







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
下表为某地区国内生产总值的统计数据(以百万元计),问该地区从2000年到2005年之间哪一种产业对GDB总量印象最大。
| 年份 | 国内生产总值 | 第一产业 | 第二产业 | 第三产业 |
| 2000 | 1988 | 386 | 839 | 763 |
| 2001 | 2061 | 408 | 846 | 808 |
| 2002 | 2335 | 422 | 960 | 953 |
| 2003 | 2750 | 482 | 1258 | 1010 |
| 2004 | 3356 | 511 | 1577 | 1268 |
| 2005 | 3806 | 561 | 1893 | 1352 |
2.1 画出统计图
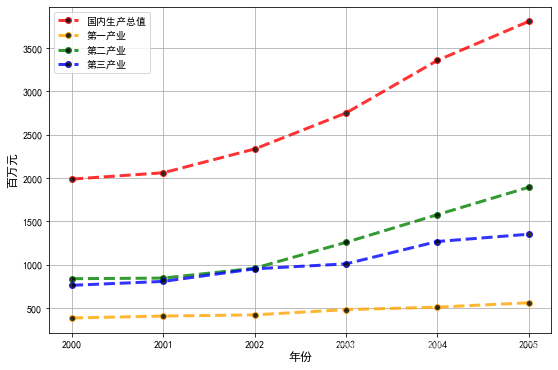
画图后得配上简单的分析 :
- 四个变量均 呈上升 的趋势
- 第⼆产业的增幅较为明显
- 第⼆产业和第三产业的差距在后三年相差增大
- 等等
2.2 确定分析数列
- 母序列(又称参考数列 、母指标) : 能反映系统⾏为特征的数据序列 。类似于因变量 Y , 此处记为 X。
- 子序列(又称⽐较数列、子指标) : 影响系统⾏为的因素组成的数据序列。类似于⾃变量X , 此处记为
。
在本例中国内⽣产总值就是母序列( ) , 第一二三产业就是子序列(
)。
2.3 对变量进⾏预处理
两个目的:
- 去量纲
- 缩⼩变量范围简化计算
对母序列和子序列中的每个指标进行预处理 :
- 先求出每个指标的均值。
- 再用该指标中的每个元素都除以其均值 。
预处理后:
| 年份 | 国内生产总值 | 第一产业 | 第二产业 | 第三产业 |
| 2000 | 0.7320 | 0.8361 | 0.6828 | 0.7439 |
| 2001 | 0.7588 | 0.8838 | 0.6885 | 0.7878 |
| 2002 | 0.8597 | 0.9141 | 0.7812 | 0.9292 |
| 2003 | 1.1025 | 1.0440 | 1.0237 | 0.9847 |
| 2004 | 1.2356 | 1.1069 | 1.2833 | 1.2363 |
| 2005 | 1.4013 | 1.2152 | 1.5405 | 1.3182 |
2.4 计算子序列中各个指标与母序列的关联系数
计算两极差:
| ** | x_{0}-x_{1} | ** |
| 0.1041 | 0.0491 | 0.0119 |
| 0.1249 | 0.0703 | 0.0289 |
| 0.0543 | 0.0784 | 0.0694 |
| 0.0315 | 0.0112 | 0.0277 |
| 0.1287 | 0.0476 | 0.0006 |
| 0.1861 | 0.1391 | 0.0831 |
- 两极最小差:
- 两极最大差:
其中向量(或矩阵)x0为母序列,x123为子序列,则有: b = 0.1861, a = 0.0006,即上三列中最大的数b和最小的数a。
定义:
其中 为分辨系数(一般取0.5),i=1,2,…,m ,k=1,2,…,n
则有:
| \frac{a+\rho b}{ | x_{0}(k)-x_{1}(k) | +\rho b} |
| 0.4751 | 0.6586 | 0.8922 |
| 0.4298 | 0.5732 | 0.7679 |
| 0.6355 | 0.5461 | 0.5766 |
| 0.7520 | 0.8984 | 0.775 |
| 0.4223 | 0.6656 | 1.0000 |
| 0.3355 | 0.4035 | 0.5317 |
2.5 计算灰色关联度
定义:
也就是对上表每列求平均
**灰色关联度结果为:[0.5084, 0.6242, 0.7572]**分别对应1 2 3 三个指标。
2.6 比较三个子序列和母序列的关联度得到结论
该地区在 2000年⾄ 2005年 间的国内⽣产总值受到第三产业的影响最大 。 (其灰色关联度最大)
惊讶了,从图上来看应该是第二产业影响最大才对:
实际上,我们最开始提到过:灰色关联分析的基本思想是根据序列曲线几何形状的相似程度来判断其联系是否紧密。曲线越接近,相应序列之间的关联度就越大,反之就越小。我们计算的结果就可以看作是在计算相似程度。
2.7 思考
1. 什么时候用标准化回归 , 什么时候用灰色关联分析 ?
当样本个数较大时, ⼀般使用标准化回归 ; 当样本个数较少时, 才使用灰⾊关联分析 。
2 . 如果母序列中有多个指标, 应该怎么分析 ?
如
是母序列,
是子序列,那么我们先计算
和
的灰度分析,在计算
和
的灰度分析。
三、用于综合评价问题
老面孔,我们上一章TOPSIS法做的题:
题目:评价下表中20条河流的水质情况。
注:含氧量越高越好;PH值越接近7越好;细菌总数越少越好;植物性营养物量介于10‐20之间最佳,超过20或低于10均不好。
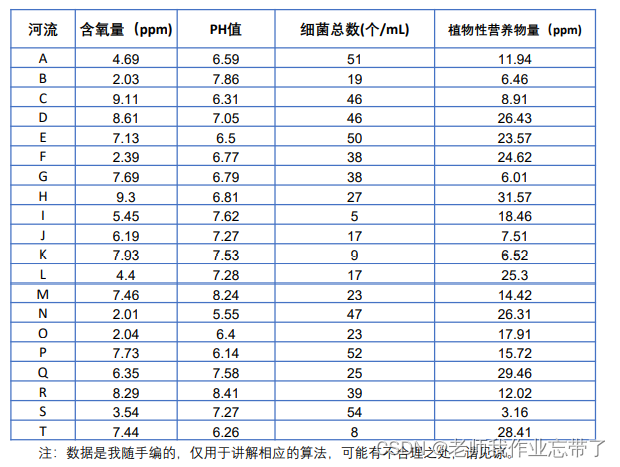
X(n*m) n=20个评价对象,m=4个评价指标。
3.1 正向化指标
之前TOPSIS所讲
含氧量越高越好;PH值越接近7越好;细菌总数越少越好;植物性营养物量介于10‐20之间最佳,超 过20或低于10均不好。
3.2 对正向化后的矩阵进行预处理
每一列除以这一列的均值,目的是去除量纲缩小计算范围。
3.3 将预处理后的矩阵每行取出最大值构成母序列(虚构的)
虚构出一个Y来作为母序列,其中Y为每行各个指标的最大值。
3.4 计算各个指标与母序列的灰色关联度
计算方法同上方案例:系统分析,得到
3.5 计算各个指标的权重
3.6 第k个评价对象的得分
3.7 对得分进行归一化
3.8 代码
import numpy as np
import pandas as pd
data = pd.read_excel('20条河流的水质情况数据.xlsx')
matrix = data.loc[:, '含氧量(ppm)':].values
# matrix第一列是极大型指标 我们对第二三四列进行正向化
# 注:正向化的公式不唯一,大家也可以结合自己的数据进行适当的修改。
# 正向化类,这里返回拷贝后的result,也可以直接在原矩阵上进行修改。
class Index_calculation:
def __init__(self, array):
# 初始化指标序列
self.array = array
# 极小型 --> 极大型
def samll_to_big(self):
max_num = max(self.array)
result = max_num - self.array
# result = 1/self.array
return result
# 中间型 --> 极大型
def middle_to_big(self, best):
M = max(abs(self.array - best))
result = 1 - abs(self.array - best) / M
return result
# 区间型 --> 极大型
def interval_to_big(self, a, b):
M = max([a - min(self.array), max(self.array) - b])
result = self.array.copy()
result[result < a] = 1 - (a - result[result < a]) / M
result[(a < result) & (result < b) | (result == a) | (result == b)] = 1
result[result > b] = 1 - (result[result > b] - b) / M
return result
if __name__ == '__main__':
n,m = matrix.shape



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
VeaA-1715816784445)]
[外链图片转存中...(img-jG9bdBoh-1715816784445)]
[外链图片转存中...(img-xrkYFBjV-1715816784445)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 1522
1522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









