







dmoz dumpfilter:抓到过的request对象指纹
(指纹集合,存放的是已经进入scheduler队列的request对象的指纹,指纹默认由请求方法,url和请求体组成)
dumpfilter的数量减去request的数量是已经抓爬取过的数量
关闭redispipeline之后,redis数据库中数据量变化:
- dmoz:requests 有变化(变多或者变少或者不变)
- dmoz:dupefilter 变多
- dmoz:items 不变
redispipeline中仅仅实现了item数据存储到redis的过程,我们可以新建一个pipeline(或者修改默认的ExamplePipeline),让数据存储到任意地方,但是权重应该小于redis存储的pipline。
scrapy-redis 源码详解
scrapy redis 如何生成指纹的?
import hashlib
f = hashlib.hsa1()
f.update(url.encode())
f.hexdigest()
scrapy-redis 判断request对象是否入队
def enqueue_request(self, request):
if not request.dont_filter and self.df.request_seen(request):
# dont_filter=False Ture True request指纹已经存在 #不会入队
# dont_filter=False Ture False request指纹已经存在 全新的url #会入队
# dont_filter=Ture False #会入队
self.df.log(request, self.spider)
return False
if self.stats:
self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider)
self.queue.push(request)
return True
- dont_filter = True ,构造请求的时候,把dont_filter置为True,该url会被反复抓取(url地址对应的内容会更新的情况)
- 一个全新的url地址被抓到的时候,构造request请求
- url地址在start_urls中的时候,会入队,不管之前是否请求过
- 构造start_url地址的请求时候,dont_filter = True
scrapy-redis如何去重
fp = hashlib.sha1()
fp.update(to_bytes(request.method)) #请求方法
fp.update(to_bytes(canonicalize_url(request.url))) #请求链接
fp.update(request.body or b'') # 请求体
return fp.hexdigest()
- 使用sha1加密request得到指纹
- 把指纹存在redis的集合中
- 下一次新来一个request,同样的方式生成指纹,判断指纹是否存在reids的集合中
判断数据是否存在redis的集合中,不存在插入
added = self.server.sadd(self.key, fp)
return added != 0
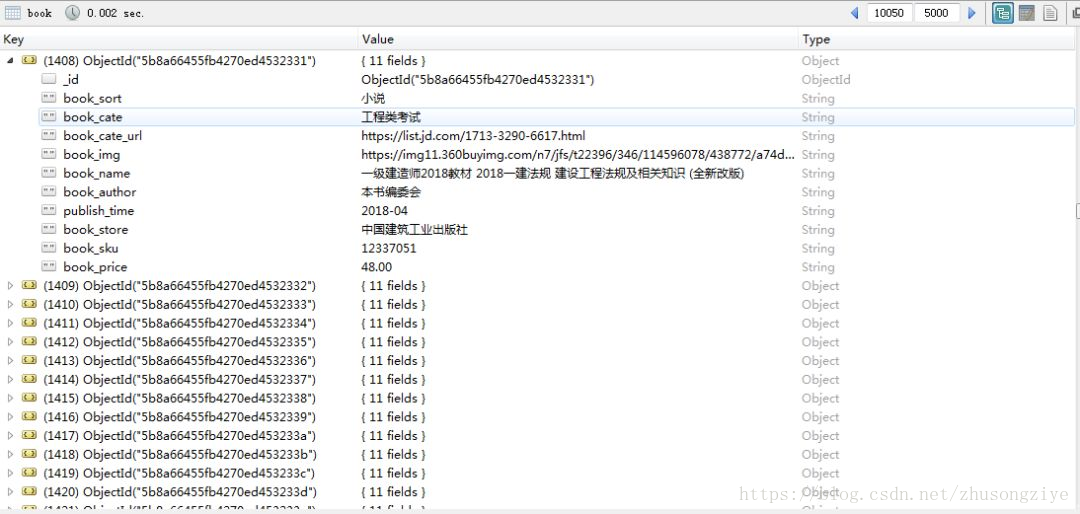
scrapy-redis实战京东图书
爬取结果截图
页面分析
分析分类聚合页
打开待爬取页面:
https://book.jd.com/booksort.html
如下图:
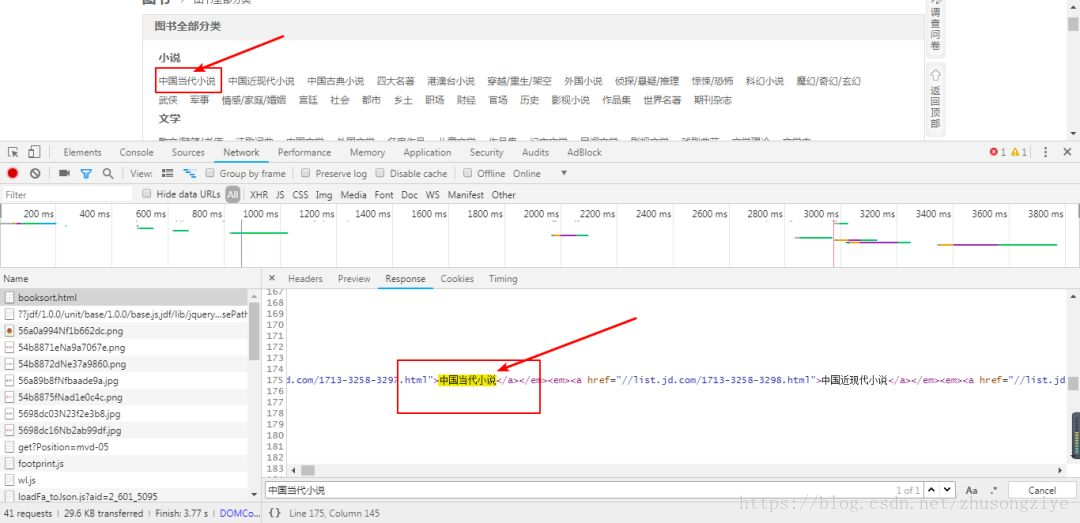
分析分类聚合页
查看页面源代码,发现待爬取的内容存在其中,所以我们可以通过分析源码写出提取相应字段的xpath。
def parse(self, response):
dl_list = response.xpath("//div[@class='mc']/dl/dt")
for dl in dl_list:
item = JdbookspiderItem()
item['book_sort'] = dl.xpath("./a/text()").extract_first()
em_list = dl.xpath("./following-sibling::dd/em")
for em in em_list:
item['book_cate'] = em.xpath("./a/text()").extract_first()
item['book_cate_url'] = em.xpath("./a/@href").extract_first()
if item['book_cate_url'] is not None:
item['book_cate_url'] = 'https:' + item['book_cate_url']
yield scrapy.Request(
item['book_cate_url'],
callback=self.parse_cate_url,
meta={"item": deepcopy(item)}
)
通过抓取分类页面分类链接,我们可以爬取到分类下的书籍列表页,这个页面包含书籍的全部信息,同样是可以使用xpath解析出来的。
分析书籍列表页
通过分析列表页的请求,可以发下列表页的请求重定向到了一个新的链接,所以我们只需要分析新请求链接的响应即可,scrapy可以自动帮我们执行重定向的操作。
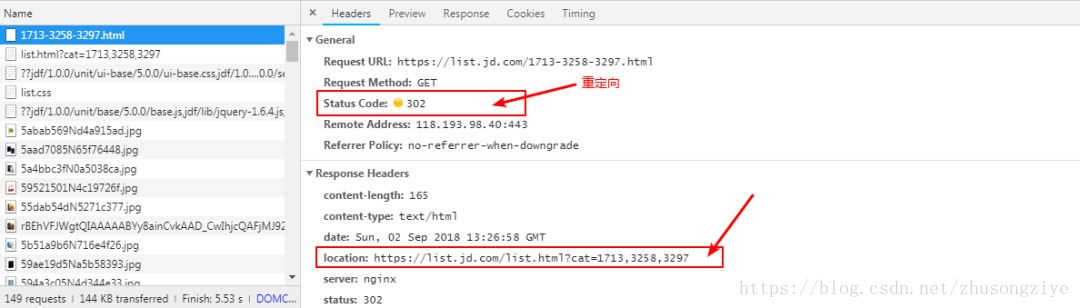
页面重定向分析
分析书籍列表页,可以发现列表页除了价格字段外其余字段都可以在链接的响应中提取到。
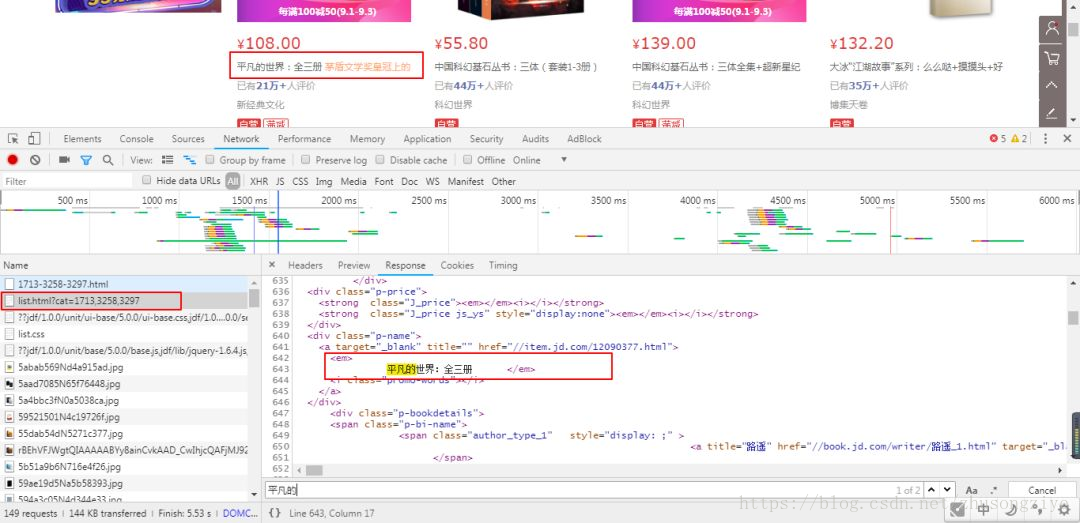
书籍列表页分析
所以我们只需要找到价格字段的请求,就可以爬取到书籍的全部字段了。我们可以直接在相应中查找价格以查看是否有相关的响应。
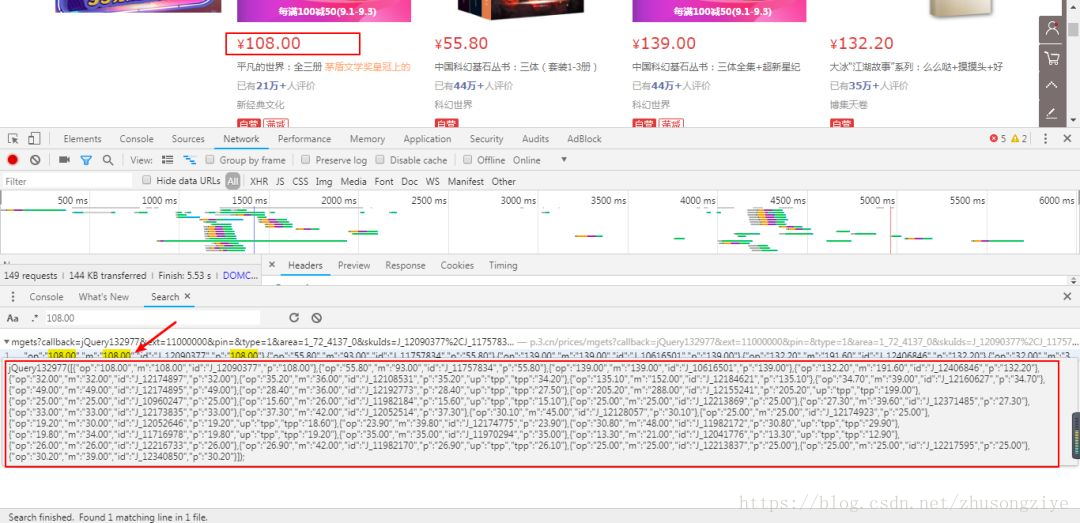
书籍价格分析1
查找结果如上所示,根据我们查找到的结果,我试着请求一下对应的链接,很幸运这里返回的是json字符串。

书籍价格分析2
根据以上分析我们可以写出相应的分析代码:
def parse_cate_url(self, response):
item = response.meta["item"]
li_list = response.xpath("//div[@id='plist']/ul/li")
for li in li_list:
item['book_img'] = li.xpath(".//div[@class='p-img']//img/@src").extract_first()
if item['book_img'] is None:
item['book_img'] = li.xpath(".//div[@class='p-img']//img/@data-lazy-img").extract_first()
item['book_img'] = "https:" + item['book_img'] if item['book_img'] is not None else None
item['book_name'] = li.xpath(".//div[@class='p-name']/a/em/text()").extract_first().strip()
item['book_author'] = li.xpath(".//span[@class='author_type_1']/a/text()").extract_first()
item['publish_time'] = li.xpath(".//span[@class='p-bi-date']/text()").extract_first().strip()
item['book_store'] = li.xpath(".//span[@class='p-bi-store']/a/@title").extract_first().strip()
item['book_sku'] = li.xpath("./div/@data-sku").extract_first()
yield scrapy.Request(
'https://p.3.cn/prices/mgets?skuIds=J_{}'.format(item['book_sku']),
callback=self.parse_book_price,
meta={"item": deepcopy(item)}
)
def parse_book_price(self, response):
item = response.meta["item"]
item['book_price'] = json.loads(response.body.decode())[0]["op"]
yield item
构建下一页请求
这里就比较简单,对比最后一页与其他页,发现最后一页是没有下一页链接的,根据以上分析可以成功构建相应代码:
# 下一页地址构建
next_url = response.xpath("//a[@class='pn-next']/@href")
if next_url:
next_url = urllib.parse.join(response.url, next_url)
yield scrapy.Request(
next_url,
callback=self.parse_cate_url,
meta={"item": item}
)
数据入库
class JdbookspiderPipeline(object):
def process_item(self, item, spider):
if isinstance(item, JdbookspiderItem):
print(item)
collection.insert(dict(item))

**感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:**
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里无偿获取](https://bbs.csdn.net/topics/618317507)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









