







点击它,再点击右边的【Cookies】就可以看到请求头里的 cookie 情况。

**cookie分析:**
因为转存是登录后的操作,所以需要模拟登录状态,将与登录有关的 cookie 设置在请求头里。我们继续使用【控制变量法】,先将浏览器里关于百度的 cookie 全部删除(在右上角的设置里面,点击【隐私】,移除cookies。具体做法自己百度吧。)
然后登录,右上角进入浏览器设置->隐私->移除cookie,搜索 "bai" 观察 cookie 。这是所有跟百度相关的 cookie ,一个个删除,删一个刷新一次百度的页面,直到删除了**BDUSS** ,刷新后登录退出了,所以得出结论,它就是与登录状态有关的 cookie 。
同理,删除掉 **STOKEN** 后,进行转存操作会提示重新登录。所以,这两个就是转存操作所必须带上的 cookie 。
弄清楚了 cookie 的情况,可以像下面这样构造请求头。
def init(self,bduss,stoken,bdstoken):
self.bdstoken = bdstoken
self.headers = {
‘Accept’: ‘/’,
‘Accept-Encoding’: ‘gzip, deflate, br’,
‘Accept-Language’: ‘zh-CN,zh;q=0.8’,
‘Connection’: ‘keep-alive’,
‘Content-Length’: ‘161’,
‘Content-Type’: ‘application/x-www-form-urlencoded; charset=UTF-8’,
‘Cookie’: ‘BDUSS=%s;STOKEN=%s;’ % (bduss, stoken),
‘Host’: ‘pan.baidu.com’,
‘Origin’: ‘https://pan.baidu.com’,
‘Referer’: ‘https://pan.baidu.com/s/1dFKSuRn?errno=0&errmsg=Auth%20Login%20Sucess&&bduss=&ssnerror=0’,
‘User-Agent’: self.pro.get_user_agent(),# 作为应对反爬虫机制的策略,这是博主写的一个随机抽取user_agent的方法,你也可以自己到网上去搜集一些,写一个随机方法。
‘X-Requested-With’: ‘XMLHttpRequest’,
}
除了上面说到的两个 cookie ,其他的请求头参数可以参照手动转存时抓包的请求头。这两个 cookie 预留出来做参数的原因是 cookie 都是有生存周期的,过期了需要更新,不同的账号登录也有不同的 cookie 。
**参数分析:**
接下来分析参数,点击【Cookies】右边的【Params】查看参数情况。如下:

上面的query string(也就是?后跟的参数)里,除了框起来的shareid、from、bdstoken需要我们填写以外,其他的都可以不变,模拟请求的时候直接抄下来。
前两个与分享的资源有关,bdstoken与登录的账号有关。下面的form data里的两个参数分别是资源在分享用户的网盘的所在目录和刚刚我们点击保存指定的目录。
所以,需要我们另外填写的参数为:**shareid、from、bdstoken、filelist 和 path**,bdstoken 可以手动转存抓包找到,path 根据你的需要自己定义,前提是你的网盘里有这个路径。其他三个需要从分享链接里爬取,这个将在后面的**【爬取shareid、from、filelist,发送请求转存到网盘】**部分中进行讲解。
搞清楚了参数的问题,可以像下面这样构造转存请求的 url 。
def transfer(self,share_id,uk,filelist_str,path_t_save):# 需要填写的参数,分别对应上图的shareid、from、filelist 和 path
# 通用参数
ondup = “newcopy”
async = “1”
channel = “chunlei”
clienttype = “0”
web = “1”
app_id = “250528”
logid = “你的logid”
url_trans = “https://pan.baidu.com/share/transfer?shareid=%s”
“&from=%s”
“&ondup=%s”
“&async=%s”
“&bdstoken=%s”
“&channel=%s”
“&clienttype=%s”
“&web=%s”
“&app_id=%s”
“&logid=%s” % (share_id, uk, ondup, async, self.bdstoken, channel, clienttype, web, app_id, logid)
form_data = {
‘filelist’: filelist_str,
‘path’: path_t_save,
}
proxies = {‘http’: self.pro.get_ip(0, 30, u’国内’)}# 为了应对反爬虫机制,这里用了代理,稍后做解释
response = requests.post(url_trans, data=form_data, proxies = proxies,headers=self.headers)
print response.content
jsob = json.loads(response.content)
if “errno” in jsob:
return jsob[“errno”]
else:
return None
## 爬取shareid、from、filelist,发送请求转存到网盘
https://pan.baidu.com/s/1jImSOXg
以上面这个资源链接为例(随时可能被河蟹,但是没关系,其他链接的结构也是一样的),我们先用浏览器手动访问,F12 打开控制台先分析一下源码,看看我们要的资源信息在什么地方。控制台有搜索功能,直接搜 “shareid”。
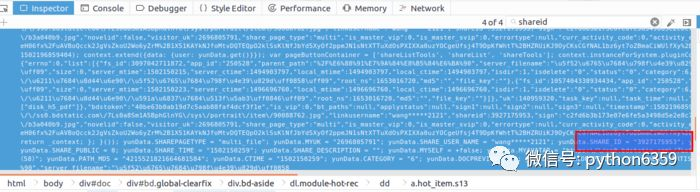
定位到4个shareid,前三个与该资源无关,是其他分享资源,最后一个定位到该 html 文件的最后一个<script></script>标签块里。双击后可以看到格式化后的 js 代码,可以发现我们要的信息全都在里边。如下节选:
yunData.SHAREPAGETYPE = “multi_file”;
yunData.MYUK = “”;
yunData.SHARE_USER_NAME = “wang*****2121”;
yunData.SHARE_ID = “3927175953”;
yunData.SIGN = “7f166e9b5cf54486074ccce2fc0548e8aa50bdfb”;
yunData.sign = “7f166e9b5cf54486074ccce2fc0548e8aa50bdfb”;
yunData.TIMESTAMP = “1502175170”;
yunData.SHARE_UK = “140959320”;
yunData.SHARE_PUBLIC = 0;
yunData.SHARE_TIME = “1502150259”;
yunData.SHARE_DESCRIPTION = “”;
yunData.MYSELF = +false;
yunData.MYAVATAR = “”;
yunData.NOVELID = “”;
yunData.FS_ID = “3097042711872”;
yunData.FILENAME = “归来的福丹芝(58)”;
yunData.PATH = “/我的资源/归来的福丹芝(58)”;
yunData.PATH_MD5 = “4215521821664681584”;
yunData.CTIME = “1502150259”;
yunData.CATEGORY = “6”;
yunData.DOCPREVIEW = “”;
yunData.IS_BAIDUSPIDER = “”;
yunData.ARTISTNAME = “”;
yunData.ALBUMTITLE = “”;
yunData.TRACKTITLE = “”;
yunData.FILEINFO = [{“fs_id”:3097042711872,“app_id”:“250528”,“parent_path”:“%2F%E6%88%91%E7%9A%84%E8%B5%84%E6%BA%90”,“server_filename”:“归来的福丹芝(58)”,“size”:0,“server_mtime”:1502150215,“server_ctime”:1494903797,“local_mtime”:1494903797,“local_ctime”:1494903797,“isdir”:1,“isdelete”:“0”,“status”:“0”,“category”:6,“share”:“0”,“path_md5”:“4215521821664681584”,“delete_fs_id”:“0”,“extent_int3”:“0”,“extent_tinyint1”:“0”,“extent_tinyint2”:“0”,“extent_tinyint3”:“0”,“extent_tinyint4”:“0”,“path”:“/我的资源/归来的福丹芝(58)”,“root_ns”:1653016720,“md5”:“”,“file_key”:“”},{“fs_id”:1057404338934434,“app_id”:“250528”,“parent_path”:“%2F%E6%88%91%E7%9A%84%E8%B5%84%E6%BA%90”,“server_filename”:“多样的儿媳(46)”,“size”:0,“server_mtime”:1502150223,“server_ctime”:1496696760,“local_mtime”:1496696760,“local_ctime”:1496696760,“isdir”:1,“isdelete”:“0”,“status”:“0”,“category”:6,“share”:“0”,“path_md5”:“5972282562760833248”,“delete_fs_id”:“0”,“extent_int3”:“0”,“extent_tinyint1”:“0”,“extent_tinyint2”:“0”,“extent_tinyint3”:“0”,“extent_tinyint4”:“0”,“path”:“/我的资源/多样的儿媳(46)”,“root_ns”:1653016720,“md5”:“”,“file_key”:“”}];
可以看到这两行
yunData.SHARE_ID = “3927175953”;
yunData.SHARE_UK = “140959320”; // 经过对比,这就是我们要的 “from”
yunData.PATH 只指向了一个路径信息,完整的 filelist 可以从 yunData.FILEINFO 里提取,它是一个 json ,list 里的信息是Unicode编码的,所以在控制台看不到中文,用Python代码访问并获取输出一下就可以了。
直接用request请求会收获 404 错误,可能是需要构造请求头参数,不能直接请求,这里博主为了节省时间,直接用selenium的webdriver来get了两次,就收到了返回信息。第一次get没有任何 cookie ,但是baidu 会给你返回一个BAIDUID ,在第二次 get 就可以正常访问了。
yunData.FILEINFO 结构如下,你可以将它复制粘贴到json.cn里,可以看得更清晰。
[{“fs_id”:3097042711872,“app_id”:“250528”,“parent_path”:“%2F%E6%88%91%E7%9A%84%E8%B5%84%E6%BA%90”,“server_filename”:“归来的福丹芝(58)”,“size”:0,“server_mtime”:1502150215,“server_ctime”:1494903797,“local_mtime”:1494903797,“local_ctime”:1494903797,“isdir”:1,“isdelete”:“0”,“status”:“0”,“category”:6,“share”:“0”,“path_md5”:“4215521821664681584”,“delete_fs_id”:“0”,“extent_int3”:“0”,“extent_tinyint1”:“0”,“extent_tinyint2”:“0”,“extent_tinyint3”:“0”,“extent_tinyint4”:“0”,“path”:“/我的资源/归来的福丹芝(58)”,“root_ns”:1653016720,“md5”:“”,“file_key”:“”},{“fs_id”:1057404338934434,“app_id”:“250528”,“parent_path”:“%2F%E6%88%91%E7%9A%84%E8%B5%84%E6%BA%90”,“server_filename”:“多样的儿媳(46)”,“size”:0,“server_mtime”:1502150223,“server_ctime”:1496696760,“local_mtime”:1496696760,“local_ctime”:1496696760,“isdir”:1,“isdelete”:“0”,“status”:“0”,“category”:6,“share”:“0”,“path_md5”:“5972282562760833248”,“delete_fs_id”:“0”,“extent_int3”:“0”,“extent_tinyint1”:“0”,“extent_tinyint2”:“0”,“extent_tinyint3”:“0”,“extent_tinyint4”:“0”,“path”:“/我的资源/多样的儿媳(46)”,“root_ns”:1653016720,“md5”:“”,“file_key”:“”}]

清楚了这三个参数的位置,我们就可以用正则表达式进行提取了。代码如下:
from wechat_robot.business import proxy_mine # 这是我自己的代理类,测试时可以先用本机ip
pro = proxy_mine.Proxy()
url = “https://pan.baidu.com/s/1jImSOXg”
driver = webdriver.Chrome()
print u"初始化代理…"
driver = pro.give_proxy_driver(driver)
def get_file_info(url):
driver.get(url)
time.sleep(1)
driver.get(url)
script_list = driver.find_elements_by_xpath(“//body/script”)
innerHTML = script_list[-1].get_attribute(“innerHTML”)# 获取最后一个script的innerHTML
pattern = ‘yunData.SHARE_ID = "(.?)“[\s\S]yunData.SHARE_UK = "(.?)”[\s\S]yunData.FILEINFO = (.?);[\s\S]’ # [\s\S]*可以匹配包括换行的所有字符,\s表示空格,\S表示非空格字符
srch_ob = re.search(pattern, innerHTML)
share_id = srch_ob.group(1)
share_uk = srch_ob.group(2)
file_info_jsls = json.loads(srch_ob.group(3))# 解析json
path_list = []
for file_info in file_info_jsls:
path_list.append(file_info[‘path’])
return share_id,share_uk,path_list
try:
print u"发送连接请求…"
share_id,share_uk,path_list = get_file_info(url)
except:
print u"链接失效了,没有获取到fileinfo…"
else:
print share_id
print share_uk
print path_list
爬取到了这三个参数,就可以调用之前的 transfer 方法进行转存了。
## 完整代码
# -- coding:utf-8 --
import requests
import json
import time
import re
from selenium import webdriver
from wechat_robot.business import proxy_mine
class BaiduYunTransfer:
headers = None
bdstoken = None
pro = proxy_mine.Proxy()
def init(self,bduss,stoken,bdstoken):
self.bdstoken = bdstoken
self.headers = {
‘Accept’: ‘/’,
‘Accept-Encoding’: ‘gzip, deflate, br’,
‘Accept-Language’: ‘zh-CN,zh;q=0.8’,
‘Connection’: ‘keep-alive’,
‘Content-Length’: ‘161’,
‘Content-Type’: ‘application/x-www-form-urlencoded; charset=UTF-8’,
‘Cookie’: ‘BDUSS=%s;STOKEN=%s;’ % (bduss, stoken),
‘Host’: ‘pan.baidu.com’,
‘Origin’: ‘https://pan.baidu.com’,
‘Referer’: ‘https://pan.baidu.com/s/1dFKSuRn?errno=0&errmsg=Auth%20Login%20Sucess&&bduss=&ssnerror=0’,
最后
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
👉Python所有方向的学习路线👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python必备开发工具👈
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

👉Python全套学习视频👈
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

👉实战案例👈
学python就与学数学一样,是不能只看书不做题的,直接看步骤和答案会让人误以为自己全都掌握了,但是碰到生题的时候还是会一筹莫展。
因此在学习python的过程中一定要记得多动手写代码,教程只需要看一两遍即可。

👉大厂面试真题👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









