







image = cv2.imread(‘your_image.jpg’, 0)
自适应阈值二值化
binary = cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2)
查找轮廓
contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
绘制轮廓
contour_image = cv2.drawContours(image.copy(), contours, -1, (0, 255, 0), 2)
显示结果
cv2.imshow(‘Binary Image’, binary)
cv2.imshow(‘Contour Image’, contour_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
在上述代码中,首先使用`cv2.adaptiveThreshold`函数对图像进行自适应阈值二值化,其中`cv2.ADAPTIVE_THRESH_MEAN_C`表示使用局部均值作为阈值计算方式。然后使用`cv2.findContours`函数查找图像中的轮廓,并使用`cv2.drawContours`函数绘制轮廓。
您可以根据实际情况调整自适应阈值二值化的参数,如窗口大小和均值计算方法,以获得最佳的结果。
### 二、扩展思路介绍
当使用自适应阈值二值化来处理图像时,还可以考虑以下几个方面的扩展:
1. 调整自适应阈值二值化的参数:除了示例代码中使用的`cv2.ADAPTIVE_THRESH_MEAN_C`方法外,还可以尝试使用`cv2.ADAPTIVE_THRESH_GAUSSIAN_C`方法,它使用局部区域的加权和作为阈值计算方式。可以根据图像的特点和需求,比较两种方法的效果并选择最佳的方法。
2. 对二值化图像进行形态学操作:在获取到二值化图像后,可以应用形态学操作来进一步处理图像,以改善文字轮廓的提取效果。例如,可以使用`cv2.dilate`函数对二值化图像进行膨胀操作,以填充文字内部的空洞;或者使用`cv2.erode`函数对二值化图像进行腐蚀操作,以去除细小的噪点。
3. 使用轮廓特征进行筛选:在查找轮廓后,可以通过一些条件来筛选出符合要求的轮廓。例如,可以根据轮廓的面积、周长、宽高比等特征进行筛选,以排除不需要的轮廓。
4. 应用其他图像处理技术:如果仍然无法满足需求,可以尝试其他图像处理技术来提取文字轮廓。例如,可以使用边缘检测算法(如Canny边缘检测)来获取文字的边缘信息;或者使用图像分割算法(如基于区域的分割算法)将图像分割为文字和背景区域。
综上所述,根据具体的需求和图像特点,可以尝试调整参数、应用形态学操作、筛选轮廓以及使用其他图像处理技术来进一步优化文字轮廓的提取效果。
### 三、调整自适应阈值二值化的参数示例代码
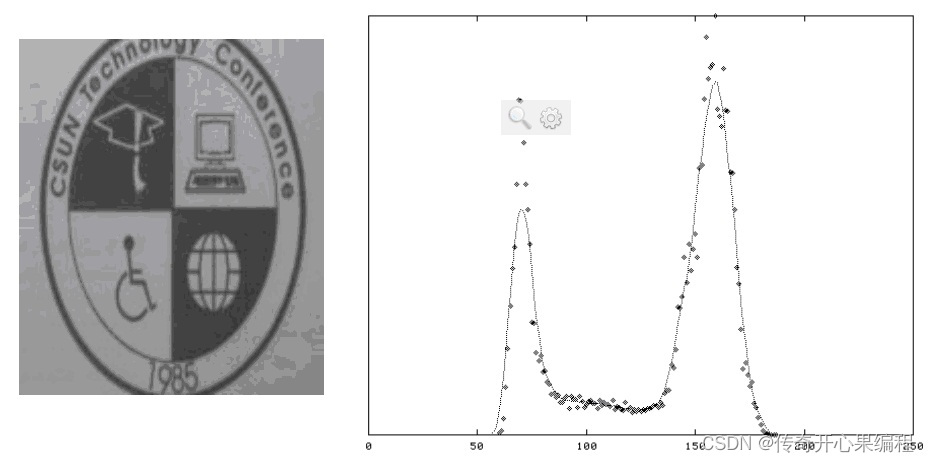下面是一个示例代码,演示了如何调整自适应阈值二值化的参数来提取文字轮廓:
import cv2
读取图像
image = cv2.imread(‘your_image.jpg’, 0)
自适应阈值二值化(调整参数)
binary = cv2.adaptiveThreshold(image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 5)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









