







独家面经总结,超级精彩
本人面试腾讯,阿里,百度等企业总结下来的面试经历,都是真实的,分享给大家!




Java面试准备
准确的说这里又分为两部分:
- Java刷题
- 算法刷题
Java刷题:此份文档详细记录了千道面试题与详解;


一个HTTP协议的请求中,通常主要包含三个部分:
- 方法/统一资源标示符(URI)/协议/版本
- 请求标头
- 实体主体
其中方法也就是所谓的get/post之类的请求方法,统一资源标示符也就是要访问的目标资源的路径,包括协议及协议版本,这些信息被放在请求的第一行。
随后,紧接着的便是请求标头;请求标头通常包含了与客户端环境及请求实体主体相关的有用信息。
最后,在标头与实体主体之间是一个空行。它对于HTTP请求格式是很重要的,空行告诉HTTP服务器,实体主体从这里开始。
前面已经说过了,我们这里想要研究的,是WEB服务器的基本实现原理。
那么我们自然想要自己来实现一下所谓的WEB服务器,我们已经知道了:
所谓的B/S结构,实际上就是客户端与服务器之间基于HTTP协议的网络通信。
那么,肯定是离不开socket与io的,所以我们可以简单的模拟一个最简易功能的山寨浏览器:
public class MyTomcat {
public static void main(String[] args) {
try {
ServerSocket tomcat = new ServerSocket(9090);
System.out.println("服务器启动");
//
Socket s = tomcat.accept();
//
byte[] buf = new byte[1024];
InputStream in = s.getInputStream();
//
int length = in.read(buf);
String request = new String(buf,0,length);
//
System.out.println(request);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
这次我们在通过对应的URL在浏览器中对我们的山寨服务器进行访问,得到的输出结果是:

通过成果我们看到,我们已经成功的简单山寨了一下tomcat。
不过这里需要注意的是,我们自己山寨的tomcat服务器当中,之所以也成功的输出了Http协议的请求体,是因为:
我们是通过web浏览器进行访问的,如果通过普通的socket进行对serversocket的连接访问,是没有这些请求信息的。
因为我们前面已经说过了,web浏览器与服务器之间的通信必须遵循Http协议。
所以,我们日常生活中使用的web浏览器,会自动的为我们的请求进行基于http协议的包装。
但是,因为我们已经了解了原理,所以我们也可以自己模拟一下浏览器过过瘾:
//山寨浏览器
public class MyBrowser {
public static void main(String[] args) {
try {
Socket browser = new Socket("192.168.1.102", 9090);
PrintWriter pw = new PrintWriter(browser.getOutputStream(),true);
// 封装请求第一行
pw.println("GET/ HTTP/1.1");
// 封装请求头
pw.println("User-Agent: Java/1.6.0_13");
pw.println("Host: 192.168.1.102:9090");
pw
.println("Accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2");
pw.println("Connection: keep-alive");
// 空行
pw.println();
// 封装实体主体
pw.println("UserName=zhangsan&Age=17");
// 写入完毕
browser.shutdownOutput();
// 接受服务器返回信息,
InputStream in = browser.getInputStream();
//
int length = 0;
StringBuffer request = new StringBuffer();
byte[] buf = new byte[1024];
//
while ((length = in.read(buf)) != -1) {
String line = new String(buf, 0, length);
request.append(line);
}
System.out.println(request);
//browser.close();
} catch (IOException e) {
System.out.println("异常了,操!");
}finally{
}
}
}
//修改后的山寨tomcat服务器
public class MyTomcat {
public static void main(String[] args) {
try {
ServerSocket tomcat = new ServerSocket(9090);
System.out.println("服务器启动");
//
Socket s = tomcat.accept();
//
byte[] buf = new byte[1024];
InputStream in = s.getInputStream();
//
int length = 0;
StringBuffer request = new StringBuffer();
while ((length = in.read(buf)) != -1) {
String line = new String(buf, 0, length);
request.append(line);
}
//
System.out.println("request:"+request);
PrintWriter pw = new PrintWriter(s.getOutputStream(),true);
pw.println("<html>");
pw.println("<head>");
pw.println("<title>LiveSession List</title>");
pw.println("</head>");
pw.println("<body>");
pw.println("<p style=\"font-weight: bold;color: red;\">welcome to MyTomcat</p>");
pw.println("</body>");
s.close();
tomcat.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
我们先启动服务器,然后运行浏览器模拟网页浏览的过程,首先看到服务器端收到的请求信息:
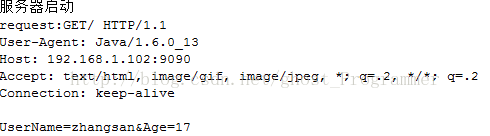
紧接着,服务器收到请求进行处理后,返回资源给浏览器,于是得到输出信息:

可以看到,我们在山寨浏览器当中得到的返回信息,实际上就是一个HTML文件的源码,
之所以我们的山寨浏览器中,这些信息仅仅是以纯文本形式显示,是因为我们的山寨浏览器不具备解析HTML语言的能力。
所以说,浏览器另外一个重要的功能其实就是:可以对超文本标记语言进行解析。而实际上,这也是浏览器开发的难点和重点。
上面这样的输出结果看上去显然不爽,所以说山寨货毕竟还是坑爹!
我们还是通过正规的WEB浏览器,来试着访问一下我们的山寨服务器,结果发现,效果帅多了:

而顺带一提的是,既然当浏览器向WEB服务器发起访问请求时,会封装有对应的HTTP请求体。
那么,对应的,当WEB服务器处理完浏览器请求,返回数据时,也会有对应的封装,就是所谓的HTTP响应体。
举例来说,假如我们将我们的山寨浏览器的代码进行修改,去连接真正的tomcat服务器:
public class MyBrowser {
public static void main(String[] args) {
try {
Socket browser = new Socket("192.168.1.102", 8080);
PrintWriter pw = new PrintWriter(browser.getOutputStream(),true);
// 封装请求第一行
pw.println("GET / HTTP/1.1");
// 封装请求头
pw.println("User-Agent: Java/1.6.0_13");
pw.println("Host: 192.168.1.102:8080");
pw
.println("Accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2");
pw.println("Connection: keep-alive");
// 空行
pw.println();
// 封装实体主体
//pw.println("UserName=zhangsan&Age=17");
// 写入完毕
browser.shutdownOutput();
// 接受服务器返回信息,
InputStream in = browser.getInputStream();
//
int length = 0;
StringBuffer request = new StringBuffer();
byte[] buf = new byte[1024];
//
while ((length = in.read(buf)) != -1) {
String line = new String(buf, 0, length);
request.append(line);
}
System.out.println(request);
//browser.close();
} catch (IOException e) {
System.out.println("异常了,操!");
}finally{
}
}
}
运行程序,你将会发下如下的输出信息:
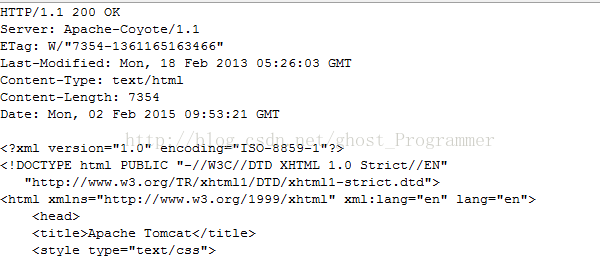
与HTTP请求类似,通常一个HTTP响应也包含三个部分:
- 协议/响应码/状态描述:协议也就是指HTTP协议的信息,响应码是指代表该次请求的处理结果的码(例如常见的200、404、500),其实就是该次请求处理的响应描述
- 响应标头:响应标头也包含与HTTP请求中的标头类似的有用信息。
- 响应实体:通常也就是指响应本身的HTML内容。
与HTTP请求一样,响应表头与响应实体之间,也会使用一个空行进行分割,方便解读。
同时我们也可以发现,其实真正被解析显示在浏览器网页上的内容,其实只是响应实体的部分。
总结:绘上一张Kakfa架构思维大纲脑图(xmind)

其实关于Kafka,能问的问题实在是太多了,扒了几天,最终筛选出44问:基础篇17问、进阶篇15问、高级篇12问,个个直戳痛点,不知道如果你不着急看答案,又能答出几个呢?
若是对Kafka的知识还回忆不起来,不妨先看我手绘的知识总结脑图(xmind不能上传,文章里用的是图片版)进行整体架构的梳理
梳理了知识,刷完了面试,如若你还想进一步的深入学习解读kafka以及源码,那么接下来的这份《手写“kafka”》将会是个不错的选择。
-
Kafka入门
-
为什么选择Kafka
-
Kafka的安装、管理和配置
-
Kafka的集群
-
第一个Kafka程序
-
Kafka的生产者
-
Kafka的消费者
-
深入理解Kafka
-
可靠的数据传递
-
Spring和Kafka的整合
-
SpringBoot和Kafka的整合
-
Kafka实战之削峰填谷
-
数据管道和流式处理(了解即可)


SpringBoot和Kafka的整合
-
Kafka实战之削峰填谷
-
数据管道和流式处理(了解即可)
[外链图片转存中…(img-caEiQcCK-1715452090561)]
[外链图片转存中…(img-dgZQtX23-1715452090561)]















 626
626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









