







//设置mapper类
job.setMapperClass(WordCountMapper.class);
//设置reduce类
job.setReducerClass(WordCountReducer.class);
//设置Mapper类的输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce类的输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置要处理的文件
FileInputFormat.addInputPath(job,new Path(“hdfs://192.168.21.128:9000/txt/words.txt”));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path(“hdfs://192.168.21.128:9000/result/wordcount”));
//启动
job.waitForCompletion(true);
}
}
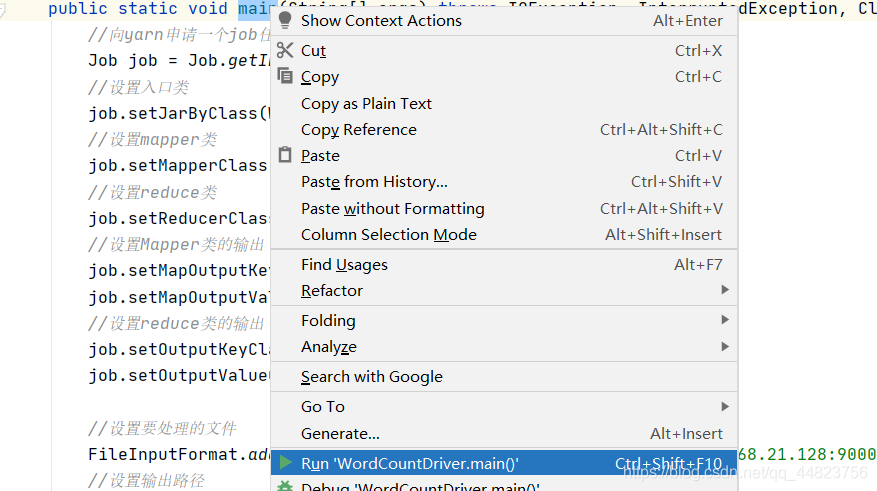
运行时,选中main函数,右键
====================================================================
package cn.top;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class CharTopMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{
//拆分这一行中的每一个字符
String datas = value.toString();
String[] split = datas.split(" ");
int x = Integer.parseInt(split[1]);
//将每一个字符进行遍历
context.write(new Text(split[0]),new IntWritable(x));
}
}
package cn.top;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class CharTopReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key,Iterable values,Context context) throws IOException,InterruptedException{
int sum=0;
int sum1=0;
for(IntWritable val:values){
sum = Integer.parseInt(String.valueOf(val));
if(sum1 < sum){
sum1=sum;
}
}
context.write(key,new IntWritable(sum1));
}
}
package cn.top;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class CharTop {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//向yarn申请一个job任务用于执行mapreduce程序
Job job = Job.getInstance(new Configuration());
//设置入口类
job.setJarByClass(CharTop.class);
//设置mapper类
job.setMapperClass(CharTopMapper.class);
//设置reduce类
job.setReducerClass(CharTopReducer.class);
//设置Mapper类的输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce类的输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置要处理的文件
FileInputFormat.addInputPath(job,new Path(“hdfs://192.168.21.128:9000/txt/score2.txt”));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path(“hdfs://192.168.21.128:9000/result/charcount”));
//启动
job.waitForCompletion(true);
}
}
===================================================================
package cn.quchong;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class quchongMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{
String datas = value.toString();
context.write(new Text(datas),NullWritable.get());
}
}
package cn.quchong;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class quchongReducer extends Reducer<Text, IntWritable,Text,NullWritable> {
@Override
protected void reduce(Text key,Iterable values,Context context) throws IOException,InterruptedException{
context.write(new Text(key), NullWritable.get());
}
}
package cn.quchong;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class quchongDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//向yarn申请一个job任务用于执行mapreduce程序
Job job = Job.getInstance(new Configuration());
//设置入口类
job.setJarByClass(quchongDriver.class);
//设置mapper类
job.setMapperClass(quchongMapper.class);
//设置reduce类
job.setReducerClass(quchongReducer.class);
//设置Mapper类的输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//设置reduce类的输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置要处理的文件
FileInputFormat.addInputPath(job,new Path(“hdfs://192.168.21.129:9000/txt/ip.txt”));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path(“hdfs://192.168.21.129:9000/result/quchong”));
//启动
job.waitForCompletion(true);
}
}
=====================================================================
package cn.ScoreSum;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class ScoreSumMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{
String data = value.toString();
String[] s = data.split(" ");
context.write(new Text(s[0]),new IntWritable(Integer.parseInt(s[1])));
}
}
package cn.ScoreSum;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ScoreSumReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key,Iterable values,Context context) throws IOException,InterruptedException{
int sum=0;
for(IntWritable val:values){
sum=sum+val.get();
}
context.write(key,new IntWritable(sum));
}
}
package cn.ScoreSum;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









