






标题:探索 Python 数据分析在工业互联网中的基石
在当今数字化的工业时代,Python 数据分析正成为工业互联网领域的关键力量。让我们一同深入了解其知识基础内容
首先,要掌握 Python 的基础知识,包括语法、数据结构和控制流。这是构建数据分析能力的根基。
数据采集
-
数据采集是关键的第一步。我们需要了解如何从各种工业数据源,如传感器、设备日志等,获取数据并将其导入到 Python 环境中。常见的库如 pandas 在此发挥重要作用,它能高效地处理和整理数据。
-
数据采集的代码会根据你要采集的数据来源和格式而有所不同。一般来说,你可以使用 Python 的requests库来发送 HTTP 请求,并使用BeautifulSoup或Pandas来解析和处理响应的数据。
以下是一个简单的数据采集示例代码,用于从网页上采集数据:
import requests
from bs4 import BeautifulSoup
# 定义要采集的网页 URL
url = 'http://example.com'
# 发送 HTTP 请求并获取响应
response = requests.get(url)
# 检查响应状态码
if response.status_code!= 200:
print(f'请求失败,状态码: {response.status_code}')
exit()
# 使用 BeautifulSoup 解析响应内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取所需的数据
data = soup.find('div', {'class': 'data-container'}).text
# 打印采集到的数据
print(data)
在上述示例中,我们首先定义了要采集的网页 URL。然后,使用requests.get()方法发送 HTTP GET 请求,并获取响应。我们检查响应的状态码,如果不是 200,则表示请求失败,退出程序。
接下来,使用BeautifulSoup解析响应的 HTML 内容,并使用find()方法找到包含数据的特定div元素。最后,提取该元素的文本内容,并将其打印出来。
请注意,这只是一个简单的数据采集示例,实际的数据采集可能涉及更复杂的逻辑,例如处理多个页面、解析不同的数据格式、处理异常情况等。此外,还需要遵守网站的使用条款和法律规定,确保你的采集行为是合法和合规的
数据清洗和预处理
- 数据清洗和预处理必不可少。工业数据往往存在缺失值、异常值等问题,我们要学会运用合适的方法进行清理和修正,以确保数据的质量。
对于数据分析,统计学概念是基础。理解均值、方差、标准差等统计指标,能帮助我们洞察数据的特征和趋势。
1.数据清洗
1.1数据去重
-import pandas as pd
# 创建一个含有重复值的表格
df = pd.DataFrame(
[['甲',80],['甲',85],['乙',90]],
columns=['姓名','分数']
)
df
df.drop_duplicates(subset=['姓名'],keep='first',inplace=True) # inplace使修改在原数据上生效
df #重新打印
2.缺失值的处理
2.1生成python中缺失值
# 生产python中缺失值
import numpy as np
print(np.nan) #方法一
print(float('nan')) #法二
print(None) #方法三 python自带空值

2.2缺失值的查找
df = pd.read_csv(r'E:\TAN XUE HUA\dataset\新用户表.csv',encoding='gbk')
df.isnull().sum()

2.3删除法处理缺失值
df_nan = pd.DataFrame(
[['甲',80,'1班'],[np.nan,np.nan,'1班'],['乙',np.nan,'1班']],
columns=['姓名','分数','班级']
)
df_nan
#情况一:针对一列来删除
df_nan.dropna(subset=['姓名'])
#情况二:针对多列并且
df_nan.dropna(subset=['姓名','分数'],how='any')
#情况三:针对多列并且所有的数据缺失才删除
df_nan.dropna(subset=['姓名','分数'],how='all')

3 异常值处理
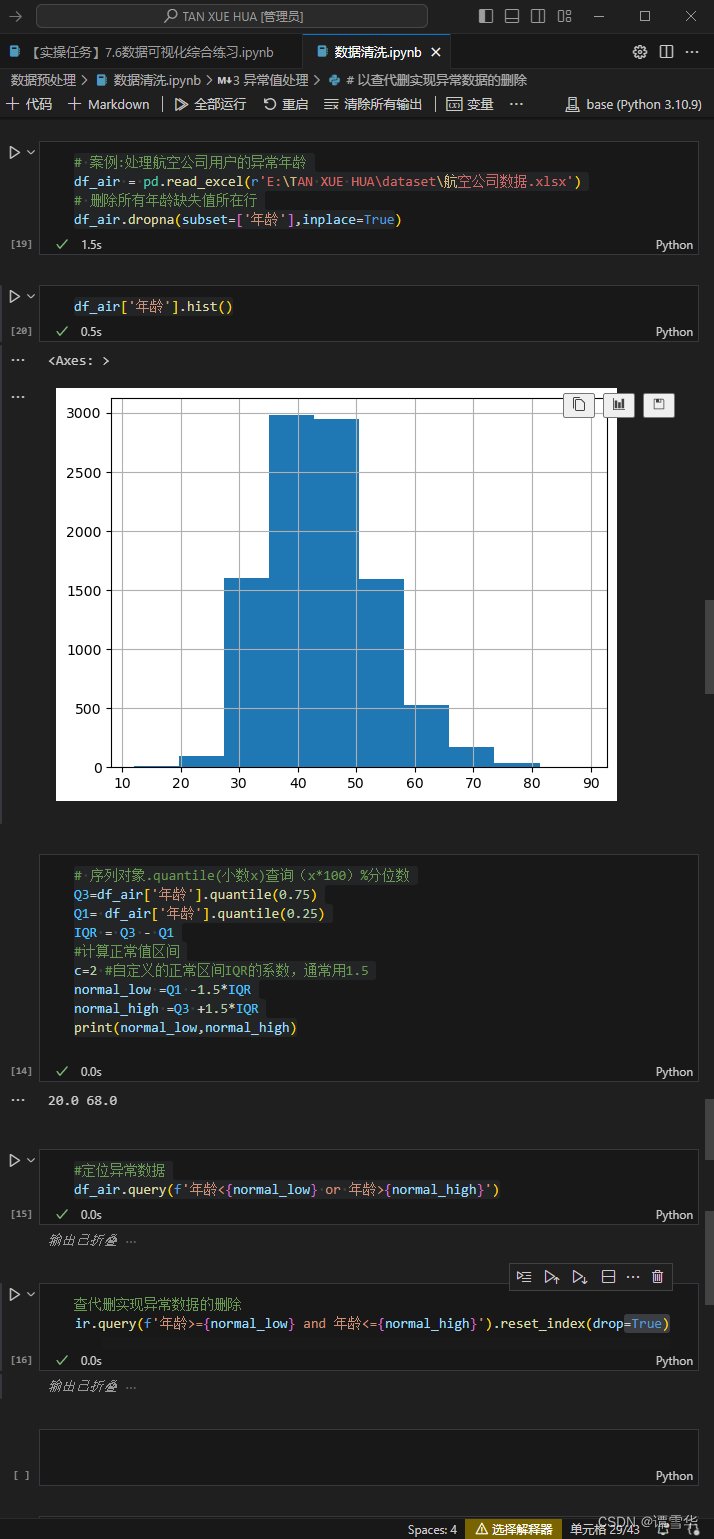
# 案例:处理航空公司用户的异常年龄
df_air = pd.read_excel(r'E:\TAN XUE HUA\dataset\航空公司数据.xlsx')
# 删除所有年龄缺失值所在行
df_air.dropna(subset=['年龄'],inplace=True
df_air['年龄'].hist()
# 序列对象.quantile(小数x)查询(x*100)%分位数
Q3=df_air['年龄'].quantile(0.75)
Q1= df_air['年龄'].quantile(0.25)
IQR = Q3 - Q1
#计算正常值区间
c=2 #自定义的正常区间IQR的系数,通常用1.5
normal_low =Q1 -1.5*IQR
normal_high =Q3 +1.5*IQR
print(normal_low,normal_high)
#定位异常数据
df_air.query(f'年龄<{normal_low} or 年龄>{normal_high}')
# 以查代删实现异常数据的删除
df_air.query(f'年龄>={normal_low} and 年龄<={normal_high}').reset_index(drop=True)
4.数据预处理
数据预处理是指在进行数据分析或建模之前,对数据进行的一系列清洗、转换和整理操作,以确保数据的质量和可用性。以下是一个简单的数据预处理代码示例,用于处理一个包含学生成绩的数据集:
import pandas as pd
# 读取数据文件
data = pd.read_csv('student_scores.csv')
# 查看数据的基本信息
print(data.info())
# 去除缺失值
data.dropna(inplace=True)
# 去除重复值
data.drop_duplicates(inplace=True)
# 数据标准化
data['score'] = (data['score'] - data['score'].mean()) / data['score'].std()
# 数据归一化
data['score'] = (data['score'] - data['score'].min()) / (data['score'].max() - data['score'].min())
# 查看处理后的数据
print(data.head())
在上述代码中,我们首先使用pandas库的read_csv()函数读取数据文件,并使用info()函数查看数据的基本信息,包括数据的行数、列数、数据类型和缺失值等情况。
然后,我们使用dropna()函数去除数据中的缺失值,并使用drop_duplicates()函数去除数据中的重复值。
接下来,我们使用mean()和std()函数计算数据的均值和标准差,并使用(data[‘score’] - data[‘score’].mean()) / data[‘score’].std()公式对数据进行标准化处理,将数据转换为均值为 0,标准差为 1 的标准正态分布。
最后,我们使用min()和max()函数计算数据的最小值和最大值,并使用(data[‘score’] - data[‘score’].min()) / (data[‘score’].max() - data[‘score’].min())公式对数据进行归一化处理,将数据转换为 0 到 1 之间的数值。
统计学概念
- 对于数据分析,统计学概念是基础。理解均值、方差、标准差等统计指标,能帮助我们洞察数据的特征和趋势。
以下是一些统计学中的基本概念和方法:
1.数据收集:通过各种方法收集数据,例如调查、实验、观察等。
描述性统计:对数据进行总结和描述,包括均值、中位数、众数、标准差等指标,以及数据的分布情况。
2.推断性统计:根据样本数据推断总体的特征和关系,包括假设检验、置信区间估计等。
3.概率分布:研究随机变量的概率分布,如正态分布、二项分布等。
4.参数估计:根据样本数据估计总体参数,如均值、比例等。
5.假设检验:对关于总体参数的假设进行检验,以确定是否拒绝或接受该假设。
6.方差分析:比较多个组之间的差异,判断因素对结果的影响。
7.回归分析:研究变量之间的关系,建立回归模型进行预测和解释。
8.时间序列分析:分析时间序列数据的趋势、季节性和周期性等特征。
9.数据可视化:使用图表和图形展示数据,帮助理解和传达信息。
统计学的应用非常广泛,包括商业、医学、社会科学、工程等领域。它可以帮助我们理解数据背后的规律,做出基于数据的决策,并评估结果的可靠性。
可视化
- 可视化是直观呈现数据的有力手段。matplotlib 和 seaborn 等库让我们能够创建精美的图表,将复杂的数据转化为易于理解的图形。
- matplotlib 是一个广泛使用的基础绘图库,它提供了高度的灵活性和定制性,可以创建各种复杂的图表。seaborn 则是在 matplotlib 的基础上构建的,它提供了一些更高级的绘图功能和更美观的默认样式,使得创建高质量的图表更加容易
使用这些库,我们可以通过以下步骤创建可视化图表:
1.导入所需的库
import matplotlib.pyplot as plt
import seaborn as sns
2.准备数据:
- 将需要可视化的数据整理成适合绘图的格式。
3.选择合适的图表类型:
- 根据数据的特点和目的,选择合适的图表类型,如折线图、柱状图、饼图等。
4.绘制图表:
- 使用相应的函数创建图表,并根据需要进行定制,如设置标题、坐标轴标签、颜色、字体等。
5.展示图表:
- 使用 plt.show() 或保存图表到文件。
例如,要创建一个简单的折线图,可以使用以下代码:
import matplotlib.pyplot as plt
# 准备数据
x = [1, 2, 3, 4, 5]
y = [5, 4, 3, 2, 1]
# 绘制折线图
plt.plot(x, y)
# 设置标题和坐标轴标签
plt.title('Simple Line Plot')
plt.xlabel('X')
plt.ylabel('Y')
# 展示图表
plt.show()
机器学习算法
- 也在工业互联网中有广泛应用。从简单的线性回归到复杂的神经网络,Python 提供了丰富的工具和库来构建预测模型和进行数据分析。
以下是一些常见的机器学习算法:
1.线性回归:用于建立自变量和因变量之间的线性关系模型。
2.逻辑回归:用于分类问题,通过构建逻辑函数来预测类别。
3.决策树:通过构建树状结构来进行分类和回归。
4.随机森林:由多个决策树组成的集成学习算法,提高了模型的准确性和稳定性。
5.支持向量机:通过寻找最优超平面来进行分类和回归。
6.K 近邻算法:根据数据点之间的距离进行分类和回归。
7.神经网络:模拟人类大脑的神经元结构,用于处理复杂的模式识别和预测问题。
8.聚类算法:将数据点分成不同的组或簇。
9.降维算法:减少数据的维度,同时保留重要的信息。
在工业场景中,时间序列分析尤为重要,用于处理和分析随时间变化的数据。
此外,了解数据存储和数据库操作,以便有效地管理和查询大规模的工业数据。
总之,掌握这些 Python 数据分析的知识基础内容,将为我们在工业互联网领域开启无限可能,助力工业智能化的发展。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









