






 本文详细介绍了如何使用Python的urllib库进行网页抓取,包括urlopen方法、User-Agent设置、处理HTTP错误、Cookie登录、以及使用代理服务器。作者展示了如何处理中文编码问题和进行POST请求,提供了解决常见爬虫问题的实用技巧。
本文详细介绍了如何使用Python的urllib库进行网页抓取,包括urlopen方法、User-Agent设置、处理HTTP错误、Cookie登录、以及使用代理服务器。作者展示了如何处理中文编码问题和进行POST请求,提供了解决常见爬虫问题的实用技巧。
这篇文章主要介绍了python 爬取网页内容并保存到数据库,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。

python 中 集成了 urllib
urllib
import urllib.request
# urlopen 方法
url="url"
response = urllib.request.urlopen(url)
print(type(response ))
print(response.read())
# 解码 字节--->字符串 decode 字符串--》字节 encode
print(response.read().decode("utf-8"))
# readline 读取一行
print(response.readline())
# 一行一行的读取 返回是列表
print(response.readlines())
# 获取状态码 200 400 500等
print(response.getcode())
# 获取headers
print(response.getheads())
# urlretrieve 方法 请求网页、图片、视频 同时下载他们
# 下载网页,下载图片 下载视频
url_page="xx"
# url:代表的下载的路径,filename 下载下来文件存储的文件的名字
urllib.request.urlretrieve(url=url_page,filename="xxx")
UA User Agent
用户代理,简称UA,它是特殊的字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU类型、浏览器及版本。
浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等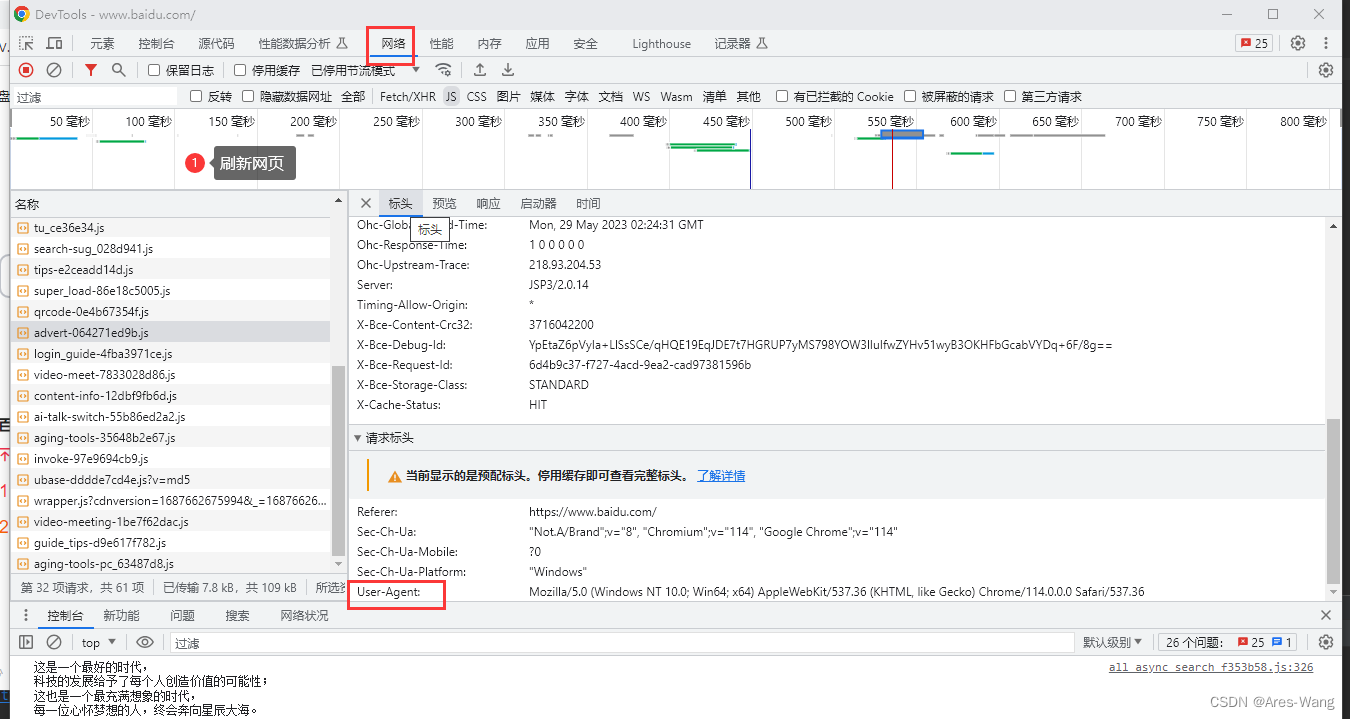
# https 协议 是ssl, 所以需要模拟代理
from urllib import request
heads = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
# 关键字传参
req = request.Request(url="https://www.baidu.com", data=None, headers=heads)
response = request.urlopen(req)
print(response.read().decode('utf-8'))
UnicodeEncodeError: ‘ascii’ codec can’t encode character ‘\u6211’ in position 9: ordinal not in range(128)
将汉字转换unicode 统一编码 两种方法
quote 应用场景 单个参数
①urllib.parse.quote(“中文”) 转换成unicode字符
urlencode 应用场景 多个参数的时候
②urllib.parse.urlencode({字典})
POST 请求

# POST 请求
from urllib import request
from urllib import parse
heads = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
url = 'https://fanyi.baidu.com/sug'
data = {
'kw': "Ares"
}
# encode 转换字节 post 请求,要encode编码,get 不需要encode()
new_data = parse.urlencode(data).encode('utf-8')
print(new_data)
# Request 不需要传参数 method='post'
req = request.Request(url=url, data=new_data, headers=heads)
# 模拟浏览器向服务器发送请求
response = request.urlopen(req)
content = response.read().decode('utf-8')
print(content)
# 上面打印的json字符串,且中文为unicode编码
import json
obj = json.loads(content)
# 打印中文的json对象
print(obj)
Cookie 反爬

异常 HTTPError URLError
- HTTPError类是URLError类的子类
- 导入的包urllib.error.HTTPError urllib.error.URLError
- http报错:http错误是针对浏览器无法连接到服务器而增加出来的错误提示用python绘制满天星代码。引导并告诉浏览者该页是哪里出了问题
- 通过urllib发送请求的时候,有可能会发送失败。这个时候如果想让你的代码更加的健壮,可以通过try: except进行捕获异常。
Cookie 登录
适应场景:数据采集时,需要绕过登录,然后进入到某个页面
个人信息页面是utf-8,但还说报错了编码错误,因为并没有进入到个人信息页面,而是跳转到登录页面了,同时登录页面不是utf-8编码,所以报错
代理
Handler 处理器
# Handler 访问百度,获取百度源码
from urllib import request
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
url = 'https://www.baidu.com/'
# 创建request请求对象
req = request.Request(url=url,headers=headers)
# handler build_opener open
# 获取handler 对象
# handler = request.HTTPHandler()
# ProxyHandler 代理服务器,相当于用别的IP地址访问百度,
proxies = {
'http':'xxx.xx.xx.xx:port'
}
handler = request.ProxyHandler(proxies=proxies)
# 获取opener对象
opener = request.build_opener(handler)
# 调用open方法
response = opener.open(req)
content = response.read().decode('UTF-8')
print(content)
代理服务器
通过random.choice 在代理池中随机选择代理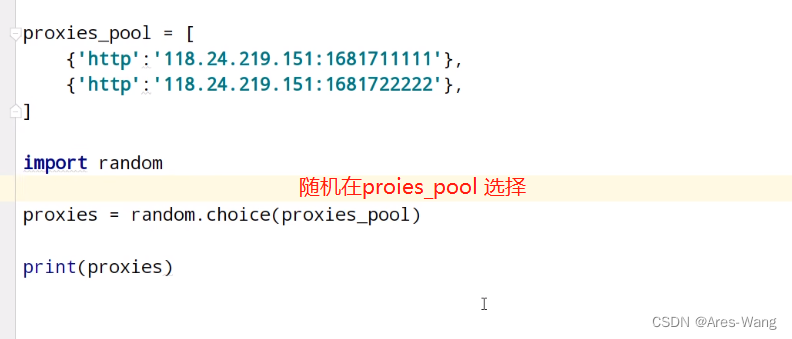
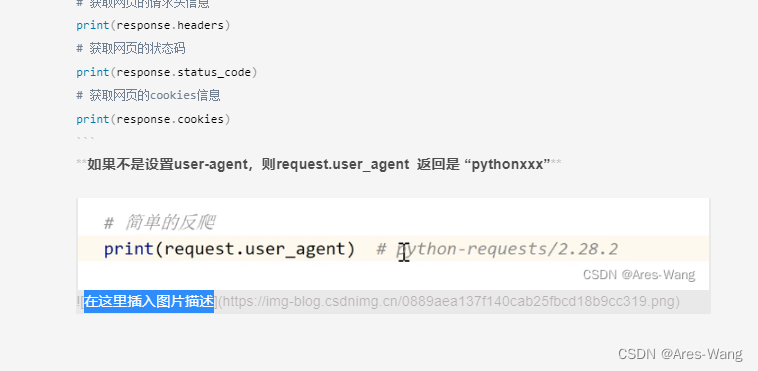















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









