








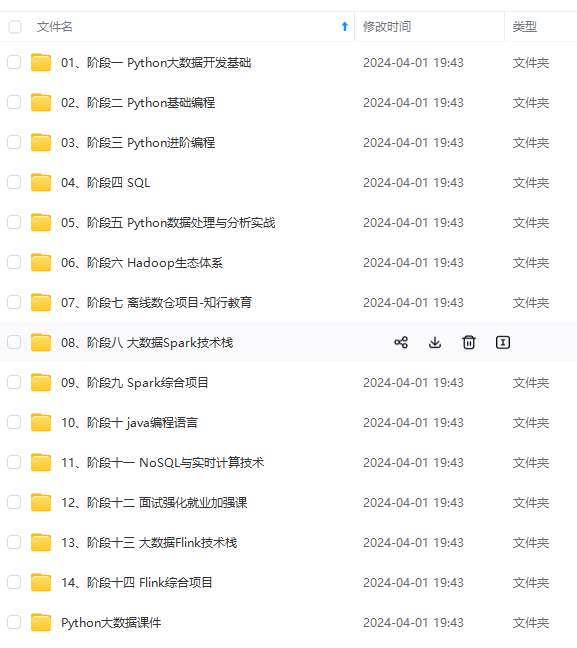
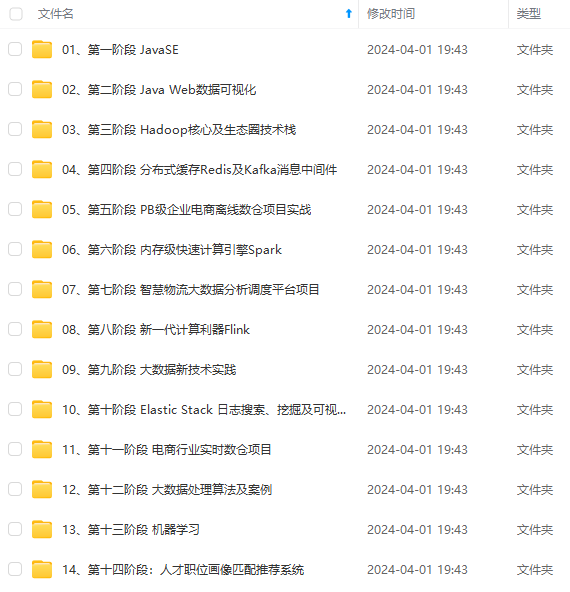
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
Hadoop在处理大数据时候特别需要注意:
1、 非常适合处理超大规模的数据集(TB,PB量级),非常不适合处理大量小文件。
2、 Hadoop一次写入,多次读写。Hadoop不支持随机修改文件。
3、Hadoop数据处理高延迟,数据的实时性不高。原因很显然,因为处理的数据规模非常大且是以分布式方式存储,读写访问需要花费更多时间。
Hadoop特点总结:不适合低延迟数据访问、无法高效存储大量小文件、不支持多用户写入及任意修改文件。
Hive
简单说,Hive提供了一种独特的SQL查询语句,使得熟悉SQL的开发者通过编写SQL语句即可访问Hadoop存储的海量数据,通过hive的SQL查询语句,开发者可以在一定程度上绕过MapReduce。hive可以用SQL的语言转化成Map Reduce任务对hdfs数据的查询分析。hive的使用者无需写Map Reduce任务,掌握SQL可完成查询分析工作。
Hbase
Hbase是一种NoSQL数据库。HBase是非关系型数据库(Nosql),在某些业务场景下,数据存储查询在Hbase的使用效率更高。
Yarn
Yarn是分布式集群资源管理框架。
MapReduce的Shuffle
MapReduce在任务结束后将数据存放到硬盘中。Hadoop的MapReduce计算模型存在问题是: MapReduce关键过程是Shuffle(洗牌),在整个Shuffle过程中,基于MapReduce计算引擎通常会将结果输出到硬盘上而不是直接在内存中,进行存储和容错。
Spark是在MapReduce基础上发展而来。Spark支持Scala语言和Java语言。Spark在数据尚未写入硬盘时即可在内存进行计算。
Spark Streaming
Spark Streaming基于微批量方式计算,处理实时流数据。数据可以从Kafka或TCP套接字等众多来源获取,并且可以使用高级函数(如 map,reduce,join 和 window)开发复杂算法进行实时流数据处理。最后处理的数据结果可以推送到文件系统,数据库或实时仪表板。
Spark架构
Spark架构采用分布式计算中的Master-Slave模型。Master是对应集群中含有Master进程的节点,Slave是集群中含有Worker进程的节点。Master作为整个集群的控制器,负责整个集群的正常运行。Worker相当于计算节点,接收主节点命令与状态汇报。Executor负责任务的执行。Client作为用户的客户端负责提交应用。Driver负责控制一个应用的执行。
Spark集群部署后,需要在主节点和从节点分别启动Master进程和Worker进程,对整个集群进行控制。在一个Spark应用的执行程序中,Driver和Worker是两个重要的角色。Driver程序是应用逻辑执行的起点,负责作业的调度,即Task任务的发布,而多个Worker用来管理计算节点和创建Executor并行处理任务。在执行阶段,Driver会将Task和Task所依赖的file和jar序列化后传递给对应的Worker机器。

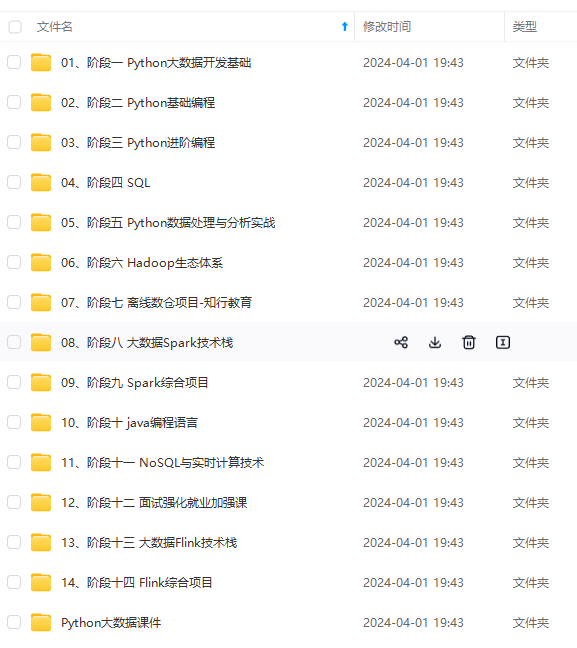
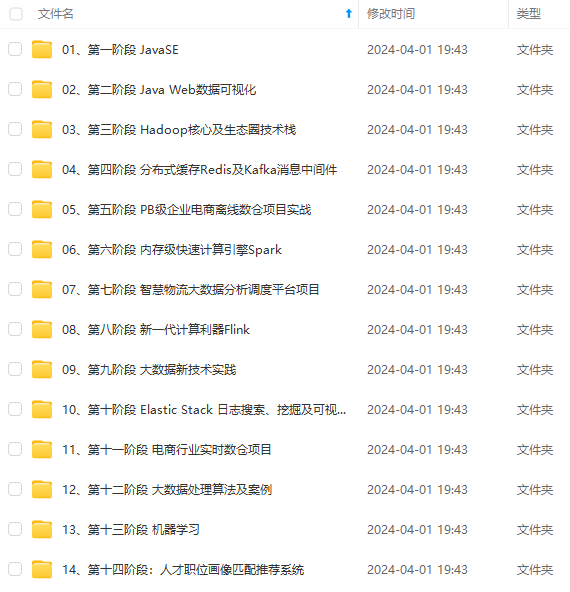
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
,并且后续会持续更新**















 4841
4841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









