







 本文主要介绍了Python爬虫的基础工作流程,包括发起请求、获取响应、解析内容和保存数据。强调了合法合规爬取的重要性,特别是尊重网站的Robots协议。同时,分享了如何接单的经验,推荐了一些接单平台,并给出了接单时应注意的事项和避免的风险。
本文主要介绍了Python爬虫的基础工作流程,包括发起请求、获取响应、解析内容和保存数据。强调了合法合规爬取的重要性,特别是尊重网站的Robots协议。同时,分享了如何接单的经验,推荐了一些接单平台,并给出了接单时应注意的事项和避免的风险。
2)爬虫的工作流程
简记为“爬虫四部曲”;
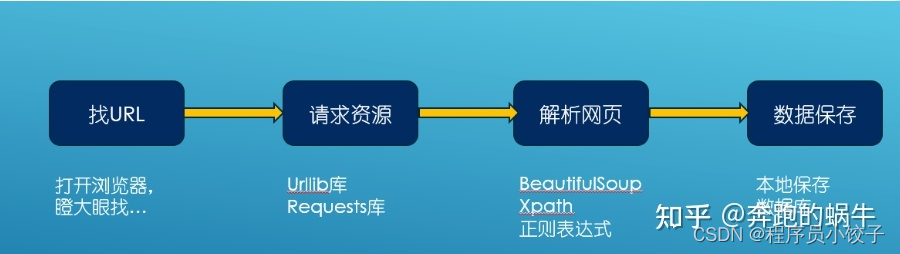
① 发起请求
使用http库向目标站点发起请求,即发送一个Request;
Request包含:请求头、请求体等;
如果只进行基本的爬虫网页抓取,urllib库足够用,Requests使用起来更简洁,自带json解析器,应付大多数的静态网页爬取问题不大。
涉及到动态网页抓取的话就要用到Selenium了,通常配合PhantomJS使用,,Selenium+PhantomJS可以抓取那些使用JS加载数据的网页。
② 获取响应内容
如果服务器能正常响应,则会得到一个Response;
Response包含:html、json、图片、视频等;
③ 解析内容
解析html数据:正则表达式、第三方解析库如Beautifulsoup、pyquery等;
解析json数据:json模块
解析二进制数据:以b的方式写入文件
个人一般情况下会用bs4,bs4无法满足就用正则。
正则一般用来满足特殊需求、以及提取其他解析器提取不到的数据,re速度比较快,但是写正则比较麻烦。
前端基础比较扎实的,用pyquery是最方便的,当然了,自己哪个用着方便就用哪个,无需纠结。
④ 保存数据
需要用到数据库;
小规模数据:可以使用txt文件、json文件、csv文件等方式来保存文件;
大规模数据:就需要使用mysql、mongodb、redis等数据库;
这步比较简单,掌握主流的数据库使用就差不多了。
1.如果是对爬虫这个领域很感兴趣的可以去听听免费的公开课,看看自己的学习天赋如何,下方大家可以微信扫描下方CSDN官方认证二维码免费领取
2.爬虫学习资料下方也有整理一部分(有视频教程,文档,写好的代码文件,以及一些爬虫所需要的软件安装包),有需要的可以下方自提

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5228
5228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









