






1.RDD是有分区的。
RDD的分区是RDD数据存储的最小单位。一份数据本质是分隔了多个分区。 如下图示,假如1个RDD有3个分区,RDD内存储了123456,那么数据本质上分散在三个分区内进行存储。
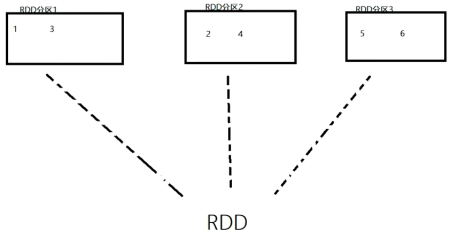
举个生活中的例子:高考的时候,每个班的同学都打散到不同的考场,此时的高3(8)班就是一个抽象的概念,在实际中,这个班级的学生可能分布在5个不同的考场。
2.计算函数会作用于每个分区
RDD的方法会作用在所有的分区上。
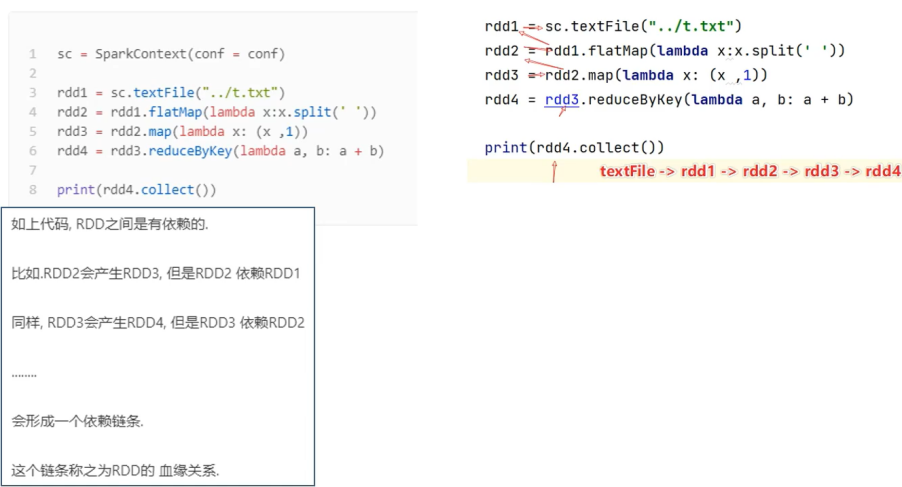
3.每个RDD之间是有依赖关系(RDD有血缘关系)
RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
4.Key-Value型的RDD可以有分区器
数据默认分区器:Hash分区规则,可以手动设置一个分区器(rdd.partitionBy的方式来设置)
5.每一个分区都有一个优先位置列表
优先位置列表会存储每个Partition的优先位置,对于一个HDFS文件来说,就是每个Partition块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度时,会尽可能地将任务分配到其所要处理数据块的存储位置。

















 1959
1959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









