







总结
我个人认为,如果你想靠着背面试题来获得心仪的offer,用癞蛤蟆想吃天鹅肉形容完全不过分。想必大家能感受到面试越来越难,想找到心仪的工作也是越来越难,高薪工作羡慕不来,却又对自己目前的薪资不太满意,工作几年甚至连一个应届生的薪资都比不上,终究是错付了,错付了自己没有去提升技术。
这些面试题分享给大家的目的,其实是希望大家通过大厂面试题分析自己的技术栈,给自己梳理一个更加明确的学习方向,当你准备好去面试大厂,你心里有底,大概知道面试官会问多广,多深,避免面试的时候一问三不知。
大家可以把Java基础,JVM,并发编程,MySQL,Redis,Spring,Spring cloud等等做一个知识总结以及延伸,再去进行操作,不然光记是学不会的,这里我也提供一些脑图分享给大家:



希望你看完这篇文章后,不要犹豫,抓紧学习,复习知识,准备在明年的金三银四拿到心仪的offer,加油,打工人!
- 集中式版本控制
============
优点:可以对具体的文件或目录进行权限控制,有全局的版本号。
缺点:所有操作都需要联网中心服务器。
- 分布式版本控制
============
优点:
i. 分支管理。
ii. 完整性和安全性更高,各客户端保留有完整的版本库。
iii. 绝大部分操作都是本地化的,支持离线。
缺点:
i. 对版本库的目录和文件无法做到精细化的权限控制。
ii. 无全局性的版本号。
通过以上分析的集中式和分布式版本控制的优缺点,我们就能总结出以Git为代表的分布式版本控制和以SVN为代表的集中式版本控制之间的区别。
- Git和SVN的区别
===============
-
最核心的区别当然是分布式和集中式。
-
处理数据的方式不同,Git以元数据方式存储数据,SVN按照文件存储,对应的取出数据方式也不一样。
-
分支管理或分支模型(下文会详解)。
-
全局性的版本号。
-
数据的完整性和安全性,分布式的更好。
三、常用的Git解决方案和代码托管平台
===================
1.开源软件解决方案:Gitea、GitLab
2.代码托管平台:码云(Gitee)、码市(Coding)、GitHub、GitLab、Bitbucket
四、Git的基石SHA-1
=============
In cryptography, SHA-1 (Secure Hash Algorithm 1) is a cryptographichash function which takes an input and produces a 160-bit (20-byte) hash value known as a message digest – typically rendered as ahexadecimal number, 40 digits long. It was designed by the UnitedStates National Security Agency, and is a U.S. Federal InformationProcessing Standard.
以上摘自维基百科,主要说明了SHA是一个密码散列函数家族,是FIPS所认证的安全散列算法。能计算出一个数字消息所对应到的,长度固定的字符串(又称消息摘要)的算法。且若输入的消息不同,它们对应到不同字符串的机率很高。SHA-1长度为20字节,160位,熟悉网络编程的都知道,4位可以转换成一个十六进制的数字,所以一个SHA-1散列可以展示为40长度的十六进制的数字。
SHA-1的计算方法为代码:
1 //Note: All variables are unsigned 32 bits and wrap modulo 232 when calculating
2
3 //Initial variables:
4 h0 := 0x67452301
5 h1 := 0xEFCDAB89
6 h2 := 0x98BADCFE
7 h3 := 0x10325476
8 h4 := 0xC3D2E1F0
9
10 //Pre-processing:
11 append the bit ‘1’ to the message
12 append k bits ‘0’, where k is the minimum number >= 0 such that the resulting message
13 length (in bits) is congruent to 448(mod 512)
14 append length of message (before pre-processing), in bits, as 64-bit big-endian integer
15
16 //Process the message in successive 512-bit chunks:
17 break message into 512-bit chunks
18 for each chunk
19 break chunk into sixteen 32-bit big-endian words w[i], 0 ≤ i ≤ 15
20
21 //Extend the sixteen 32-bit words into eighty 32-bit words:
22 for i from 16 to 79
23 w[i] := (w[i-3] xor w[i-8] xor w[i-14] xor w[i-16]) leftrotate 1
24
25 //Initialize hash value for this chunk:
26 a := h0
27 b := h1
28 c := h2
29 d := h3
30 e := h4
31
32 //Main loop:
33 for i from 0 to 79
34 if 0 ≤ i ≤ 19 then
35 f := (b and c) or ((not b) and d)
36 k := 0x5A827999
37 else if 20 ≤ i ≤ 39
38 f := b xor c xor d
39 k := 0x6ED9EBA1
40 else if 40 ≤ i ≤ 59
41 f := (b and c) or (b and d) or(c and d)
42 k := 0x8F1BBCDC
43 else if 60 ≤ i ≤ 79
44 f := b xor c xor d
45 k := 0xCA62C1D6
46 temp := (a leftrotate 5) + f + e + k + w[i]
47 e := d
48 d := c
49 c := b leftrotate 30
50 b := a
51 a := temp
52
53 //Add this chunk’s hash to result so far:
54 h0 := h0 + a
55 h1 := h1 + b
56 h2 := h2 + c
57 h3 := h3 + d
58 h4 := h4 + e
59
60 //Produce the final hash value (big-endian):
61 digest = hash = h0 append h1 append h2 append h3 append h4
虽然SHA-1作为数字签名的算法不安全,但是作为日常项目代码管理来说却足够能够保证其唯一性。
我们已经了解到SHA-1摘要的长度是20字节,也就是160位。要确保有50%的概率出现一次冲突,需要280个随机散列的对象(计算冲突概率的公式是p=(n(n-1)/2)*(1/2160))。280=1.2*1024,也就是一亿亿亿,这是地球上沙粒总数的1200倍。即使按照目前公开的2005年CRYPTO会议中由王小云提出的更具效率的SHA-1攻击法,也需要263=9.2*1018,也就是九十二亿亿,虽然不及地球上的沙粒数也是一个很大的数字。
超大型项目Linux内核有超过45万次提交,包含360万个对象,也至多需要前11个字符就能够保证SHA-1的唯一性。
Git根据文件内容或目录结构计算出SHA-1散列值,然后通过散列值存储、检索和处理信息。
五、Git模型
=======
- 区域模型
=========
Git项目中的主要区域:Git目录(仓库)、工作目录和暂存区(索引)
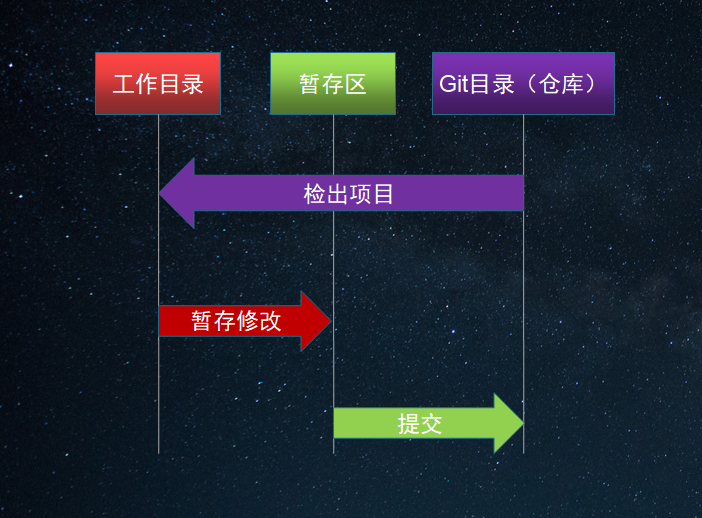
Git目录也称为Git仓库或Git数据库,是保存Git项目元数据和对象数据库的地方。是Git最重要的部分,当从其它计算机中克隆项目时需要复制的内容。
工作目录是项目某个版本的单次检出。这些文件从Git仓库中提取出来,放置在磁盘上使用和修改。我们平时码代码时的区域就是在工作目录中,因为这里是唯一提供了对文件进行编辑的地方。
暂存区也称为索引,是一个文件,一般位于Git目录中。保存了下次所要提交内容的相关信息。Git的add命令就是将工作目录中的内容添加到暂存区中。
- 分支模型
=========
分支模型是Git的精髓,被称为Git的“杀手锏特性”。
分支意味着偏离开发主线并继续你自己的工作而不影响主线开发。在其它很多版本控制工具中,有较昂贵的成本,因为常常需要去对整个源代码目录进行一次复制,特别对于大型项目,这样的复制时间成本是很高的。
Git的分支与众不同的地方在于,极致的轻量,几乎即时就可以完成分支操作,分支间的切换操作也很方便。
Git以快照的方式存储数据。
当发起提交时,Git存储的是提交对象(commit object),其中包含了指向暂存区快照的指针。提交对象也包含作者的姓名和邮箱地址、已输入的提交信息以及指向其父提交的指针。初始提交没有父提交,而一般的提交会有一个父提交;对于两个或更多分支的合并提交,存在多个父提交。
当执行git commit进行提交时,Git会先为每个子目录计算校验和,然后再把这些树对象(tree object)保存到Git仓库中,Git随后会创建提交对象,其中包括元数据以及指向项目根目录的树对象的指针,以便有需要的时候重新创建这次快照。
Git分支只不过是一个指向某次提交的轻量级的可移动指针。Git默认的分支名称是master。当你发起提交时,你的当前分支比如master分支就会移动指向你刚刚的提交。
git init命令默认创建的就是master分支。
Git的分支实际上就是一个简单的文件,其中只包含了该分支所指向提交的长度为40个字符的SHA-1校验和。正因如此,Git分支的创建和删除成本就很低。创建新分支就如同向文件写入40个字符外加一个换行符一件简单方便。
提交时Git保存了父对象的指针,当进行合并操作时Git会自动寻找适当的合并基础,创建新分支并在其上coding,然后把多个分支间的代码进行合并很方便,所以Git鼓励开发人员创建和使用分支。
接下来我们来了解几个分支概念
长期分支VS主题分支
主题分支是指短期的、用于实现某一特定功能及其相关工作的分支。与之相对的就是长期分支,长期分支是在整个项目中会一直保持,用于合并主题分支或版本控制和代码发布的分支。比如在master分支上存放稳定版的代码,develop上进行开发,test分支上进行测试,在iss-email上进行email的主题开发。
远程分支VS跟踪分支
远程分支是指向远程仓库的分支的指针,这些指针存在于本地且无法被移动。基于远程分支创建的本地分支就是其远程分支的跟踪分支(tracking branch),有时也叫做上游分支(upstream branch)。远程分支我们能够理解是在服务器上的分支,那跟踪分支呢?我随便创建的本地分支都是跟踪分支吗?本地非跟踪分支和跟踪分支又有什么区别呢?
当你克隆一个远程仓库时,Git默认情况下会自动创建跟踪着远程origin/master分支的本地master分支。当你试图执行分支切换操作时,如果该分支尚未被创建,并且该分支名称和某个远程分支名称一致,那么Git会帮你创建跟踪分支。当设置成为跟踪分支后,使用Git命令时可以简化操作,比如在master分支上push代码到远程仓库上,可以直接使用git push,如果没设置跟踪分支需要使用git push origin/master。
$git checkout --track origin/serverfix
Branch serverfix set up to track remote branch serverfix from origin.
Switched to new Branch ‘serverfix’
$git checkout -b sf origin/serverfix
Branch sf set up to track remote branch serverfix from origin.
Switch to a new branch ‘sf’
当我们了解了Git的分支模型后,分支模型正确的打开方式是什么样的呢?
假设你在master分支上做了一些项目起始的工作,之后为了实现某个需求,创建并切换到主题分支sub-record,并在其上做了一些开发工作。之后,你又尝试另一种能实现需求的方式,创建并切换到新的分支sub-recordv1。接着你又切换回master分支并继续工作了一段时间,最后你创建了新的分支dumb-idea来实现你的一个不确定的想法。
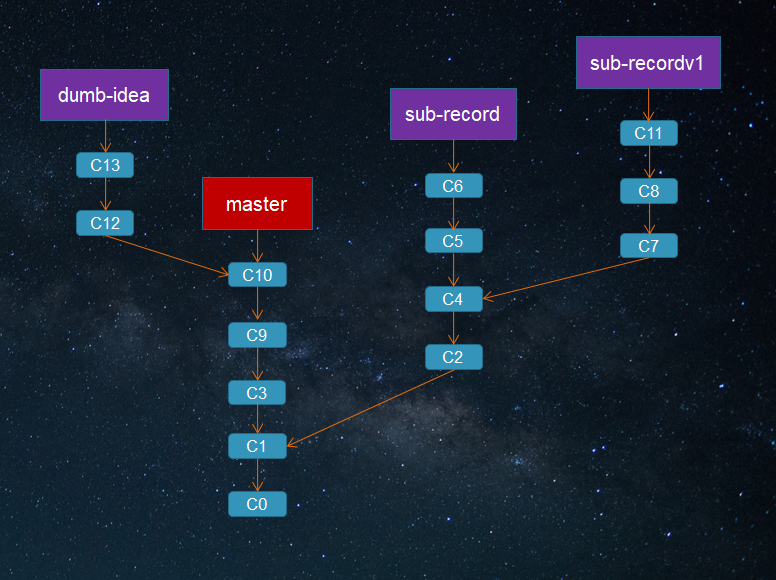
最后你觉得sub-recordv1方案效率比较高,而在dumb-idea上的工作同事们都觉得很有意义,那么把主题分支上的提交合并合并入长期分支master,舍弃掉sub-record上的C5和C6提交。
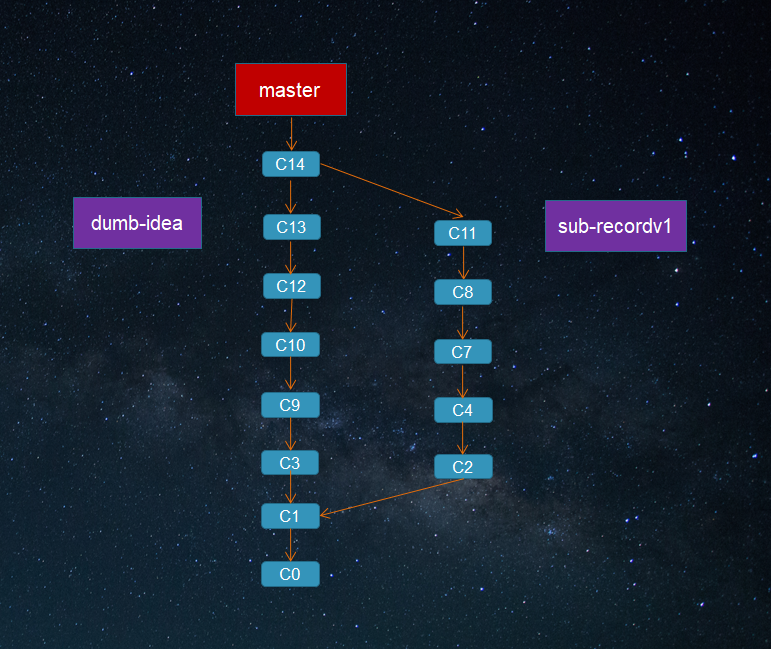
根据项目的需要,为实现一个需求或一个子需求甚至一个想法创建一个分支。合并代码的时候只需要合并需要的,那些暂时没能合并入的代码也许以后要么直接或间接就可以用上,如果没能用上也可以借鉴和参考。毕竟创建和使用Git分支的成本很低而且方便有效,这样才是Git分支模型的正确打开方式。
- 对象模型
=========
对象模型分为:主要对象和标签对象。主要对象又分为blob对象、树对象和提交对象。
blob对象是保存到Git仓库的文件当前版本或者称为元数据。可以理解为文件内容。
树对象解决的是文件名的存储问题。可以认为是目录,对应为Unix目录项。单个树对象包含一个或多个树条目,每个条目包含一个指向blob对象或子树的指针以及相关模式、类型和文件名。
提交对象指定了此刻项目快照的顶层树对象、作者/提交者信息、提交时间戳、一个空行以及提交消息。指向的是树对象。
标签对象与提交对象非常相似,包含了标签的创建者、日期、标签消息和一个指针。通常指向提交对象也可以指向blob对象。是不可变的分支引用,总是指向相同的提交对象或blob对象。
- “三棵树”模型
============
将Git类比为三棵树的内容管理器。“树”实际上指的是“文件的集合”,并非特定的数据结构。
三棵树HEAD最近提交的快照,下次提交的父提交
写在最后
作为一名即将求职的程序员,面对一个可能跟近些年非常不同的 2019 年,你的就业机会和风口会出现在哪里?在这种新环境下,工作应该选择大厂还是小公司?已有几年工作经验的老兵,又应该如何保持和提升自身竞争力,转被动为主动?
就目前大环境来看,跳槽成功的难度比往年高很多。一个明显的感受:今年的面试,无论一面还是二面,都很考验Java程序员的技术功底。
最近我整理了一份复习用的面试题及面试高频的考点题及技术点梳理成一份“Java经典面试问题(含答案解析).pdf和一份网上搜集的“Java程序员面试笔试真题库.pdf”(实际上比预期多花了不少精力),包含分布式架构、高可扩展、高性能、高并发、Jvm性能调优、Spring,MyBatis,Nginx源码分析,Redis,ActiveMQ、Mycat、Netty、Kafka、Mysql、Zookeeper、Tomcat、Docker、Dubbo、Nginx等多个知识点高级进阶干货!
由于篇幅有限,为了方便大家观看,这里以图片的形式给大家展示部分的目录和答案截图!

Java经典面试问题(含答案解析)

阿里巴巴技术笔试心得

ker、Dubbo、Nginx等多个知识点高级进阶干货!**
由于篇幅有限,为了方便大家观看,这里以图片的形式给大家展示部分的目录和答案截图!
[外链图片转存中…(img-8d7U5lVB-1715101970988)]
Java经典面试问题(含答案解析)
[外链图片转存中…(img-YxSdIZXi-1715101970989)]
阿里巴巴技术笔试心得
[外链图片转存中…(img-yXqSXijA-1715101970989)]
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









