取该Bean的时候,该Bean的id应为testObject(首字母小写),也可以指定其id:
@Component(value = “test”)
public class TestObject {
}
倘若该包下有一个子包com.wwj.springdemo.annotation.repository,若是想只扫描该子包下的类,则可以使用resource-pattern过滤:
<context:component-scan base-package=“com.wwj.springdemo.annotation” resource-pattern=“repository/*.class”></context:component-scan>
当然了,还可以使用context:include-filter和context:exclude-filter来包含或者排除目标类,比如:
<context:component-scan base-package=“com.wwj.springdemo.annotation”>
<context:exclude-filter type=“annotation” expression=“org.springframework.stereotype.Repository”/>
</context:component-scan>
在这段配置中,context:exclude-filter节点中的type属性值为annotation,则Spring容器会根据指定的注解进行排除,expression属性值为org.springframework.stereotype.Repository,则Spring容器会将@Repository注解标注的所有类全部排除,排除后就无法获取到这些Bean实例了。
还可以通过指定类名的方式排除指定的类,如:
<context:component-scan base-package=“com.wwj.springdemo.annotation”>
<context:exclude-filter type=“assignable” expression=“com.wwj.springdemo.annotation.repository.UserRepository”/>
</context:component-scan>
指定类名后,Spring容器便会排除它,若指定的类是一个接口,则容器会排除该接口的所有实现类。
建立组件之间的关联关系
要想建立组件之间的关联关系,其实非常简单,当你使用了组件扫描之后,它会自动注册一个AutoWiredAnnotationBeanPostProcessor实例,该实例可以自动装配具有@Autowired、@Resource和@Inject注解的属性。
在刚才的基础上,我们来建立几个类:
@Controller
public class UserController {
@Autowired
private UserService userService;
public void execute() {
System.out.println(“UserController execute…”);
userService.add();
}
}
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public void add() {
System.out.println(“UserService add…”);
userRepository.save();
}
}
@Repository
public class UserRepositoryImpl implements UserRepository{
@Override
public void save() {
System.out.println(“UserRepositoryImpl save…”);
}
}
测试代码:
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext(“beans-annotation.xml”);
UserController userController = (UserController) ctx.getBean(“userController”);
userController.execute();
}
运行结果:
UserController execute…
UserService add…
UserRepositoryImpl save…
自动装配过程需要注意以下几点:
-
构造器、普通字段,一切具有参数的方法都可以使用@Autowired注解
-
默认情况下,所有使用@Autowired注解的属性都需要被设置,当Spring找不到匹配的Bean时,就会抛出异常,若某一个属性允许不被设置,可以设置@Autowired注解的required属性为false
-
默认情况下,当IOC容器中存在多个类型相同的Bean时,通过类型的自动装配将无法工作,此时可以在@Qualifier注解里提供Bean的名称,Spring允许对方法的入参标注@Qualifier以指定注入Bean的名称
-
@Autowired注解也可以应用在数组类型的属性上,此时Spring将会把所有匹配的Bean进行自动装配
-
@Autowired注解也可以应用在集合类型的属性上,此时Spring读取该集合的类型信息,然后自动装配所有与之兼容的Bean
-
@Autowired注解用在Map集合上时,若该Map的键值为String,那么Spring将自动装配与之Map值类型兼容的Bean,此时Bean的名称作为键值
Spring还支持@Resource和@Inject注解,这两个注解和@Autowired注解的功能类似。
@Resource注解要求提供一个Bean名称的属性,若该属性为空,则自动采用标注处的变量或方法名作为Bean的名称;@Inject注解和@Autowired注解一样也是按类型匹配注入的Bean,但没有reqired属性。
综上所述,建立使用@Autowired注解。
SpringAOP
=========
一个稳定的项目离不开多次版本的迭代,而在这个过程中,越来越多的非业务需求,比如:日志、用户验证等加入后,原有的业务方法急剧膨胀,每个方法在处理核心逻辑的同时还必须兼顾其它多个关注点。
以日志需求为例,只是为了满足这个单一需求,就不得不在多个模块里多次重复相同的日志代码,如果日志需求发生变化,就必须修改所有模块。
为了解决这些问题,AOP顺势而生。AOP即面向切面编程,它是一种新的方法论,是对传统OOP的补充。AOP的主要编程对象是切面。
在应用AOP编程时,仍然需要定义公共功能,但可以明确地定义这个功能在哪里,以什么方式应用,并且不必修改受影响的类,这样一来横切关注点就被模块化到特殊的对象(切面)里,AOP有以下好处:
-
每个事物逻辑位于一个位置,代码不分散,便于维护和升级
-
业务模块更简洁,只包含核心业务代码
比如这样的一个类:
@Component(“arithmeticCalculator”)
public class ArithmeticCalculatorImpl implements ArithmeticCalculator {
@Override
public int add(int i, int j) {
int result = i + j;
return result;
}
@Override
public int sub(int i, int j) {
int result = i - j;
return result;
}
@Override
public int mul(int i, int j) {
int result = i * j;
return result;
}
@Override
public int div(int i, int j) {
int result = i / j;
return result;
}
}
该类用于实现加减乘除的运算,若是想在这些方法中添加日志打印,该如何实现呢?看AOP如何大显神通吧。
前置通知
首先定义一个切面:
@Aspect
@Component
public class LoggingAspect {
@Before(“execution(public int com.wwj.springdemo.aop.impl.ArithmeticCalculator.*(int,int))”)
public void beforeMethod(JoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
List args = Arrays.asList(joinPoint.getArgs());
System.out.println(“before…” + methodName + " with" + args);
}
}
使用@Component注解将该类交由IOC容器管理,使用@Aspect将该类声明为一个切面,该类中有一个beforeMethod()方法,该方法用于处理核心代码外的逻辑。
使用@Before标注该方法,说明该方法是一个前置通知,即:在指定方法之前执行,指定方法格式为execution(),括号内填写方法全名,这里的方法名采用了通配符*,这样就能使该前置通知在四个计算方法中都有效。
通过入参JoinPoint还能够获取到待执行的方法名和参数,如何获取看上面的代码就好了。
最后需要在配置文件中配置一下:
<context:component-scan base-package=“com.wwj.springdemo.aop.impl”></context:component-scan>
aop:aspectj-autoproxy</aop:aspectj-autoproxy>
<aop:config proxy-target-class=“true”></aop:config>
通过配置<aop:aspectj-autoproxy></aop:aspectj-autoproxy>时通知注解起作用,并为匹配的类自动生成代理对象。
后置通知
总目录展示
该笔记共八个节点(由浅入深),分为三大模块。
高性能。 秒杀涉及大量的并发读和并发写,因此支持高并发访问这点非常关键。该笔记将从设计数据的动静分离方案、热点的发现与隔离、请求的削峰与分层过滤、服务端的极致优化这4个方面重点介绍。
一致性。 秒杀中商品减库存的实现方式同样关键。可想而知,有限数量的商品在同一时刻被很多倍的请求同时来减库存,减库存又分为“拍下减库存”“付款减库存”以及预扣等几种,在大并发更新的过程中都要保证数据的准确性,其难度可想而知。因此,将用一个节点来专门讲解如何设计秒杀减库存方案。
高可用。 虽然介绍了很多极致的优化思路,但现实中总难免出现一些我们考虑不到的情况,所以要保证系统的高可用和正确性,还要设计一个PlanB来兜底,以便在最坏情况发生时仍然能够从容应对。笔记的最后,将带你思考可以从哪些环节来设计兜底方案。
篇幅有限,无法一个模块一个模块详细的展示(这些要点都收集在了这份《高并发秒杀顶级教程》里),麻烦各位转发一下(可以帮助更多的人看到哟!)


由于内容太多,这里只截取部分的内容。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
看AOP如何大显神通吧。
前置通知
首先定义一个切面:
@Aspect
@Component
public class LoggingAspect {
@Before(“execution(public int com.wwj.springdemo.aop.impl.ArithmeticCalculator.*(int,int))”)
public void beforeMethod(JoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
List args = Arrays.asList(joinPoint.getArgs());
System.out.println(“before…” + methodName + " with" + args);
}
}
使用@Component注解将该类交由IOC容器管理,使用@Aspect将该类声明为一个切面,该类中有一个beforeMethod()方法,该方法用于处理核心代码外的逻辑。
使用@Before标注该方法,说明该方法是一个前置通知,即:在指定方法之前执行,指定方法格式为execution(),括号内填写方法全名,这里的方法名采用了通配符*,这样就能使该前置通知在四个计算方法中都有效。
通过入参JoinPoint还能够获取到待执行的方法名和参数,如何获取看上面的代码就好了。
最后需要在配置文件中配置一下:
<context:component-scan base-package=“com.wwj.springdemo.aop.impl”></context:component-scan>
aop:aspectj-autoproxy</aop:aspectj-autoproxy>
<aop:config proxy-target-class=“true”></aop:config>
通过配置<aop:aspectj-autoproxy></aop:aspectj-autoproxy>时通知注解起作用,并为匹配的类自动生成代理对象。
后置通知
总目录展示
该笔记共八个节点(由浅入深),分为三大模块。
高性能。 秒杀涉及大量的并发读和并发写,因此支持高并发访问这点非常关键。该笔记将从设计数据的动静分离方案、热点的发现与隔离、请求的削峰与分层过滤、服务端的极致优化这4个方面重点介绍。
一致性。 秒杀中商品减库存的实现方式同样关键。可想而知,有限数量的商品在同一时刻被很多倍的请求同时来减库存,减库存又分为“拍下减库存”“付款减库存”以及预扣等几种,在大并发更新的过程中都要保证数据的准确性,其难度可想而知。因此,将用一个节点来专门讲解如何设计秒杀减库存方案。
高可用。 虽然介绍了很多极致的优化思路,但现实中总难免出现一些我们考虑不到的情况,所以要保证系统的高可用和正确性,还要设计一个PlanB来兜底,以便在最坏情况发生时仍然能够从容应对。笔记的最后,将带你思考可以从哪些环节来设计兜底方案。
篇幅有限,无法一个模块一个模块详细的展示(这些要点都收集在了这份《高并发秒杀顶级教程》里),麻烦各位转发一下(可以帮助更多的人看到哟!)
[外链图片转存中…(img-gyNPFwx4-1713678944263)]
[外链图片转存中…(img-X0Nnk31Y-1713678944264)]
由于内容太多,这里只截取部分的内容。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-7LBuNlsO-1713678944264)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









