







做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
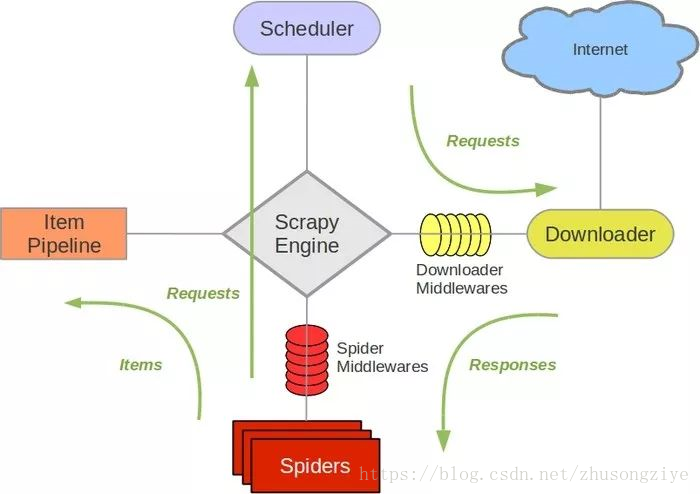
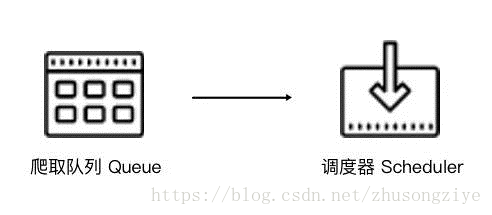
Scrapy单机爬虫中有一个本地爬取队列Queue,这个队列是利用deque模块实现的。如果新的Request生成就会放到队列里面,随后Request被Scheduler调度。之后,Request交给Downloader执行爬取,简单的调度架构如下图所示。
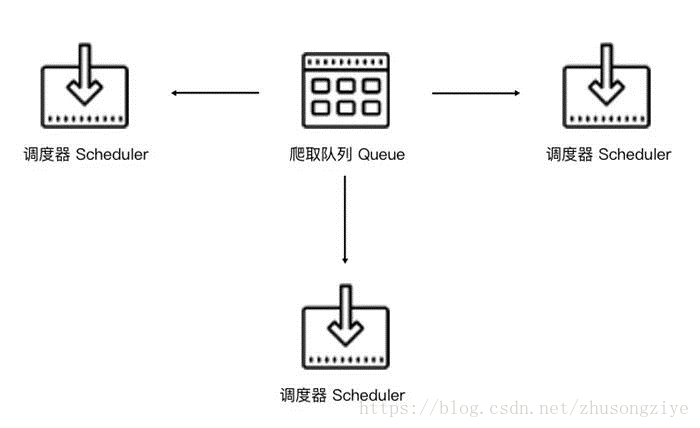
如果两个Scheduler同时从队列里面取Request,每个Scheduler都有其对应的Downloader,那么在带宽足够、正常爬取且不考虑队列存取压力的情况下,爬取效率会有什么变化?没错,爬取效率会翻倍。
这样,Scheduler可以扩展多个,Downloader也可以扩展多个。而爬取队列Queue必须始终为一个,也就是所谓的共享爬取队列。这样才能保证Scheduer从队列里调度某个Request之后,其他Scheduler不会重复调度此Request,就可以做到多个Schduler同步爬取。这就是分布式爬虫的基本雏形,简单调度架构如下图所示。
我们需要做的就是在多台主机上同时运行爬虫任务协同爬取,而协同爬取的前提就是共享爬取队列。这样各台主机就不需要各自维护爬取队列,而是从共享爬取队列存取Request。但是各台主机还是有各自的Scheduler和Downloader,所以调度和下载功能分别完成。如果不考虑队列存取性能消耗,爬取效率还是会成倍提高。
二、维护爬取队列
那么这个队列用什么来维护?首先需要考虑的就是性能问题。我们自然想到的是基于内存存储的Redis,它支持多种数据结构,例如列表(List)、集合(Set)、有序集合(Sorted Set)等,存取的操作也非常简单。
Redis支持的这几种数据结构存储各有优点。
- 列表有
lpush()、lpop()、rpush()、rpop()方法,我们可以用它来实现先进先出式爬取队列,也可以实现先进后出栈式爬取队列。 - 集合的元素是无序的且不重复的,这样我们可以非常方便地实现随机排序且不重复的爬取队列。
- 有序集合带有分数表示,而Scrapy的Request也有优先级的控制,我们可以用它来实现带优先级调度的队列。
我们需要根据具体爬虫的需求来灵活选择不同的队列。
三、如何去重
Scrapy有自动去重,它的去重使用了Python中的集合。这个集合记录了Scrapy中每个Request的指纹,这个指纹实际上就是Request的散列值。我们可以看看Scrapy的源代码,如下所示:
import hashlib
def request_fingerprint(request, include_headers=None):
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b’')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
request_fingerprint()就是计算Request指纹的方法,其方法内部使用的是hashlib的sha1()方法。计算的字段包括Request的Method、URL、Body、Headers这几部分内容,这里只要有一点不同,那么计算的结果就不同。计算得到的结果是加密后的字符串,也就是指纹。每个Request都有独有的指纹,指纹就是一个字符串,判定字符串是否重复比判定Request对象是否重复容易得多,所以指纹可以作为判定Request是否重复的依据。
那么我们如何判定重复呢?Scrapy是这样实现的,如下所示:
def __init__(self):
self.fingerprints = set()
def request_seen(self, request):
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
如果你也是看准了Python,想自学Python,在这里为大家准备了丰厚的免费学习大礼包,带大家一起学习,给大家剖析Python兼职、就业行情前景的这些事儿。
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









