







计算key="name"的hash值二进制结果是1100110111101010111000转成十进制为3373752
进制在线转换:https://c.runoob.com/front-end/58/
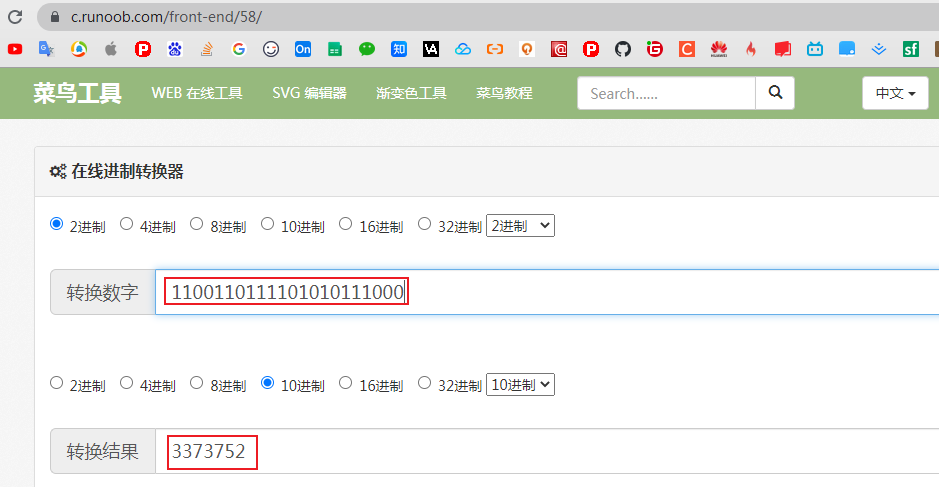
即计算key="name"的hash值为3373752,也可以debug断点往后查看hash值刚好也是这个值
第三步曲:根据hash值计算出哈希表数组index下标
公式:i = (n - 1) & hash
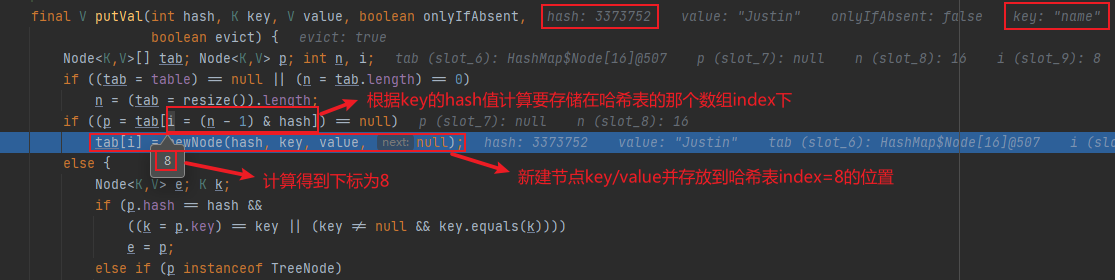
这里公式(n - 1) & hash 用到了&按位与运算(都为1则得1),奥妙之处在于n表示HashMap中的数组容量大小,并且刚好是16,32,64…2的次方,这种情况其实是等效于 hash % n 取模计算出的数组index下标值,并且下标不会超过容量(n-1)即能够保证不会数组下标越界
但是HashMap这里没有使用%取模,而是使用位运算,直接对内存数据进行操作,效率最高,如果使用%取模需要先将内存数据转成十进制再进行运算,多了这部分的性能开销,效率会变低
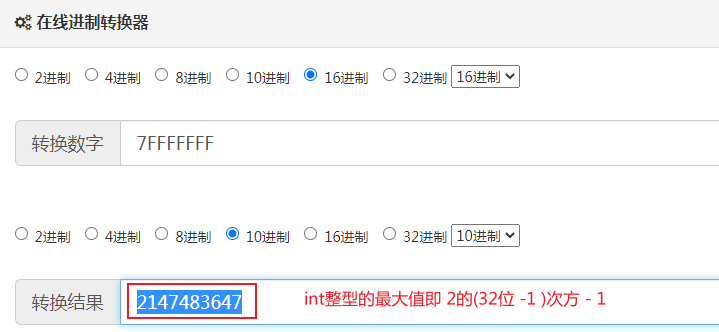
HashTable底层倒是用的%取模,hash值与十六进制0x7FFFFFFF做按位与运算目的是为了保证hash值始终是正数
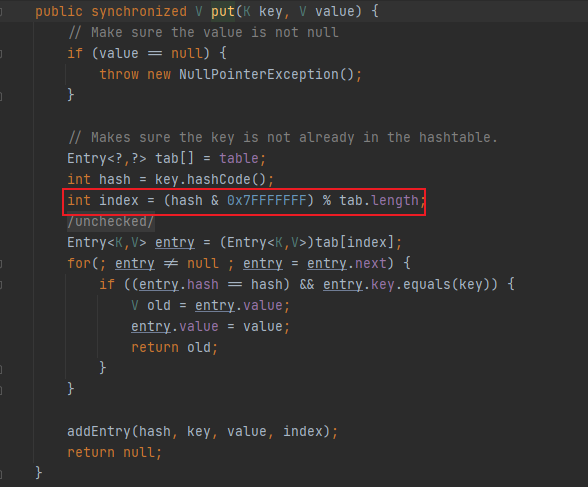
有的小伙伴可能会问了,使用%取模计算,那这里为啥HashTable还在用,我想说的是其实也可以优化,只不过HashTable本身就是主打synchronized线程安全,也就不考虑优化%取模为位运算了吧
第四步曲:将元素节点保存到哈希表指定数组index下标
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
//该位置首次添加节点,则直接新建节点添加
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
//如果节点是红黑树,调用方法进行添加元素
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果节点是链表,则遍历链表
for (int binCount = 0; ; ++binCount) {
//遍历链表到最后一个节点
if ((e = p.next) == null) {
//新建节点进行添加
p.next = newNode(hash, key, value, null);
//如果遍历指定位置的链表现有节点已经是大于等于8个了
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//则当前节点,需要通过该方法进行添加
//如果数组容量大于64,该过程会进行链表转化为红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break; 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5363
5363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









