







2.当秘钥,iv偏移量,待加密的明文,字节长度不够16字节或者16字节倍数的时候需要进行补全。
- CBC模式需要重新生成AES对象,为了防止这类错误,我写代码无论是什么模式都重新生成AES对象。
5. 编码模式
前面说了,python中的 AES 加密解密,只能接受字节型(bytes)数据。而我们常见的 待加密的明文可能是中文,或者待解密的密文经过base64编码的,这种都需要先进行编码或者解码,然后才能用AES进行加密或解密。反正无论是什么情况,在python使用AES进行加密或者解密时,都需要先转换成bytes型数据。
我们以ECB模式针对中文明文进行加密解密举例:
from Crypto.Cipher import AES
password = b'1234567812345678' #秘钥,b就是表示为bytes类型
text = "好好学习天天向上".encode('gbk') #gbk编码,是1个中文字符对应2个字节,8个中文正好16字节
aes = AES.new(password,AES.MODE_ECB) #创建一个aes对象
# AES.MODE\_ECB 表示模式是ECB模式
print(len(text))
en_text = aes.encrypt(text) #加密明文
print("密文:",en_text) #加密明文,bytes类型
den_text = aes.decrypt(en_text) # 解密密文
print("明文:",den_text.decode("gbk")) # 解密后同样需要进行解码
输出:
16
密文: b'=\xdd8k\x86\xed\xec\x17\x1f\xf7\xb2\x84~\x02\xc6C'
明文: 好好学习天天向上
对于中文明文,我们可以使用encode()函数进行编码,将字符串转换成bytes类型数据,而这里我选择gbk编码,是为了正好能满足16字节,utf8编码是一个中文字符对应3个字节。这里为了举例所以才选择使用gbk编码。
在解密后,同样是需要decode()函数进行解码的,将字节型数据转换回中文字符(字符串类型)。
现在我们来看另外一种情况,密文是经过base64编码的(这种也是非常常见的,很多网站也是这样使用的),我们用 http://tool.chacuo.net/cryptaes/ 这个网站举例子:
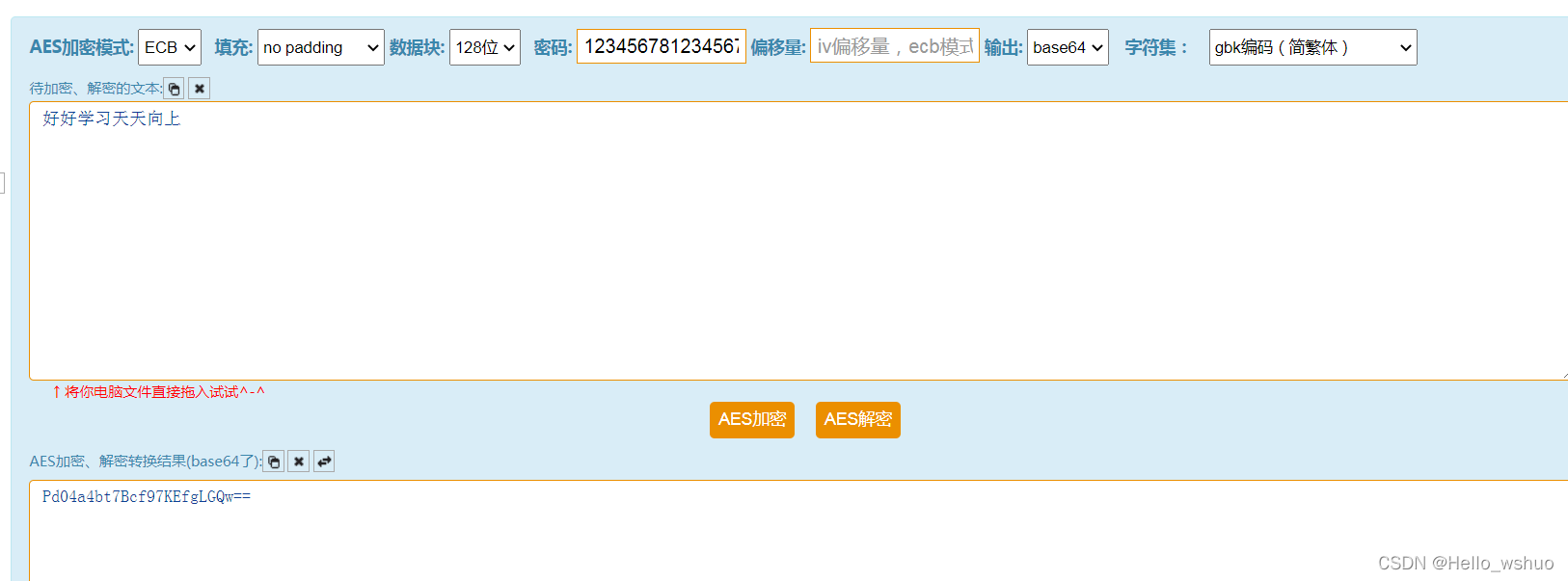
模式:ECB
密码: 1234567812345678
字符集:gbk编码
输出: base64
我们来写一个python 进行aes解密:
from Crypto.Cipher import AES
import base64
password = b'1234567812345678'
aes = AES.new(password,AES.MODE_ECB)
en_text = b"Pd04a4bt7Bcf97KEfgLGQw=="
en_text = base64.decodebytes(en_text) #将进行base64解码,返回值依然是bytes
den_text = aes.decrypt(en_text)
print("明文:",den_text.decode("gbk"))
输出:
明文: 好好学习天天向上
这里的 b"Pd04a4bt7Bcf97KEfgLGQw==" 是一个bytes数据, 如果你传递的是一个字符串,你可以直接使用 encode()函数 将其转换为 bytes类型数据。
from Crypto.Cipher import AES
import base64
password = b'1234567812345678'
aes = AES.new(password,AES.MODE_ECB)
en_text = "Pd04a4bt7Bcf97KEfgLGQw==".encode() #将字符串转换成bytes数据
en_text = base64.decodebytes(en_text) #将进行base64解码,参数为bytes数据,返回值依然是bytes
den_text = aes.decrypt(en_text)
print("明文:",den_text.decode("gbk"))
因为无论是 utf8 和 gbk 编码,针对英文字符编码都是一个字符对应一个字节,所以这里**encode()**函数主要作用就是转换成bytes数据,然后使用base64进行解码。
hexstr,base64编码解码例子:
import base64
import binascii
data = "hello".encode()
data = base64.b64encode(data)
print("base64编码:",data)
data = base64.b64decode(data)
print("base64解码:",data)
data = binascii.b2a_hex(data)
print("hexstr编码:",data)
data = binascii.a2b_hex(data)
print("hexstr解码:",data)
输出:
base64编码: b'aGVsbG8='
base64解码: b'hello'
hexstr编码: b'68656c6c6f'
hexstr解码: b'hello'
这里要说明一下,有一些AES加密,所用的秘钥,或者IV向量是通过 base64编码或者 hexstr编码后的。针对这种,首先要进行的就是进行解码,都转换回 bytes数据,再次强调,python实现 AES加密解密传递的参数都是 bytes(字节型) 数据。
另外,我记得之前的 pycryptodome库,传递IV向量时,和明文时可以直接使用字符串类型数据,不过现在新的版本都必须为 字节型数据了,可能是为了统一好记。
6. 填充模式
前面我使用秘钥,还有明文,包括IV向量,都是固定16字节,也就是数据块对齐了。而填充模式就是为了解决数据块不对齐的问题,使用什么字符进行填充就对应着不同的填充模式
AES补全模式常见有以下几种:
| 模式 | 意义 |
|---|---|
| ZeroPadding | 用b’\x00’进行填充,这里的0可不是字符串0,而是字节型数据的b’\x00’ |
| PKCS7Padding | 当需要N个数据才能对齐时,填充字节型数据为N、并且填充N个 |
| PKCS5Padding | 与PKCS7Padding相同,在AES加密解密填充方面我没感到什么区别 |
| no padding | 当为16字节数据时候,可以不进行填充,而不够16字节数据时同ZeroPadding一样 |
这里有一个细节问题,我发现很多文章说的也是不对的。
ZeroPadding填充模式的意义:很多文章解释是当为16字节倍数时就不填充,然后当不够16字节倍数时再用字节数据0填充,这个解释是不对的,这解释应该是no padding的,而ZeroPadding是不管数据是否对其,都进行填充,直到填充到下一次对齐为止,也就是说即使你够了16字节数据,它会继续填充16字节的0,然后一共数据就是32字节。
这里可能会有一个疑问,为什么是16字节 ,其实这个是 数据块的大小,网站上也有对应设置,网站上对应的叫128位,也就是16字节对齐,当然也有192位(24字节),256位(32字节)。
本文在这个解释之后,后面就说数据块对齐问题了,而不会再说16字节倍数了。
除了no padding 填充模式,剩下的填充模式都会填充到下一次数据块对齐为止,而不会出现不填充的问题。
PKCS7Padding和 PKCS5Padding需要填充字节对应表:
| 明文长度值(mod 16) | 添加的填充字节数 | 每个填充字节的值 |
|---|---|---|
| 0 | 16 | 0x10 |
| 1 | 15 | 0x0F |
| 2 | 14 | 0x0E |
| 3 | 13 | 0x0D |
| 4 | 12 | 0x0C |
| 5 | 11 | 0x0B |
| 6 | 10 | 0x0A |
| 7 | 9 | 0x09 |
| 8 | 8 | 0x08 |
| 9 | 7 | 0x07 |
| 10 | 6 | 0x06 |
| 11 | 5 | 0x05 |
| 12 | 4 | 0x04 |
| 13 | 3 | 0x03 |
| 14 | 2 | 0x02 |
| 15 | 1 | 0x01 |
这里可以看到,当明文长度值已经对齐时(mod 16 = 0),还是需要进行填充,并且填充16个字节值为0x10。ZeroPadding填充逻辑也是类似的,只不过填充的字节值都为0x00,在python表示成 b'\x00'。
填充完毕后,就可以使用 AES进行加密解密了,当然解密后,也需要剔除填充的数据,无奈Python这些步骤需要自己实现(如果有这样的库还请评论指出)。
7.python的完整实现
from Crypto.Cipher import AES
import base64
import binascii
# 数据类
class MData():
def \_\_init\_\_(self, data = b"",characterSet='utf-8'):
# data肯定为bytes
self.data = data
self.characterSet = characterSet
def saveData(self,FileName):
with open(FileName,'wb') as f:
f.write(self.data)
def fromString(self,data):
self.data = data.encode(self.characterSet)
return self.data
def fromBase64(self,data):
self.data = base64.b64decode(data.encode(self.characterSet))
return self.data
def fromHexStr(self,data):
self.data = binascii.a2b_hex(data)
return self.data
def toString(self):
return self.data.decode(self.characterSet)
def toBase64(self):
return base64.b64encode(self.data).decode()
def toHexStr(self):
return binascii.b2a_hex(self.data).decode()
def toBytes(self):
return self.data
def \_\_str\_\_(self):
try:
return self.toString()
except Exception:
return self.toBase64()
### 封装类
class AEScryptor():
def \_\_init\_\_(self,key,mode,iv = '',paddingMode= "NoPadding",characterSet ="utf-8"):
'''
构建一个AES对象
key: 秘钥,字节型数据
mode: 使用模式,只提供两种,AES.MODE\_CBC, AES.MODE\_ECB
iv: iv偏移量,字节型数据
paddingMode: 填充模式,默认为NoPadding, 可选NoPadding,ZeroPadding,PKCS5Padding,PKCS7Padding
characterSet: 字符集编码
'''
self.key = key
self.mode = mode
self.iv = iv
self.characterSet = characterSet
self.paddingMode = paddingMode
self.data = ""
def \_\_ZeroPadding(self,data):
data += b'\x00'
while len(data) % 16 != 0:
data += b'\x00'
return data
def \_\_StripZeroPadding(self,data):
data = data[:-1]
while len(data) % 16 != 0:
data = data.rstrip(b'\x00')
if data[-1] != b"\x00":
break
return data
def \_\_PKCS5\_7Padding(self,data):
needSize = 16-len(data) % 16
if needSize == 0:
needSize = 16
return data + needSize.to_bytes(1,'little')\*needSize
def \_\_StripPKCS5\_7Padding(self,data):
paddingSize = data[-1]
return data.rstrip(paddingSize.to_bytes(1,'little'))
def \_\_paddingData(self,data):
if self.paddingMode == "NoPadding":
if len(data) % 16 == 0:
return data
else:
return self.__ZeroPadding(data)
elif self.paddingMode == "ZeroPadding":
return self.__ZeroPadding(data)
elif self.paddingMode == "PKCS5Padding" or self.paddingMode == "PKCS7Padding":
return self.__PKCS5_7Padding(data)
else:
print("不支持Padding")
def \_\_stripPaddingData(self,data):
if self.paddingMode == "NoPadding":
return self.__StripZeroPadding(data)
elif self.paddingMode == "ZeroPadding":
return self.__StripZeroPadding(data)
elif self.paddingMode == "PKCS5Padding" or self.paddingMode == "PKCS7Padding":
return self.__StripPKCS5_7Padding(data)
else:
print("不支持Padding")
def setCharacterSet(self,characterSet):
'''
设置字符集编码
characterSet: 字符集编码
### 最后
> **🍅 硬核资料**:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
> **🍅 技术互助**:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
> **🍅 面试题库**:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
> **🍅 知识体系**:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里无偿获取](https://bbs.csdn.net/topics/618317507)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









