







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala.typeutils.Types
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.sources.CsvTableSource
import org.apache.flink.types.Row
import org.apache.flink.api.scala._
object TestScalarFunction {
def main(args: Array[String]): Unit = {
val filePath = “E:\\devlop\\workspace\\streaming1\\src\\main\\resources\\testdata.csv”
val env = ExecutionEnvironment.getExecutionEnvironment
val tableEnv = TableEnvironment.getTableEnvironment(env)
val csvtable = CsvTableSource
.builder
.path(filePath)
.ignoreFirstLine
.fieldDelimiter(“,”)
.field(“rank”, Types.INT)
.field(“player”, Types.STRING)
.field(“club”, Types.STRING)
.field(“matches”, Types.INT)
.field(“red_card”, Types.INT)
.field(“total_score”, Types.INT)
.field(“total_score_home”, Types.INT)
.field(“total_score_visit”, Types.INT)
.field(“pass”, Types.INT)
.field(“shot”, Types.INT)
.build
tableEnv.registerTableSource(“goals”, csvtable)
tableEnv.registerFunction(“ts”,new TotalScores(2))
val tableTest = tableEnv.sqlQuery(“select player,total_score_home,total_score_visit,ts(total_score_home,total_score_visit) from goals where total_score > 10”)//.scan(“test”).where(“id=‘5’”).select(“id,sources,targets”)
tableEnv.toDataSet[Row](tableTest).print()
}
}
首先别忘记引用
import org.apache.flink.api.scala._
否则会有奇怪事情发生。
然后,注册函数,默认构造客场进球权重为2
tableEnv.registerFunction(“ts”,new TotalScores(2))
“select player,total_score_home,total_score_visit,ts(total_score_home,total_score_visit) from goals where total_score > 10”
在SQL中使用函数 ts(total_score_home,total_score_visit) 就这么简单
我们来看下输出:
C-罗纳尔多,5,7,19
夸利亚雷拉,5,5,15
萨帕塔,1,4,9
米利克,0,1,2
皮亚特克,2,0,2
因莫比莱,3,3,9
卡普托,2,4,10
表函数(TableFunction)
简单的说,表函数,就是你输入几个数(0个或几个都行),经过一系列的处理,再返回给你行数,返回的行可以包含一列或是多列值。这里我们使用一套新的数据案例来做一个说明。
假设这是某年四个直辖市四个季度GDP的一张透视表(说到透视表,想了解的同学可以异步到我之前的 文章 去看看)
provice,s1,s2,s3,s4
天津,10,11,13,14
北京,13,16,17,18
重庆,14,12,13,14
上海,15,11,15,17
我们来将这张透视表,还原成一张列表,接下来,我们来看代码
import org.apache.flink.table.functions.TableFunction
class UnPivotFunction(separator: String) extends TableFunction[(String)] {
@scala.annotation.varargs
def eval(strs:String*): Unit = {
strs.foreach(x=>collect(x))
}
}
函数要继承TableFunction,后面泛型需要输入返回列的类型,这里为了方便,我们就使用了字符串。我们计划在查询里面把四个季度的值都输入进来,转换成列表。collect是TableFunction提供的函数,用于添加列,eval方法的参数,可以根据你的需要自行扩展,注意在使用不确定参数值的时候,加上注解@scala.annotation.varargs
接下来,我们来测试一下
import org.apache.flink.api.common.typeinfo.Types
import org.apache.flink.api.scala.{ExecutionEnvironment, _}
import org.apache.flink.table.api.TableEnvironment
import org.apache.flink.table.sources.CsvTableSource
import org.apache.flink.types.Row
import wang.datahub.udf.UnPivotFunction
object TestMyTableFunction2 {
def main(args: Array[String]): Unit = {
val filepath = “E:\\devlop\\workspace\\testsbtflink\\src\\main\\resources\\GDP.csv”
val env = ExecutionEnvironment.getExecutionEnvironment
val tableEnv = TableEnvironment.getTableEnvironment(env)
tableEnv.registerFunction(“mtf2”, new UnPivotFunction(“@”))
val cts = CsvTableSource.builder().ignoreFirstLine()
//provice,s1,s2,s3,s4
.field(“provice”,Types.STRING)
.field(“s1”,Types.STRING)
.field(“s2”,Types.STRING)
.field(“s3”,Types.STRING)
.field(“s4”,Types.STRING)
.path(filepath)
.build()
tableEnv.registerTableSource(“m”,cts)
val tableTest = tableEnv.sqlQuery(“select provice,word from m , LATERAL TABLE(mtf2(s1,s2,s3,s4)) as T(word)”)
val stream = tableEnv.toDataSet[Row](tableTest)
stream.print()
}
}
在SQL我使用了 JOIN LATERAL ,有兴趣了解的同学,可以看下云栖的文章,我放在参考文档里了。
我们来看下输出结果:
天津,10
天津,11
天津,13
天津,14
北京,13
北京,16
北京,17
北京,18
上海,15
上海,11
上海,15
上海,17
重庆,14
重庆,12
重庆,13
重庆,14
这个案例也许并不是那么恰当,其实,也可以利用到邮件切分等场景,这里算是抛砖引玉把。
聚合函数(AggregateFunction)
关于聚合函数,官方文档上的这张图,就充分的解释了其工作原理,主要计算通过
-
createAccumulator() -
accumulate() -
getValue()
这几个方法来完成,首先我们createAccumulator创建累加器,然后调用accumulate累加计算,最后getValue获取值。
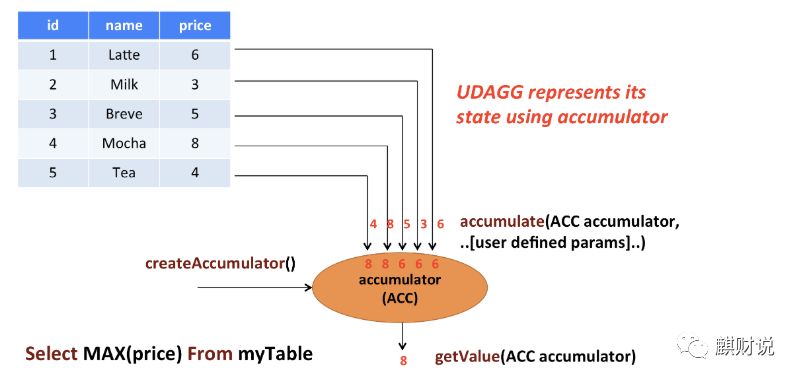
当然这只是完成了初步工作,
-
retract() -
merge() -
resetAccumulator()
我们还需要回滚,合并,重置累加器等操作以适应不同的计算场景。
好了,我们的案例,再次来到了大家喜闻乐见的意甲联赛,这次我们统计俱乐部的进球数,还是使用了一个更靠谱的规则,就是给客场进球加了一个权重,然后来计算加权场均进球数。
先来创建累加器
class WeightedAvgAccum {
var sum = 0
var count = 0
}
然后创建计算函数
总结
本文从基础到高级再到实战,由浅入深,把MySQL讲的清清楚楚,明明白白,这应该是我目前为止看到过最好的有关MySQL的学习笔记了,我相信如果你把这份笔记认真看完后,无论是工作中碰到的问题还是被面试官问到的问题都能迎刃而解!
MySQL50道高频面试题整理:

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
class WeightedAvgAccum {
var sum = 0
var count = 0
}
然后创建计算函数
总结
本文从基础到高级再到实战,由浅入深,把MySQL讲的清清楚楚,明明白白,这应该是我目前为止看到过最好的有关MySQL的学习笔记了,我相信如果你把这份笔记认真看完后,无论是工作中碰到的问题还是被面试官问到的问题都能迎刃而解!
MySQL50道高频面试题整理:
[外链图片转存中…(img-B5WkkqDS-1713555934616)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-Uz8KRxzU-1713555934617)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 187
187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









