







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Telegraf(收集数据) —> InfluxDB(存储数据) —> Chronograf(显示数据) —>Kapacitor(处理数据)

与传统数据库中的名词做比较
| influxDB中的名词 | 传统数据库中的概念 |
| database | 数据库 |
| measurement | 数据库中的表 |
| points | 表里面的一行数据 |
InfluxDB中独有的一些概念
Point由时间戳(time)、数据(field)、标签(tags)组成。
| Point属性 | 传统数据库中的概念 |
| time | 每个数据记录时间,是数据库中的主索引(会自动生成) |
| fields | 各种记录值(没有索引的属性)也就是记录的值:温度, 湿度 |
| tags | 各种有索引的属性:地区,海拔 |
1.2、Windows 下的 InfluxDB 安装和运行
1.2.1、解压后修改配置文件 influxdb.conf
网络端口说明:
InfluxDB默认使用以下网络端口:
- TCP端口 2003 用于 向 InfluxDB写数据(jmeter通过2003端口连)
- TCP端口 8086 用于 从 InfluxDB读数据(grafana通过8086端口连)
- TCP端口 8088 用于RPC服务以进行备份和还原
- 除了上面的端口,InfluxDB配置文件还提供了多个可能需要自定义端口的插件。
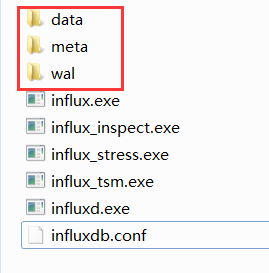
(1)新建3个文件夹,并修改3个路径(注意:Windows下 路径必须用双斜杠"\",否则启动报错)

(2)修改 graphite 部分
[[graphite]]
enabled = true
database = "jmeter"
bind-address = ":2003"
protocol = "tcp"
consistency-level = "one"
(3)修改 http 部分 (第4行那几个小星星不知道啥意思,反正官网是这么写的)
[http]
enabled = true
bind-address = ":8086"
auth-enabled = true # ✨
log-enabled = true
write-tracing = false
pprof-enabled = false
https-enabled = false
1.2.2、命令行启动
CMD到 influxdb 的目录下,直接命令 influxd -config influxdb.conf 启动。
【注意:不能直接 双击 influxd.exe 启动,那样的话刚才的配置是无效的,会造成 jmeter写入influxdb 时报错,参考:https://blog.csdn.net/qq_35304570/article/details/81290072。这个低级错误困扰了我半天的时间】
1.2.3、influxdb 连接测试
双击 influx.exe,打开命令行窗口,依次执行以下命令:
【注意:由于配置文件中开启了登录授权,数据库连接上之后,必须首先创建用户并授权,否则一切操作无效。这里也困扰了我半天的时间】
CREATE USER admin WITH PASSWORD 'admin' WITH ALL PRIVILEGES
auth admin admin
CREATE DATABASE jmeter
show databases
use jmeter
show measurements
执行最后一个命令,命令行界面显示为空,当前还没有数据。
2、配置 jmeter
jmeter 下载地址: http://jmeter.apache.org/download_jmeter.cgi
2.1、添加线程组

2.2、添加一个Java请求
方便测试(因为想偷懒,Java请求我什么都不用写,直接运行就能成功)

2.3、添加结果树,方便查看结果

2.4、添加 “Backend Listener”
配置如图:


2.5、运行测试
上述配置好之后,点击运行测试。
(1)结果树页面:

(2) influx.exe 命令行界面,运行 show measurements ,可看到数据:

3、安装 Grafana
【本部分主要参考文章:https://blog.csdn.net/zuozewei/article/details/82911173】
Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。它主要有以下六大特点:
1、展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
2、数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等;
3、通知提醒:以可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过Slack、PagerDuty等获得通知;
4、混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
5、注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记;
6、过滤器:Ad-hoc过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询。
官网下载地址:Grafana
3.1、安装并运行
比起前两者,安装相对简单。
我使用的是 msi 安装文件,【注意:安装之前关闭 360 杀毒(如果用的是压缩包,直接解压即可)】
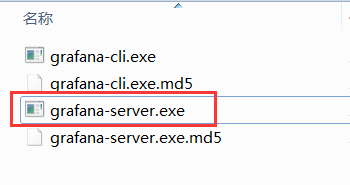
安装好之后,进入 bin 目录,直接双击 grafana-server.exe 运行即可。
通过 msi 文件安装的程序自动进入 服务列表,作为系统服务自动启动,不需要再双击 EXE 运行
3.2、配置数据源
(1)用浏览器 打开:http://localhost:3000/ 。输入: admin admin 登录

(2)配置数据源:按照下图中所示操作


下图红框中是必填项:


3.3、配置图表
配置图表有两种方式,一种是利用系统提供的图表自己组合,另一种是导入官方提供的图表展示模板。
3.3.1、自定义图表


下图中右边红框的两个地方配置好

指标说明
线程数/用户相关指标
test.minAT-Min active threads:最小活跃线程数
test.maxAT-Max active threads:最大活跃线程数
test.meanAT-Mean active threads:活跃线程数
test.startedT-Started threads:启动线程数
test.endedT-Finished threads:结束线程数
响应时间指标
.ok.count:采样器的成功响应数
.h.count:每秒点击数
.ok.min:采样器成功最短响应时间
.ok.max:采样器成功最长响应时间
.ok.avg:采样器成功平均响应时间
.ok.pct:采样器成功响应百分比
.ko.count:采样器失败响应数
.ko.min:采样器失败的响应最短时间
.ko.max:采样称失败最长响应时间
.ko.avg:采样器失败平均响应时间
.ko.pct:采样器失败响应百分比
.a.count:采样器响应数(ok.count和ko.count的总和)
.a.min:采样器最小响应时间(ok.count和ko.count的最小值)
.a.max:采样器最大响应时间(ok.count和ko.count的最大值)
.a.avg:采样器平均响应时间(ok.count和ko.count的平均值)
.a.pct:采样器响应百分比(根据和失败样本的总数计算)
Backend Listener的默认百分位设置为“90;95;99”,即百分位数为90%,95%和99%。
Graphite使用点(“.”)去拆分的元素,这可能与十进制百分位值混淆。JMeter转换任何此类值,用下划线(“ - ”)替换点(“.”)。例如,“99.9 ”变为“99_9 ”
默认情况下,JMeter发送在samplerName“all”下累计的所有采样器的指标。 如果配置了 BackendListenerSamplersList,那么JMeter还会发送匹配样本名称的指标,前提是配置 summaryOnly=true
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
285907136)]
[外链图片转存中…(img-T5lnJFk7-1715285907136)]
[外链图片转存中…(img-i3DIOasg-1715285907137)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









