







本项目将介绍如何基于PaddleNLP对ERNIE 3.0预训练模型微调完成法律文本多标签分类预测。本项目主要包括“什么是多标签文本分类预测”、“ERNIE 3.0模型”、“如何使用ERNIE 3.0中文预训练模型进行法律文本多标签分类预测”等三个部分。
1. 什么是多标签文本分类预测
文本多标签分类是自然语言处理(NLP)中常见的文本分类任务,文本多标签分类在各种现实场景中具有广泛的适用性,例如商品分类、网页标签、新闻标注、蛋白质功能分类、电影分类、语义场景分类等。多标签数据集中样本用来自 n_classes 个可能类别的m个标签类别标记,其中m的取值在0到n_classes之间,这些类别具有不相互排斥的属性。通常,我们将每个样本的标签用One-hot的形式表示,正类用1表示,负类用0表示。例如,数据集中样本可能标签是A、B和C的多标签分类问题,标签为[1,0,1]代表存在标签 A 和 C 而标签 B 不存在的样本。
近年来,随着司法改革的全面推进,“以公开为原则,不公开为例外”的政策逐步确立,大量包含了案件事实及其适用法律条文信息的裁判文书逐渐在互联网上公开,海量的数据使自然语言处理技术的应用成为可能。法律条文的组织呈树形层次结构,现实中的案情错综复杂,同一案件可能适用多项法律条文,涉及数罪并罚,需要多标签模型充分学习标签之间的关联性,对文本进行分类预测。
2. ERNIE 3.0模型
ERNIE 3.0首次在百亿级预训练模型中引入大规模知识图谱,提出了海量无监督文本与大规模知识图谱的平行预训练方法(Universal Knowledge-Text Prediction),通过将知识图谱挖掘算法得到五千万知识图谱三元组与4TB大规模语料同时输入到预训练模型中进行联合掩码训练,促进了结构化知识和无结构文本之间的信息共享,大幅提升了模型对于知识的记忆和推理能力。
ERNIE 3.0框架分为两层。第一层是通用语义表示网络,该网络学习数据中的基础和通用的知识。第二层是任务语义表示网络,该网络基于通用语义表示,学习任务相关的知识。在学习过程中,任务语义表示网络只学习对应类别的预训练任务,而通用语义表示网络会学习所有的预训练任务。
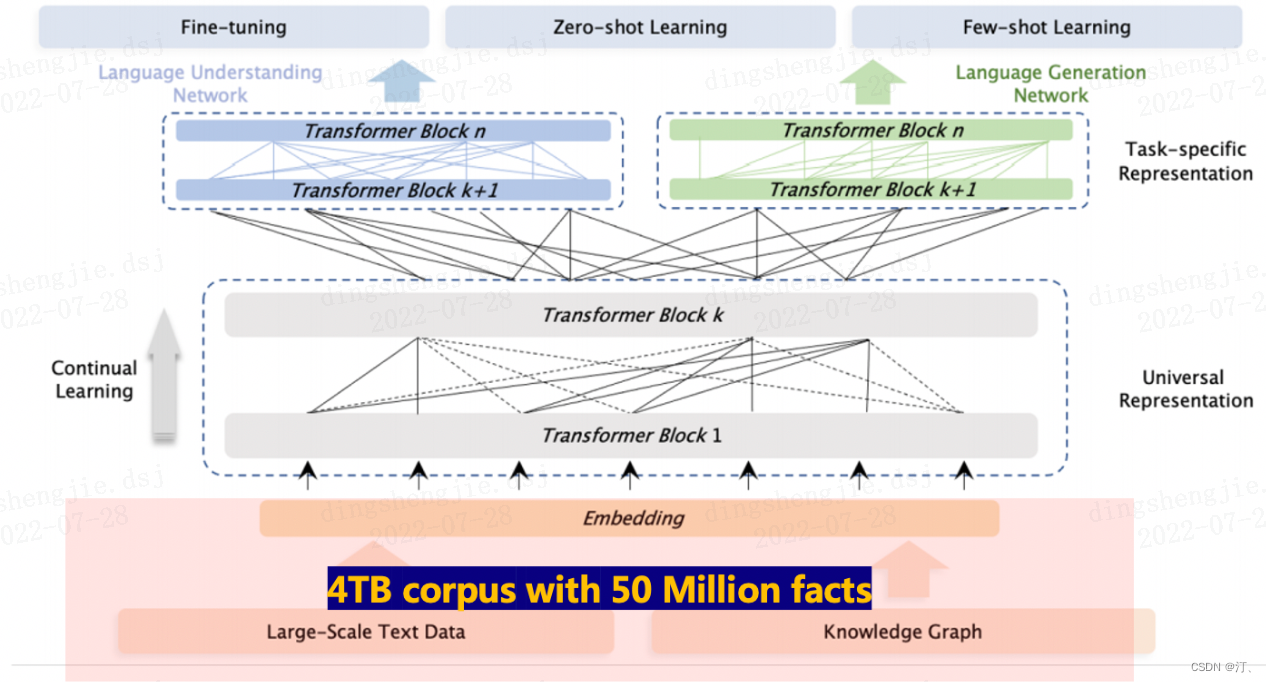
comment: <> (ERNIE 3.0介绍参考新闻稿 http://ex.chinadaily.com.cn/exchange/partners/82/rss/channel/cn/columns/snl9a7/stories/WS60e41d0fa3101e7ce9758648.html)
3. ERNIE 3.0中文预训练模型进行法律文本多标签分类预测
3.1 环境准备
AI Studio平台默认安装了Paddle和PaddleNLP,并定期更新版本。 如需手动更新Paddle,可参考飞桨安装说明,安装相应环境下最新版飞桨框架。使用如下命令确保安装最新版PaddleNLP:
3.2 加载法律文本多标签数据
本数据集(2019年法研杯要素识别任务)来自于“中国裁判文书网”公开的法律文书,每条训练数据由一份法律文书的案情描述片段构成,其中每个句子都被标记了对应的类别标签,数据集一共包含20个标签,标签代表含义如下:
代码语言:txt
复制
DV1 0 婚后有子女
DV2 1 限制行为能力子女抚养
DV3 2 有夫妻共同财产
DV4 3 支付抚养费
DV5 4 不动产分割
DV6 5 婚后分居
DV7 6 二次起诉离婚
DV8 7 按月给付抚养费
DV9 8 准予离婚
DV10 9 有夫妻共同债务
DV11 10 婚前个人财产
DV12 11 法定离婚
DV13 12 不履行家庭义务
DV14 13 存在非婚生子
DV15 14 适当帮助
DV16 15 不履行离婚协议
DV17 16 损害赔偿
DV18 17 感情不和分居满二年
DV19 18 子女随非抚养权人生活
DV20 19 婚后个人财产
数据集示例:
代码语言:txt
复制
text labels
所以起诉至法院请求变更两个孩子均由原告抚养,被告承担一个孩子抚养费每月600元。 0,7,3,1
2014年8月原、被告因感情不和分居,2014年10月16日被告文某某向务川自治县人民法院提起离婚诉讼,被法院依法驳回了离婚诉讼请求。 6,5
女儿由原告抚养,被告每月支付小孩抚养费500元; 0,7,3,1
使用本地文件创建数据集,自定义read_custom_data()函数读取数据文件,传入load_dataset()创建数据集,返回数据类型为MapDataset。更多数据集自定方法详见如何自定义数据集。
代码语言:python
复制
# 自定义数据集
import re
from paddlenlp.datasets import load_dataset
def clean_text(text):
text = text.replace("\r", "").replace("\n", "")
text = re.sub(r"\\n\n", ".", text)
return text
# 定义读取数据集函数
def read_custom_data(is_test=False, is_one_hot=True):
file_num = 6 if is_test else 48 #文件个数
filepath = 'raw_data/test/' if is_test else 'raw_data/train/'
for i in range(file_num):
f = open('{}labeled_{}.txt'.format(filepath, i))
while True:
line = f.readline()
if not line:
break
data = line.strip().split('\t')
# 标签用One-hot表示
if is_one_hot:
labels = [float(1) if str(i) in data[1].split(',') else float(0) for i in  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









