







2. bs4模块安装
bs4 是一个第三方库,首先我们得进行安装
在 Python 中推荐使用 pip 进行安装,很简单,在 Pycharm 下方找到 Terminal,输入以下命令:
pip install bs4
如果安装过慢,可以考虑更换为国内源:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple bs4
3. 搞搞农产品价格
bs4 在使用的时候需要参照一些 HTML 的基本语法来进行使用,通过案例来学会使用 bs4 更加快捷
我们来尝试抓取北京岳各庄批发市场的农产品价格 ➔ 目标网站
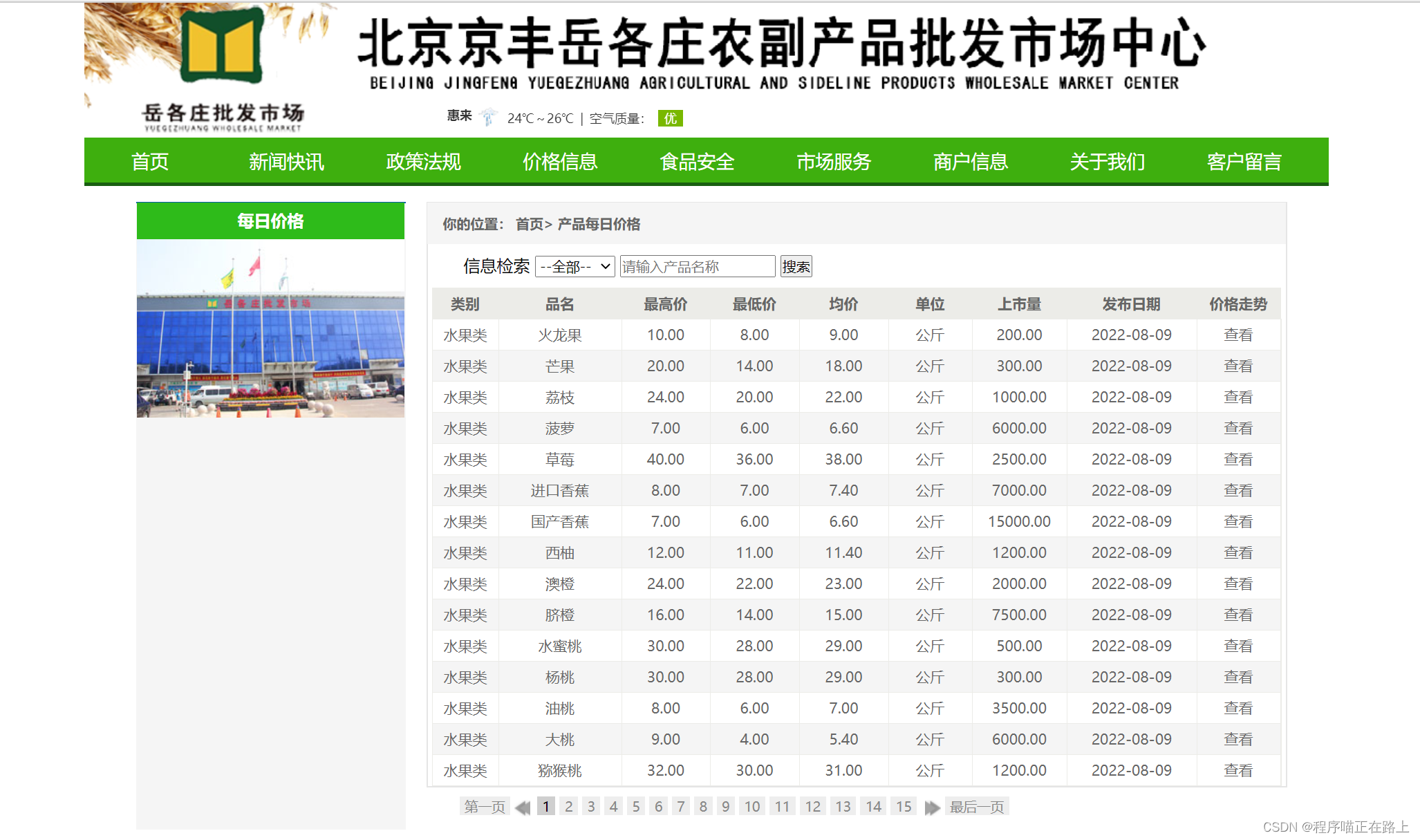

代码实现:
import csv
import requests
from bs4 import BeautifulSoup
# 获取页面源代码
url = "http://www.ygzapm.com/web/dailyPrice"
resp = requests.get(url)
# print(resp.text) # 测试用
f = open("农产品信息.csv", mode="w", encoding='utf-8', newline='')
csvWriter = csv.writer(f)
# 解析数据
# 1. 把页面源代码交给 BeautifulSoup 进行处理,生成 bs 对象
page = BeautifulSoup(resp.text, "html.parser") # 指定html解析器
# 2. 从bs对象中查找数据,两个函数
# find(标签, 属性=值) 找一个
# find\_all(标签, 属性=值) 找全部
# table = page.find("table", class\_="table") # 加下划线区分关键字,与下面的表达式一样
table = page.find("table", attrs={"class": "table"})
# print(table) # 测试用
trs = table.find_all("tr")[1:]
for tr in trs: # 遍历表格的每一行
tds = tr.find_all("td")
type = tds[0].text # 拿到被标签标记的内容
name = tds[1].text
max_price = tds[2].text
min_price = tds[3].text
avg_price = tds[4].text
unit = tds[5].text
market = tds[6].text
date = tds[7].text
# print(type, name, max\_price, min\_price, avg\_price, unit, market, date) # 测试用
csvWriter.writerow([type, name, max_price, min_price, avg_price, unit, market, date])
resp.close()
f.close()
print("over!!!")
效果:
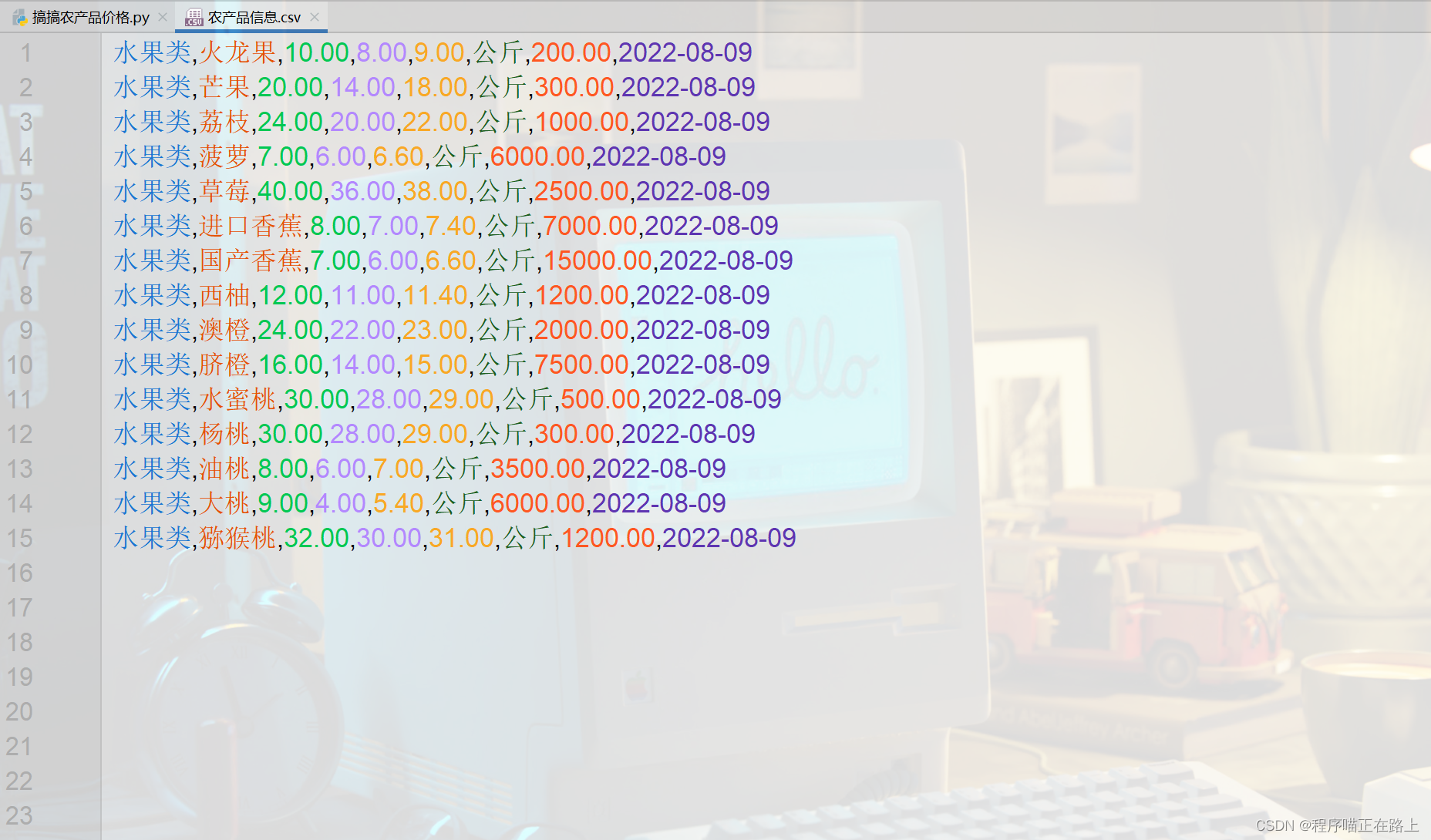
你也可以对代码进行改进,抓取多页数据,但个人建议不要将全部数据都抓取下来
4. 抓取彼岸图网壁纸
你以为我们要抓取的是这些图片吗?
其实不是,我们要抓取的是点击图片进入的页面的高清图片,也就是如下
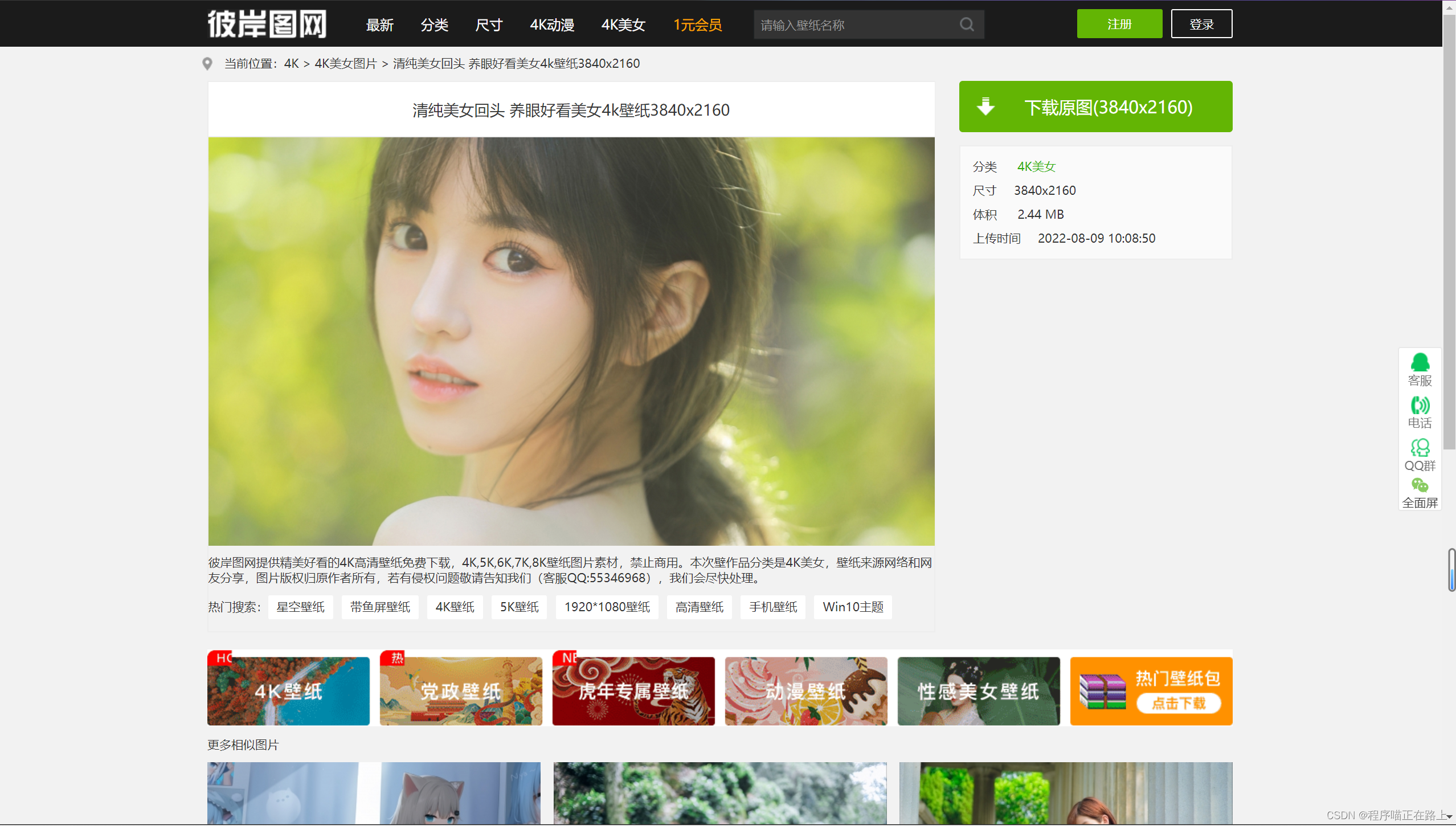
具体步骤一共有三步:
- 获取主页面源代码,然后提取子页面的链接地址
- 获取子页面源代码,查找图片的下载地址
- 下载图片
废话不多说,开搞
import requests
from bs4 import BeautifulSoup
import time
# 1. 获取主页面源代码,然后提取子页面的链接地址
url = "https://pic.netbian.com/"
resp = requests.get(url)
resp.encoding = 'gbk'
main_page = BeautifulSoup(resp.text, "html.parser")
alist = main_page.find("div", class_="slist").find_all("a")
# print(alist) # 测试用
for a in alist:
href = url + a.get('href') # 通过get得到属性的值,拼接得到完整子页面链接
# print(a) # 测试用
# 2. 获取子页面源代码,查找图片的下载地址
sub_page_resp = requests.get(href)
sub_page_resp.encoding = 'gbk'
sub_page_text = sub_page_resp.text
# 从子页面中获取图片的下载地址
sub_page = BeautifulSoup(sub_page_text, "html.parser")
div = sub_page.find("div", class_="photo-pic")
img = div.find("img")
img_href = url + img.get("src").strip("/") # 拼接图片的下载地址
# print(img\_href) # 测试用
# 3. 下载图片
img_resp = requests.get(img_href)
img_name = img_href.split("/")[-1] # 图片名称
img_package = "D:\\pythonProject\\images\\" # 先自己创建一个文件夹以便存放图片,再运行程序
with open(img_package + img_name, mode='wb') as f:
f.write(img_resp.content) # 这里拿到的是字节
img_resp.close()
sub_page_resp.close()
print(img_name + " 已下载成功")
time.sleep(1) # 让服务器休息一下
resp.close()
print("over!!!")
这里是因为我的编译器设置了背景,图片效果不是特别好,还行

xpath解析
xpath 是一门在 XML 文档中查找信息的语言,xpath 可用来在 XML 文档中对元素和属性进行遍历,而我们熟知的 HTML 恰巧属于 XML 的一个子集,所以完全可以用 xpath 去查找 html 中的内容
首先,我们先了解几个概念
<book>
<id>1</id>
<name>天才基本法</name>
<price>8.9</price>
<author>
<nick>林朝夕</nick>
<nick>裴之</nick>
</author>
</book>
在上述 html 中,
- book, id, name, price…都被称为节点.
- Id, name, price, author 被称为 book 的子节点
- book 被称为 id, name, price, author 的父节点
- id, name, price,author 被称为同胞节点
好的,有了这些基础知识后,我们就可以开始了解 xpath 的基本语法了
在 Python 中想要使用 xpath,需要安装 lxml 模块
pip install lxml
用法:
- 将要解析的 html 内容构造出 etree 对象.
- 使用 etree 对象的 xpath() 方法配合 xpath 表达式来完成对数据的提取
from lxml import etree
xml = """
<book>
<id>1</id>
<name>天才基本法</name>
<price>8.9</price>
<author>
<nick id="10086">林朝夕</nick>
<nick id="10010">裴之</nick>
<div>
<nick id="jay1">周杰伦1</nick>
</div>
<span>
<nick id="jay2">周杰伦2</nick>
</span>
</author>
<partner>
<nick id="ppc">佩奇</nick>
<nick id="ppbc">乔治</nick>
</partner>
</book>
"""
tree = etree.XML(xml)
# result = tree.xpath("/book") # / 表示层级关系,第一个 / 是根节点
# result = tree.xpath("/book/name/text()") # text() 获取文本
### 一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

### 二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

### 三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里无偿获取](https://bbs.csdn.net/topics/618317507)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1808
1808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









