







分享
这次面试我也做了一些总结,确实还有很多要学的东西。相关面试题也做了整理,可以分享给大家,了解一下面试真题,想进大厂的或者想跳槽的小伙伴不妨好好利用时间来学习。学习的脚步一定不能停止!

Spring Cloud实战

Spring Boot实战

面试题整理(性能优化+微服务+并发编程+开源框架+分布式)
1、开启binlog
(1)MySQL的 my.cnf 中配置:
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复如果订阅的是mysql的从库,需求增加配置让从库日志也写到binlog里面
log_slave_updates=1
(2)可以通过在 mysql 终端中执行以下命令判断配置是否生效:
进入mysql:
mysql -hlocalhost -uroot -p[密码]
查看log日志是否开启命令:
show variables like ‘log_bin’;
查看当前二进制日志记录格式:
show variables like ‘binlog_format’;

注意:
1. 以上截图是 ON 是开启状态 ,如果是OFF就是未开启,mysql数据库log-bin默认是不开启
2. canal需要的log日志格式为 ROW格式
2、授权账号权限
授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant:
CREATE USER canal IDENTIFIED BY ‘canal’;
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO ‘canal’@‘%’;
FLUSH PRIVILEGES;
二、单机部署
一、canal下载
下载地址:
https://github.com/alibaba/canal/releases/tag/canal-1.1.6-hotfix-1
二.can-admin部署
1. 解压到admin文件夹
tar -zxvf canal-admin-1.1.6.tar.gz -C admin
- 修改配置文件
vim conf/application.yml
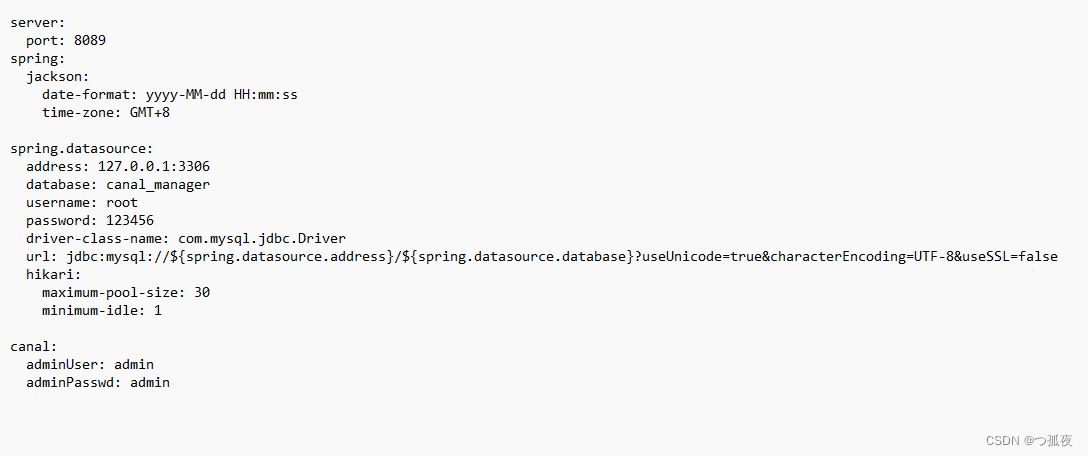
注意:(1)准备一个mysql数据库,执行admin下的canal_manager.sql为管理库
(2) 配置address、username、password为管理库地址、账号、密码 即可
- 启动admin服务
./bin/startup.sh
4.启动成功管理界面
初始账号/密码:admin/123456

以上界面代表admin部署成功,
三、canal-deployer部署
1. 解压到adeployer文件夹
tar -zxvf canal-deployer-1.1.6.tar.gz -C deployer
- 修改配置文件
删除原有canal.properties文件,修改canal_local.properties文件名为canal.properties
vim conf/canal.properties

注意:(1)修改manager为admin地址,账号密码默认即可
- 启动adeployer服务
./bin/startup.sh
启动成功日志不报错即可。
4.启动成功界面
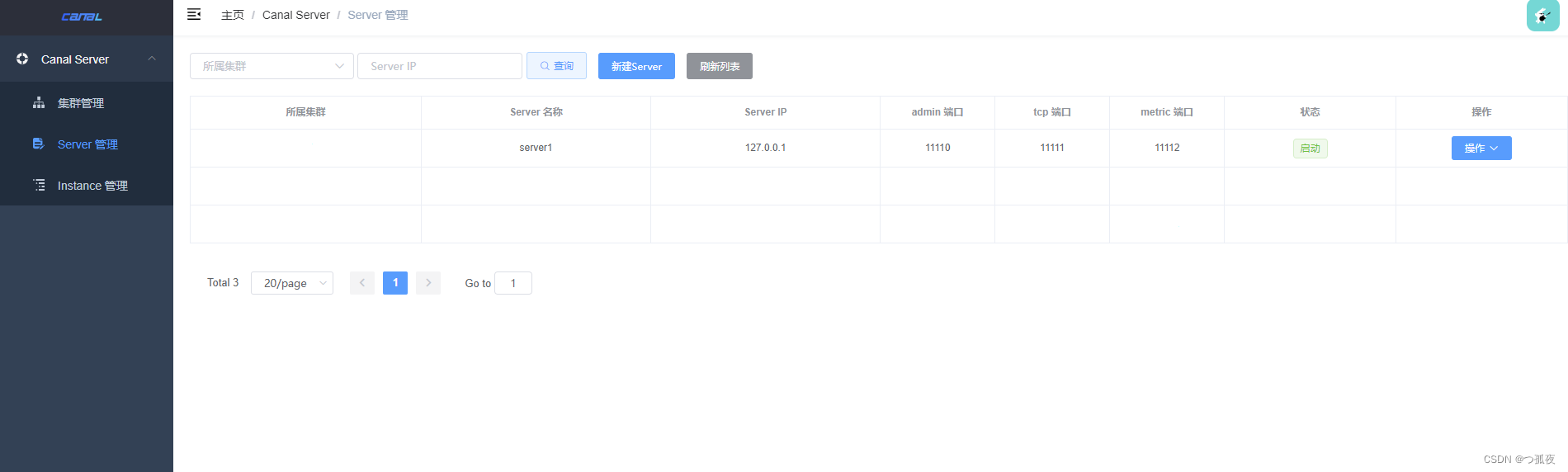
启动成功后即可在admin管理界面查看到server为启动状态
4.配置Instance实例

注意:Instance实例只需修改slaveId、address、username、password等数据库连接信息,多个实例的slaveId不能重复,且不能和mysql的slaveId重复
1.如果需要指定同步的binlog日志,配置:
canal.instance.master.journal.name 日志名称
canal.instance.master.position 日志偏移量
2.如果需要指定同步时间戳
canal.instance.master.timestamp 时间戳
四、canal-adapter部署
1. 解压到adapter文件夹
tar -zxvf canal-adapter-1.1.6.tar.gz -C adapter
- 修改配置文件
删除原有canal.properties文件,修改canal_local.properties文件名为canal.properties
vim conf/canal.properties
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_nullcanal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
batchSize: 500 #每次获取的数据大小,单位为 k
syncBatchSize: 1000 #每次同步的批数量
retries: 5 #重试次数,-1为无限次
timeout: 60000 #超时时间
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: #对应单机模式下的canal
# canal.tcp.zookeeper.hosts: # 对应集群模式下的zk地址, 如果配置了
canal.tcp.batch.size: 500 #每次获取的数据大小,单位为 k
#canal.tcp.username:
#canal.tcp.password:
srcDataSources:
defaultDS:
url: jdbc:mysql://localhost:3306/mysql?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: 123456
canalAdapters:
- instance: test # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
- name: es7 # es6 or es7
key: exampleKey # 配置key
hosts: http://localhost:9200 # 集群地址,逗号隔开
mode: rest # rest or transport
# security.auth: test:123456 # only used for rest mode
cluster.name: es7
3.配置查询sql
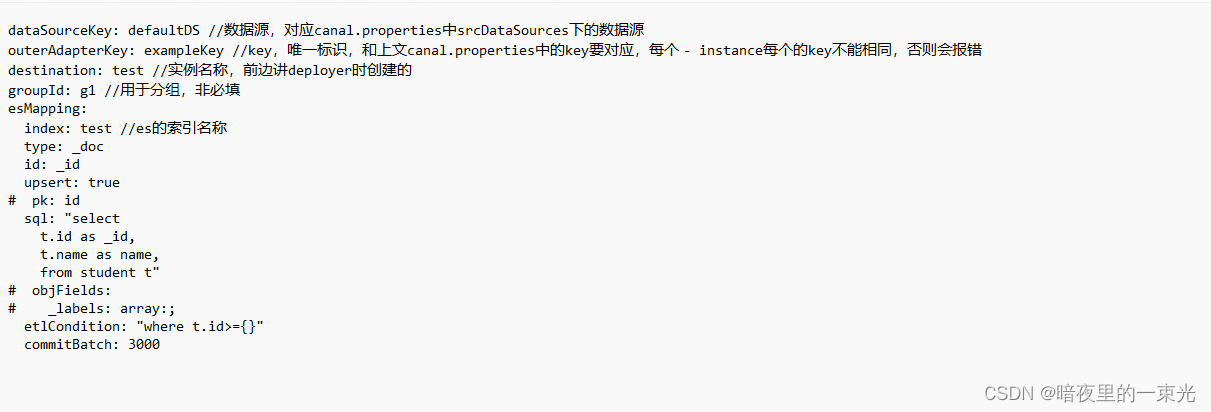
- 启动adapter服务
./bin/startup.sh
启动成功日志不报错即可。
以上即是单机模式下canal的配置部署了,一定要熟练掌握!
三、HA模式
单机模式多用于测试、练习等场景,在生产中多用HA模式保证高可用。基础的配置和搭建这里不再赘述,不懂得同学请先看单机部署。
首先准备3个服务器:
192.168.40.111
192.168.40.112
192.168.40.113
一、zookeeper部署
canal的HA 模式是以主从形式搭建,服务间调用时通过zookeeper获取地址,借助zookeepe做集群管理实现故障转移,当发生故障时集群间重新选主,集群节点推荐为3个。
1. 下载
https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.9.0/apache-zookeeper-3.9.0-bin.tar.gz
2. 解压
tar -zxvf apache-zookeeper-3.8.1-bin.tar -C zookeeper
3. 配置修改
1.添加配置文件
mv zoo_sample.cfg zoo.cfg
2. 创建data文件夹,修改dataDir路径:
mkdir zkData
3.修改配置文件
vim zoo.cfg
进入zoo.cfg文件:vim zoo.cfg
修改dataDir路径为
dataDir=/opt/zookeeper/zkData
添加集群信息:
server.1=192.168.40.111::3188:3288
server.2=192.168.40.112::3188:3288
server.3=192.168.40.113::3188:3288
- 添加服务器ID
在每个zookeeper的 zkData目录下创建一个 myid 文件,内容分别是1、2、3 。这个文件就是记录每个服务器的ID。
4. 启动服务
./bin/zkServer.sh start|stop|status|restart
5.设置开机自启
1.配置 Zookeeper 启动脚本
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME=‘opt/zookeeper’
case 1 i n s t a r t ) e c h o " − − − − − − − − − − z o o k e e p e r 启动 − − − − − − − − − − " 1 in start) echo "----------zookeeper启动----------" 1instart) echo"−−−−−−−−−−zookeeper启动−−−−−−−−−−" ZK_HOME/bin/zkServer.sh start
;;
stop)
echo “---------- zookeeper停止-----------”
Z K _ H O M E / b i n / z k S e r v e r . s h s t o p ; ; r e s t a r t ) e c h o " − − − − − − − − − − z o o k e e p e r 重启 − − − − − − − − − − − − " ZK\_HOME/bin/zkServer.sh stop ;; restart) echo "---------- zookeeper 重启------------" ZK_HOME/bin/zkServer.shstop;;restart) echo"−−−−−−−−−−zookeeper重启−−−−−−−−−−−−" ZK_HOME/bin/zkServer.sh restart
;;
status)
echo “---------- zookeeper 状态------------”
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo “Usage: $0 {start|stop|restart|status}”
esac
2. 设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper
3.启动Zookeeper
service zookeeper start
4. 查看当前状态
service zookeeper status
二、admin添加集群
集群多个zookeeper中间用逗号隔开

总结
对于面试还是要好好准备的,尤其是有些问题还是很容易挖坑的,例如你为什么离开现在的公司(你当然不应该抱怨现在的公司有哪些不好的地方,更多的应该表明自己想要寻找更好的发展机会,自己的一些现实因素,比如对于我而言是现在应聘的公司离自己的家更近,又或者是自己工作到达了迷茫期,想跳出迷茫期等等)

Java面试精选题、架构实战文档
整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~
你的支持,我的动力;祝各位前程似锦,offer不断!
中间用逗号隔开
总结
对于面试还是要好好准备的,尤其是有些问题还是很容易挖坑的,例如你为什么离开现在的公司(你当然不应该抱怨现在的公司有哪些不好的地方,更多的应该表明自己想要寻找更好的发展机会,自己的一些现实因素,比如对于我而言是现在应聘的公司离自己的家更近,又或者是自己工作到达了迷茫期,想跳出迷茫期等等)
[外链图片转存中…(img-wmJDmQWN-1715366571961)]
Java面试精选题、架构实战文档
整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~
你的支持,我的动力;祝各位前程似锦,offer不断!















 5092
5092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









