







知其然不知其所以然,大厂常问面试技术如何复习?
1、热门面试题及答案大全
面试前做足功夫,让你面试成功率提升一截,这里一份热门350道一线互联网常问面试题及答案助你拿offer

2、多线程、高并发、缓存入门到实战项目pdf书籍



3、文中提到面试题答案整理

4、Java核心知识面试宝典
覆盖了JVM 、JAVA集合、JAVA多线程并发、JAVA基础、Spring原理、微服务、Netty与RPC、网络、日志、Zookeeper、Kafka、RabbitMQ、Hbase、MongoDB 、Cassandra、设计模式、负载均衡、数据库、一致性算法 、JAVA算法、数据结构、算法、分布式缓存、Hadoop、Spark、Storm的大量技术点且讲解的非常深入



总结:Topic是个逻辑的概念,Topic可以很好的做业务划分,每个消费者只需要关注自己的Topic即可。
分区如何保证顺序
========
通过上文我们知道分区的目的就是分散单节点的压力,再结合Topic和Message,那么消息的大概分层就是Topic(主题)->Partition(分区)->Message(消息)。也许你会问,既然分区是为了降低单节点的压力,那么干嘛不用多个topic代替多个分区,在多个机器节点的情况下,我们可以把多个topic部署在多个节点上,似乎也能实现分布式,简单一想似乎可行,仔细一想,还是不对。我们最终还要服务业务的,这样的话,本来一个topic的业务,要拆解成多个topic,反而把业务的定义打散了。
好吧,既然有多个分区了,那么消息的分配是个问题,如果topic下面的数据过于集中在某个分区上,又会造成分布不均匀,解决这个问题,一套好的分配算法是很有必要的。
kafka支持轮询法,即在多分区的情况下,通过轮询可以均匀地把消息分给每个分区,这里需要注意的是,每个分区里的数据是有序的,但是整体的数据是无法保证顺序的,如果你的业务强依赖消息的顺序,那么就要慎重考虑这种方案,比如生产者依次发了A、B、C三个消息,它们分别分布在3个分区中,那么有可能出现的消费顺序是B、A、C。
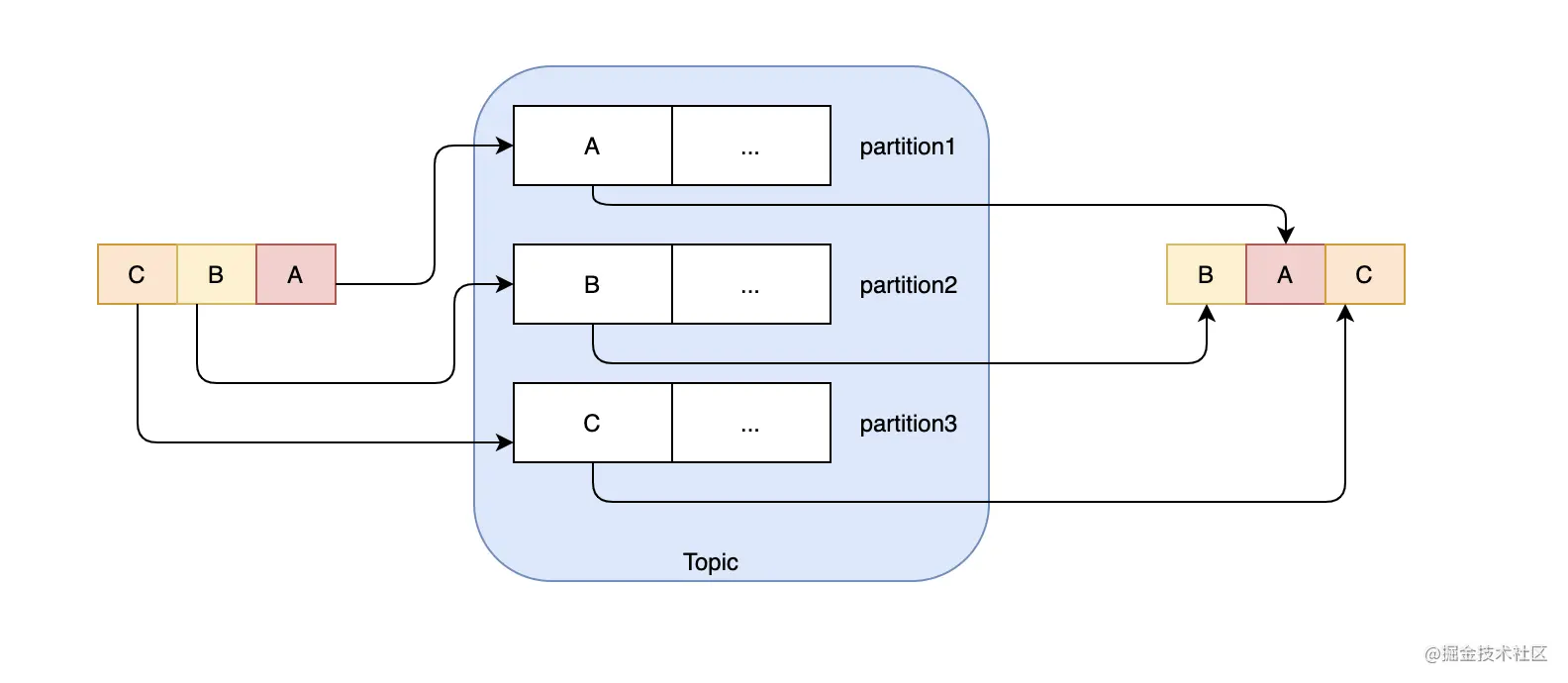
那么如何保证消息的顺序性?从整体的角度来看,只要分区数大于1,就永远无法保证消息的顺序性,除非你把分区数设置成1,但是这样的话吞吐就是问题。从实际的业务场景来说,一般我们可能需要某个用户的消息、或者某个商品的消息有序就可以了,用户A和用户B的消息谁先谁后没关系,因为它们之间没什么关联,但是用户A的消息我们可能要保持有序,比如消息描述的是用户的行为,行为的先后顺序是不能乱的。这时候我们可以考虑用key hash的方式,同一个用户id,通过hash始终能保持分到一个分区上,我们知道分区内部是有序的,所以这样的话,同一个用户的消息一定是有序的,同时不同的用户可以分配到不同的分区上,这样也利用到了多分区的特性。
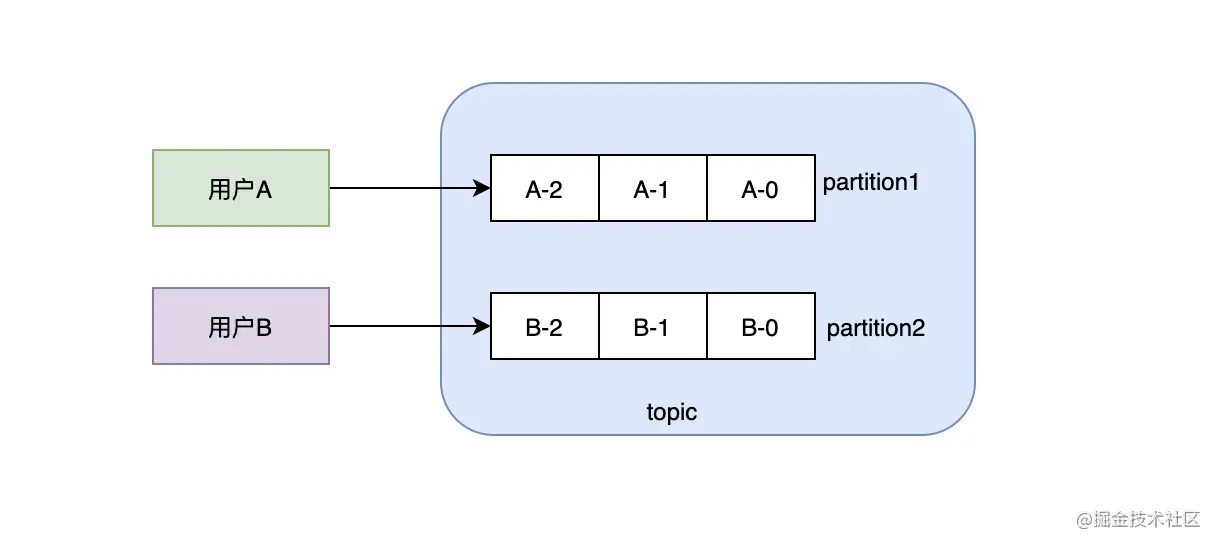
总结:kafka整体消息是无法保证有序的,但是单个分区的消息是可以保证有序的。
如何设计一个合理的消费者模型
==============
既然是设计消息模型,那么消费者必不可少,实现消费者最简单的方式就是起一个进程或者线程直接去broker里面拉取消息即可,这很合理,但是如果生产的速度大于当前的消费速度怎么办?第一时间想到的就是再起一个消费者,通过多个消费者来提升消费速度,这里似乎又有个问题,两个消费者都消费到了同一条消息怎么办?加锁是个解决方案,但是效率会降低,也许你会说消费的本质就是读,读是可以共享的,只要保证业务幂等,重复消费消息也没关系。这样的话,如果10个消费者都争抢到了同样的消息,结果有9个消费者都是白白浪费资源的。因此在需要多个消费者提升消费能力的同时,还要保证每个消费者都消费到没被处理的消息,这就是消费者组,消费者组下面可以有多个消费者,我们知道topic是分区的,因此只要消费者组内的每个消费者订阅不同的分区就可以了。理想的情况下是每个消费者都分配到相同数据量分区,如果某个消费者获得的分区数不平均(较多或者较少),出现数据倾斜状态,那么就会导致某些消费者非常繁忙或者轻松,这样就不合理,这就需要一套均衡的分配策略。
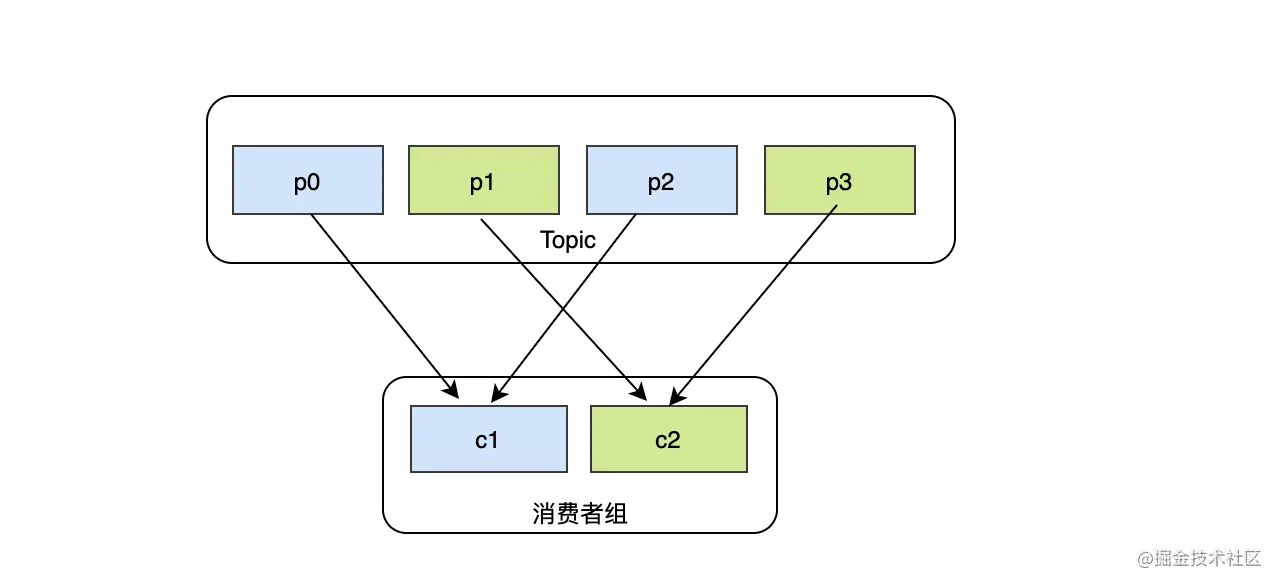
kafka消费者分区分配策略主要有3种:
1.Range:这种策略是针对topic的,会把topic的分区数和消费者数进行一个相除,如果有余数,那就说明多余的分区不够平均分了,此时排在前面的消费者会多分得1个分区,乍看其实挺合理,毕竟本来数量就不均衡。但是如果消费者订阅了多个topic,并且每个topic平均算下来都多几个个分区,那么对于排在前面的消费者就会多消费很多分区。
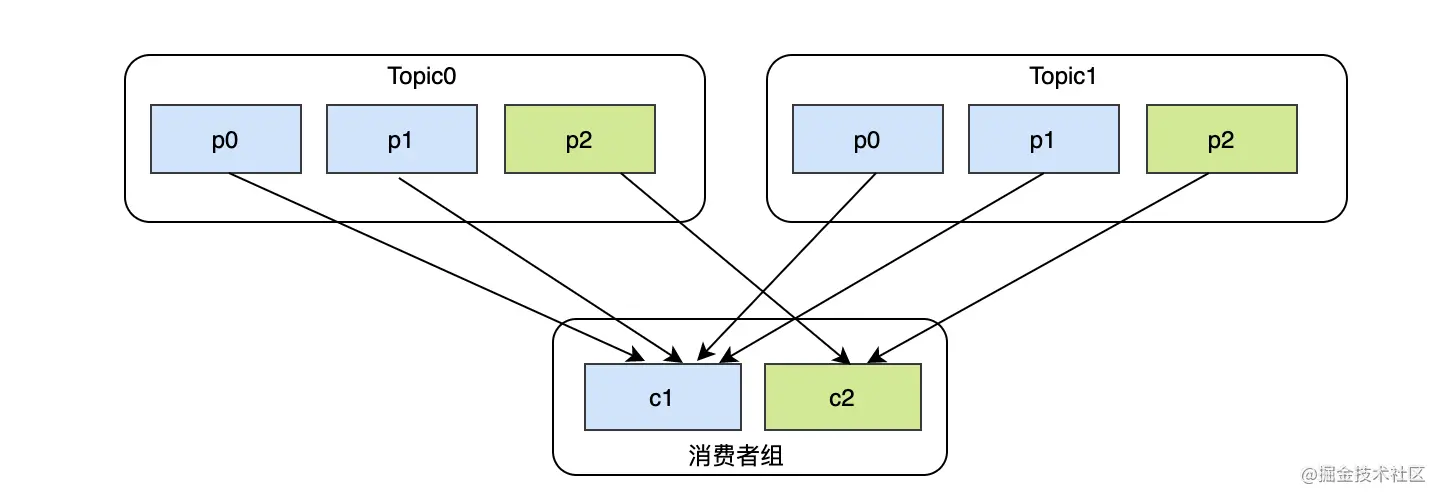
由于是按照topic维度来划分的,所以最终:
-
c1消费 Topic0-p0、Topic0-p1、Topic1-p0、Topic1-p1
-
c2消费 Topic0-p2、Topic1-p2
最终可以发现消费者c1比消费者c2整整多两个分区,完全可以把c1的分区分一个给c2,这样就可以均衡了。
2.RoundRobin:这种策略的原理是将消费组内所有消费者以及消费者所订阅的所有topic的partition按照字典序排序,然后通过轮询算法逐个将分区以此分配给每个消费者。假设现在有两个topic,每个topic3个分区,并且有3个消费者。那么大致消费状况是这样的:
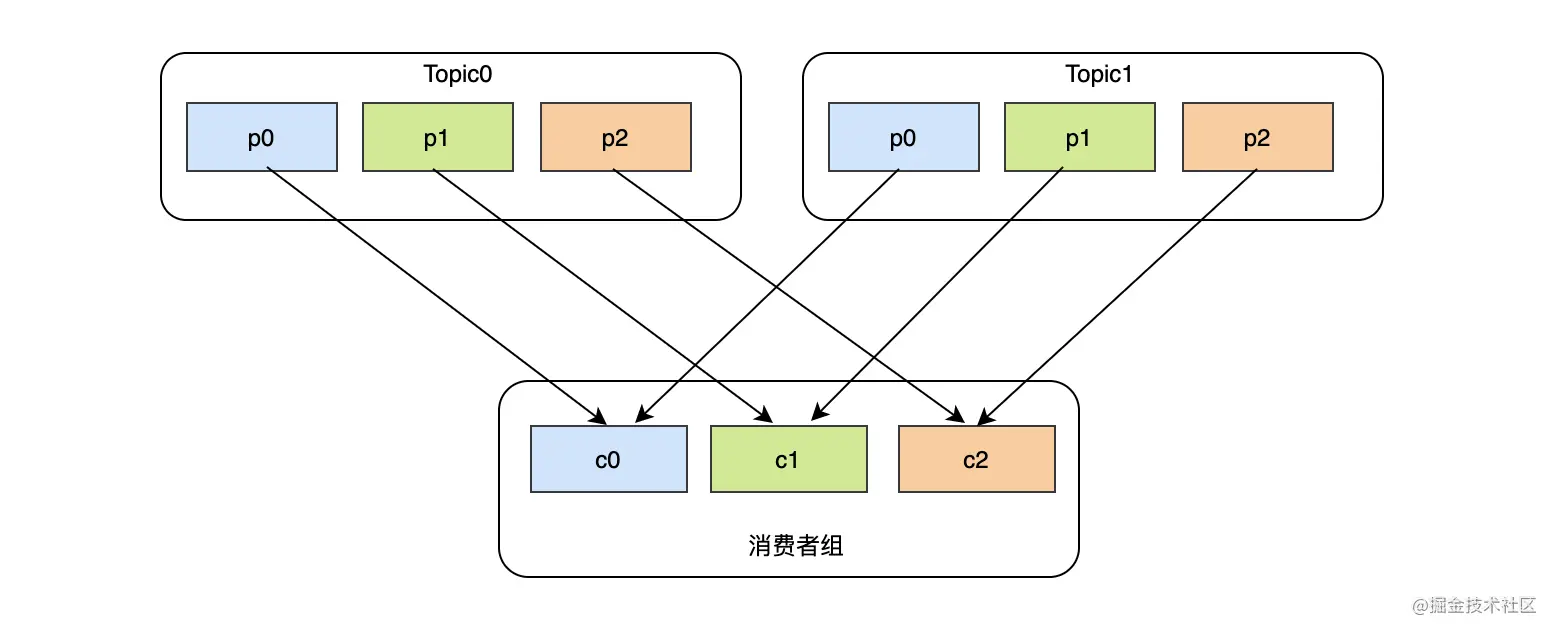
-
c0消费 Topic0-p0、Topic1-p0
-
c1消费 Topic0-p1、Topic1-p1
-
c2消费 Topic0-p2、Topic1-p2
看似很完美,但是如果现在有3个topic,并且每个topic分区数是不一致的,比如topic0只有一个分区,topic1有两个分区,topic2有三个分区,而且消费者c0订阅了topic0,消费者c1订阅了topic0和topic1,消费者c2订阅了topic0、topic1、topic2,那么大致消费状况是这样的:
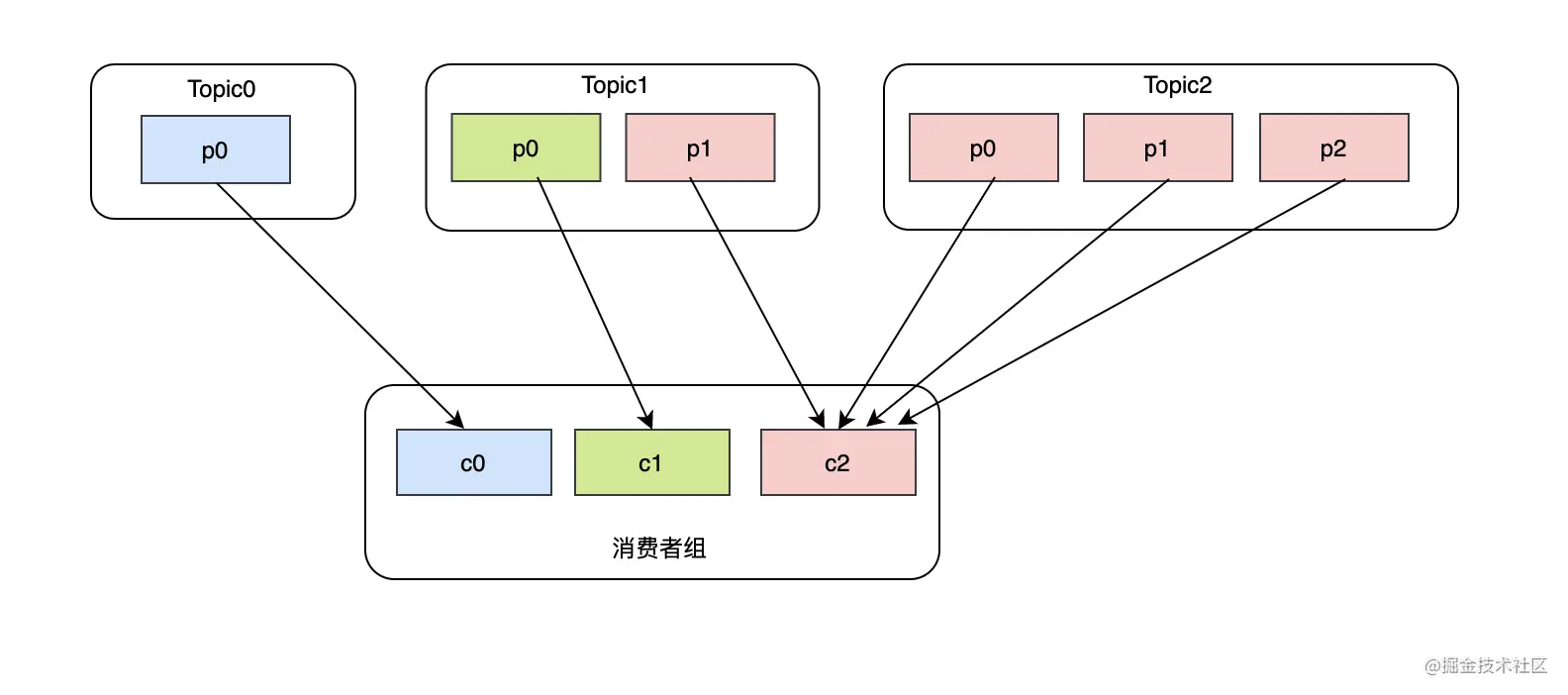
-
c0消费 Topic0-p0
-
c1消费 Topic1-p0
-
c2消费 Topic1-p1、Topic2-p0、Topic2-p1、Topic2-p2
这么看来RoundRobin并不是最完美的,在不考虑每个topic分区吞吐能力的差异,可以看到c2的消费负担明显很大,完全可以将Topic1-p1分区分给消费者c1。
3.Sticky:Range和RoundRobin都有各自的缺点,某些情况下可以更加均衡,但是没有做到。
Sticky引入目的之一就是:分区的分配要尽可能均匀。以上面RoundRobin 3个topic分别对应1、2、3个分区的case来说,因为c1完全可以消费Topic1-p1,但是它没有。针对这种情况,在Sticky模式下,就可以做到把Topic1-p1分给c1。

Sticky引入目的之二就是:分区的分配尽可能与上次分配的保持相同。这里主要解决就是rebalance后分区重新分配的问题,假设现在有3个消费者c0、c1、c2,他们都订阅了topic0、topic1、topic2、topic3,并且每个topic都有两个分区,此时消费的状况大概是这样:
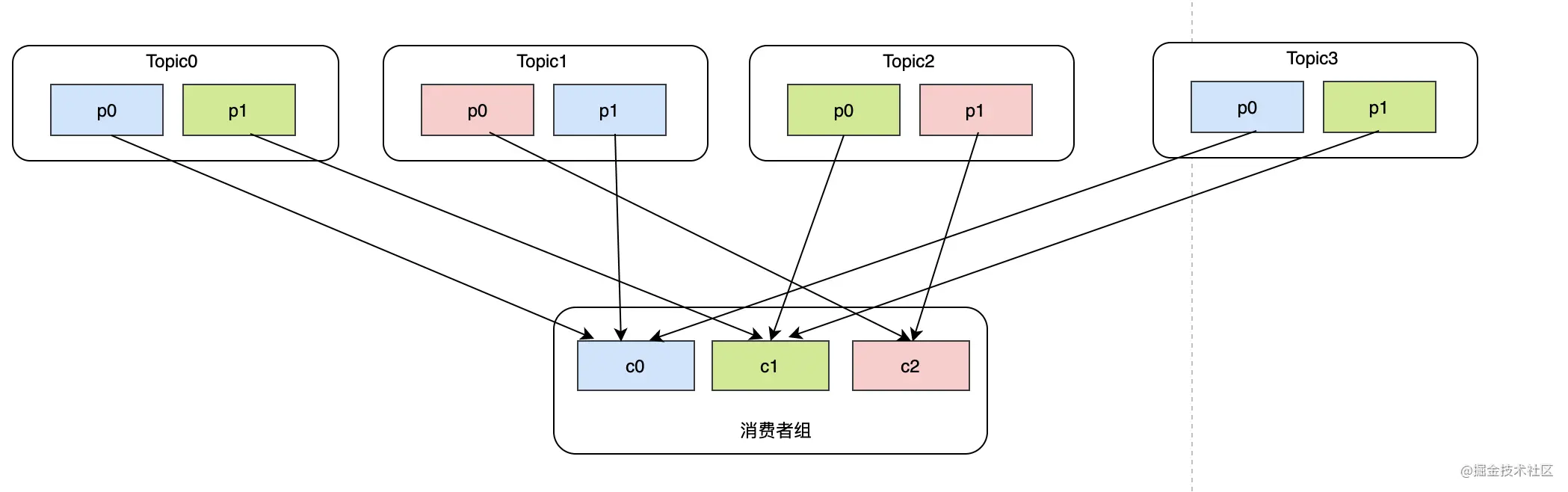
这种分配方式目前看RoundRobin没什么区别,但是如果此时消费者c1退出,消费者组内只剩c0、c2。那么就需要把c1的分区重新分给c0和c2,我们先来看看RoundRobin是如何rebalance的:
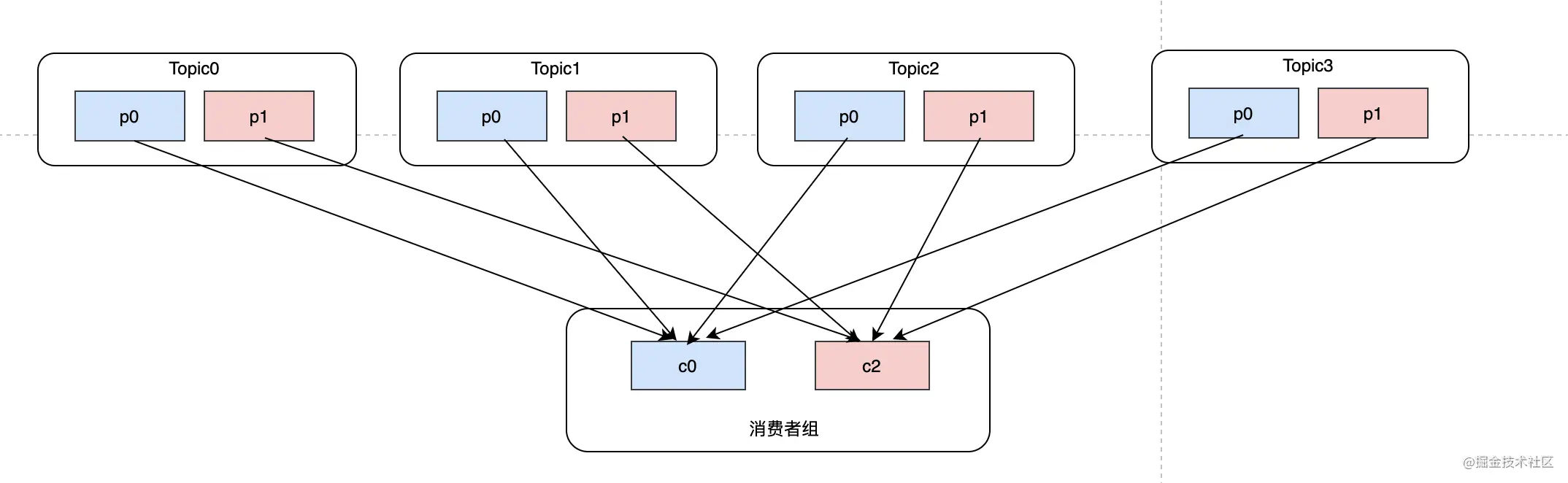
可以发现原来c0的topic1-p1分给了c2,原来c2的topic1-p0分给了c0。这种情况可能会造成重复消费问题,在消费者还没来得及提交的时候,发现分区已经被分给了一个新的消费者,那么新的消费者就会产生重复消费。但是从理论的角度来说,在c1退出之后,可以没必要去动c0和c2的分区,只需要把原本c1的分区瓜分给c0和c2即可,这就是sticky的做法:
最后
由于文案过于长,在此就不一一介绍了,这份Java后端架构进阶笔记内容包括:Java集合,JVM、Java并发、微服务、SpringNetty与 RPC 、网络、日志 、Zookeeper 、Kafka 、RabbitMQ 、Hbase 、MongoDB、Cassandra 、Java基础、负载均衡、数据库、一致性算法、Java算法、数据结构、分布式缓存等等知识详解。

本知识体系适合于所有Java程序员学习,关于以上目录中的知识点都有详细的讲解及介绍,掌握该知识点的所有内容对你会有一个质的提升,其中也总结了很多面试过程中遇到的题目以及有对应的视频解析总结。


大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码】](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)收录**















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









