







 本文介绍了深度学习中标记数据的概念,监督学习的数据集划分(训练集、验证集、测试集)以及分类模型的评估指标(正确率、精确率、召回率和F1值)。同时强调了系统化学习的重要性,鼓励读者在IT行业中进行实践和交流。
本文介绍了深度学习中标记数据的概念,监督学习的数据集划分(训练集、验证集、测试集)以及分类模型的评估指标(正确率、精确率、召回率和F1值)。同时强调了系统化学习的重要性,鼓励读者在IT行业中进行实践和交流。
强化学习也是使用未标记的数据,但是可以通过某种方法知道你是离正确答案越来越近还是越来越远。
以上只是给出各个神经网络学习方法的基本概念,基本上初次接触深度学习基本不知道它讲的是啥,它们的定义都是从数据层面来看的,我们需要先理解什么叫做标记好的数据和未标记好的数据,脱离数据谈深度学习基本都是瞎扯,我们训练模型都是为了让计算机学习到一些东西,而数据就可以说是我们的一些先验知识。
什么是标记好的数据?
举个例子吧,比如我们有很多猫的图片和狗的图片,我们分别给这些图片打上标签(label),用来告诉计算机哪些是猫的图片,哪些是狗的图片,类似这些数据就是标记好的数据。而未标记好的数据则是没有被打上标签的。

图片引用自:莫烦PYTHON
监督学习有哪些数据集?
目前笔者接触深度学习并不多,都还处于监督学习的阶段当中,所以这里说的数据集也是基于监督学习来说的。
我们在进行有监督的神经网络学习当中,经常会谈到以下几个数据集:
-
训练集(train dataset)
-
验证集(validation dataset)
-
测试集(test dataset)
训练集
字面意思,就是用来训练模型的数据集。
验证集
作用是当通过训练集训练出多个模型之后,使用各个模型对验证集进行预测,并记录模型的准确率。
测试集
测试集是从原始数据划分出来用来预测训练好的模型,通常用来衡量模型的性能和分类能力。必须要注意,测试集是不允许出现在训练集当中的,不然就没有意义了。
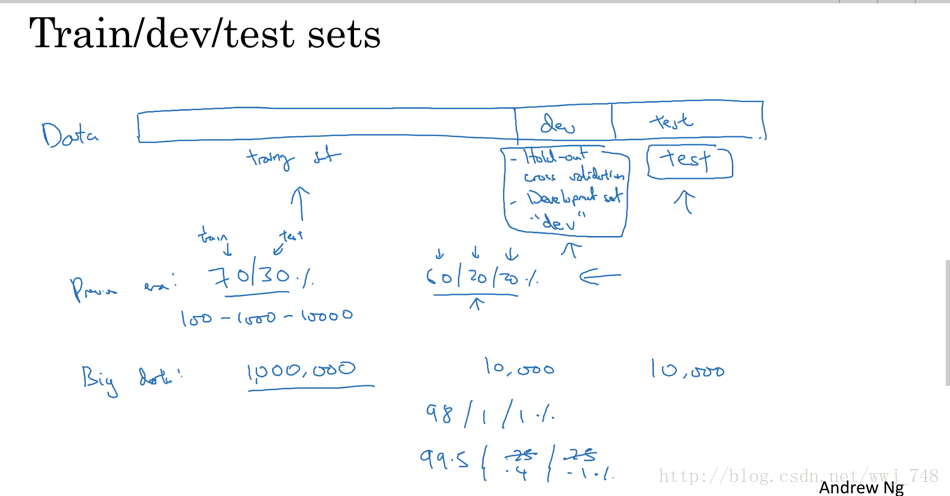
问题:三个数据集该怎么划分?
是的,这也是笔者在拿到原始数据在进行数据划分产生的疑惑,关于这三块数据集有什么经验值呢,其实是有的:
小数据集
-
训练集 60%
-
验证集 20%
-
测试集 20%
大数据集
比如100万数据,我们可以按照以下比例划分:
-
98/1/1(训练集/验证集/测试集)
-
99.5/0.4/0.1(同上)
具体可以参考吴恩达的深度学习课程。
分类模型有哪些评测指标?
当数据集有了,模型也训练出来了,那我们怎么去评测一个模型的性能和效果呢,这里以分类模型来谈下如何衡量模型的好坏,不同的模型的评价指标不一样,后续笔者学到的话也会分享给大家。
分类模型一般会有哪些指标呢?
-
正确率(Accuracy)
-
精确率(Precision)
-
召回率(Recall)
-
F1值(F1-Measure)
定义样本的计算变量:
TP(True Positive):正类被预测为正类样本数
FP(False Positive):负类被预测为正类样本数
TN(True Negative):负类被预测为负类样本数
FN(False Negative):正类被预测为负类样本数
你可能会比较懵,这里正样本指的是正类,比如我要识别一张猫的图片,猫的图片就是我们的正样本,而其他类型的图片就是我们的负样本,比如狗的图片就是负类我们不希望它被识别为猫的。
正确率
对于给定的测试集,分类器正确分类的样本数与总样本数之比。
计算公式:Acc = (TP + TN) / all
重要知识点
下面是有几位Android行业大佬对应上方技术点整理的一些进阶资料。

高级进阶篇——高级UI,自定义View(部分展示)
UI这块知识是现今使用者最多的。当年火爆一时的Android入门培训,学会这小块知识就能随便找到不错的工作了。不过很显然现在远远不够了,拒绝无休止的CV,亲自去项目实战,读源码,研究原理吧!

- 面试题部分合集

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 26万+
26万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









