






目 录
3.2 语音采集模板(Speech Recording Plane)
3.3 预处理模板(Voice Preprocessing Plane)
3.4 特征提取模板(Feature Extraction Plane)
摘 要
说话是人类相互沟通交流最方便、最快捷的一种方式,世界上每一个说话人都拥有自己特定的语音,正如每个人的指纹一样,都是绝无仅有的。说话人识别应用广泛,现已应用到通信、消费电子产品等各个领域。本文将把语音进行数字化传输、存储、然后进行识别等。说话人识别系统主要包括预处理、特征提取、训练和识别四个模块。其中预处理和特征提取尤为重要。有许多的预处理方法,对语音信号的采样和量化是第一,然后预加重和加窗。特征提取是指提取语音信号的重要特征的过程。信号的时域分析包括信号的短时平均能量和短时过零率等。频域分析可以采用LPC倒谱系数法和Mel倒谱系数法。为了训练得到模版语音信号,可以利用矢量量化(VQ)、隐马尔可夫模型(HMM)、BP神经网络(ANN)等对说话人的语音信号进行训练识别。
说话人识别实现过程中的算法是多种多样的。本文将运用MATLAB仿真工具强大的编程、图形开发功能和数学计算能力。本文将把BP神经网络作为训练识别的方法,利用MFCC(MEL频率倒谱系数)产生的语音信号特征向量,最后运用十字交叉法,建立起一个说话人识别系统。结合MATLAB平台中的GUI设计预处理、特征提取、训练等几个模板,最后利用神经网络的模式识别,真正实现说话人的识别。
关键词:语音识别 MATLAB 模式识别 倒谱系数
Abstract
Talking is a way of human communication, the most convenient and quick communication, each of the speakers all over the world have their own specific speech, as everyone's fingerprints, are unique. Speaker recognition is widely used in various fields, have been applied to communications, consumer electronic products. This paper will make speech digital transmission, storage, and then identify etc.. The speaker recognition system includes preprocessing, feature extraction, training and recognition of four modules. The preprocessing and feature extraction is very important. There are many preprocessing methods of sampling and quantization, the speech signal is first, and then the pre emphasis and the window. Feature extraction is the process to extract important features of speech signal. Signal analysis in time domain signal short-time average energy and short-time zero crossing rate. Frequency domain analysis can be used LPC cepstrum coefficient and Mel cepstrum coefficient method. In order to get the template training speech signal, can use vector quantization (VQ), hidden Markov model (HMM), BP neural network (ANN) training recognition on the speaker's voice signal.
Speaker recognition in the process of realizing the algorithm is varied. This paper will use the MATLAB simulation tool powerful programming, graphical function and mathematical computation ability. This paper will use the BP neural network as a method of training recognition, using MFCC (MEL frequency cepstrum coefficient) speech signal feature vector is generated, finally using cross method, set up a speaker recognition system. Combined with the MATLAB platform GUI design in the preprocessing, feature extraction, training and several other template, finally using pattern recognition, neural network, realizing the speaker recognition.
Keywords: Speech recognition MATLAB Pattern recognition Cepstral coefficients
第一章 引言
1.1 研究背景及意义
说话人识别技术也被称之为声纹识别技术,它属于一种生物的识别技术。说话人识别技术拥有方便,经济,准确等特点,广受世人瞩目。
最早的语言研究被称为“口耳之学”。因为当时没有可供研究的仪器,只能通过耳听口模仿来进行研究。
最早的语音信号处理研究起源于1876年,电话的发明者贝尔首次使用声电、电声转换技术实现了语音的远距离传输

。
语音信号经过语音合成,语音编码和语音识别三个发展过程。语音识别的实验追溯到20世纪50年代贝尔实验室的Audry系统,此系统仅仅只能识别10个英文数字。又经过很长时间的研究发展,现在我们已经完全进入语音识别时代。
1.2 优势及应用前景
生物认证技术有:虹膜识别,掌纹识别,指纹识别和声纹识别(语音识别)。声纹识别有不丢失,没有记忆和使用方便等独特的优点

。
对于虹膜识别技术,虽然准确性很高,但是实现困难,成本较高,所以不能普遍使用。指纹识别虽然是一种使用比较普遍的识别技术,成本也不算太高,但是用户不易接受,指纹往往和犯罪牵扯在一起。还有一些生物认证技术也因为实现难度过大而不被关注。但是说话人识别技术只需简单的麦克风,一台普通计算机就可以实现。和其他生物识别技术进行对比,说话人识别系统还具有使用方便,低成本,易实现等优点。
说话人识别技术应用前景十分广泛,可在各种安全认证身份的领域发挥重要作用。随着数字化时代的急速发展,数字音频数据随处可见,说话人识别技术不仅在语音检索和信息检索中投入使用,而且不少手机已经加入了语音拨号,语音书写短信,语音打开应用程序等等功能。
1.3 国内外研究现状
20世纪60年代末,世界掀起了一股语音识别的研究热潮。这期间研究出的重要成果包括动态规划(DP)和线性预测编码(LPC)技术等。
语音识别技术取得突破性进展是在20世纪70年代的时候。LPC技术得到了进一步发展,特别是其中的VQ和HMM系统理论。直到今天,这两种理论依旧是研究语音识别最有效,最常用的方法。
20世纪80年代,语音识别迎来了一股新新力量。人们重新开始了人工神经网络(ANN)研究,并有效地将ANN和HMM在同一语音识别中结合使用,使连续语音识别问题变得更加容易。近年来对于人工神经网络(ANN)的研究不断发展,关于语音信号处理的各项内容研究是促使其迅速发展的重要原因之一。同时,它的许多成就体现在语音信号处理技术。
人工神经网络(ANN)以其简单灵活有效的特点,逐渐成为实现语音识别技术的新宠。它将说话人识别技术的探究带入了一个新的高度。
第二章 说话人识别的基本原理
2.1 说话人识别基本知识
2.1.1 语音的发声机理
空气从肺排入喉咙,然后通过声带进入通道,最后由口辐射声波,从而形成了声音。声带以左负责产生激励;声带以右负责的是:“辐射系统”和“声道系统”。之所以存在不同性质的语音,是因为其激励和辐射不同
。
2.1.2 清音和浊音
浊音与清音都统称为音素,而音素则是构成语音信号的基本单元。
发浊音时,空气流经紧绷的声带,声带产生振动,所以声带会周期性的打开、闭合。如果声带的长度短,厚度薄,张力就很大,听起来的的音调就越高,所以浊音的基音频率就越高。
发清音时,空气流经声带,声带是张开的,则由肺排出的空气将不受防碍的经过声门。空气经过声门后会发生两种情况,一种是形成摩擦音,另一种情况则形成爆破音。这两种情况都统称为清音
。
2.1.3 语音信号模型
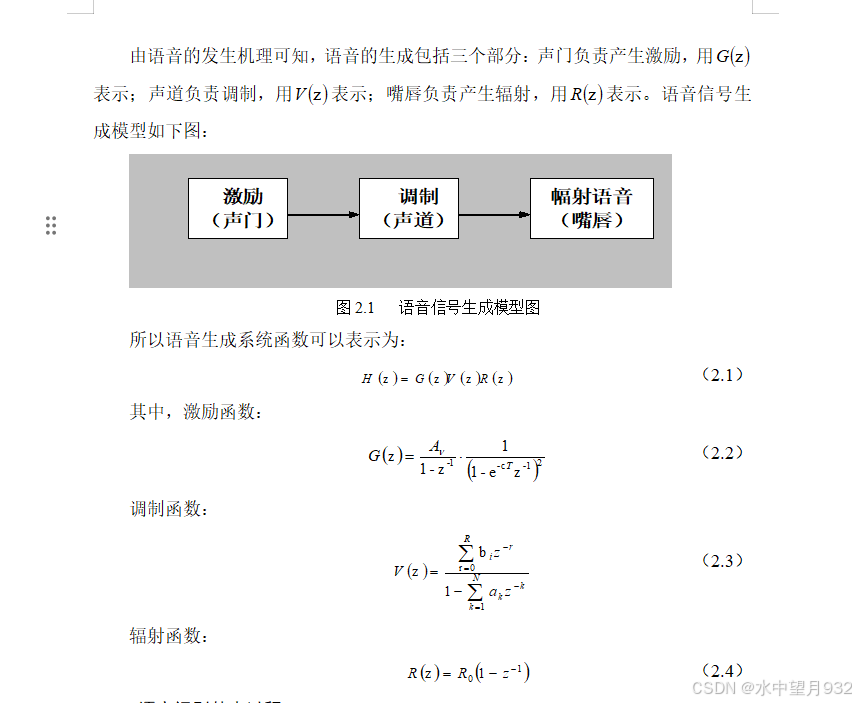
2.1.4 语音识别基本过程
说话人识别即提取说话人语音中特征,然后将此特征作为确定说话人身份的过程。因此,需要找出每一个已知说话人发音中存在的差异,这些差异包括声道差异,发音习惯差异等等。
对于如何找出这些差异,确定说话人的身份,需要解决以下问题
:
- 对说话人的语音进行预处理;
- 提取说话人语音中的特征;
- 用提取出的这些特征为指定说话人建立一个只属于此说话人的语音特征库;
- 用一段未知语音与新建立的语料库进行对比,从而得出结论:此未知语音是否属于已知说话人。
为了解决以上问题,说话人识别系统一般进行以下四个模块的过程:预处理模块、特征提取模块,训练模块与识别模块。
2.2 预处理模块


短时平均过零率同样能够应用于清音与浊音的辨别,也能应用在语音信号的端点检测。但是仅仅使用过零率进行端点检测有一定难度,往往将短时平均能量与其结合起来进行检测使用。
2.3.4 短时自相关分析
自相关函数的功能在于权衡语音信号本身时间函数的相似性。由于浊音和清音的发音机理不同,因此二者在短时平均能量,短时平均幅度,短时平均过零率上都存在显著差异。这些差异使得它们在时间波形上也有很大不同。清音的时间波形杂乱无章,没有规律,并且波形间的相似性较差;浊音则恰好相反,它的时间波形表现出规律的周期性,波形间的相似性较好。所以能够利用短时自相关函数来分辨浊音和清音。语音信号的短时自相关函数
(2.16)
其中
。
式(2.16)表示,语音信号的自相关函数
可由信号
通过一个冲激函数
的滤波器组成。
通过实验,可知浊音与清音的短时自相关函数存在以下特征:
- 浊音信号的短时自相关函数具有一定的周期性;
- 清音信号的短时自相关函数杂乱无章,不存在周期性,其性质与噪声信号类似;
- 窗函数影响着自相关函数,窗长直接影响自相关函数。
2.3.5 LPC倒谱系数(LPCC)
倒谱系数是指语音信号
变换的对数模函数的逆
变换。通常先求信号的傅里叶变换,然后区模的对数,再求傅里叶逆变换。
使已知语音的采样值与线性预测采样值之间达到最小均方差误差,便可得出线性预测系数LPC。LPC是一种参数谱估计方法,并且它的函数的频率响应
反应了声道的频率响应和被分析语音信号的频谱包络。因此,可对
做傅里叶变换得到倒谱系数。,这样的倒谱系数是一种良好的表述信号的参数。
LPC倒谱系数的优点在于:比较完整地去除了语音信号产生的激励信息,LPCC系数的计算量较小,易实现,表述元音的能力强。往往只需几个倒谱系数就可以准确的表述语音信号的共振峰特性。弊端有:表述辅音的能力不好,抗噪声性能也不好。LPCC也继承了LPC的缺点,LPC中包含语音信号高频部分的大部分噪声特征,这会影响系统的性能。
2.3.6 Mel频率倒谱系数(MFCC)
MFCC倒谱系数数拥有良好的辨别能力和抗噪声能力,但它的计算量很大,计算精度要求很高。Mel频率倒谱系数是频率轴的信号频谱转换为Mel尺度变换的倒谱域,然后获得倒谱系数。
由于人类对约1000Hz以上的声响频率范围的感知不遵循线性关系,而是遵循在对数频率坐标上的近似线性关系。所以, Mel频率的计算公式可以表示为:
(2.17)
MFCC参数的计算过程如下:
- 对计算已知语音信号的傅里叶变换获得其频谱;
- 对频谱的幅度求平方,得到能量谱;
- 使用一组三角滤波器对(2)中得到的能量谱进行带通滤波,滤波器的数量一般和临界带数一致。假设滤波器的个数为,滤波后得到的输出为
,其中;
- 对滤波后的输出取对数,然后做点的傅里叶逆变换,并进行反离散余弦变换,得到的值即为MFCC:
(2.18)
其中,MFCC系数的个数L一般取12~16左右。
2.4 训练和识别模块
语音识别中的训练模块是把语音信号中提取的特征参数组成一个模型库,这个模型库的形成过程就是训练。而一个模型库的形成则需要几十甚至上百个特征参数。
语音识别的基本原理:将未知语音与训练获得模板集合进行对比,找出模板集合和未知语音匹配最优的集合。通过此模板识别出位置语音。
一般来说语音识别有以下几种方法:基于声道模型与语音知识的方法、模式匹配法、统计模型法与人工神经网络法。其中后三种方法使用比较广泛,其中实现模式匹配的方法有:矢量量化(VQ)和动态时间规整(DTW);实现统计模型法最常用的方法是隐马尔科夫模型(HMM);常用的人工神经网络法有:反向传播(BP)网络、径向基函数网络(RBF)和小波网络。

2.4.3 人工神经网络模型(ANN)
ANN的具体内容是模仿人类大脑的模型,将听觉体系中人类神经机制的信息处理系统引用到机器的研究中,因此具有学习和理解的能力。ANN在语音识别中的应用十分广泛,如分类区分、共振峰检测等。其中用的最多的是利用神经网络的分类区分能力。人工神经网络可以分辨浊音和清音,鼻音、摩擦音和爆破音。长期的实验证明了人工神经网络强大的分类区分能力。
将神经网络之所以能应用到语音识别中,是经过大量研究和训练而建立的,是语音特征在系统中的一种映射。它与传统的识别方法完全不同的地方是:单个权值与识别基元之间没有十分明确的对应关系,只存在整个权值构成的系统参数与整个识别空间之间的对应关系。从处理信息方面来看:一组信息存储在人工神经网络内部是乱中有序的,在存储信息过程中ANN对信息进行了大量的处理,而不是单纯的把信心孤立地存在内部。存储和处理信息是密不可分的。但用人工神经网络识别语音有个很大的缺陷:时序性很差,没有解决时间一致的问题。人工神经网络的具体模型如下:
当神经元j有多个输入
与一个输出
时,输入与输出的关系可表示成以下关系式:
(2.26)
其中
表示阈值,
表示从神经元i到神经元j的连接权重因子,
表示激励函数。上式也可简化为:
(2.27)
其中
。
激励函数
可选择线性函数,也可选择非线性函数。常见的有:
- 阶跃函数:;
(2)S型函数:
;
(3)双曲正切函数:
(4)高斯函数:
。
最为常见、最具典型性且最简的人工神经网络是BP神经网络。BP神经网络是采用误差的反向传播算法的多层感应器神经网络,是一种单向传输的多层前向网络,网络不仅有输入与输出节点,又有单层或多层隐层的节点,同层节点中没有任何祸合。输入的语音信号首先从输入节点挨个传送到每个隐层的节点,然后传输至输出节点,每一隐层节点的输出只关系着下一隐层节点的输出。
2.4.4 HMM和ANN的混合模型
隐马尔可夫模型(HMM)和人工神经网络模型(ANN)的混合模型完整的使用了ANN的以下优点,成功掩盖了HMM的大部分缺点与不足,主要有以下三个:
- 混合模型可以很好地适应语音数据无规律的变化。这可以不必刻意选取特殊的语音特征参数输入模型库进行训练和识别。
- 把人类的听觉模型也融入人工神经网络中,在人工神经网络的开始端可以在同一时刻输入邻近帧的语音特征参数矢量,因此它与语音信号的真实形态更加一致。
- ANN的结束端可以和任何形式的概率分布函数达到一致,不仅可以很好地掌控训练模型库中的概率分布的特性,还可以很真实地描述语音信号的概率分布曲线。
第三章 基于Matlab的说话人识别
3.1 说话人识别系统平台介绍
对于说话人识别系统平台的搭建十分简单,只需用到一台电脑,麦克风,matlab软件。
Matlab是一款强大仿真、编程软件。自1984年问世以来,经过时间的凝练,已经成为广大学者、师生最常用和最信赖的仿真软件。Matlab对人们强大的影响表现在两个方面:传统的分析设计方法在Matlab平台上运用十分方便快捷,准确度也很可靠;而新的分析设计方法也在Matlab上不断发展。基于matlab的说话人识别会用到matlab的编程功能和GUI仿真功能。
麦克风的主要作用是采集说话人语音。
本系统对于电脑的要求不高,只需安装matlab软件。以上这些平台的基础准备好了,一个说话人识别系统平台就搭建起来了。这样搭建起来的说话人识别系统不仅方面快捷,而且价格便宜。
3.2 语音采集模板(Speech Recording Plane)
语音采集模板的主要目的便是采集说话人的声音,为后来的语音处理、识别做好准备。图3.1为语音采集模块:
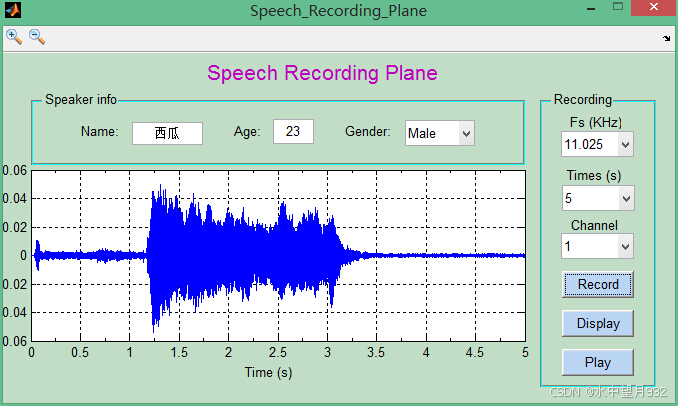
图3.1 语音采集模板
图3.1是利用matlab的GUI制作的。它包含了说话人的信息,如:姓名、年龄和性别。这些信息需要预先设置。对于语音的采集,设置了三个采集的下拉框:频率、时间和通道,和三个按键采集、显示语音和回放。语音信号的采集频率是指采样模块在1s内对声音信号的采集次数,采样频率越高,语音复原后就更接近实际情况。图3.1中设置了四种采集频率,

下拉框中可以选择11.025

、22.050

、44.100

和88.200

。语音采集的时间的长短也是可变的,Times(s)下拉框中设置了5s、10s、15s、30s、60s和120s六种不同的采集时间。上图实现了语音的采集(Record)、显示语音(Display)和回放(Play),并且存储采集到的语音信号,这里采集的语音信号将被命名为“西瓜.mat”而存储下来。
3.3 预处理模板(Voice Preprocessing Plane)
预处理就是将语音进行一些基本的处理,使语音更有利于识别。前面已经介绍过预处理的方法和过程。这个模块的主要作用是截取语音有声音的部分,舍弃没有声音的时间段,然后将有声音的部分拼接在一起。同样利用matlab的GUI做了一个预处理模块,如图3.2: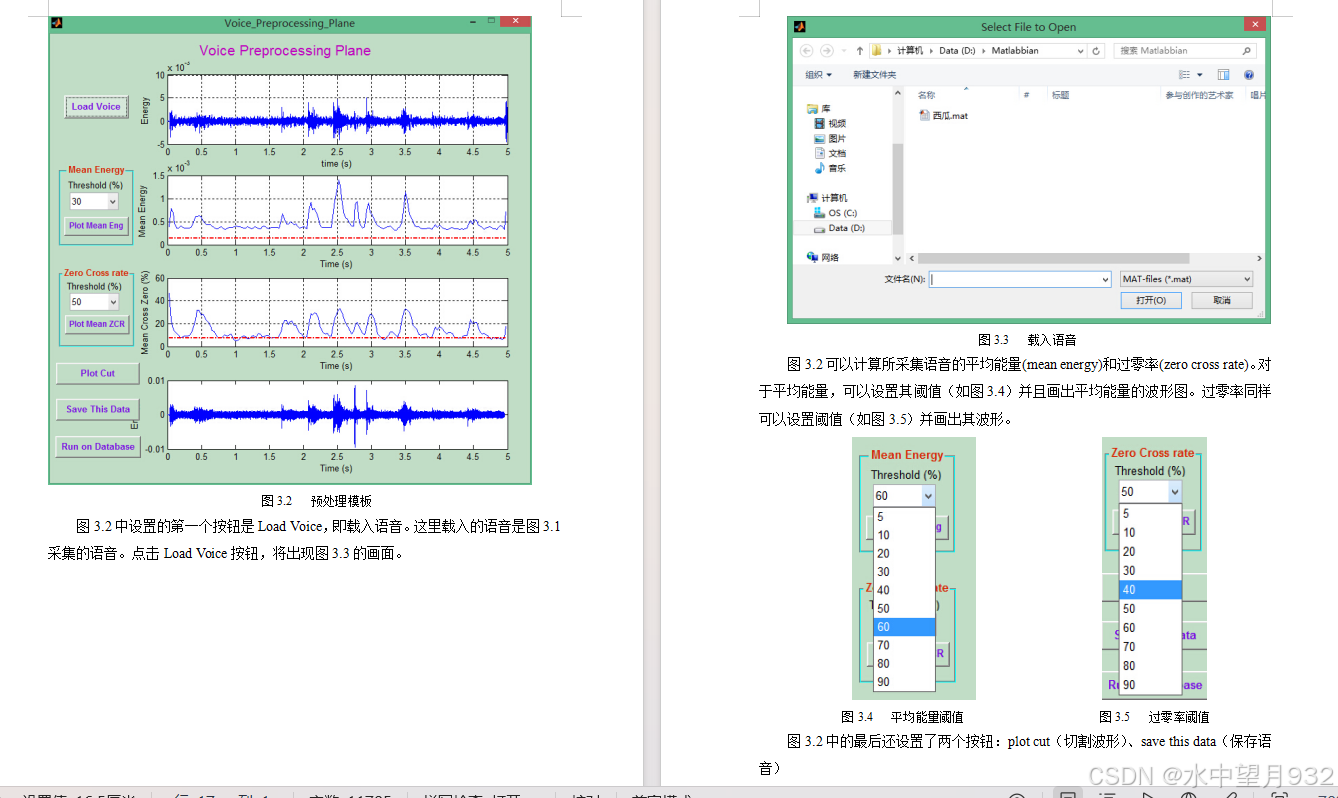
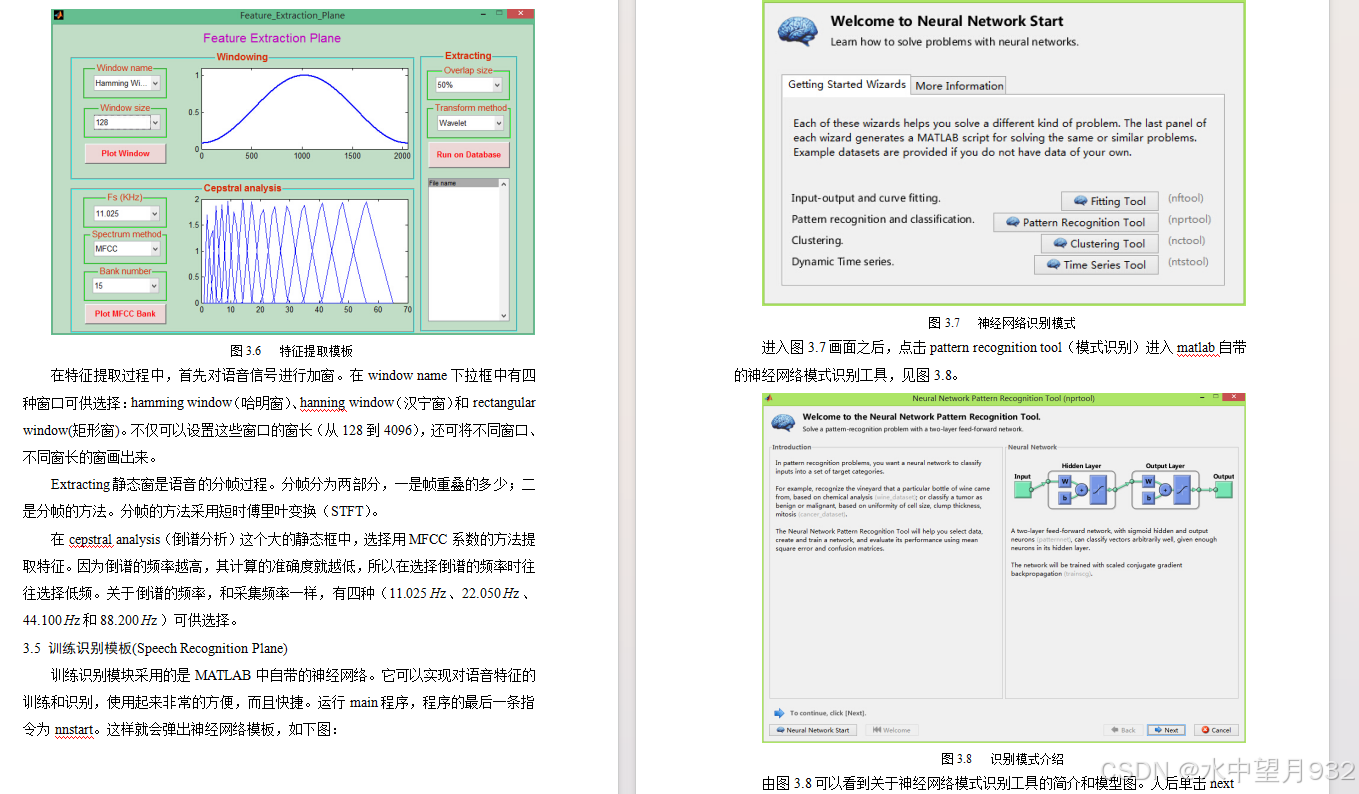
- 总结与展望
4.1 总结
本文充分展现了Matlab 仿真软件强大的数学计算和编程能力。通过对其自带工具GUI图形用户界面和神经网络模式识别的使用,结合程序的自由编写,使一些极其复杂的数学计算过程变得方便快捷。在MATLAB仿真软件平台上实现说话人语音的识别,基本达到预期目的。通过matlab实现了对说话人语音的采集、处理、训练和识别。Matlab中的神经网络模式识别系统是实现各类识别的重要工具。本文采用神经网络模式识别作为语音识别的过程,能准确识别3人及其以下说话人,识别率高达100%;能较好的识别3到10,识别率的范围为81.6092%~95.4128%;10~20人的识别率一般;20人以上的识别率较差。所以,本文最大的不足就在于识别人数较多时,识别的准确率较差。再进一步改进实验中,可以讲训练识别的算法改为隐马尔可夫模型(HMM)或者高斯混合模型(GMM)。
4.2 展望
随着现代技术的发展,语音识别技术已经取得了飞速的发展,也取得了许多成就。但是人类语言交流都是在十分复杂的环境下进行的,难免会存在各种噪声,使得计算机很难具有人类一样的智能识别。因此对未来语音识别的发展展望如下:
- 口音识别能力
由于人类生活的领域不同,导致人类交流的语言不大相同。在今后语音识别技术的发展过程中,对于不同语言、不同口音的识别将是一个研究方向。
- 扩展能力
现在有各种技术的语音识别系统,对于这些系统与其相关的链接上,也就是该系统的扩展能力还有待进一步研究和发展
- 正确率
一个较好的语音识别系统,应该要有较好的使用价值,其识别率应该在95%以上。所以未来对于语音识别的正确率也提出了比较高的要求。
- 识别速度
识别速度越快,就越和真实人类语音交流相同。这就要求语音识别系统在未来的发展中,想着高识别速度发展,不断达到和口语速度一致。
- 新理论、新方法
当今世界是一个发展的世界,软硬件结合是时代的一个潮流。所以在今后语音识别技术的发展中,结合已有相关理论知识和软硬件基础,不断创造出新的语音识别处理方法。
[1]吴朝辉,杨莹春.说话人识别模型与方法.2009年 北京 清华大学出版社
[2]王永琦.MATLAB与音频视频技术.2013年 北京 清华大学出版社
[3]罗华飞.MATLAB GUI设计学习手机.2009年 北京 北京航空航天大学出版社
[4]张雄伟,陈亮,杨吉斌.现代语音处理技术及应用.2003年 北京 机械工业出版社
[5]D.G.Childers.Matlab之语音处理与合成工具箱.2004年 北京 清华大学出版社
[6]张雪英.数字语音处理及MATLAB仿真.2010年 北京 电子工业出版社
[7]何英,何强.MATLAB扩展编程.北京 清华大学出版社 2002
[8]Jean Claude Junqua.Robust Speech Recognition in Embedded System and PC Application.Snger.2000
[9] Rabiner L, Juang B H. Fundamentals of Speech Recognition, Prentice-Hall International. Inc 1999
[10] 黄文梅, 熊桂林, 杨勇.信号分析与处理—MATLAB语言及应用.北京 国防科技大学出版社 2000
[11] 张军英,说话人识别的现代方法与技术 西北大学出版社 1994
[12] 杨行峻,迟惠生.语音数字信号处理.合肥 电子工业出版社 1995
[13]王炳锡,屈丹,彭煊.实用语音识别基础.北京 国防丁业出版社 2005
[14] Christoph Gerber. A General Approach to Speech Recognition. Electronic Workshops in Computing 1995
[15]刘么和.语音识别与控制应用技术 北京 科学出版社 2008
[16]胡广书.现代信号处理教程 北京 清华大学出版社 2004
[17] 张志涌,精通MATLAB 北京航空航天大学出版社 2000
[18] 胡征,矢量量化原理及应用 西安电子科技大学出版社 1998
附 录
Main函数:
load_wav;%(1)载入数据,数据在矩阵Y中,每列一个说话人
%(2)预处理及特征提取
w=512;%窗口大小
P=0.5;%能量大小
N=size(Y,2);
fs=8000;
YY=[];%装载所有说话人向量,行向量
for i=1:N
V=preprocessing1(Y(:,i),w,P,fs);
[M1,N1]=size(V);
T=ones(M1,1)*i;
YY=[YY;[V,T]];
end
%构造ANN的多类分类数据
X=YY(:,1:end-1);
Y=YY(:,end);
clear YY;
N=size(X,1);
%识别小规模分类问题
SN=[1:10];
indx=[];
for i=1:length(SN)
indx1=find(Y(:,1)==SN(i));%
indx=[indx;indx1];
end
X1=X(indx,:);
Y1=Y(indx,:);
N1=size(X1,1);
YY=zeros(N1,length(SN));
for i=1:N1
YY(i,Y1(i,1))=1;
end
X1=X1';
YY=YY';
save XY2.mat X1 YY Y1;
clear all;
load XY2.mat;
pause(1);
nnstart
Load_wav函数:
clear;clc;
cd dataset20
N=6;%the number of sec.
Y=[];
for i=2:21
if i<10
eval(['[y,fs,Nbits,Opts]=wavread(''000' num2str(i) '-cell-A.wav'');']) ;
else
eval(['[y,fs,Nbits,Opts]=wavread(''00' num2str(i) '-cell-A.wav'');']) ;
end
i
fs
Y(:,i)=y(fs:fs*N);
end
Y(:,1)=[];
cd ..
L=size(Y,1);
for i=1:20
subplot(4,5,i)
plot([1:L]/fs,Y(:,i));
axis tight;
end
preprocessing1函数:
function V_feature=preprocessing1(Y,w,P,Fs)
y=Y;
w=300;
N=length(y);
N_w=length(y)/w;
mean_y=mean(abs(y));
y_new=[];
for i=1:N_w-1
y_mean_eng(i)=mean(abs(y(((i-1)*w+1):(i+1)*w)));
if y_mean_eng(i)>=P*mean_y
y_new=[y_new;y(((i-1)*w+1):i*w)];
end
End
y_new=y_new';
WS=1024;
Over_size=0.1;
N_Banks=36;
V_feature=extraction(y_new,Fs,WS,Over_size,N_Banks);
Start函数:
[a,b]=max(output);
Y2B=[Y1(:,1),b']
Q=length(find(Y1(:,1)==b'))/length(Y1(:,1))*100
N=max(Y1);
A=[N,Q];
eval(['save A.mat'])
plot(N,Q,'O')
title('人数--识别率')
xlabel('人数')
ylabel('识别率')


















 1274
1274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









