






大家好,给大家分享一下python 爬取网页内容并保存到数据库,很多人还不知道这一点。下面详细解释一下。现在让我们来看看!
Source code download: 本文相关源码
requests库


PS:还有一个库叫做urllib.request,但能用它做的事情,requests库就够了,不用多学。
# 打开百度网页,查看状态码和html代码
import requests
import urllib3
# 不让弹出https的 verify=False 的InsecureRequestWarning
urllib3.disable_warnings()
url1 = 'https://www.baidu.com'
headers1 = {
'user-agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 81.0.4044.122Safari / 537.36',
'Connection': 'keep-alive'
}
body = ''
response = requests.get(url=url1, data=body, headers=headers1, verify=False)
比如这种东西就需要传入bodypython编程代码画红心。
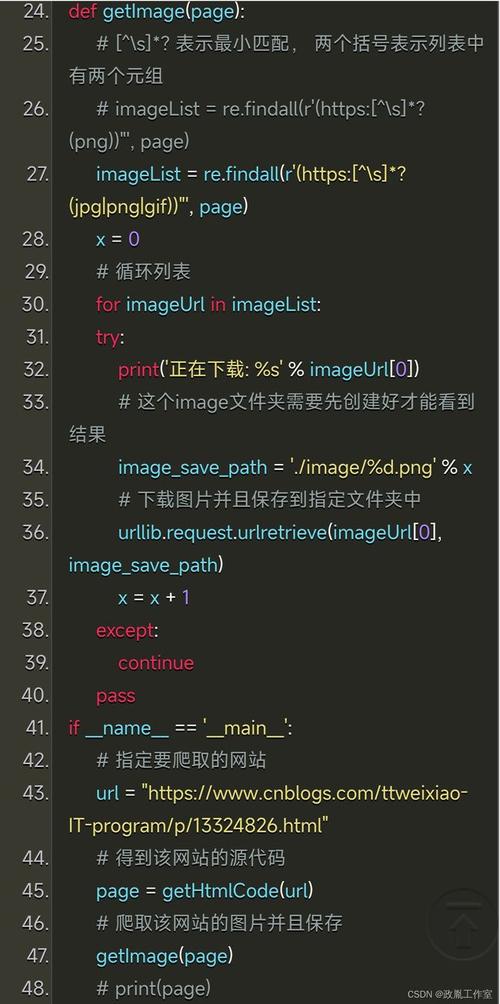
# 下载一个图片
import requests
response = requests.get('http://ss.bdimg.com/static/superman/img/topnav/baiduyun@2x-e0be79e69e.png')
# 写入图片
with open('test.png', 'wb') as fp:
# 判断状态码
if response .status_code == 404:
print(['response.status_code'], response.status_code)
# 写入数据
else:
fp.write(response.content)
解析文档树
bs4

# 打开百度网页,查看状态码和html代码
import requests
from bs4 import BeautifulSoup
url1 = 'https://www.baidu.com'
headers1 = {
'user-agent':
'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 81.0.4044.122Safari / 537.36',
'Connection': 'keep-alive'
}
response = requests.get(url=url1, headers=headers1, verify=False)
bs = BeautifulSoup(response.text, 'html.parser')
# <class 'bs4.BeautifulSoup'>
print(bs.__class__)
# 找到所有'img'的标签
for item in bs.find_all('img'):
# 输出该标签的html代码
print(item)
# 输出该标签的src属性
print(item.get('src'))
etree的xpath
from lxml import etree
elemt = etree.HTML(html)
img_list = elemt.xpath('//img[@src]') # 找到的是列表,哪怕只有一个
first_img_src = img_list[0].get('src') # 获取第一个元素
改进
多线程
fake_useragent
>>> from fake_useragent import UserAgent
>>> ua = UserAgent()
>>> ua.ie
Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US);
>>> ua.chrome
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2'
>>> ua.firefox
Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/16.0.1
>>> ua.safari
Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5355d Safari/8536.25
>>> ua.msie
Mozilla/5.0 (compatible; MSIE 10.0; Macintosh; Intel Mac OS X 10_7_3; Trident/6.0)'
>>> ua.opera
Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11
>>> ua['Internet Explorer']
Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; GTB7.4; InfoPath.2; SV1; .NET CLR 3.3.69573; WOW64; en-US)
>>> ua.google
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4) AppleWebKit/537.13 (KHTML, like Gecko) Chrome/24.0.1290.1 Safari/537.13
>>> ua['google chrome']
Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11
>>> ua.ff
Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1
# and the best one, random via real world browser usage statistic
>>> ua.random
'Mozilla/5.0 (X11; NetBSD) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36'
from fake_useragent import UserAgent
headers = {'User-Agent': UserAgent().random}
other
m3u8文件

如果要下载视频的话,网站传给我们的是ts格式的分段视频,网站的分段方式是start和end标记一个小视频的大小。因此会遇到一个问题,那就是我们如何知道start和end的。
在m3u8文件中记载了这个东西,只要我们得到m3u8文件就行。
def get_ts_urls(m3u8_path):
start_end_list = []
with open(m3u8_path, "r") as file:
# 读取全部的行,待'\n'换行符
lines = file.readlines()
for line in lines:
# 如果以XXX结尾
if line.endswith("&type=mpegts\n"):
start_end_list.append(line.strip("\n"))
return start_end_list
webbrowser
内置库webbrowser:在浏览器中打开网址
import webbrowser as web
url = 'http://www.baidu.com'
web.open_new_tab(url) # 使用默认浏览器
# 指定浏览器
chromepath = r'C:\Users\???\AppData\Local\Google\Chrome\Application\Chrome.exe'
web.register('chrome', None, web.BackgroundBrowser(chromepath))
open_flag = web.get('chrome').open_new_tab(url)
print(open_flag)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









