







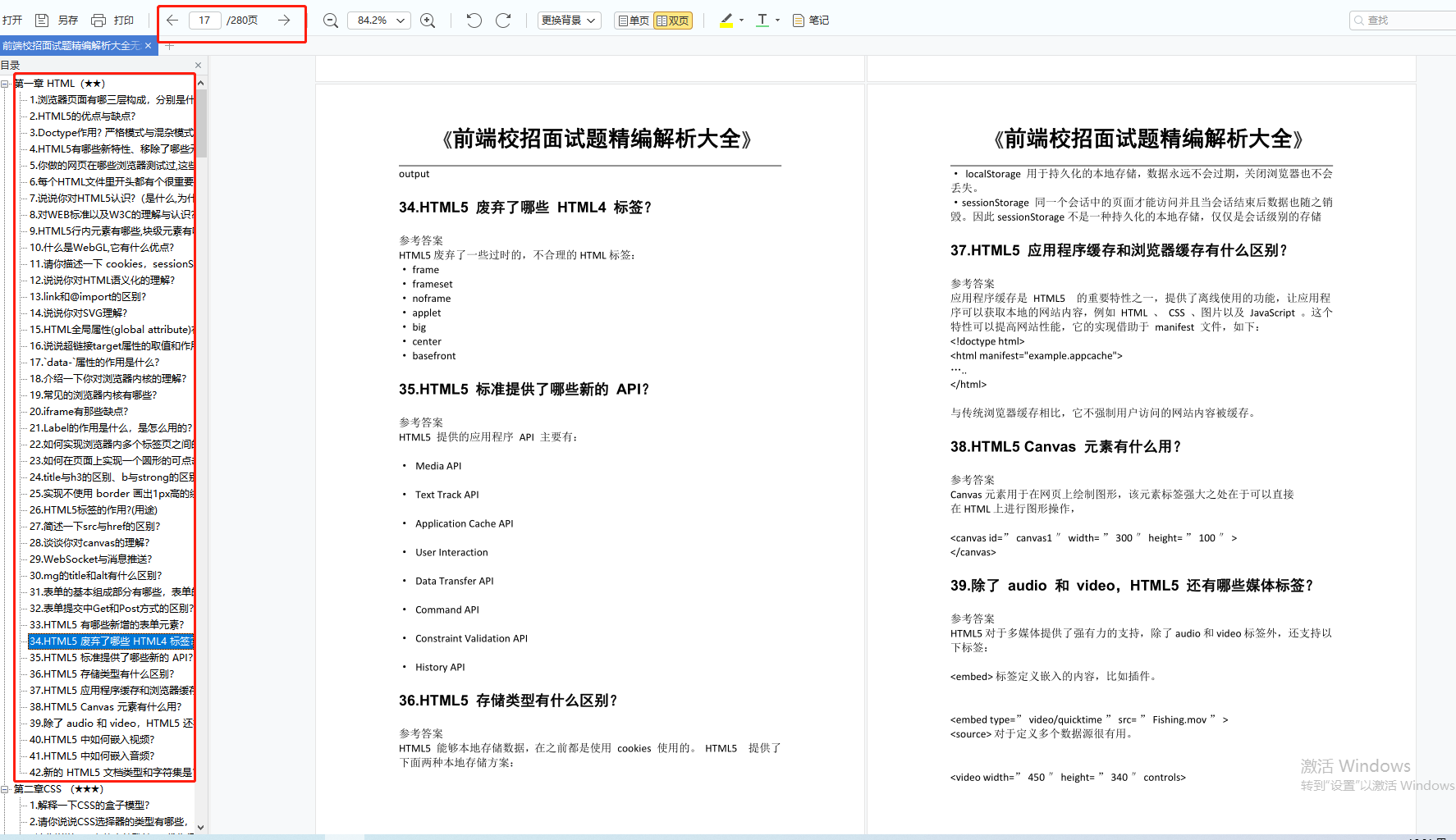
Vue 面试题
1.Vue 双向绑定原理
2.描述下 vue 从初始化页面–修改数据–刷新页面 UI 的过程?
3.你是如何理解 Vue 的响应式系统的?
4.虚拟 DOM 实现原理
5.既然 Vue 通过数据劫持可以精准探测数据变化,为什么还需要虚拟 DOM 进行 diff 检测差异?
6.Vue 中 key 值的作用?
7.Vue 的生命周期
8.Vue 组件间通信有哪些方式?
9.watch、methods 和 computed 的区别?
10.vue 中怎么重置 data?
11.组件中写 name 选项有什么作用?
12.vue-router 有哪些钩子函数?
13.route 和 router 的区别是什么?
14.说一下 Vue 和 React 的认识,做一个简单的对比
15.Vue 的 nextTick 的原理是什么?
16.Vuex 有哪几种属性?
17.vue 首屏加载优化
18.Vue 3.0 有没有过了解?
19.vue-cli 替我们做了哪些工作?
…

算法
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
- 冒泡排序
- 选择排序
- 快速排序
- 二叉树查找: 最大值、最小值、固定值
- 二叉树遍历
- 二叉树的最大深度
- 给予链表中的任一节点,把它删除掉
- 链表倒叙
- 如何判断一个单链表有环
- 给定一个有序数组,找出两个数相加为一个目标数
…

由于篇幅限制小编,pdf文档的详解资料太全面,细节内容实在太多啦,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!有需要的程序猿(媛)可以帮忙点赞+评论666
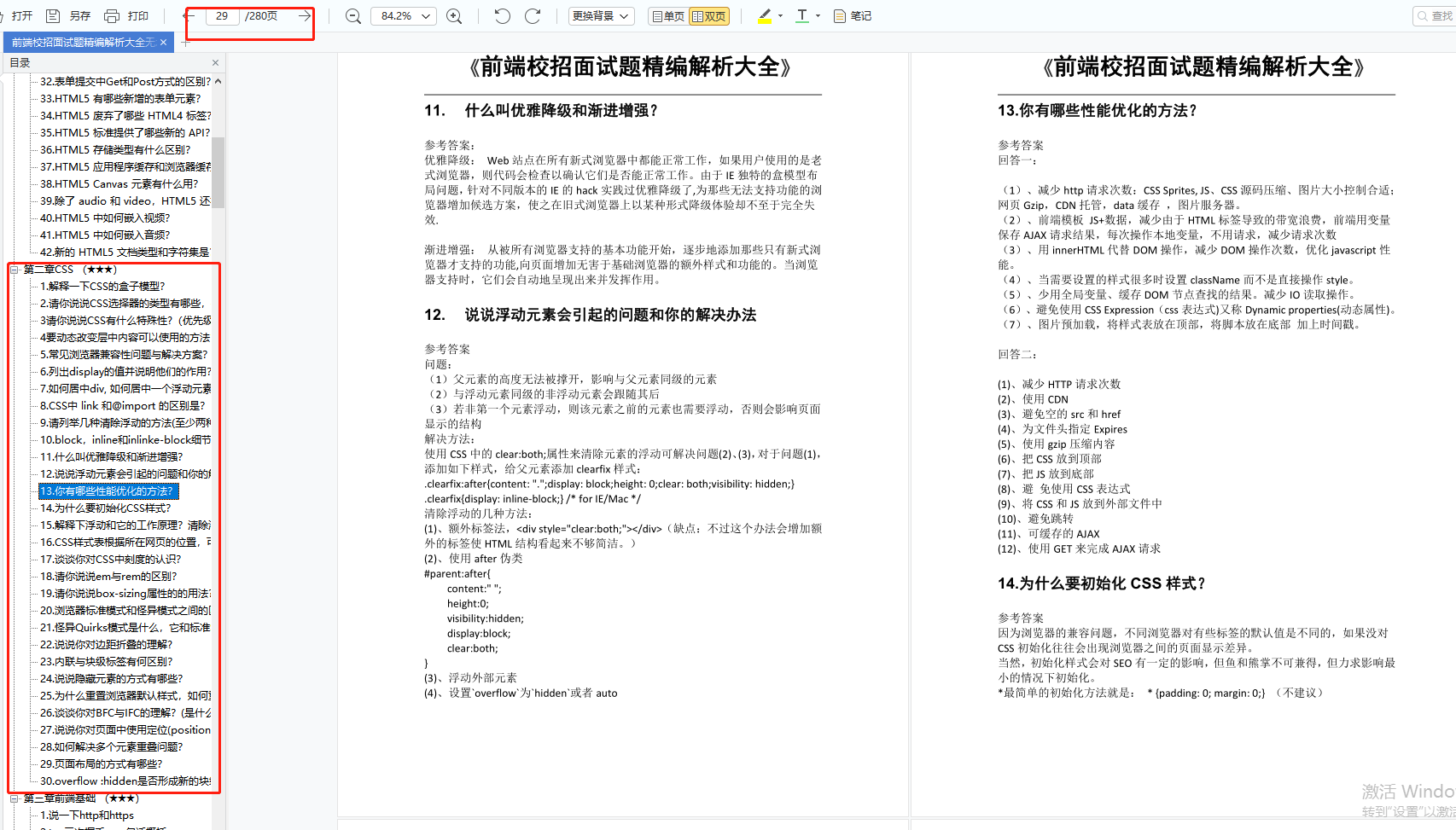
正则表达式从入门到入坑
入坑前先介绍两个辅助网站:
正则表达式测试网站:https://regex101.com
正则表达式思维导图:https://regexper.com
正则基础(入门)
1、元字符
进入正题,我们先去了解最基本的字符及其初步应用。
| 元字符 | 描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。 |
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。 |
| \B | 匹配非单词边界。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。 |
| \n | 匹配一个换行符。 |
| \r | 匹配一个回车符。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配字母、数字、下划线。等价于’[A-Za-z0-9_]'。 |
| \W | 匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]’。 |
不运用起来的知识都不是自己的知识,所以看完总得写点例子建立思维记忆。
比如:
1、匹配有hello开头的字符串:
let str = "hello world";
// 方法一
let reg = /^hello/;
reg.test(str); //true
// 方法二
let reg2 = /\bhello/;
reg2.test(str); //true
这么一看\b和^好像功能差不多,其实不然,我们看下一个例子:
let str = "say hello";
let reg = /^hello/;
reg.test(str); //false
let reg2 = /\bhello/;
reg2.test(str); //true
可以看出\b并不是匹配开头,它匹配的是单词边界。
2、匹配1开头的11位数字的手机号码:
let phone = "13388882983";
let reg = /^1\d\d\d\d\d\d\d\d\d\d$/
3、匹配8的数字、字母和下划线组成的密码:
let password = "A_1234_b"
let reg = /^\w\w\w\w\w\w\w\w$/
2、重复限定符
匹配每一个数字都得写一个/d,代码怎么可以这么冗余,我们追求的是优雅,那该怎么写呢?我们先看下面的限定符。
| 语法 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。 |
| {n,} | n 是一个非负整数。至少匹配n 次。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。配n 次。 |
看完我们对刚刚的正则进行一点点优雅的改造。
1、匹配8的数字、字母和下划线组成的密码:
let password = "A_1234_b"
let reg = /^\w{8}$/
但是产品觉得限制8位太不灵活了,它要8-15位,好,满足它:
let password = "A_1234_b"
let reg = /^\w{8,15}$/
2、匹配以a开头的,中间带有一个或多个b,0个或多个c结尾的字符串:
let reg = /^ab+c*$/;
let str = "abbc";
reg.test(str); //true
let str2 = "abb";
reg.test(str2); //true
let str3 = "acc";
reg.test(str3); //false
3、区间 []
产品想法越来越多,密码希望只能给用户设置由大小写字母和数字组成的8-15位密码,摸了摸刀柄,决定继续满足它。
let reg = /^[A-Za-z0-9]{8,15}$/;
let password = "A123456789b";
reg.test(password); //true
let password2 = "A_1234_b";
reg.test(password2); //false
4、条件或
产品给你点了个赞然后提出了手机号码验证要优化的想法,调查发现VIP客户的手机只有13、156、176、186开头的11位数,要我们进行精确一点匹配。看了一眼它更长的刀,默默的写下下面的正则:
let reg = /^(13\d|156|176|186)\d{8}$/
产品表示很满意,结束了它的基本需求。
5、修饰符
标记也称为修饰符,正则表达式的标记用于指定额外的匹配策略。
标记不写在正则表达式里,标记位于表达式之外,格式如下:
/pattern/flags
| 修饰符 | 含义 | 描述 |
|---|---|---|
| i | ignore - 不区分大小写 | 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别。 |
| g | global - 全局匹配 | 查找所有的匹配项。 |
| m | multiline - 多行匹配 | 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾。 |
| s | 特殊字符圆点 . 中包含换行符 \n | 默认情况下的圆点 . 是匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。 |
let str = 'The fat cat eat the fish on the dish.'
let reg = /the/
str.match(reg); //["the",index:16]
通常正则匹配到第一个就会自动结束,因此我们只能匹配到the fish中的ths就结束了,如果我们希望把后面的"the"也匹配出来呢?这时候我们就要加一个全局匹配修饰符了。
let str = 'The fat cat eat the fish on the dish.'
let reg = /the/g
str.match(reg); //["the","the"]
要是希望把开头大写的"The"也一起匹配出来呢?这时候我们需要再加多一个全局匹配修饰符i。
let str = 'The fat cat eat the fish on the dish.'
let reg = /the/gi
str.match(reg); //["The","the","the"]
一般我们使用^或$只会匹配文章的开头和结尾。
let str = 'The fat cat eat the fish on the dish.\nThe cat is beautiful.'
let reg = /^The/g
str.match(reg); //["The"]
但是如果我们需要匹配各个段落的开头呢?
let str = 'The fat cat eat the fish on the dish.\nThe cat is beautiful.'
let reg = /^The/gm
str.match(reg); //["The","The"]
默认情况下的圆点 . 是匹配除换行符 \n 之外的任何字符。如:
let str = 'The fat cat eat the fish on the dish.\nThe cat is beautiful.'
let reg = /.+/
str.match(reg); //["The fat cat eat the fish on the dish.",...]
我们发现遇到\n的时候会切换了匹配,如果我们想继续完全匹配下去,需要加上修饰符s。
let str = 'The fat cat eat the fish on the dish.\nThe cat is beautiful.'
let reg = /.+/s
str.match(reg); //['The fat cat eat the fish on the dish.\nThe cat is beautiful.',...]
6、运算符优先级
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
相同优先级的从左到右进行运算,不同优先级的运算先高后低。下表从最高到最低说明了各种正则表达式运算符的优先级顺序:
| 运算符 | 描述 |
|---|---|
| \ | 转义符 |
| (), (?: ), (?=), [] | 圆括号和方括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
Js正则常用方法
1、定义正则
定义正则有下面两种方式:
// 第一种
//RegExp对象。参数就是我们想要制定的规则。
let reg = new RegExp("a");
// 第二种
// 简写方法 推荐使用 书写简便、性能更好。
let reg = /a/;
2、test()
在字符串中查找符合正则的内容,若查找到返回true,反之返回false。
例:
let reg = /^ab+c*$/;
let str = "abbc";
reg.test(str); //true
3、match()
在字符串中搜索复合规则的内容,搜索成功就返回内容,格式为数组,失败就返回null。
例:
let str = 'The fat cat eat the fish on the dish.';
let reg = /the/;
str.match(reg); //["the",index:16,...]
全局匹配匹配到多个是则在数组中按序返回,如:
let str = 'The fat cat eat the fish on the dish.';
let reg = /the/g;
str.match(reg); //["the","the"]
4、search()
在字符串搜索符合正则的内容,搜索到就返回坐标(从0开始,如果匹配的不只是一个字母,那只会返回第一个字母的位置), 如果搜索失败就返回 -1 。
例:
let str = 'abc';
let reg = /bc/;
str.search(reg); //1
5、exec()
和match方法一样,搜索符合规则的内容,并返回内容,格式为数组。
let str = 'The fat cat eat the fish on the dish.';
let reg = /the/;
reg.exec(str); //["the",index:16]
如果是全局匹配,可以通过while循环 找到每次匹配到的信息。如:
let str = 'The fat cat eat the fish on the dish.';
let reg = /the/g;
let res = "";
while(res = reg.exec(str)){
console.log(res);
}
/**
* 匹配到两次
* 第一次:
* [
0: "the"
groups: undefined
index: 16
input: "The fat cat eat the fish on the dish."
* ]
*
* 第二次:
* [
0: "the"
groups: undefined
index: 28
input: "The fat cat eat the fish on the dish."
* ]
*/
6、replace()
查找符合正则的字符串,就替换成对应的字符串。返回替换后的内容。
replace方法接收两个参数,第一个是正则,第二个是替换字符/回调方法,我们下面分别举例说明:
例1:
let str = 'abc';
let reg = /a/;
str.replace(reg,"A"); //"Abc"
例2:
let str = 'abc';
let reg = /a/;
str.replace(reg,function(res){
console.log(res); //'a'
return "A"; //不return则会返回undefine,输出结果则会变成"undefinedbc"。
}); //"Abc"
除此以外replace还有更深入的用法,会放在后面入坑那里再说。
正则进阶(入坑)
1、零宽断言
我们先去理解零宽和断言分别是什么。
–零宽:就是没有宽度,在正则中,断言只是匹配位置,不占字符,也就是说,匹配结果里是不会返回断言本身。
–断言:俗话的断言就是“我断定什么什么”,而正则中的断言,就是说正则可以指明在指定的内容的前面或后面会出现满足指定规则的内容。
总结:
零宽断言正如它的名字一样,是一种零宽度的匹配,它匹配到的内容不会保存到匹配结果中去,最终匹配结果只是一个位置而已。
javascript只支持零宽先行断言,而零宽先行断言又可以分为正向零宽先行断言,和负向零宽先行断言。
1、 正向先行断言(正向肯定预查):
–语法:(?=pattern)
–作用:匹配pattern表达式的前面内容,不返回本身。
我们来举个栗子:
The fat cat eat the fish on the dish.
我们希望拿到fat前面的字符串The。
let str = 'The fat cat eat the fish on the dish.'
let reg = /the(?=\sfat)/gi
str.match(reg); //["The"]
2、负向先行断言(正向否定预查):
–语法:(?!pattern)
–作用:匹配pattern表达式的前面内容,不返回本身。
那如果我们希望拿到不是fat前面的字符串The呢?很简单:
let str = 'The fat cat eat the fish on the dish.'
let reg = /the(?!\sfat)/gi
str.match(reg); //["the","the"]
### 最后
在面试前我花了三个月时间刷了很多大厂面试题,最近做了一个整理并分类,主要内容包括html,css,JavaScript,ES6,计算机网络,浏览器,工程化,模块化,Node.js,框架,数据结构,性能优化,项目等等。
包含了腾讯、字节跳动、小米、阿里、滴滴、美团、58、拼多多、360、新浪、搜狐等一线互联网公司面试被问到的题目,涵盖了初中级前端技术点。
* HTML5新特性,语义化
* 浏览器的标准模式和怪异模式
* xhtml和html的区别
* 使用data-的好处
* meta标签
* canvas
* HTML废弃的标签
* IE6 bug,和一些定位写法
* css js放置位置和原因
* 什么是渐进式渲染
* html模板语言
* meta viewport原理
* **[开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)**
,项目等等。
包含了腾讯、字节跳动、小米、阿里、滴滴、美团、58、拼多多、360、新浪、搜狐等一线互联网公司面试被问到的题目,涵盖了初中级前端技术点。
* HTML5新特性,语义化
* 浏览器的标准模式和怪异模式
* xhtml和html的区别
* 使用data-的好处
* meta标签
* canvas
* HTML废弃的标签
* IE6 bug,和一些定位写法
* css js放置位置和原因
* 什么是渐进式渲染
* html模板语言
* meta viewport原理

* **[开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)**

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









