







给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网络安全面试题
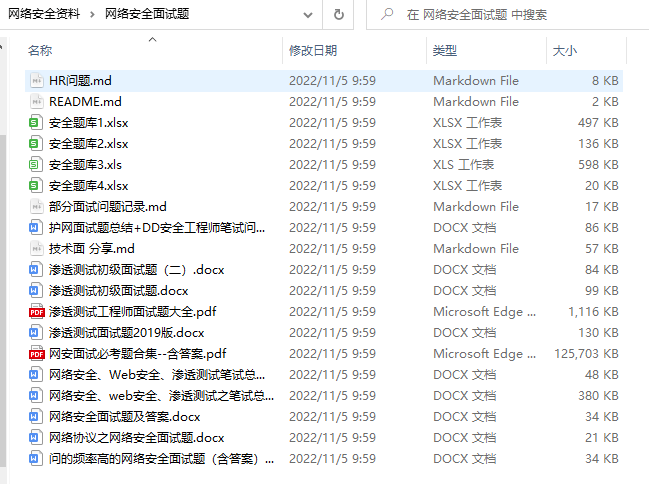
绿盟护网行动
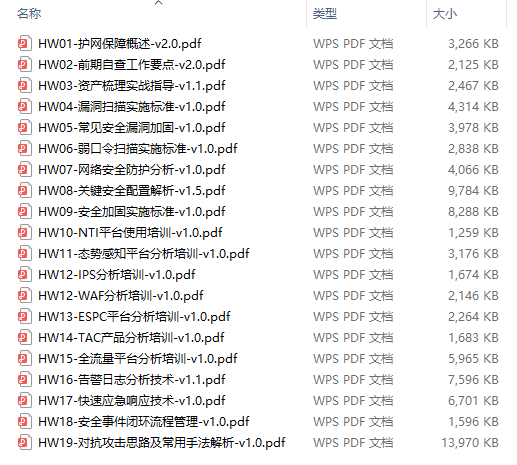
还有大家最喜欢的黑客技术
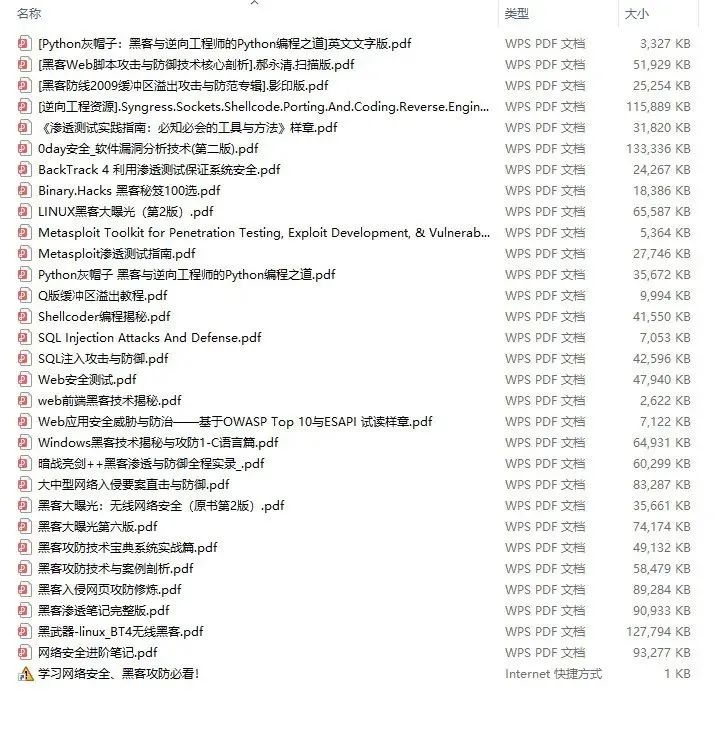
网络安全源码合集+工具包

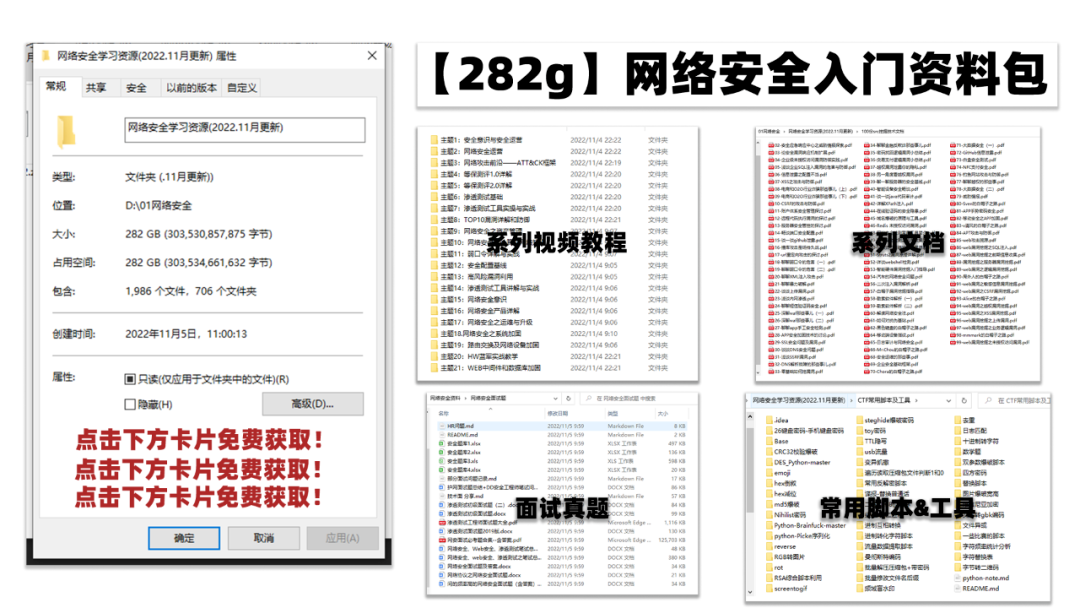
所有资料共282G,朋友们如果有需要全套《网络安全入门+黑客进阶学习资源包》,可以扫描下方二维码领取(如遇扫码问题,可以在评论区留言领取哦)~
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
下面具体来总结一下三者的区别
-
同步代码块:同步代码块的范围较小,只是锁定了某个对象,所以性能较高
-
普通同步方法:给整个方法上锁,性能较低
-
静态同步方法:相当于整个类的同步代码块,性能较低
ReentrantLock
除了synchronized这个关键字外,我们还能通过concurrent包下的Lock接口来实现这种效果,ReentrantLock是lock的一个实现类,可以在任何你想要的地方进行加锁,比synchronized关键字更加灵活,下面看一下使用方式
使用方式
//ReentrantLock同步
public void addReentrantLock() {
mReentrantLock.lock();//上锁
bugNumber++;
System.out.println(“normalSynchronized—>” + getBugNumber());
mReentrantLock.unlock();//解锁
}
运行测试
ReentrantLock—>1
ReentrantLock—>2
ReentrantLock—>3
ReentrantLock—>4
ReentrantLock—>5
ReentrantLock—>6
我们发现也是可以达到同步的目的,看一下ReentrantLock的继承关系

ReentrantLock实现了lock接口,而lock接口只是定义了一些方法,所以相当于说ReentrantLock自己实现了一套加锁机制,下面简单分析一下ReentrantLock的同步机制,在分析前,需要知道几个概念:
-
CLH:AbstractQueuedSynchronizer中“等待锁”的线程队列。在线程并发的过程中,没有获得锁的线程都会进入一个队列,CLH就是管理这些等待锁的队列。
-
CAS:比较并交换函数,它是原子操作函数,也就是说所有通过CAS操作的数据都是以原子方式进行的。
成员变量
private static final long serialVersionUID = 7373984872572414699L;
/** Synchronizer providing all implementation mechanics */
private final Sync sync;//同步器
成员变量除了序列化ID之外,只有一个Sync,那就看一看具体是什么

Sync有两个实现类,一个是FairSync,一个是NonfairSync,从名字可以大致推断出一个是公平锁,一个是非公平锁,
FairSync(公平锁)
lock方法:
final void lock() {
acquire(1);
}
ReentrantLock是独占锁,1表示的是锁的状态state。对于独占锁而言,如果所处于可获取状态,其状态为0,当锁初次被线程获取时状态变成1,acquire最终调用的是tryAcquire方法
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
// 当c==0表示锁没有被任何线程占用
(hasQueuedPredecessors),
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
//锁已经被线程占用
int nextc = c + acquires;
if (nextc < 0)
throw new Error(“Maximum lock count exceeded”);
setState(nextc);
return true;
}
return false;
}
tryAcquire主要是去尝试获取锁,获取成功则设置锁状态并返回true,否则返回false
NonfairSync(非公平锁)
非公平锁NonfairSync的lock()与公平锁的lock()在获取锁的流程上是一直的,但是由于它是非公平的,所以获取锁机制还是有点不同。通过前面我们了解到公平锁在获取锁时采用的是公平策略(CLH队列),而非公平锁则采用非公平策略它无视等待队列,直接尝试获取。
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
lock()通过compareAndSetState尝试设置锁的状态,若成功直接将锁的拥有者设置为当前线程(简单粗暴),否则调用acquire()尝试获取锁,对比一下,公平锁跟非公平锁的区别在于tryAcquire中
//NonfairSync
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
//FairSync
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
公平锁中要通过hasQueuedPredecessors()来判断该线程是否位于CLH队列头部,是则获取锁;而非公平锁则不管你在哪个位置都直接获取锁。
unlock
public void unlock() {
sync.release(1);//释放锁
}
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
对比分析
等待可中断
-
synchronized:线程A跟线程B同时竞争同一把锁,如果线程A获得锁之后不释放,那么线程B会一直等待下去,并不会释放。
-
ReentrantLock:可以在线程等待了很长时间之后进行中断,不需要一直等待。
锁的公平性
公平锁:是指多个线程在等待同一个锁时,必须按照申请的时间顺序来依次获得锁;非公平锁:在锁被释放时,任何一个等待锁的线程都有机会获得锁;
-
synchronized:是非公平锁
-
ReentrantLock:可以是非公平锁也可以是公平锁
绑定条件
-
synchronized中默认隐含条件。
-
ReentrantLock可以绑定多个条件
可见性
volatile
内存语义
由于多个线程方法同一个变量,导致了线程安全问题,主要原因是因为线程的工作副本的变量跟主内存的不一致,如果能够解决这个问题就可以保证线程同步,而Java提供了volatile关键字,可以帮助我们保证内存可见性,当我们声明了一个volatile关键字,实际上有两层含义;
-
禁止进行指令重排序。
-
一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
volatile是一种稍弱的同步机制,在访问volatile变量时不会执行加锁操作,也就不会执行线程阻塞,因此volatile变量是一种比synchronized关键字更轻量级的同步机制。
原理
在使用volatile关键字的时候,会多出一个lock前缀指令,lock前缀指令实际上相当于一个内存屏障实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
2)它会强制将对缓存的修改操作立即写入主存;
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。
使用场景
这里需要强调一点,volatile关键字并不一定能保证线程同步,如果非要采用volatile关键字来保证线程同步,则需要满足以下条件:
-
对变量的写操作不依赖于当前值
-
该变量没有包含在具有其他变量的不变式中
其实看了一些书跟博客,都是这么写的,按照我的理解实际上就是只有当volatile修饰的对象是原子性操作,才能够保证线程同步,为什么呢。
测试代码:
class Volatile {
volatile static int count = 0;
public static void main(String[] args) {
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
Volatile.add();
}
}).start();
}
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(“count—>” + ++count);
}
private static void add() {
count++;
}
}
运行结果
count—>1001
理论上是1000才对,但是输出的值是1001,为什么呢,这个其实在之前的JMM中已经分析过了,下面再贴一张图

跟之前一样,我们每次从主内存中获取到的count确实是最新的,但是由于对count的操作不是原子性操作,假如现在有两个线程,线程1跟线程2,如果线程1读取到了count值是5,然后read—>load进内存了,然后现在被线程2抢占了CPU,那么线程2就开始read—>load,并且完成了工作副本的赋值操作,并且将count 的值回写到主内存中,由于线程1已经进行了load操作,所以不会再去主内存中读取,会接着进行自己的操作,这样的话就出现了线程不安全,所以volatile必须是原子性操作才能保证线程安全。
基于以上考虑,volatile主要用来做一些标记位的处理:
volatile boolean flag = false;
//线程1
while(!flag){
doSomething();
}
//线程2
public void setFlag() {
flag = true;
}
当有多个线程进行访问的时候,只要有一个线程改变了flag的状态,那么这个状态会被刷新到主内存,就会对所有线程可见,那么就可以保证线程安全。
automatic
automatic是JDK1.5之后Java新增的concurrent包中的一个类,虽然volatile可以保证内存可见性,大部分操作都不是原子性操作,那么volatile的使用场景就比较单一,然后Java提供了automatic这个包,可以帮助我们来保证一些操作是原子性的。
使用方式
替换之前的volatile代码
public static AtomicInteger atomicInteger = new AtomicInteger(0);
private static void add() {
atomicInteger.getAndIncrement();
}
测试一下:
AtomicInteger: 1000
原理解析
AtomicInteger既保证了volatile保证不了的原子性,同时也实现了可见性,那么它是如何做到的呢?
成员变量
private static final long serialVersionUID = 6214790243416807050L;
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
private volatile int value;
运算方式
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
int compare_and_swap(int reg, int oldval, int newval) {
ATOMIC();
int old_reg_val = reg;
if (old_reg_val == oldval)
reg = newval;
END_ATOMIC();
return old_reg_val;
}
分析之前需要知道两个概念:
-
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。
-
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。
compare_and_swap这个才是核心方法,也就是上面提到的CAS,因为CAS是基于乐观锁的,也就是说当写入的时候,如果寄存器旧值已经不等于现值,说明有其他CPU在修改,那就继续尝试。所以这就保证了操作的原子性。
变量私有化
这种方式实际上指的就是ThreadLocal,翻译过来是线程本地变量,ThreadLocal会为每个使用该变量的线程提供独立的变量副本,但是这个副本并不是从主内存中进行读取的,而是自己创建的,每个副本相互之间独立,互不影响。相对于syncronized的以时间换空间,ThreadLocal刚好相反,可以减少线程并发的复杂度。
简单使用
class ThreadLocalDemo {
public static ThreadLocal local = new ThreadLocal<>();//声明静态的threadlocal变量
public static void main(String[] args) {
local.set(“Android”);
for (int i = 0; i < 5; i++) {
SetThread localThread = new SetThread();//创建5个线程
new Thread(localThread).start();
}
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(local.get());
}
static class SetThread implements Runnable {
@Override
public void run() {
local.set(Thread.currentThread().getName());
}
}
}
进行 测试
Android
虽然我用for循环创建了好几个线程,但是并没有改变ThreadLocal中的值,依然是我的大Android,这个就能够说明我赋的值是跟我的线程绑定的,每个线程有特定的值。
源码分析
成员变量
private final int threadLocalHashCode = nextHashCode();//当前线程的hash值
private static AtomicInteger nextHashCode =//下一个线程的hash值
new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;//hash增长因子
构造函数
public ThreadLocal() {
}
空实现。。。。
set方法
public void set(T value) {
Thread t = Thread.currentThread();//获取到当前线程
ThreadLocalMap map = getMap(t);//获取一个map
if (map != null)
//map不为空,直接进行赋值
map.set(this, value);
else
//map为空,创建一个Map
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
ThreadLocalMap
上面创建的Map实际上是一个ThreadLocalMap,也即是用来保存跟线程绑定的数据的,之间看过HashMap的源码,既然也叫Map,那么其实应该是差不多的
基本方法

成员变量
private static final int INITIAL_CAPACITY = 16;//初始容量,2的幂
private Entry[] table;//用来存放entry的数组
private int size = 0;//数组长度
private int threshold; // 阈值
//Entry继承了WeakReference,说明key弱引用,便于内存回收
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
构造方法
ThreadLocalMap(java.lang.ThreadLocal<?> firstKey, Object firstValue) {
// 初始化table数组
table = new Entry[INITIAL_CAPACITY];
// 通过hash值来计算存放的索引
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
// 创建entry节点
table[i] = new Entry(firstKey, firstValue);
// 数组长度由0到1
size = 1;
// 将阈值设置成为初始容量
setThreshold(INITIAL_CAPACITY);
}
还有一个构造方法是传一个Map,跟传key-value大同小异就不解释了
getEntry
private Entry getEntry(ThreadLocal<?> key) {
//通过key来计算数组下标
int i = key.threadLocalHashCode & (table.length - 1);
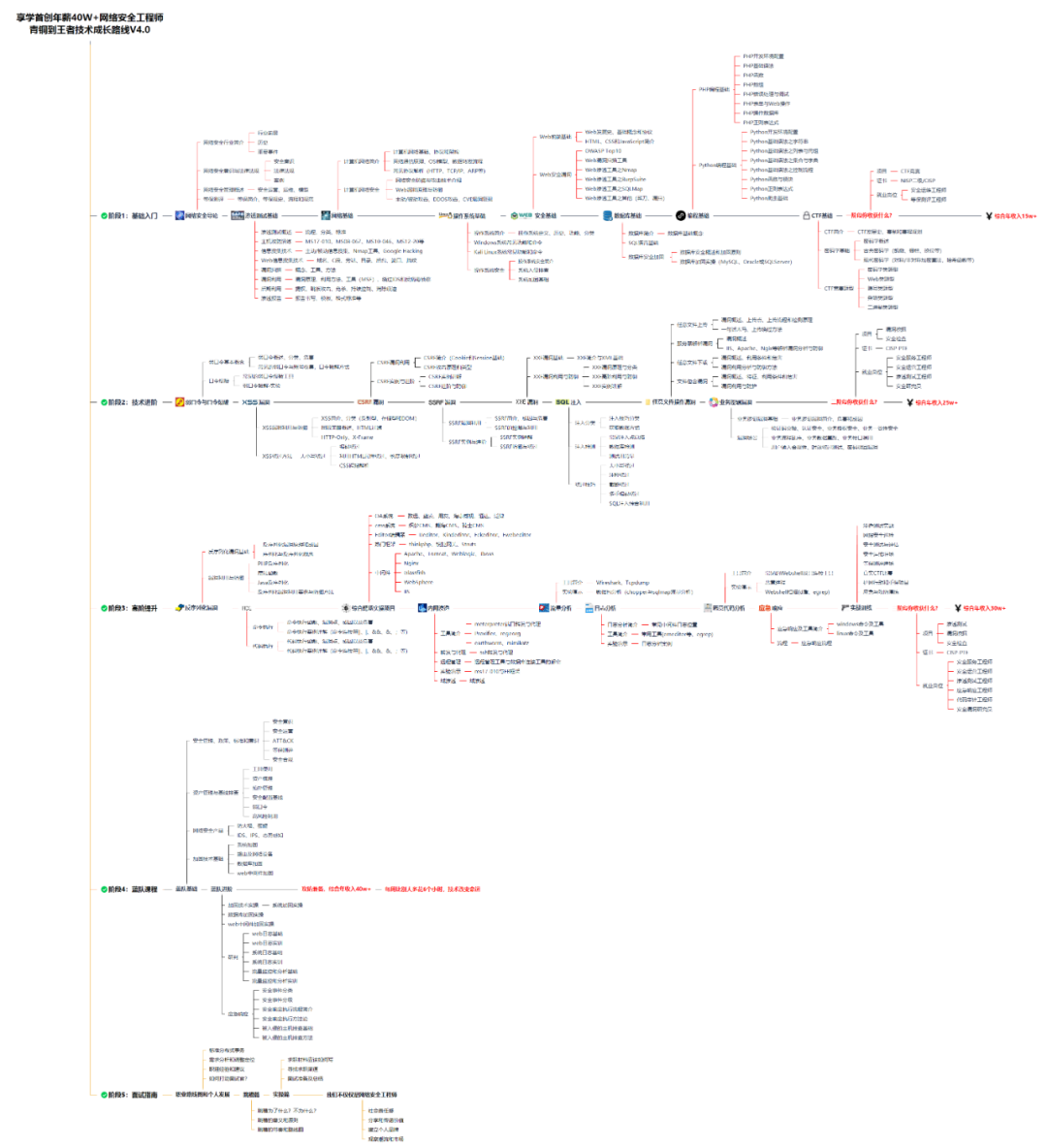
一、网安学习成长路线图
网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、网安视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
三、精品网安学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、网络安全源码合集+工具包
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、网络安全面试题
最后就是大家最关心的网络安全面试题板块
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









