







还有兄弟不知道网络安全面试可以提前刷题吗?费时一周整理的160+网络安全面试题,金九银十,做网络安全面试里的显眼包!
王岚嵚工程师面试题(附答案),只能帮兄弟们到这儿了!如果你能答对70%,找一个安全工作,问题不大。
对于有1-3年工作经验,想要跳槽的朋友来说,也是很好的温习资料!
【完整版领取方式在文末!!】
93道网络安全面试题
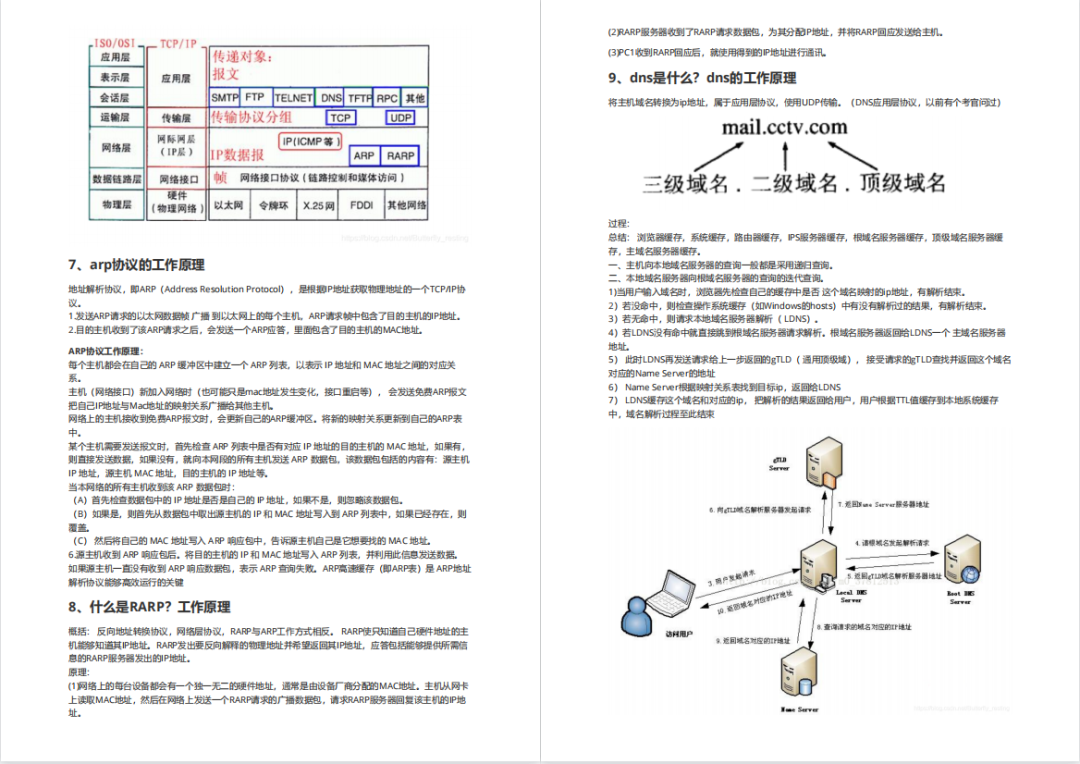


内容实在太多,不一一截图了
黑客学习资源推荐
最后给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
1️⃣零基础入门
① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
最新想法:
本学期选修了下大数据,发现其实本题的解法还涉及到数据库、大数据各个层次数据处理和分布式数据流blabla,而之前那几天美赛做的还停留在最基础的数据处理层(而且我现在觉得如果要做大的话不应该在这个层里面进行深度学习),前面的数据库处理并没实现,后面的数据分布式分发处理、前端数据可视化也没有做,emmm
所以建议选C题的同学,首先要真正会大数据这门课程(而不是只会Matlab、数学建模,这个大数据的题里面数学建模只在中间的数据处理层,其他还有很多层次要你做),而且最后你不是也要数据可视化吗,还要你写前端页面。
所以:如果你想以后做大数据工程师(jd上有相关技术栈),非常建议你选C题,做之前系统学大数据课程(分布式等等),然后再学点机器学习基础,数据库,然后再学点web前端数据可视化;如果你非科班且只想写论文、做点数学模型,负责任的建议去隔壁A、B题。
大四有空做个工程化模型(从底到高全部)卷土重来
好消息:相关论文word版本已经上传至百度云,请三连后自取哈!
链接: https://pan.baidu.com/s/1k5V7D_PQ_tmb6kAmg-NhVg 密码: kj6u
【MCM】2020C题(总结和论文分享)
前言:QAQ ,数学建模美赛竟然在两个多月的疫情中结束了,美赛的这段时间效率属实高,仿佛是这两个月没有学习一下子迸发出的潜力一样。然后通过美赛也学了点知识。为了防止以后忘记这次美赛的东西,或者误删文件,现在来做个总结吧!
文章目录
- 最新想法:
- 所以建议选C题的同学,首先要真正会大数据这门课程(而不是只会Matlab、数学建模,这个大数据的题里面数学建模只在中间的数据处理层,其他还有很多层次要你做),而且最后你不是也要数据可视化吗,还要你写前端页面。
- 所以:如果你想以后做大数据工程师(jd上有相关技术栈),非常建议你选C题,做之前系统学大数据课程(分布式等等),然后再学点机器学习基础,数据库,然后再学点web前端数据可视化;如果你非科班且只想写论文、做点数学模型,负责任的建议去隔壁A、B题。
- 大四有空做个工程化模型(从底到高全部)卷土重来
- 好消息:相关论文word版本已经上传至百度云,请三连后自取哈!
- 【MCM】2020C题(总结和论文分享)
C题题目:数据财富
在亚马逊创建的网上商城中,亚马逊为客户提供了对购买进行评分和评价的机会。使购
买者可以使用 1(低评级,低满意度)到 5(高评级,高满意度)的等级(称为“星级”)来
表示他们对产品的满意度。此外,客户可以提交基于文本的消息(称为“评论”),以表达有
关产品的更多意见和信息。其他客户可以在这些评论中提交有帮助或无帮助的评分(称为“帮
助评分”),以协助产品购买决策。生产厂商使用这些数据来深入了解其参与的市场,参与
的时点以及潜在成功的产品设计选择。
阳光公司(Sunshine Company)计划在网上商城中推出和销售三种新产品:微波炉,婴
儿奶嘴和吹风机。 他们已聘请您的团队作为顾问,从客户提供的历史评级和评论中识别出
关键的模式、关系、模型和参数,以便:1)描述其在线销售策略; 2)识别潜在的重要设
计功能,以增强产品的效用。阳光公司过去也使用过数据为销售策略提供信息,但他们以前
从未使用过这种特殊的组合和数据类型。阳光公司特别感兴趣的是这些数据中的基于时间的
变化规律,以及它们是否以有助于该公司制造成功的产品。
为了帮助您,阳光公司的数据中心为您提供了该项目的三个数据文件:吹风机.tsv,微
波炉.tsv 和婴儿奶嘴.tsv。 这些数据代表在指示的时间段内在亚马逊市场上出售的微波炉,
婴儿奶嘴和吹风机的客户提供的评分和评论。 还提供了数据标签定义的词汇表。提供的三
个数据文件是您应用于此问题的唯一数据。
要求:
1.分析提供的三个产品数据集,使用数学论证来识别、描述和支持:①有意义的定量和/或定
性模式,②阳光公司的星级、评论、帮助评分之间的内部关系和相互关系③模型及其参数。
这些数据将在有助于他们的三项新产品在网上商城中取得成功。
2.使用您的分析来解决阳光公司市场总监的以下特定问题和要求:
a.一旦三种产品在网上商城里出售后,公司通过使用模型,就可以根据评级和评论数据
获取一些信息。
b.在每个数据集中识别并讨论基于时间的度量和模式,这些度量和模式可能表明产品在
在线市场中的声誉在上升或下降。
c.根据文本和评级,确定潜在的最成功或最失败的产品。
d.特定星级会引起更多评论吗? 例如,在看到一系列低星级评级之后,客户是否更有
可能撰写某种类型的评论?
e.诸如**“热情”,“失望”**之类的基于文本的评论的特定质量描述符是否与评分水平紧密相
关?
3.写一到两页的信给阳光公司市场总监,总结您团队的分析和结果。一定要陈述具体理由。
您提交的内容应包括:
1.一页摘要表
2.目录
3.一到两页的给阳光公司市场总监的信
4.您的解决方案(不超过 20 页,包含摘要页、目录和两页信函的话不超过 24 页)
词汇表
科研交流学员专属第二个版本的翻译,请勿外传,谢谢合作!
帮助评分:在决定是否购买某产品时,某条关于该产品的顾客评论的价值。
奶嘴:一种橡胶或塑料的舒缓装置,通常为乳头状,提供给婴儿吸吮或咬咬。
评论:对产品的书面文字评估。
星级:在系统中给出的分数,该分数是人们对产品的评分。(1-5 颗星)
附件:问题数据集
Problem_C_Data.zip
所提供的三个数据集包含产品用户评分和通过 Amazon Simple Storage Service(Amazon
S3)从 Amazon 客户评论数据集提取的评论。
hair_dryer.tsv
microwave.tsv
pacifier.tsv
数据集定义:每行代表划分为以下几列的数据。
●marketplace(字符串):撰写评论的市场的 2 个字母的国家代码。
●customer_id(字符串):随机标识符,可用于汇总单个作者撰写的评论。
●review_id(字符串):评论的唯一 ID。
●product_id(字符串):审核所属的唯一产品 ID。
●product_parent(字符串):随机标识符,可用于汇总同一产品的评论。
●product_title(字符串):产品的标题。
●product_category(字符串):产品的主要消费者类别。
●star_rating(整型):评论的 1-5 星评级。
●helpful_votes(整型):有用的投票数。
●total_votes(整型):评论收到的总票数。
●vine(字符串):基于客户在撰写准确而有见地的评论方面所获得的信任,亚马逊邀请客
户成为 Amazon Vine Voices。亚马逊为 Amazon Vine 成员提供了供应商免费提供的试用产品。
Amazon 不会影响 Amazon Vine 成员的意见,也不会修改或编辑评论。
●verify_purchase(字符串):“ Y”表示亚马逊已验证撰写评论的人在亚马逊上购买了该产
品,并且没有以大幅折扣收到该产品。
●review_headline(字符串):评论的标题。
●review_body(字符串):评论文本。
●review_date(长整型):撰写评论的日期。
直接上论文(主要已经很详细了,可能会根据内容进行后期改善)
标题:基于数据挖掘和语义情感分析的商品指标评价研究
摘要
- 本文针对阳光公司的产品数据问题进行了研究,建立了基于TOPSIS的多指标评价模型,通过使用Python实现的机器学习基于自然语言处理(NLP)的文本情感分析,从给定数据集中获得了每条评论的文本情感作为TOPSIS算法的评价指标之一,经过基于大数据的程序批量运算后,得到了评价商品优劣的综合指数,这些指数作为验证集与其他影响因素协同验证了算法模型的可行性,以以及寻找出与其他影响因素的规律,以此推广应用到公司产品数据分析的问题上。
- 针对问题一,概括为建立基于各项指标的商品评价模型。其主要过程是:首先将初始数据进行预处理;然后列举出商品评价的各项指标:star raking,NLP for comment,purchase number,proportion of useful comments。通过TOPSIS算法对各项指标进行分析,得出评价能够评判每个商品优劣的指数,列举出TOP10的商品,并分析出了各项指标对于商品优劣的影响程度。
- 针对问题二的A题,概括为只从rating star和comment两项指标来进行商品评价的问题。首先基于问题一的数据预处理和几项指标的综合分析,得到了商品的综合优劣分数。缩小指标范围,通过只对rating star和comment两项指标的TOPSIS评价算法的分析,得到能够评价每个商品优劣的指数,列举出TOP10的商品。
- 针对问题二的B,C,D题,概括为寻找出商品的评价指数与时间的关系以及预测两者之间的未来关系的问题。首先基于问题一的综合优劣分数和时间序列进行抽样分析,画出能够直观反映两者关系的时间序列图,分析出商品的评价指数的高峰期和低谷期,从中的数据找出影响高峰期和低谷期的主要因素和指标。然后通过ARMA模型算法对未来一段时期的商品评价指数进行预测。
- 针对问题二的E题,基于问题一的几项指标的综合分析,以及综合分析后产生的数据进行指标的相关性分析,使用SPSS软件模拟了各种指标对于TOPSIS评价模型的影响因素。不仅分析了文本和评级的影响因素,还分析了其他指标对于评价模型的影响因素。
- 关键字:TOPSIS,数据挖掘,NLP,LSTM,Python,ARMA。
1引言
1.1背景
在亚马逊在线市场上,客户可以对购买的商品进行评分和评估。这些评分和评估表示客户对产品的满意度为1-5;评论消费者的意见,以及有关购买产品的更多信息。帮助级别是其他级别用户根据评论提交帮助或非帮助。帮助级别对其他用户有帮助做出决定。公司使用星级,评论和帮助级别来了解市场他们参与的实践,他们参与的实践以及产品设计的潜在成功功能选择。Sunshine现在计划推出和销售微波炉,婴儿奶嘴和市场上的吹风机。我们需要帮助阳光公司制定在线销售策略并确定潜在的重要设计特征。
1.2重述问题
•根据星级,评分,评论和帮助评分这三个变量,检查变量之间以及变量内部的定性和定量关系,以帮助阳光公司进行初步的市场研究。
•根据第一个问题,建立一个基于评分和评论的模型,以估算产品质量。
•根据问题a,建立基于时间的模型并分析时间的影响各种变量的因素•根据文本和评分指标预测产品是否成功。
•阳光公司想知道某个星级是否会触发特定类型的评论,例如较低的评论是否会触发较大的评论差评数量•阳光公司想知道特定的情感表达词汇与评级有关,以及特定的星级是否会触发发布包含特定情感表达词的评论。
•写信给市场总监,分析其具体含义,原因和各种模型获得的结果的建议。
2.模型假设:略。
3第一个问题
3.1第一个问题的分析
分析产品数据集,并定量分析几个指标,定性地。分析数据集需要先对数据集进行预处理;其次,数据集中的审查是非常重要的指标,因此在进行定量分析和对总体指标进行定性分析,需要以数学方式衡量审查。将自然语言处理变成注释。
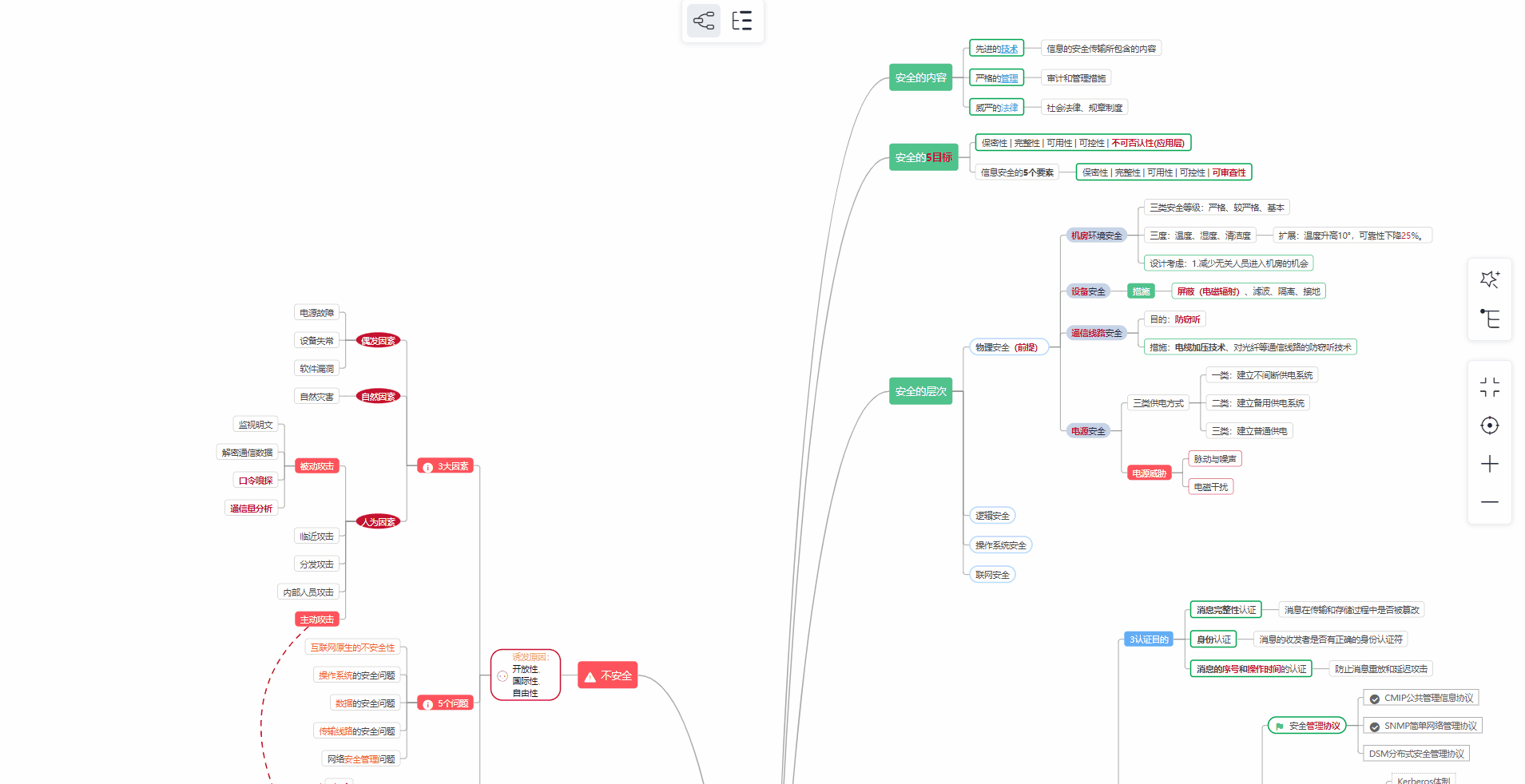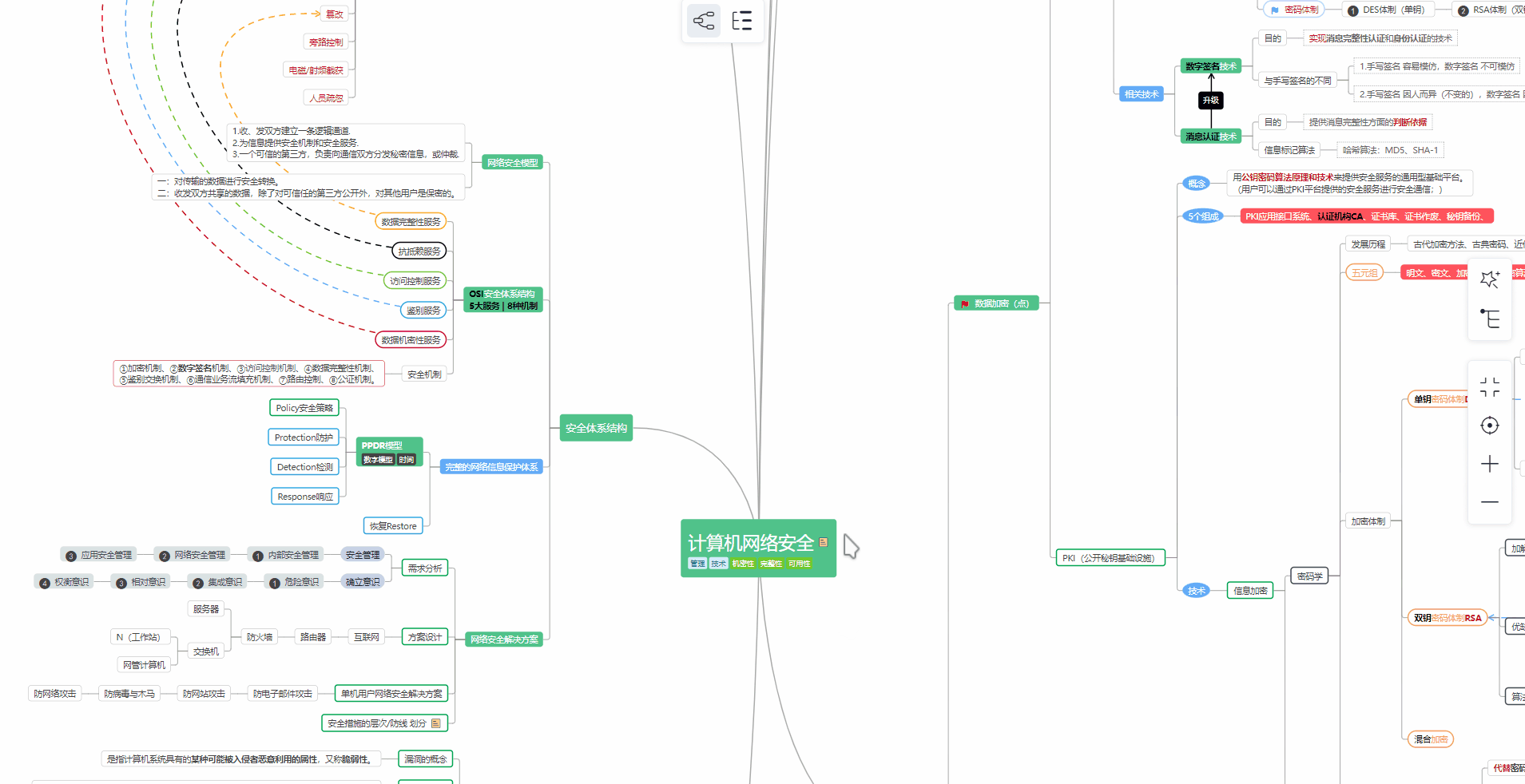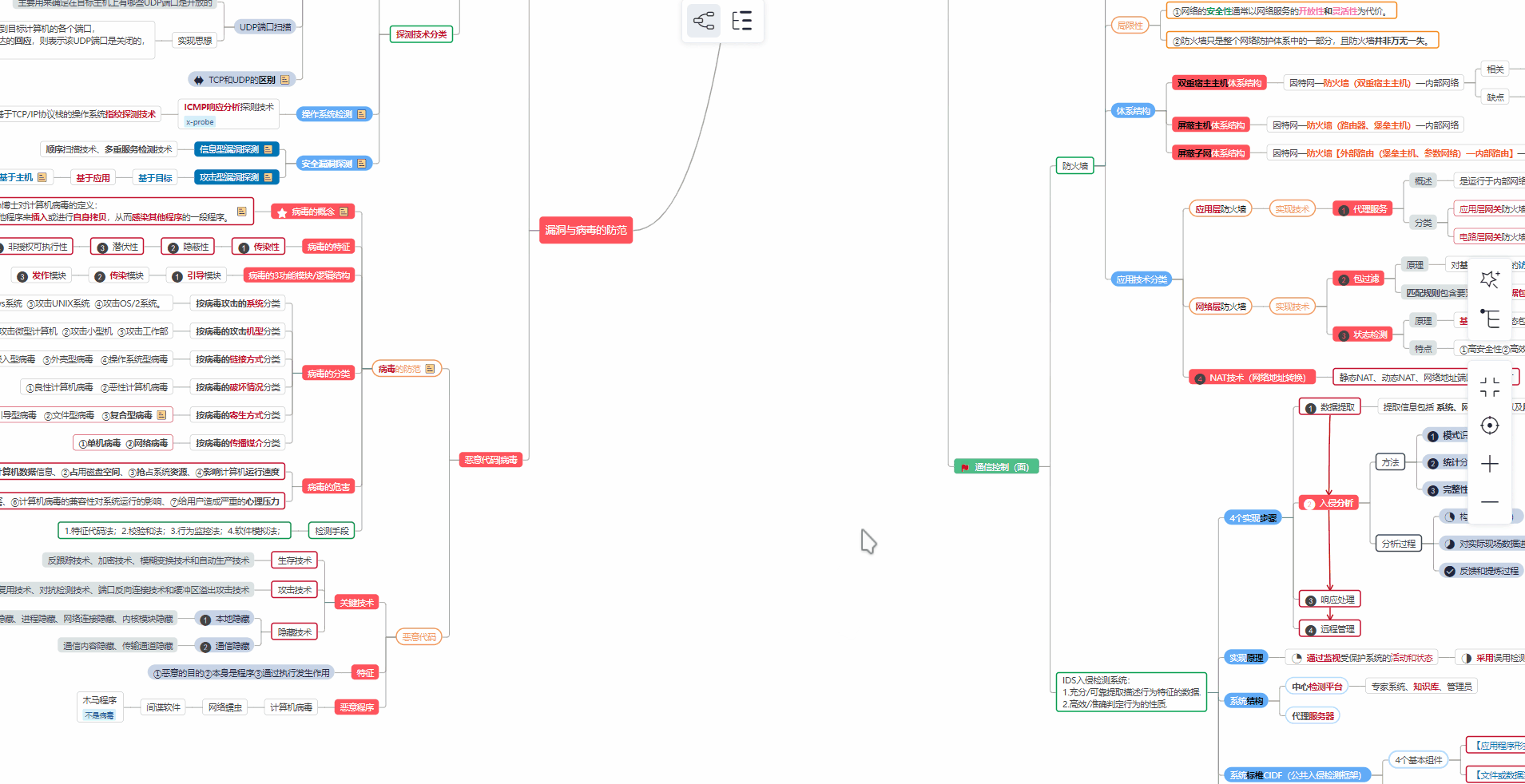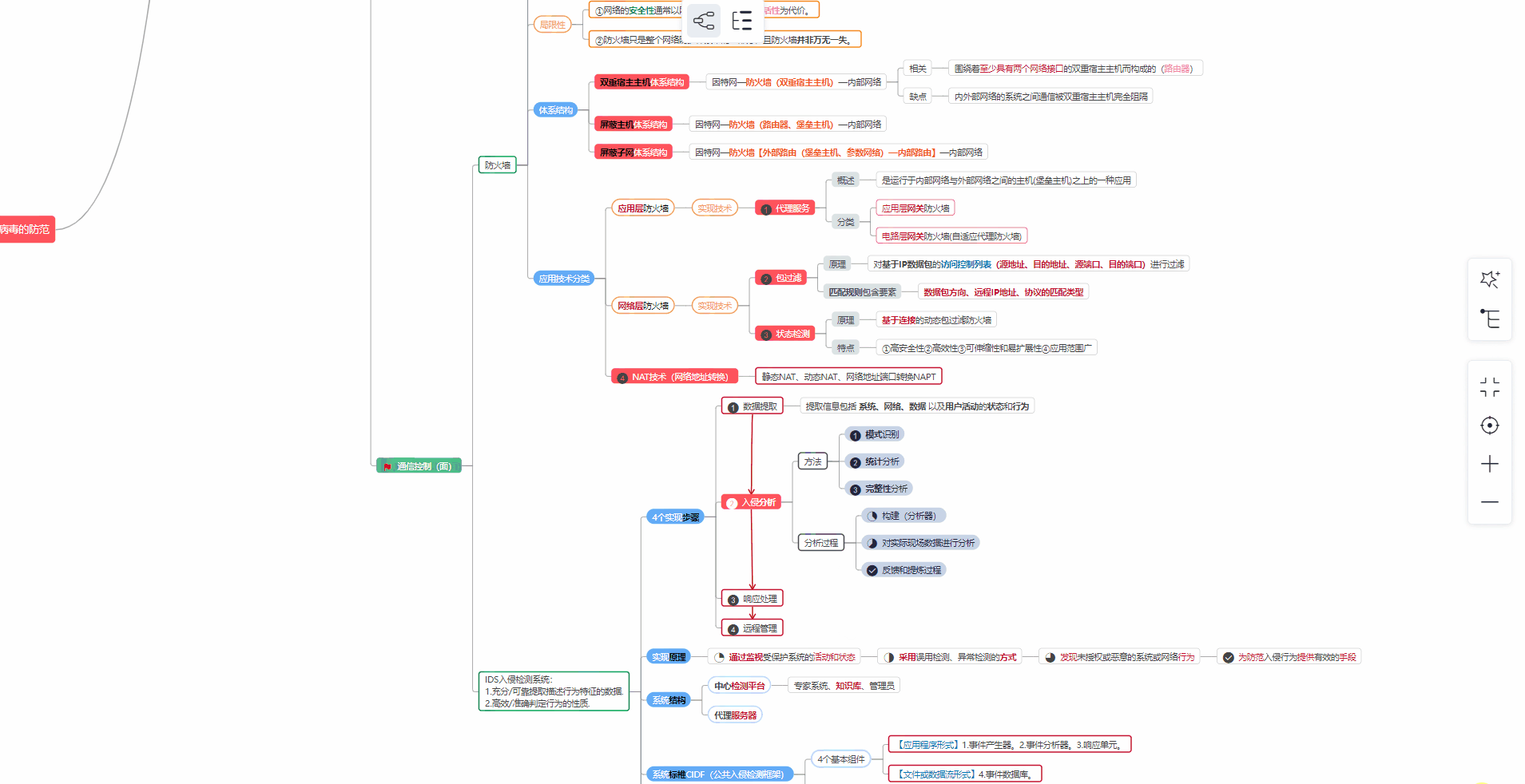
这个问题找到了两种用于情感分析的自然语言处理方法。第一个是基于textblob的语义情感分析,第二个是情感分析基于LSTM机器学习。通过这些分析注释的语义之后通过两种方法,获得了两个可以衡量评论的语义情感的索引:基于textblob nlp分析的情绪和基于LSTM机器学习nlp的情绪分析。然后,选择星级,评论,帮助等级和两个观点作为变量执行topsis算法的计算,首先执行无量纲处理,然后然后赋予每个变量权重以计算最终答案。3.2用于nlp识别的Textblob阳光给出的数据有很多不准确之处。例如,有些人尚未购买产品已评估产品。这将导致系统错误结果。因此,必须先对数据进行预处理,以删除无效和不合理的数据数据。首先,我们将NLP数据添加到表中的情感文本中的三列中其次,将正利率划分为一列并将其添加到表格中。标题,星级,nlp,帮助/总计。然后执行编程处理。我们删除数据拥有五星级正面评价,但有两个负面NLP指标和一星级负面评价但是两个NLP都正面评价。此后,收集购买次数Y,以形成评估指标:星,斑点,rnn,h / t和转换购买。星,斑点,rnn,h / t之后平均后,用Y输入算法。算法结果代表判断的分数产品。该算法的结果与星号,斑点,rnn,h / t和转换购买形成表格。为了使数据更客观,我们添加了三个新指标:•Blob.sentiment.polarity:极性判断零到一之间的好标准或介于零和一之间的不良标准。•Blob.sentiment.subjectivity:表示主观性,主观性在[0.0,0.1],其中0.0是非常客观的,而0.1是非常主观的。•Rnn-lstm-predict:表示预测。零为负,一个为正。得到预处理数据后,注释的主题为文本变量。为更好的数据分析,我们选择Python中的textblob库对文本进行情感分析数据。在我们获得由textblob处理的数据之后,为了确保结果,我们使用LSTM来纠正textblob的错误,并将textblob获得的值添加到通过LSTM获得的平均值。然后,我们使用NLP研究审稿人对相关产品并将其量化为0和1,其中0为负,而1为正。
3.2.1选择textblob库的原因textblob库源自Naive Bayes算法。
贝叶斯分类算法是一类分类算法。分类算法的内容需要给定的功能。让我们获取类别。这是解决所有分类问题的关键。指定功能以获取所需类别,这触及了每个分类的核心思想功能算法。朴素贝叶斯算法是这一类别中最简单的算法。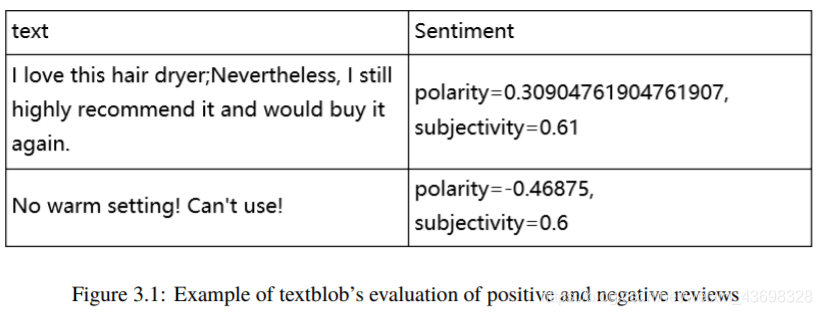
图3.1:textblob评价正面和负面评论的示例
我们已经统计上暴露于贝叶斯定理:
P(B i | A)=P(A | B i)P(B i)Σ ñj = 1P(B j)P(A | B j)(3.1)
朴素贝叶斯算法基于贝叶斯定理,并假设特征包含位置彼此独立。
首先,通过给定的训练集,特征词独立性被假定为前提。结合概率分布,然后根据在学习的模型中,输入X以找到使后验概率最大的输出Y。
设置样本数据集D = d 1 ,d 2 ,...,d n与样本对应的特征属性集data是X = x 1 ,x 2 ,...,x d,类变量是Y = y 1 ,y 2 ,...,y m,即D可除分为y m个类别。x 1 ,x 2 ,...,x d独立且随机,Y的先验概率为P 现有 = P(Ý),和的后验概率ÿ是P 交 = P(Y | X).Available从幼稚贝叶斯算法,后验概率可以从先验概率计算出的P 之前,所述证据P(X)和类别条件概率P(X | Y)。
公式如下:P(Y | X)=P(Y)P(X | Y)P(X)(3.2)
朴素贝叶斯基于每个功能的独立性。给定类别y,上述公式可以进一步表示为以下公式:
P(X | Y = y)=d∏我 = 1P(x i | Y = y)(3.3)
从以上两个公式可以得出后验概率为
P post = P(Y | X)=P(Y)∏ d我 = 1P(x i | Y = y)P(X)(3.4)
由于P(X)的大小是固定的,因此只能比较上述公式的分子比较后验概率时。因此您可以获得属于类别的样本数据y 我朴素贝叶斯计算公式:
P(ÿ 我 | X 1 ,X 2 ,...,X d)=P(y i)∏ dj = 1P(x i | y i)∏ dj = 1P(x j)(3.5)
3.2.2 Textblob如何工作
Textblob是基于朴素贝叶斯算法的文本分类器。最大似然概率文本中特定单词的能力由以下公式给出:P(x i | c)=c类文档中的x i计数C类文件中的单词总数(3.6)
在训练期间,特定单词的频率计数存储在哈希表中。如果分类器遇到一个没有出现在训练集中的单词,这种可能性word将变为0,无法进行比较,但是Laplace可以解决此问题平滑P(x i | c j)=数(x i)+ k(k + 1)*(c j类中的单词数)(3.7)

通常,将K选为1,以便新单词在任何类别中都具有相同的概率。否定词中还有一种特殊的词。机器没有弹性思维。有时负面词表达正面的意思,因此负面的处理单词是训练分类器的主要任务。由于我们使用每个单词作为特征,因此“不好”一词中的“好”一词将有助于形成积极的情绪,而不是消极的情感作为不存在的存在不被考虑在内。为了解决这个问题,在分类器中设计了一种简单的算法。这个算法通过检查否定词的数量来确定它是肯定的还是否定的。如果否定词是奇数,表示否定含义,否定词是偶数。一种双重否定是肯定的。否定词的处理提高了词的准确性分类器。通常,形容词会被副词修饰,例如“非常”,“十”等。副词会增加文件的正值或负值,以便更准确地识别文本通过分类器,它需要大量的文本训练。
3.3用于nlp识别的机器学习
由于textblob库识别的准确性不是很准确,因此我们使用机器学习在自然语言处理中进行情感分析。
3.3.1机器学习步骤
首先,我们也从亚马逊获得了50,000条评论的数据集。正面和负面该数据集的评论已被标记。作为我们的机器学习培训集。这个过程是大概是这样的:形成训练集中所有单词的词汇表。例如,我们现在有一个“非常好”的评论,然后该评论被标记为1(1是一个正数,0是一个负数),因此假设此句子的每个单词,他的标签向量为[1]在此词汇表中排名2,555,666,8988,则相对词汇表的值向量这句话是[555,666,8988]。因为我们的数据集有50,000条评论,也就是说我们对于50,000个句子的相对字典,具有50,000个标签向量和词法值向量。因此,我们将这两个值发送给lstm进行机器学习并训练了最终模型。
下边是该模型的相关准确性和召回率

图3.2:相对精度和召回机器模型
3.3.2关于LSTM的一些知识
LSTM很详细的解释
e-init和init对象设置了LSTM权重和偏差的计算方式初始化。该演示程序创建一个Adam(“自适应矩估计”)优化器宾语。Adam是许多类型的深度神经网络的非常好的通用优化器。替代方案包括RMSprop,Adagrad和Adadelta。尽管可以输入整数-编码的句子直接传送到LSTM网络,通过转换每个句子可获得更好的结果将整数ID转换为实数值向量。例如,单词“ the”的索引值为4,但是会被转换为矢量(0.1234,0.5678,… 0.3572)。这称为单词嵌入。想法是构造向量,以便类似的词(例如“ man”和“ male”)具有向量在数字上接近。向量的长度必须通过反复试验确定。的演示使用32号大小,但对于大多数问题,矢量大小通常为100到500。为LSTM网络创建词嵌入的主要方法有三种。一种方法是使用诸如Word2Vec之类的外部工具来创建嵌入。第二种方法是使用一组预先构建的嵌入,例如GloVe(“用于词表示的全局向量”),使用Wikipedia的文字构建而成。该演示程序使用第三种方法,就是要动态创建嵌入。这些嵌入将特定于词汇表问题场景。指定Embedding()层后,演示程序将设置一个LSTM()层。LSTM是非常复杂的软件模块。你可以得到一个大概的主意通过查看图4.3中的图表,了解LSTM的工作原理。
图3.3:简化的LSTM单元
x(t)对象是在时间t的输入,它是单词嵌入。输出为h(t)。不像常规神经网络,LSTM具有状态,这使它们能够处理句子,下一个单词取决于前一个单词。在图中,c(t)是时间t的单元状态。注意输出h(t)取决于当前输入x(t)以及先前的输出h(t-1)和单元状态c(t)。出色!
LSTM网络具有最终的Dense()层,该层对LSTM()层的输出进行处理降低到0.0到1.0之间的单个数值。小于0.5的输出值映射到分类0表示否定,输出大于0.5表示肯定(1)审查。在您的情绪分析具有多种价值的情况下,您可以使用一键式负数=(1、0、0),中性数=(0、1、0),正数=(0、0、1)等编码。因此我们可以使用经过训练的模型进行预测:预测的结果如下(0表示差评,1表示肯定)

3.4拓扑评价模型Topsis方法
基于有限数量的评估对象与理想的目标。这是对现有对象的相对较好的评估。那里有两个理想目标,一个是积极理想目标或最佳目标,一个是消极理想目标或最坏的目标。最佳评估对象应最接近最佳目标,并且最差的目标。Topsis方法是用于理想目标相似性的顺序优化技术。这是一个非常多目标决策分析的有效方法。它使用标准化的数据标准化矩阵以找到最佳和最差的目标(以理想和反理想的解决方案代表,多个目标之间),并计算每个评估目标与理想和反理想的解决方案然后,每个目标与理想解决方案的接近度为得出理想解的紧密程度,以此作为评估的依据目标的好坏。接近度的值在0到1之间。值越接近接近1,相应的评估目标越接近最佳水平;否则,值越接近0,评估目标越接近最差水平。我们将数据分析后的五个指标传递给topsis模型,这五个指标是:星级,情绪,lstm情绪,帮助/总票数,购买数量。这五个指标将起作用作为我们判断品牌优劣的标准。指示符(因为(0 1)表示评级很好,而(-1 0)表示评级不好)。的其他是非常大的指标。例如,对于2个包装的奶嘴之一,natursuttenbpa-免费天然橡胶,圆形乳头品牌。相关数据如图3.4所示:这只是品牌的topsis计算结果。将所有数据放入topsis模型中,我们可以获取所有品牌的分数。相关图表是3.5。
图3.4:
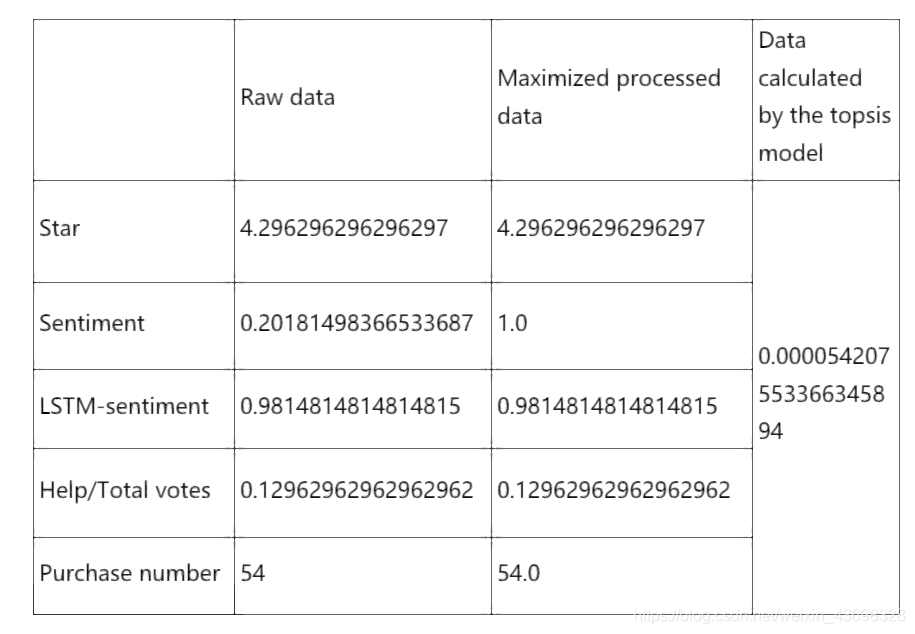
图3.5:
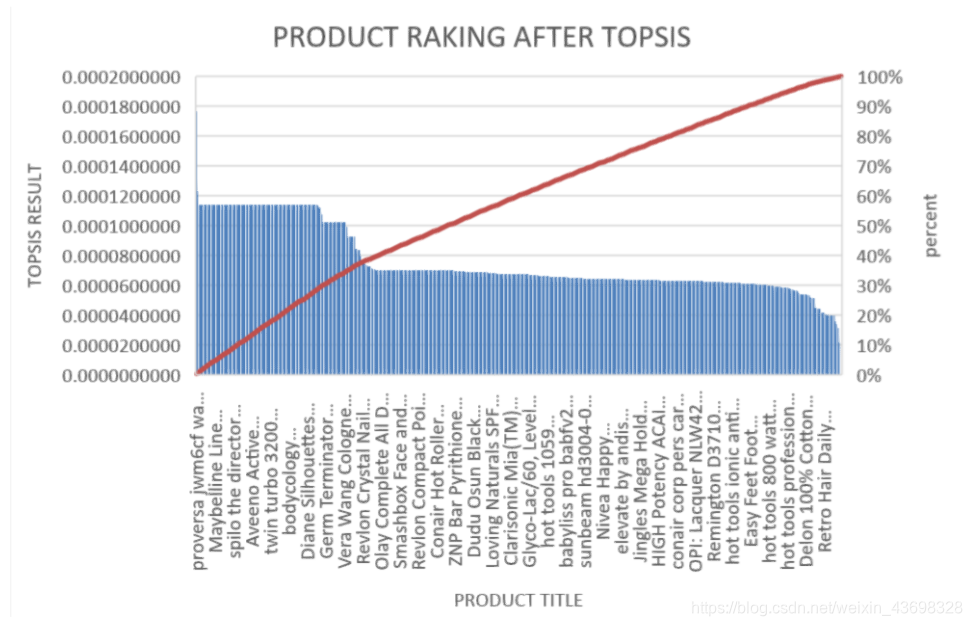
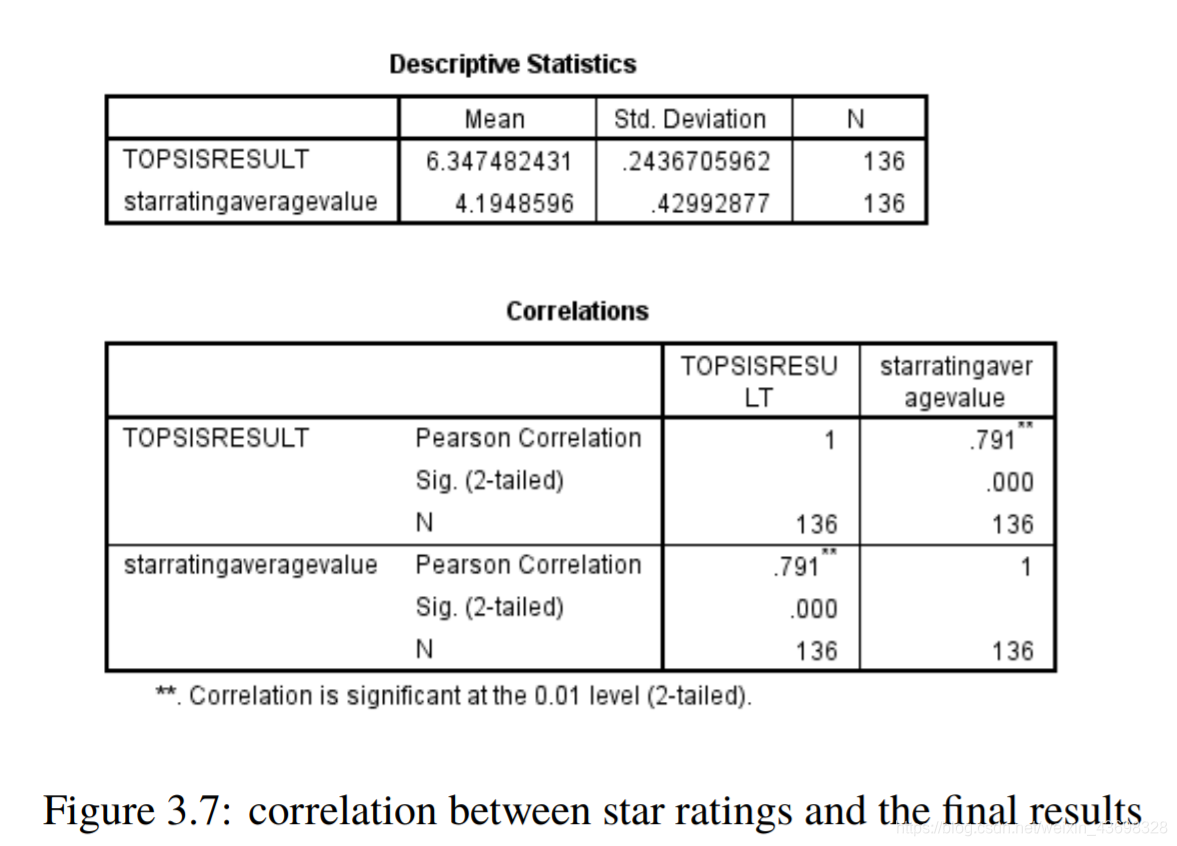
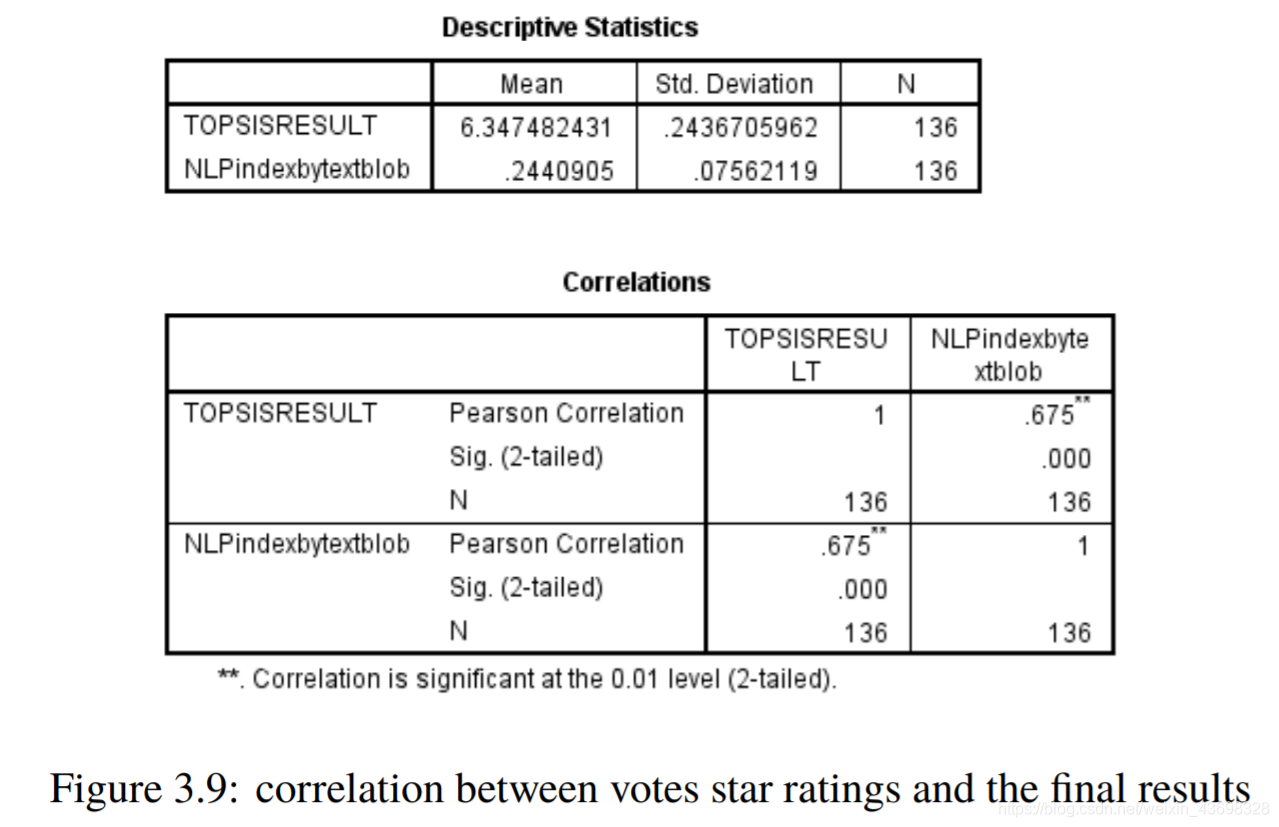
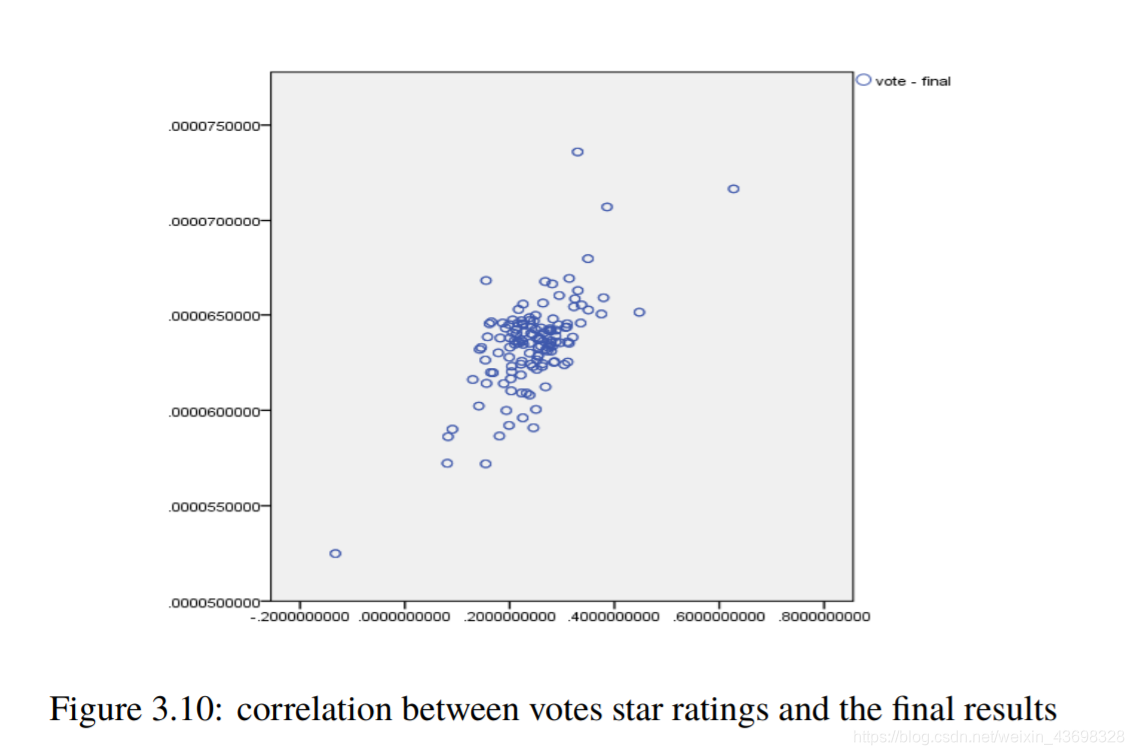
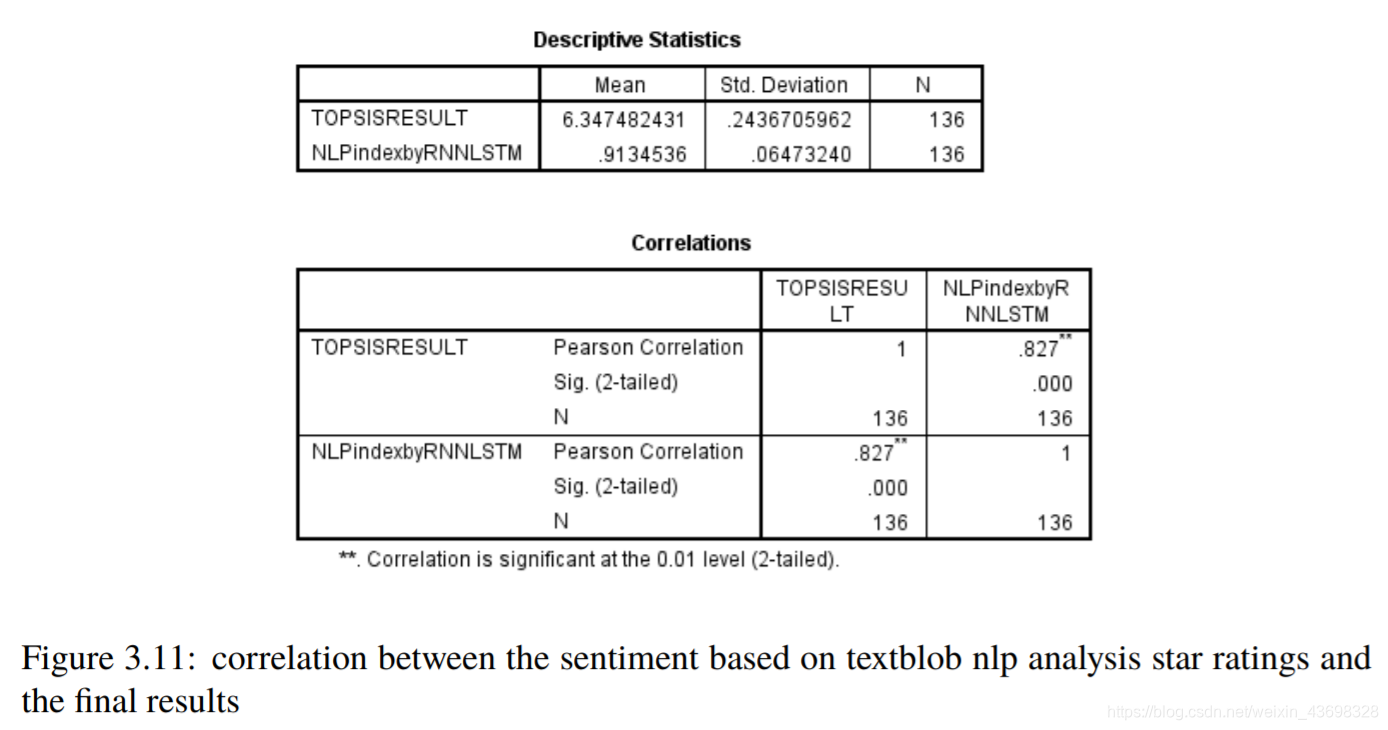
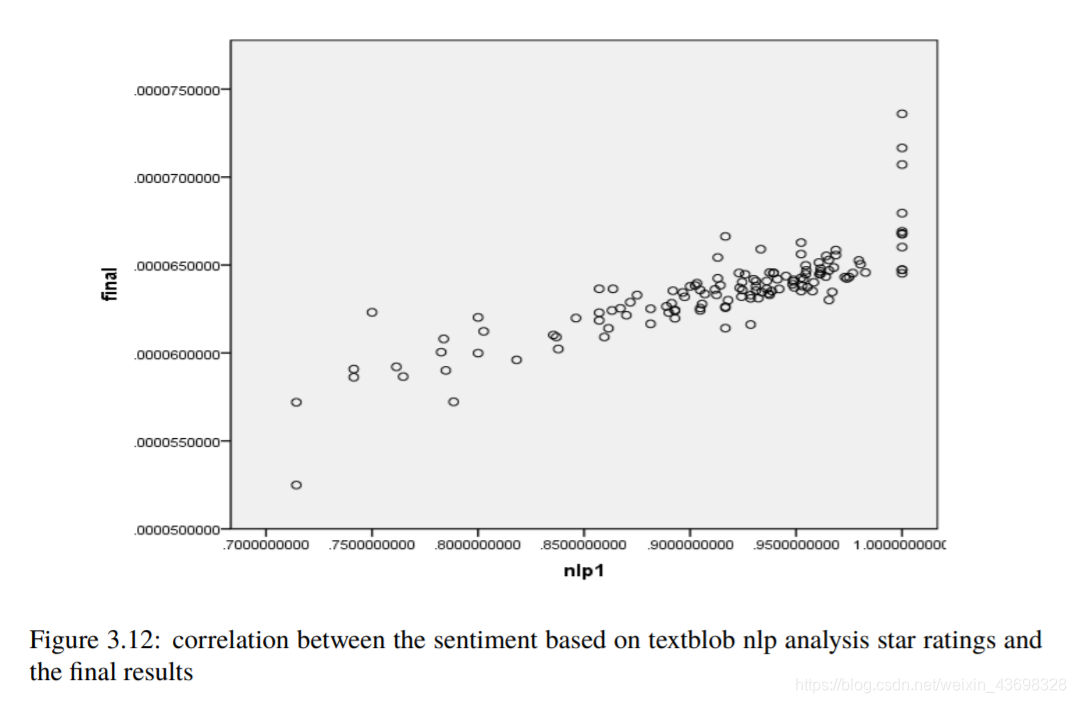
所有品牌吹风机的Topsis得分结果3.5相关分析通过topsis获得品牌的计算结果后,以检验结果的相关性,我们使用SPSS对结果进行相关性分析。首先我们检查星级与最终结果之间是否存在相关性。结果是如图3.6和图3.7所示。可以看出,假设检验结果为0.000,相关水平为0.791,相关性很大。考虑投票与最终结果之间的相关性,以及结果如图3.8和3.9所示。可以看出,假设检验结果为0.000,相关水平为0.675,并且相关性很大。然后考虑基于textblob nlp分析的情感和与最终结果的相关性。结果如图3.10和3.11所示。可以看出,假设检验结果为0.000,相关水平为0.827,
图3.6:吹风机品牌的topsisi得分前十名结果
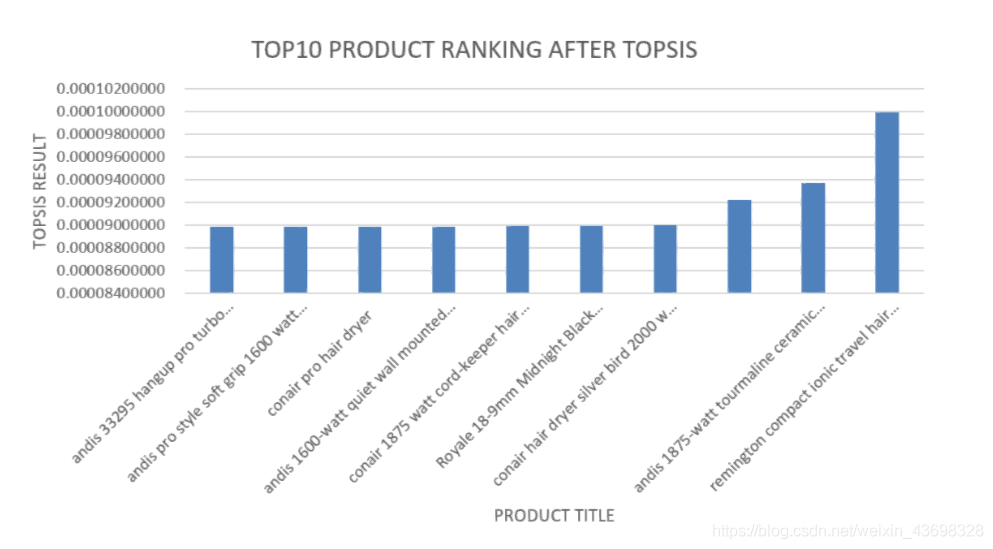
图3.7:星级与最终结果之间的相关性相关性很大。
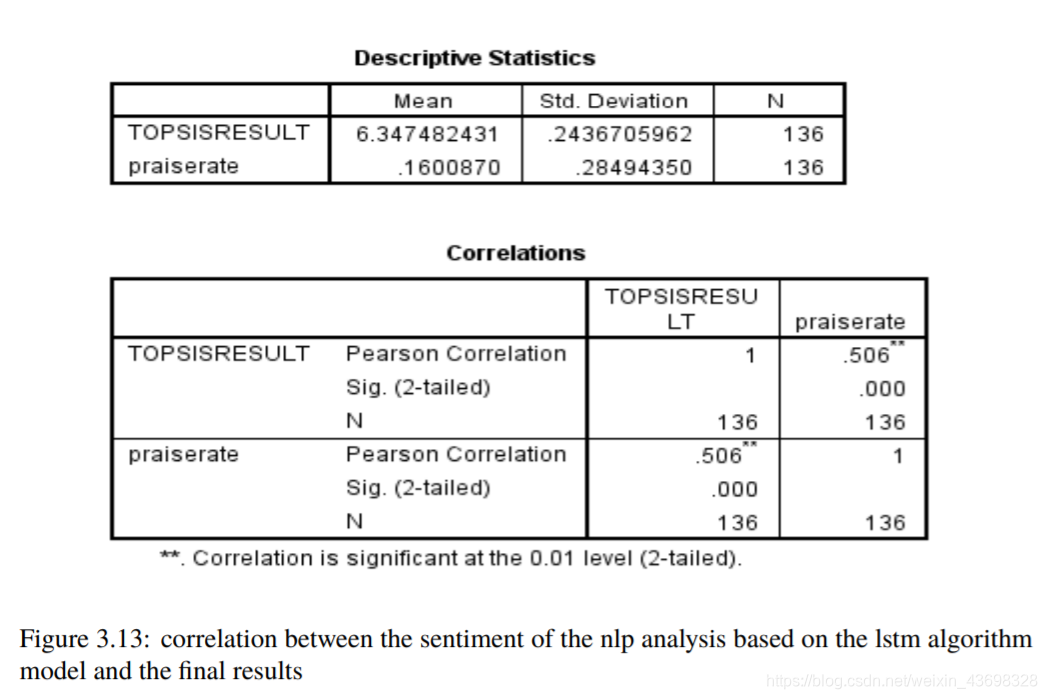
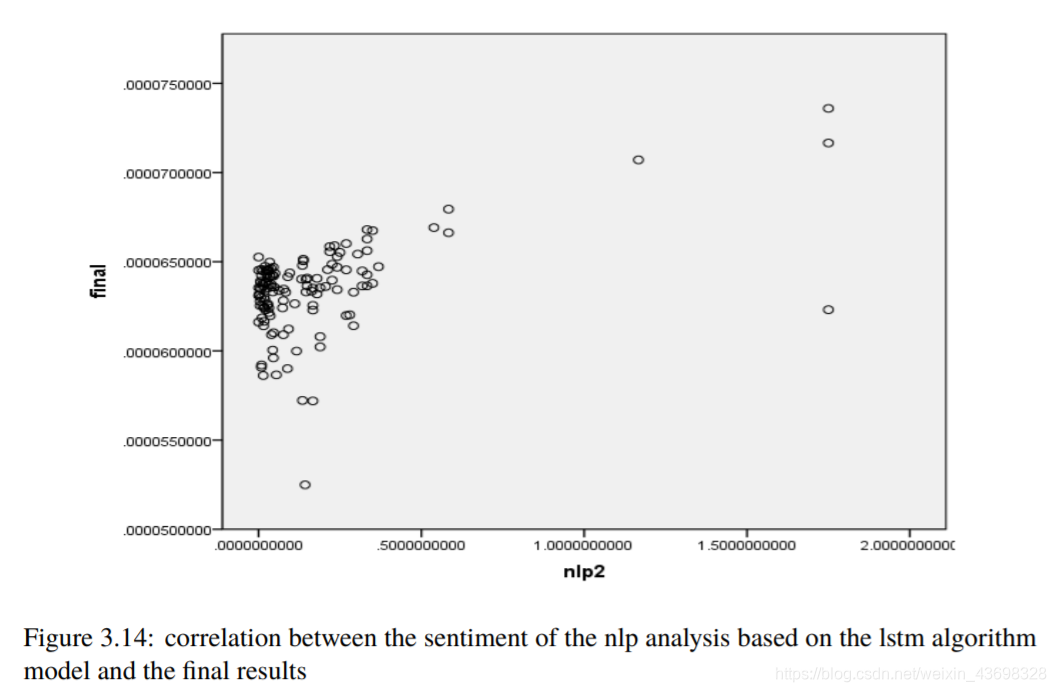
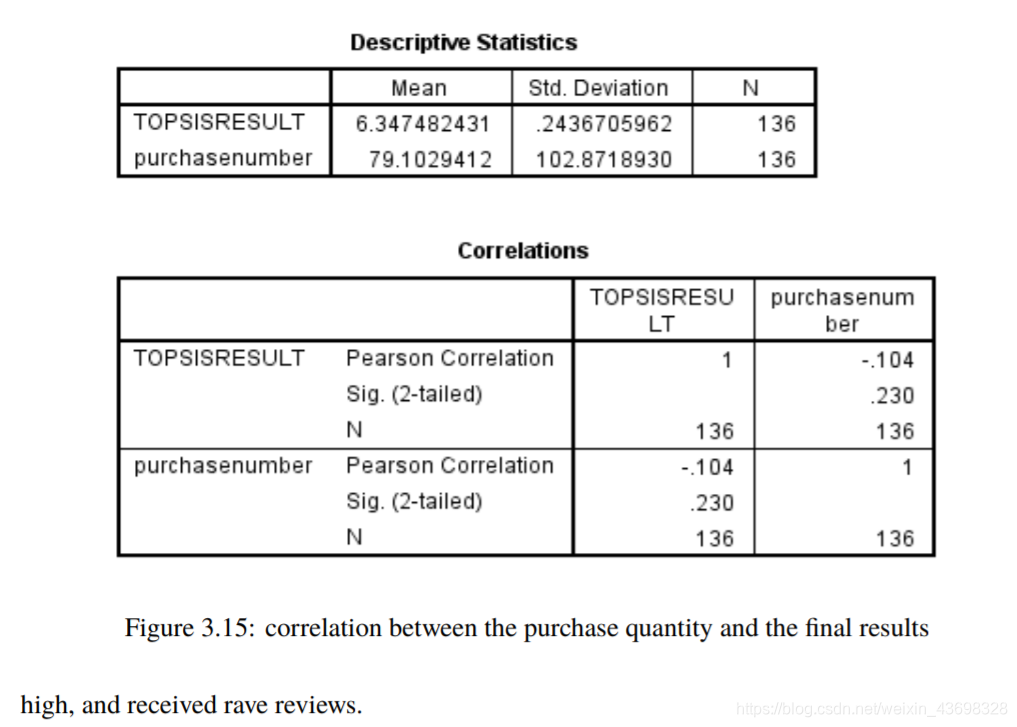
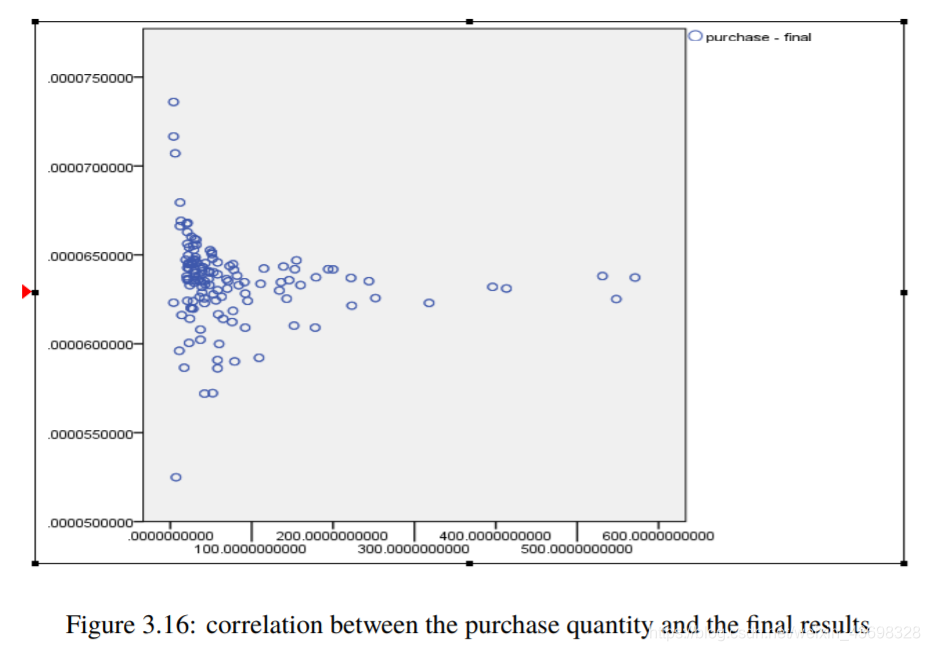
然后考虑基于lstm算法的nlp分析的情绪模型以及与最终结果的相关性。结果如图3.12和3.13所示。可以看出,假设检验结果为0.000,相关水平为0.506,相关性很大。考虑到购买数量和与最终结果的相关性,结果如图3.14和3.15所示。可以看出,假设检验结果为0.235,相关水平为-0.104,与相关性很小。4问题一4.1问题分析因为标题要求:基于评分和评论这两个指标,它们具有对阳光影响最大,确定一种数据测量方法。所以考虑这两个
图3.8:星级与最终结果之间的相关性
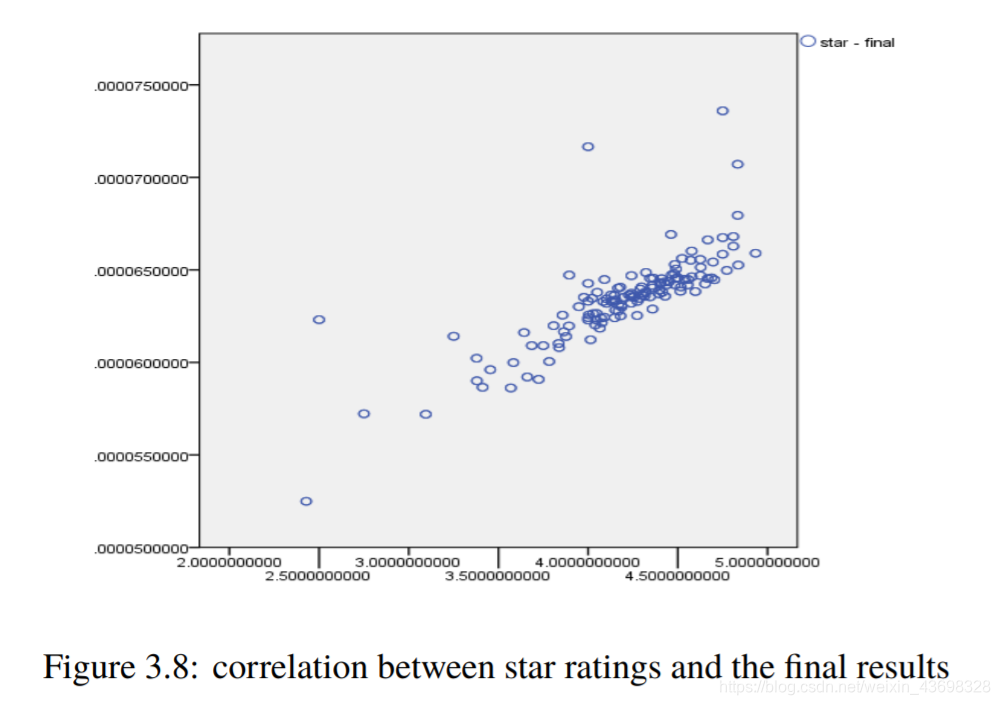
图3.9:投票星级与最终结果之间的相关性
因素:星级越高,产品越好;评论越好,越好产品; 星级越高,评论越可信。使用的topsis算法第一个问题,给出了三个指数:星级,NLP索引(按textblob)和NLP指数由LSTM。将每个指标的数据引入topsis算法以获得结果,可以用作评分和审查两个指标的数据衡量标准。4.2模型建立与解决方案考虑以下两个因素:星级越高,产品越好;越好评论,产品越好;星级越高,评论越可信。评论和星级是产品,因此两者应保持一致,但现在将有“五星级差评”和“一星肯定评价”,这表示出现了评分和星级。不一致之处。在这种情况下,数据需要进行预处理,并且“五星级差评”和“一星赞”将被删除。在上面的第一个问题中,通过基于textblob的NLP和基于机器学习的lstm
图3.10:投票星级与最终结果之间的相关性图
3.11:基于textblob nlp分析星级评定的情绪与最终结果模型,我们已将产品评论指标转化为数据形式的两个指标:NLP按textblob索引,按LSTM索引NLP。在第一个问题中,考虑了五个指标,包括星级和NLP指数,之后按textblob的NLP指数和按LSTM的NLP指数审查情绪分析。另外两个是我们的预定价格和购买数量。因此,在第一个问题中,考虑了星级和评论评论,并且建立了基于这五个指标的topsis算法模型。但是如果根据标题的含义只能判断产品的好坏通过评级和审查,那么我们仅将topsis算法模型提供给以下三个指标:星级和NLP指数Nemo指数通过textblob,NLP指数通过LSTM进行分析。
下图4.1是topsis算法之后的数据结果排名。
图3.12:基于textblob nlp分析星级评定的情绪与最终结果
5问题b
5.1问题分析b
根据“可以预测或预测的数据”来分析和讨论“基于时间的度量和模式”表示产品的声誉会在市场中增加或减少。”该表在一段时间内具有相关的索引参数,因此请找出产品的数据以相对大量的购买为样本,然后执行拓扑算法分析此样本中的数据以获得结果。数据以图表。
5.2模型建立与解决
我们发现了一种名为“ conair 1875瓦电气石陶瓷吹风机”的产品,该产品从2008年11月8日到2015年8月26日。执行nlp语义情感该产品对n条评论的认可产生了两个指标,textblob给出了NLP指数LSTM的NLP指数。这两个指标,星级评定和四个评判指标作为Topsis算法。按时间顺序对topsis的结果进行排序,然后制作一个图形:水平轴是时间轴(从2008年11月8日到2015年8月26日),垂直轴是topsis的结果。如图5.1、5.2和5.3所示。
6.问题c
介绍了时间序列模型。时间序列模型是用于预测一段时间内变量的变化。AR模型:如果时间序列Xt是其先前值和随机项的线性函数,可以表示为:X 吨 = φ 1 X 叔 1 + φ 2 X 叔 2 + … + φ p X 吨-P + ù 吨(6.1)
图3.13:基于lstm算法的nlp分析情绪之间的相关性模型和最终结果
真正的参数φ 1 ,φ 2 ,…,φ p被称为自回归系数,是一个特殊的估计参数。随机数u t是一系列独立的白噪声,并且服从正态分布,平均的0和的方差σ 2。随意的想法不是与滞后变量有关。MA模型:如果时间序列Xt是其当前误差和先前随机误差的线性函数术语,可以表示为:X 吨 = Ü 吨 - θ 1 Ü 叔 1 - θ 2 ü 叔 2 - … - θ q ü 吨-Q(6.2)真正的参数θ 1 ,θ 2 ,…,θ q是移动平均系数,是成为参数估计。ARMA模型:如果时间序列Xt是其当前和先前随机数的线性函数错误条款和以前的值。表示为:X 吨 = φ 1 X 叔 1 + φ 2 X 叔 2 + … + φ p X 吨-P + ù 吨 - θ 1 Ü 叔 1 - θ 2 ü 叔 2 - … - θ q ù q(6.3)公式(6.3)称为阶(p,q)的自回归平均模型,写为ARMA(p,q)。真正的参数φ 1 ,φ 2 ,…,φ p被称为自回归系数,和θ 1 ,θ 2 ,…,θ q被称为移动平均系数。使用ARMA模型根据当前评级预测未来产品的价值和视图,结果如图所示
图3.14:基于lstm算法的nlp分析情绪之间的相关性模型和最终结果
7问题d
7.1问题分析d
根据先前问题的时间模式,分析是否还会有更多问题在一段时间内集中正面或负面评论。直接使用问题B的时空算法进行分析。找出一条数据,其中topsis算法连续一段时间处于高点和低点,以进行分析数据索引。
7.2模型建立与解决
为了更直观,我们将问题b的时间轴四舍五入以绘制雷达图表,即图5.3。从该图可以直观地看出,对产品在一定时间内会出现高点和低点。随机走入低谷(4月25日,2015年至2015年5月6日)进行分析。如您在2015年4月25日所见,一位客户评论说:“耗尽了大约4个月我买了之后 总可怜。我已经使用Conait吹风机多年了,从没有之前发行。这是一个半身像:-(“,并且打了一颗低星,所以顾客的评价态度稍后更改,导致此期间的TOPSIS RESULT减少。还可以看出,TOPSIS分数的高潮发生在2015年2月25日至2015年3月6日。分析了以下日期的具体数据:您可以看到在此期间,topsisNLP TEXTBLOB,NLP的四个指标LSTM,PRAISE RATE和STAR RATING都在接近最大值的水平,这表明这一时期的商品综合指标非常高。
图3.15:采购数量与最终结果之间的相关性高,并获得好评如潮。
8.问题e
根据问题1中的topsis算法模型,我们可以使用spss查找评分,平均得分和NLP指数之间的相关性(按textblob),NLP指数按LSTM,如下图所示如上图所示,可以看出textblob假设检验结果的NLP指数为0.000,相关水平为0.756。的相关性很大。因此,基于textbolb算法的评论具有很强的与星级之间呈正线性关系。可以看出,LSTM假设检验结果的NLP指数为0.559,相关性水平为-0.051,线性相关性不显着。因此,基于LSTM算法与星级无关紧要的线性关系。
9.给公司的写一封信
尊敬的营销总监
感谢您邀请我们的团队担任您的顾问。我们很荣幸为您服务。对于您的要求和问题,几天后我们的团队就达到了最佳解决方案思考和计算。请花几分钟为您阅读我们的解决方案,希望您很满意。根据公司提供的数据集,我们使用机器学习来分析基于自然语言处理(NLP)的文本,并获得了一些指标来判断产品质量(星级评价,NLP供评论,购买数量,有用的促销注释),在对这些指标建模TOPSIS算法后,获得每种产品。研究这些指标后,我们发现评论和购买
图3.16:采购数量与最终结果之间的相关性
数量指标对于产品最重要;产品评价指标并分析了产品销售的时间点,结果发现口在一定时间内增加或减少,即产品对应于我们在此期间较早研究的这些指标的变化时间的口碑也会改变。产品的声誉直接影响价值产品的质量和质量。希望贵公司的各种评价产品的指标,尤其是用户评论,售出的产品数量以及极端服务端口在一定时间内得到关注。同时,在分析了当前数据,我们可以预测未来几天的数据。也就是说,我们也希望贵公司可以建立商品的预测模型并预测商品中的指标下一个时期。将会发生的事情对于您公司的产品销售非常重要且有用。您忠诚的,你的朋友们
10附录参考文献
[1] Vivek Narayanan,Ishan Arora,Arjun Bhatia,“快速准确的情感分类使用增强的朴素贝叶斯模型。”
[2]黄,CL;Yoon,K.(1981)。多属性决策:方法与应用阳离子。纽约:施普林格出版社。
[3] Yoon,K.(1987)。“不同折衷情况之间的和解”。的杂志运筹学学会。38(3):277286. doi:10.1057 / jors.1987.44
[4] abc Sepp Hochreiter;JürgenSchmidhuber(1997)。“长期短期记忆”。神经的计算。9(8):17351780. doi:10.1162 / neco.1997.9.8.1735。PMID 9377276。
[5] Graves,A .;Liwicki,M .;费尔南德斯(S. Bertolami,R .; 邦克,H。Schmidhuber,J.(2009年)。“新型的连接器系统,用于改进无限制的手写识别”(PDF)。IEEE模式分析和机器智能交易。31(5):855868。CiteSeerX 10.1.1.139.4502。doi:10.1109 / tpami.2008.137。PMID 19299860。
[6] Funnell,Rob(2016年6月13日)。“'Arma Mobile Ops’在新西兰的App Store”。TouchArcade。2016年6月23日检索。
图4.1:topsis算法之后的数据结果排名
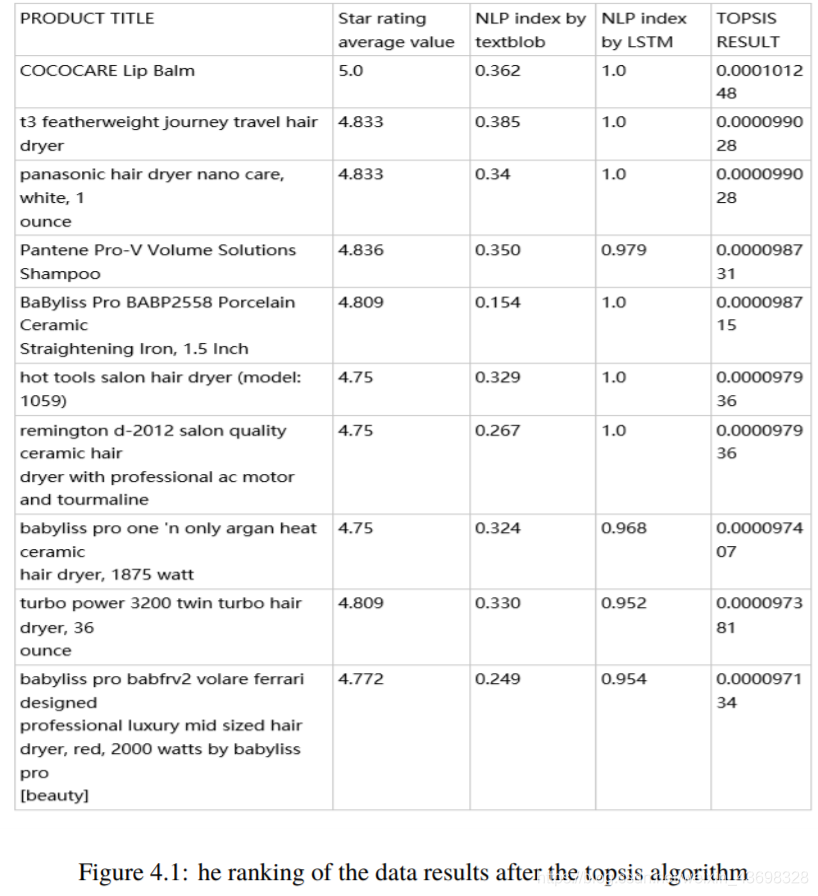
图5.1:topsis结果
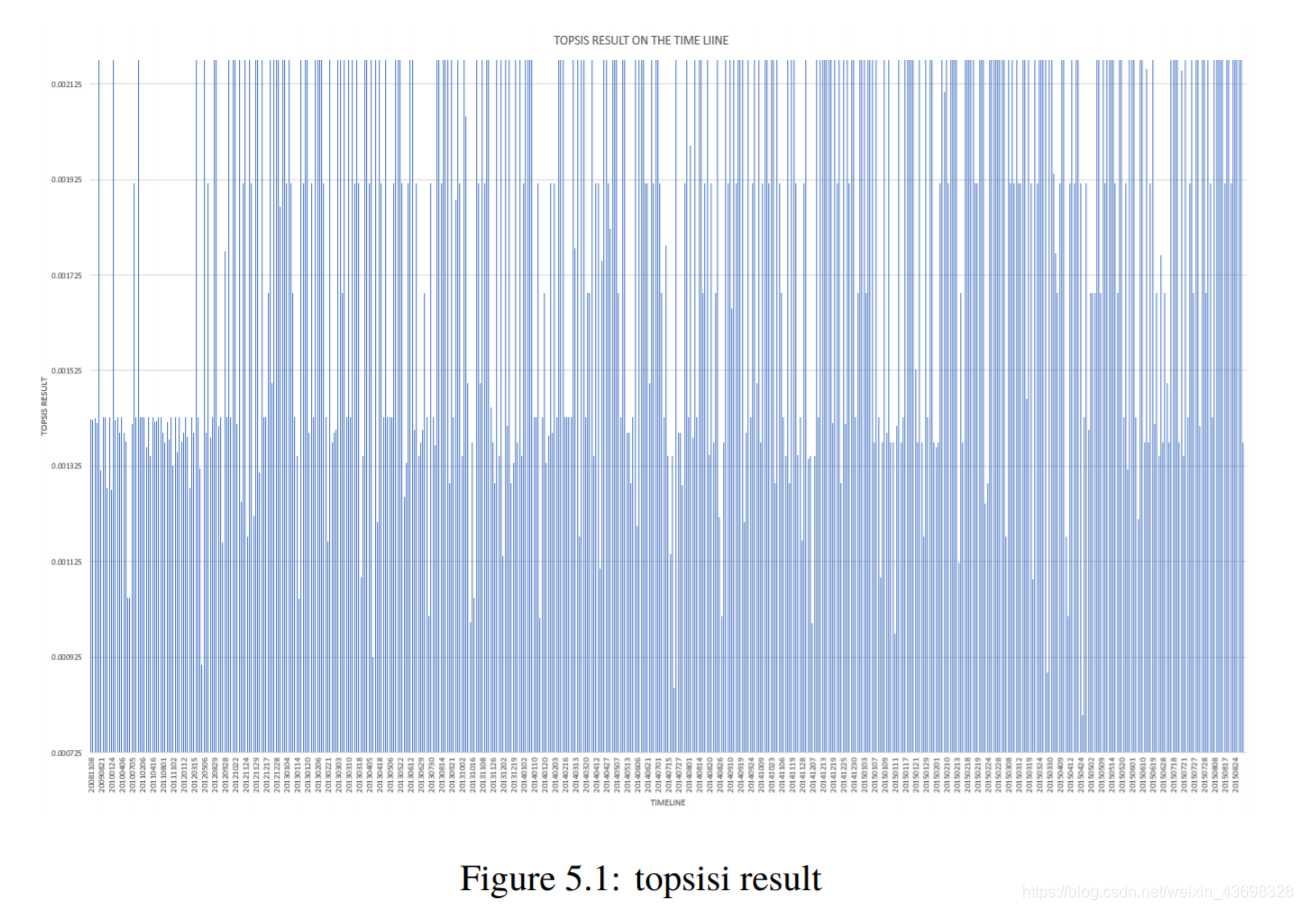
图5.2:拓扑结果
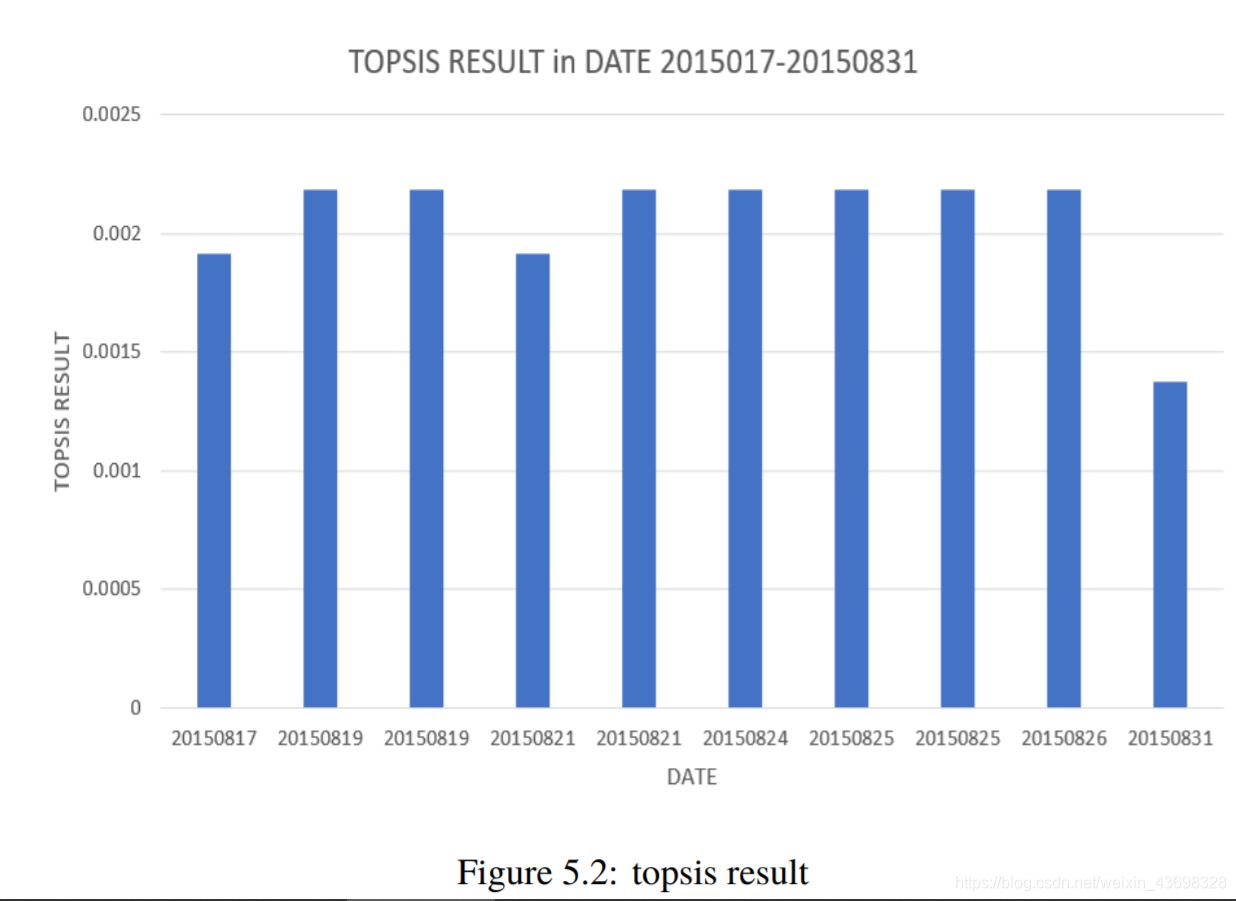
图5.3:拓扑结果
图6.1:ARMA结果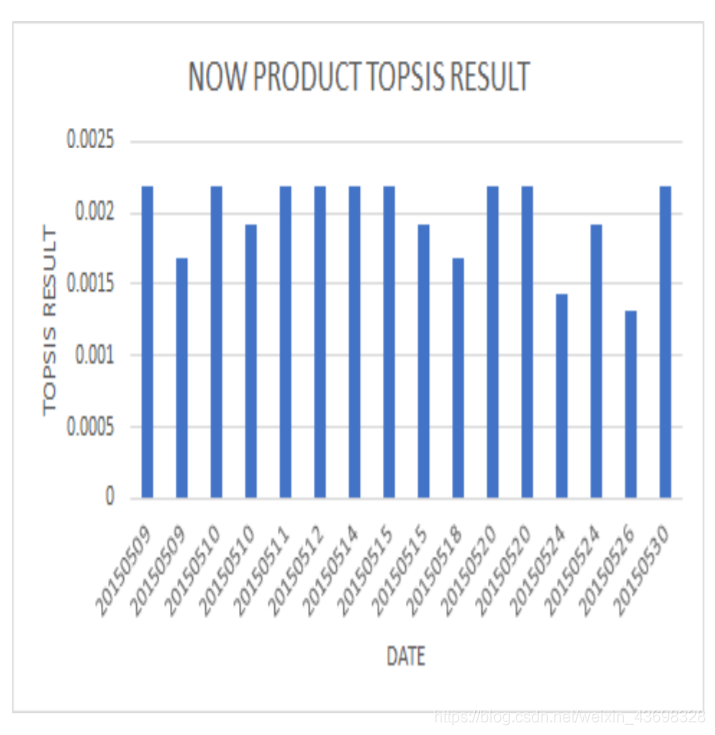
图6.2:ARMA结果
图7.1:槽分析结果
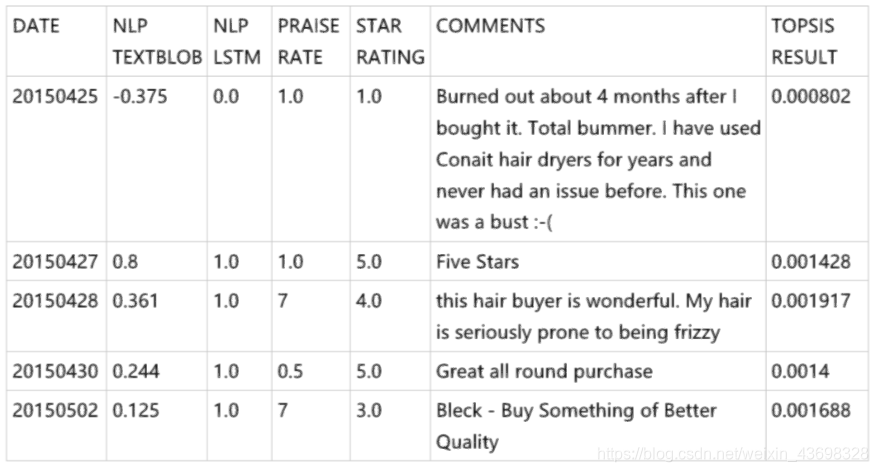
图7.2:高潮分析结果
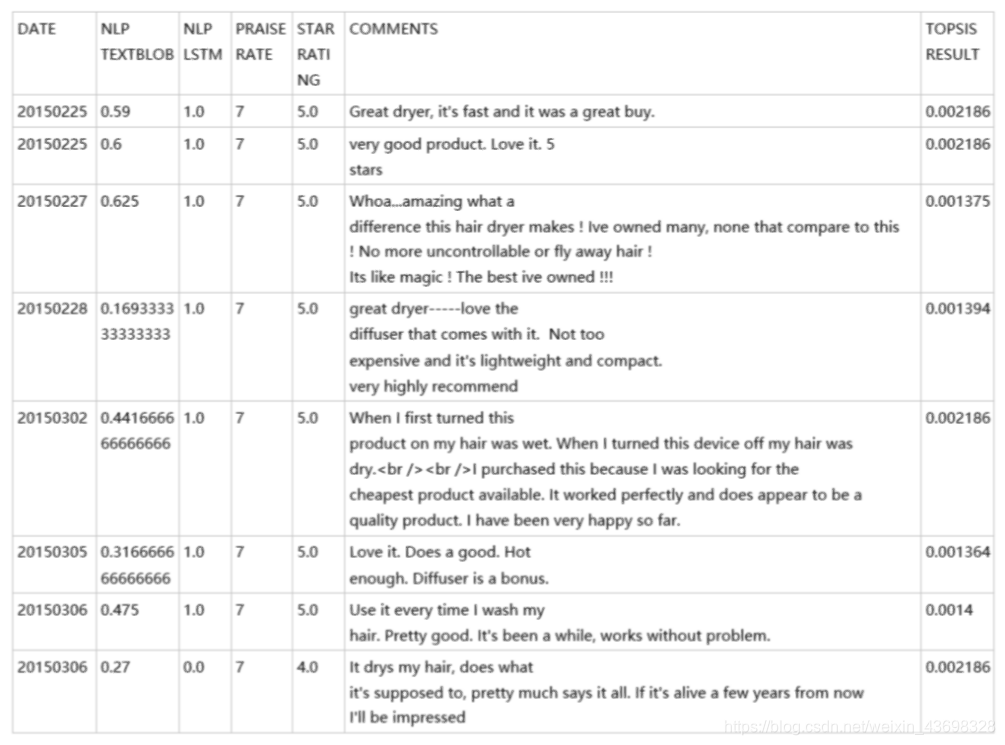
图8.1:
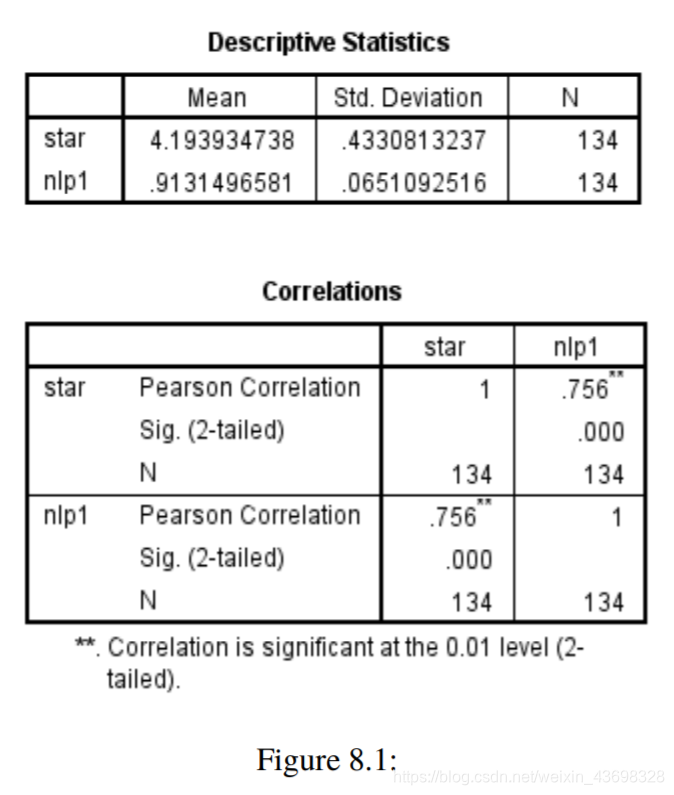
图8.2:
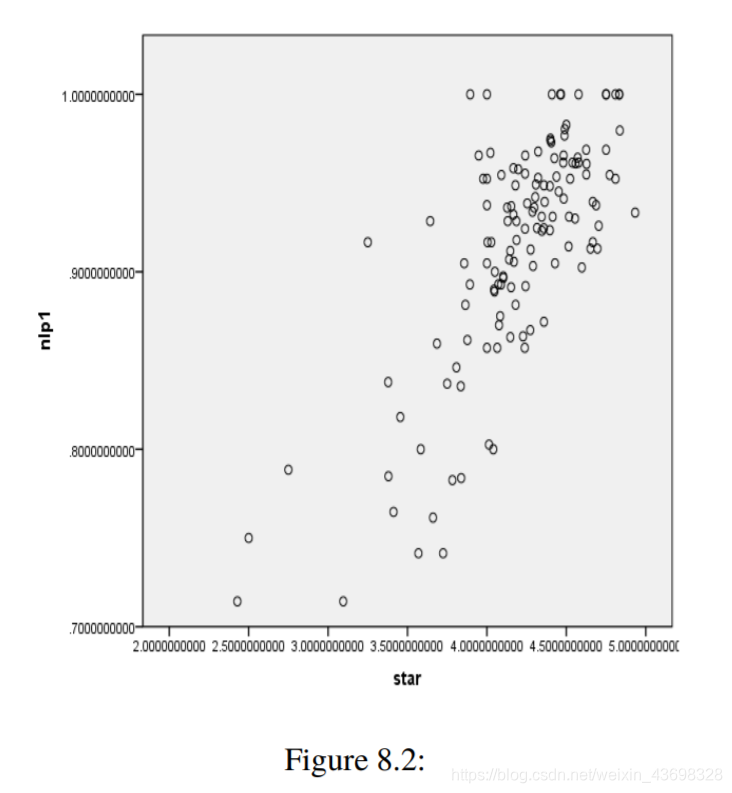
图8.3:
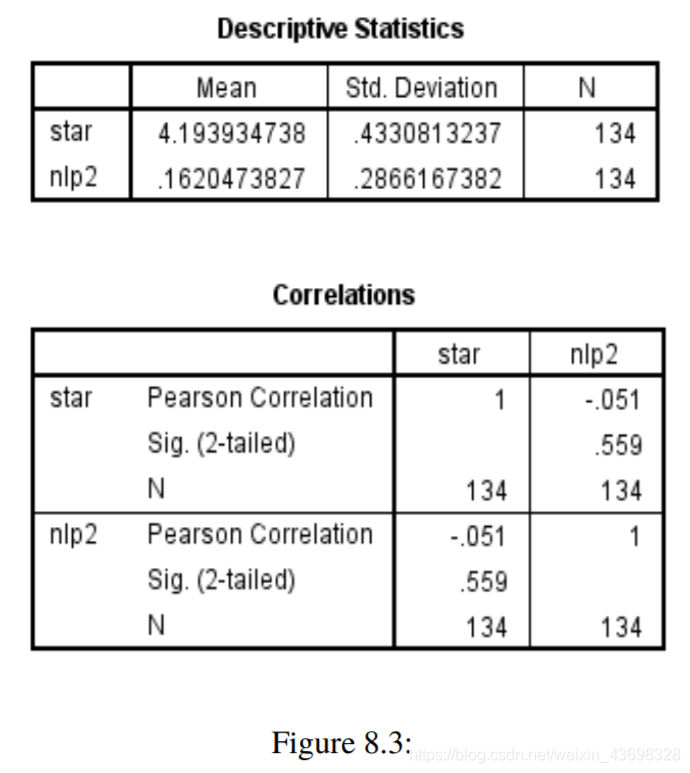
图8.4: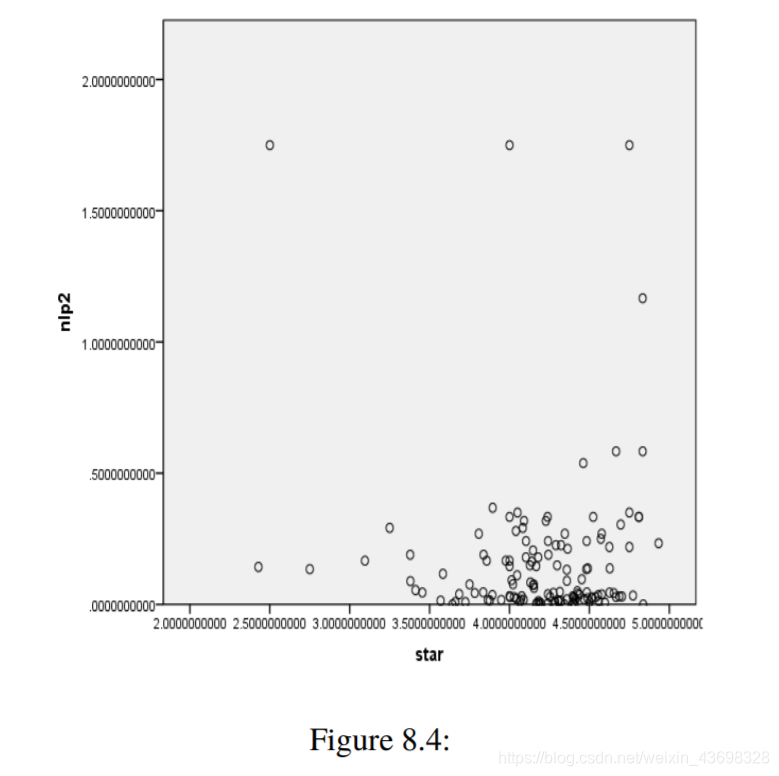
代码部分
1.Textblob的NLP语义情感分析
from textblob import TextBlob
text = "Like these for my rentals, but.. had one to quit on me although it's brand new"
blob = TextBlob(text)
print(blob.sentiment)
结果:
Sentiment(polarity=0.13636363636363635, subjectivity=0.45454545454545453)
2.基于LSTM机器学习的NLP语义情感分析
参考:这个网址
import os
os.environ['TF\_CPP\_MIN\_LOG\_LEVEL'] = '2'
import json
import numpy as np
import keras.backend as K
from keras.utils import to_categorical
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.models import load_model
from keras.models import Sequential
from keras.layers import Dense, Dropout, Embedding, LSTM, Bidirectional
from textblob import TextBlob
# 1. Loading the data
print("loading data...")
pos_file_name = "pos\_amazon\_cell\_phone\_reviews.json"
neg_file_name = "neg\_amazon\_cell\_phone\_reviews.json"
pos_file = open(pos_file_name, "r")
neg_file = open(neg_file_name, "r")
pos_data = json.loads(pos_file.read())['root']
neg_data = json.loads(neg_file.read())['root']
print("Posititve data loaded. ", len(pos_data), "entries")
print("Negative data loaded. ", len(neg_data), "entries")
print("done loading data...")
plabels = []
nlabels = []
# 2.Process reviews into sentences
pos_sentences, neg_sentences = [], []
for entry in pos_data :
pos_sentences.append(entry['summary'] + " . " + entry['text'])
plabels.append(1)
for entry in neg_data :
nlabels.append(0)
neg_sentences.append(entry['summary'] + " . " + entry['text'])
print(len(pos_sentences))
print(len(neg_sentences))
#
texts = pos_sentences + neg_sentences
labels = [1]\*len(pos_sentences) + [0]\*len(neg_sentences)
print("after app", labels)
# print(type(pos\_sentences), pos\_sentences.shape, type(neg\_sentences), neg\_sentences.shape)
# print(type(texts), texts.shape, type(labels), labels.shape)
# 3. Tokenize
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
'''
根据文本列表更新内部词汇表。
在文本包含列表的情况下,
我们假设列表中的每个条目都是一个标记。
必须在使用' texts\_to\_sequences '或' texts\_to\_matrix '之前。
'''
sequences = tokenizer.texts_to_sequences(texts)
'''
将文本中的每个文本转换为一个整数序列。
整数序列如:the -->1 and -->3
只有“num\_words-1”最常见的单词才会被考虑在内。
只有标记器知道的单词才会被考虑在内。
#参数
文本:文本列表(字符串)。
#返回
序列的列表。
'''
word_index = tokenizer.word_index
# 每个单词出现的次数
print('Found %s unique tokens.' % len(word_index))
# 宏定义 最大序列长度
MAX_SEQUENCE_LENGTH = 50
data = sequence.pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
'''
该函数将一个' num\_samples '序列列表(整数列表)转换为一个二维Numpy形状数组' (num\_samples, num\_timesteps) '。
如果提供了' num\_timesteps ',则为' maxlen '参数,否则为最长序列的长度。
'''
print(labels)
labels = np.array(labels)
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)
# split the data into a training set and a validation set
indices = np.arange(data.shape[0]) #0-shape
np.random.shuffle(indices) #以随机数来给indices赋值
# data和label都打乱
data = data[indices]
labels = labels[indices]
#
rest_data = data[3000:]
rest_labels = labels[3000:]
data = data[:5000]
labels = labels[:5000]
VALIDATION_SPLIT = 0.2 #验证参数
nb_validation_samples = int(VALIDATION_SPLIT \* data.shape[0]) #总样本数\*验证参数
print(data.shape, labels.shape, nb_validation_samples)
print(labels)
x_train = data[:-nb_validation_samples] #取得时候在后面省略 总样本数\*验证参数 这么多个
y_train = labels[:-nb_validation_samples]
x_val = data[-nb_validation_samples:] #只取后面的 总样本数\*验证参数 这么多个
y_val = labels[-nb_validation_samples:]
print(len(x_train), len(y_train))
#
#GloVe
embeddings_index = {} #嵌入的指数
f = open('glove.6B.50d.txt', 'r', encoding = 'utf-8')
for line in f:
values = line.split()
word = values[0] #word
coefs = np.asarray(values[1:], dtype='float32') #value数组
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index)) #词条特征向量
EMBEDDING_DIM = MAX_SEQUENCE_LENGTH
embedding_matrix = np.zeros((len(word_index) + 1, EMBEDDING_DIM))
# 嵌入矩阵:(有多少词汇,每个句子有多少词汇--50)
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all-zeros.
embedding_matrix[i] = embedding_vector
#
from keras.layers import Embedding
'''
将正整数(索引)转化为固定大小的稠密向量。
如。[[4], [20]] -> [[0.25, 0.1], [0.6, -0.2]]
输入,输出,
'''
embedding_layer = Embedding(len(word_index) + 1,
EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=False)
def precision(y_true, y_pred): #计算准确率
true_positives = K.sum(K.round(K.clip(y_true \* y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
#
def recall(y_true, y_pred): #召回率
true_positives = K.sum(K.round(K.clip(y_true \* y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
#
#
# Training the LSTM model
#
batch_size = 128
#
'''
线性叠加层。
#参数
层:要添加到模型中的层的列表。
名称:模型的名称
'''
model = Sequential()
#
'''
在层堆栈的顶部添加一个层实例。
#参数
一层一层:实例。
#提出
类型错误:如果“层”不是一个层实例。
ValueError:在“层”参数没有
知道它的输入形状。
ValueError:在“层”参数有
多个输出张量,或已经连接
其他地方(在“序列”模型中禁止)。
'''
model.add(embedding_layer)
#
model.add(LSTM(64))
#
'''
”“将Dropout应用于输入。
辍学包括随机设置
在训练期间的每次更新中,输入单位的分数“比率”为0,
这有助于防止过度拟合。
#参数
速率:在0到1之间浮动。要降低的输入单位的分数。
noise\_shape:一维整数张量,表示
二进制丢弃掩码,它将与输入相乘。
例如,如果您的输入具有形状
((batch\_size,时间步长,功能)和
您希望所有时间步长的辍学面具都一样,
您可以使用`noise\_shape =(batch\_size,1,features)`。
seed:用作随机种子的Python整数。
#参考
-[Dropout:防止神经网络过度拟合的简单方法](
http://www.jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf)
“”
'''
model.add(Dropout(0.50))
#
model.add(Dense(1, activation='sigmoid'))
#
# try using different optimizers and different optimizer configs
# 尝试使用不同的优化器和不同的优化器配置
model.compile('adam', 'binary\_crossentropy', metrics=['accuracy', precision, recall])
print('Train...')
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=16,
validation_data=[x_val, y_val])
x = model.evaluate(rest_data[:5000], rest_labels[:5000])
model.compile(optimizer='adam', loss='categorical\_crossentropy', metrics=['accuracy', precision, recall])
# model.save("model.hdf5")
#
print("Loss: ", x[0])
print("Accuracy: ", x[1])
print("Precision: ", x[2])
print("Recall: ", x[3])
input_text = "I like this dryer but it is a little bit larger than I wanted. Work really well and is not too loud."
# token = Tokenizer(num\_words=2000)
# token.fit\_on\_texts(train\_text)
#将影评转化为数字列表
input_seq = tokenizer.texts_to_sequences([input_text])#将影评转化为数字列表
#进行取长补短操作
pad_input_seq = sequence.pad_sequences(input_seq , maxlen=50)#进行取长补短操作
predict_result=model.predict_classes(pad_input_seq)#放入模型进行分析
print(predict_result)
model部分的结果,以及识别预测结果
Loss: 0.2165962651014328
Accuracy: 0.9152
Precision: 0.9188494445800781
Recall: 0.9928984497070312
[[1]]
这里训练模型要用到:
亚马逊的评论数据集(含手工标注5w条评论的情感值)+GLOVE语义情感数据库。
- 以下为识别新句子:
input_text = "I love this hair dryer;Nevertheless, I still highly recommend it and would buy it again."
model = load_model("model.hdf5",custom_objects={'precision': precision,'recall':recall})
sequences = tokenizer.texts_to_sequences(input_text)
print(sequences)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
data = sequence.pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)#取长补短操作
print(data)
print('Shape of data tensor:', data.shape)
result=model.predict_classes(data)#放入模型进行分析
print(result)
TOPSIS模型的Python实现
import numpy as np
import xlrd
import pandas as pd
# 从excel文件中读取数据
def read(file):
wb = xlrd.open_workbook(filename=file) # 打开文件
sheet = wb.sheet_by_index(0) # 通过索引获取表格
rows = sheet.nrows # 获取行数
all_content = [] # 存放读取的数据
# title star blob rnn h/t verified\_purchase
for j in [5, 7, 8, 10, 13, 13]: # 取第1~第4列对的数据
temp = []
for i in range(1, rows):
cell = sheet.cell_value(i, j) # 获取数据
temp.append(cell)
all_content.append(temp) # 按列添加到结果集中
temp = []
return np.array(all_content)
# 极小型指标 -> 极大型指标
def dataDirection\_1(datas):
return np.max(datas) - datas # 套公式
# 中间型指标 -> 极大型指标
def dataDirection\_2(datas, x_best):
temp_datas = datas - x_best
M = np.max(abs(temp_datas))
answer_datas = 1 - abs(datas - x_best) / M # 套公式
return answer_datas
# 区间型指标 -> 极大型指标
def dataDirection\_3(datas, x_min, x_max):
M = max(x_min - np.min(datas), np.max(datas) - x_max)
answer_list = []
for i in datas:
if (i < x_min):
answer_list.append(1 - (x_min - i) / M) # 套公式
elif (x_min <= i <= x_max):
answer_list.append(1)
### 一、网安学习成长路线图
网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
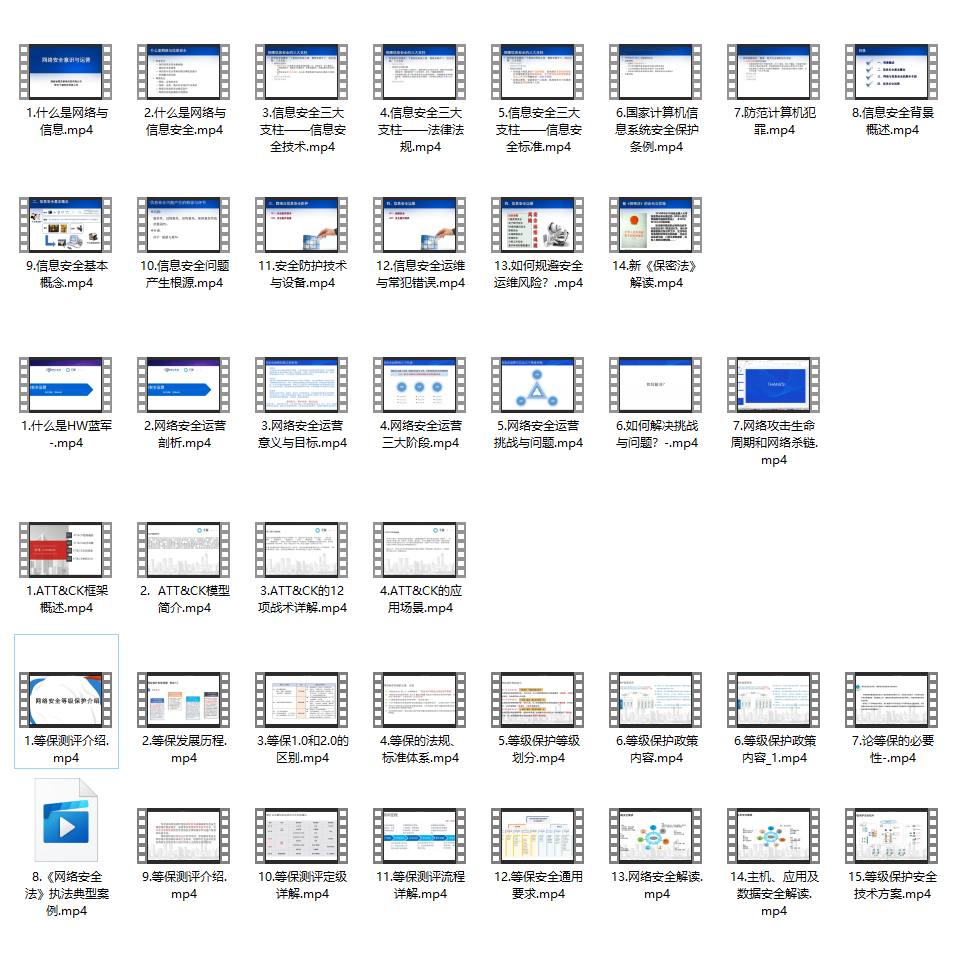
### 二、网安视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
### 三、精品网安学习书籍
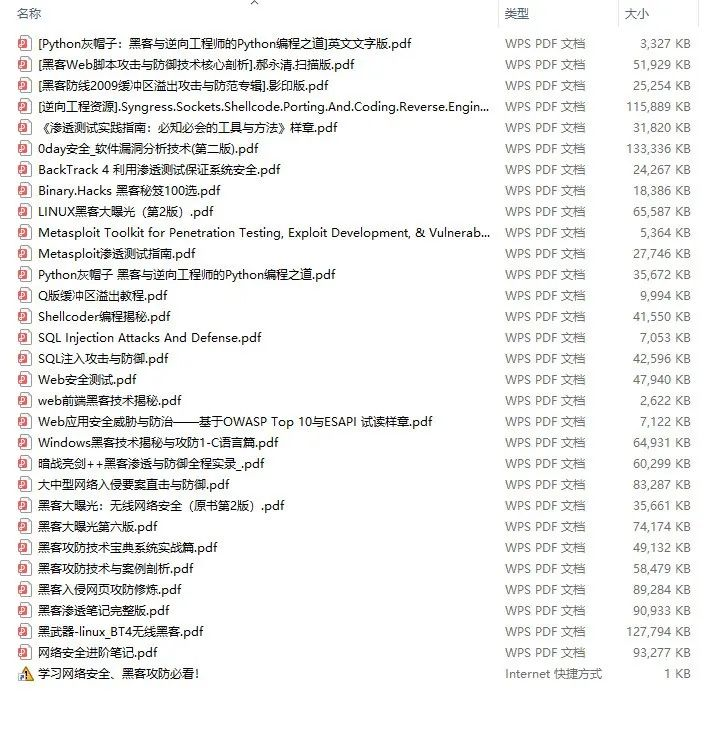
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
### 四、网络安全源码合集+工具包
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

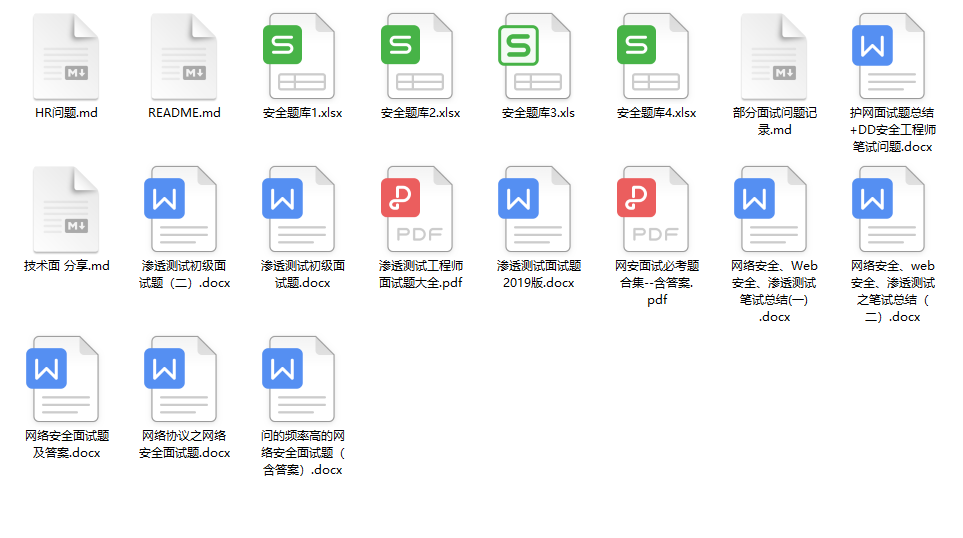
### 五、网络安全面试题
最后就是大家最关心的网络安全面试题板块
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









