







主要是`PyIntObject`和`PyInt_Type`,其他和普遍的PyObject, PyTyoeObject没什么,值得关注的有
* python2中稍小一点的数直接用C语言中的long去存储,稍大一点的数(超过long的承受范围)会使用python的long对象去存储,而python3不会作区分,统一用longObect去存储,实现用到了`柔性数组`,感兴趣可以查一下
* 小整形数组的内存池和大整形对象的内存链的维护,避免频繁malloc
在Python中,整数的使用是很广泛的,对应的,它的创建和释放也将会很频繁,那么如何设计一个高效的机制,使得整数对象的使用不会成为Python的瓶颈?在Python中是使用整数对象的缓冲池机制来解决此问题。使用缓冲池机制,那意味着运行时的整数对象并不是一个个独立的,而是相关联结成一个庞大的整数对象系统了。
### 小整形对象
// [intobject.c]
#ifndef NSMALLPOSINTS
#define NSMALLPOSINTS 257
#endif
#ifndef NSMALLNEGINTS
#define NSMALLNEGINTS 5
#endif
#if NSMALLNEGINTS + NSMALLPOSINTS > 0
/* References to small integers are saved in this array so that they
can be shared.
The integers that are saved are those in the range
-NSMALLNEGINTS (inclusive) to NSMALLPOSINTS (not inclusive).
*/
static PyIntObject *small_ints[NSMALLNEGINTS + NSMALLPOSINTS];
#endif
在实际的编程中,数值比较小的整数,比如1,2,等等,这些在程序中是频繁使用到的,而Python中,所有的对象都存活在系统堆上,也就是说,如果没有特殊的机制,对于小整数对象,Python将一次次的malloc在堆上申请空间,然后free,这样的操作将大大降低了运行效率。
那么如何解决呢?Python中,对小整数对象使用了对象池技术。
那么又有一个问题了,Python中的大对象和小对象如何区分呢?嗯,Python中确实有一种方法,用户可以调整大整数和小整数的分界点,从而动态的确定小整数的对象池中应该有多少个小整数对象,但是调整的方法只有自己修改源代码,然后重新编译。
### 大整数对象
对于小整数,小整数对象池中完全的缓存PyIntObject对象,对于其它对象,Python将提供一块内存空间,这些内存空间将由这些大整数轮流使用,也就是谁需要的时候谁使用。
比如,在Python中有一个PyIntBlock结构,维护了一块内存,其中保存了一些PyIntObject对象,维护对象的个数也可以做动态的调整。在Python运行的某个时刻,有一些内存已经被使用,而另一些内存则处于空闲状态,而这些空闲的内存必须组织起来,那样,当Python需要新的内存时,才能快速的获得所需的内存,在Python中使用一个单向链表(free\_list)来管理所有的空闲内存。
// [intobject.c]
#define BLOCK_SIZE 1000 /* 1K less typical malloc overhead */
#define BHEAD_SIZE 8 /* Enough for a 64-bit pointer */
#define N_INTOBJECTS ((BLOCK_SIZE - BHEAD_SIZE) / sizeof(PyIntObject))
struct _intblock {
struct _intblock *next;
PyIntObject objects[N_INTOBJECTS];
};
typedef struct _intblock PyIntBlock;
static PyIntBlock *block_list = NULL;
static PyIntObject *free_list = NULL;
**创建**
如果小整数对象池机制被激活,则尝试使用小整数对象池;如果不能使用小整数对象池,则使用通用整数对象池。
可以创建int的代码理解这两块的使用
// [intobject.c]
PyObject *
PyInt_FromLong(long ival)
{
register PyIntObject *v;
#if NSMALLNEGINTS + NSMALLPOSINTS > 0 /* 尝试使用小整数对象池 */
if (-NSMALLNEGINTS <= ival && ival < NSMALLPOSINTS) {
v = small_ints[ival + NSMALLNEGINTS];
Py_INCREF(v);
return (PyObject *) v;
}
#endif
if (free_list == NULL) {
if ((free_list = fill_free_list()) == NULL)
return NULL;
}
/* Inline PyObject_New */
v = free_list;
free_list = (PyIntObject *)v->ob_type; /* 有一个看似不合适但是比较方便的地方,freelist会通过 ob_type存放可用空间的pyObject的地址(类似链表的next),而不是 PyTyoeObject */
(void)PyObject_INIT(v, &PyInt_Type);
v->ob_ival = ival;
return (PyObject *) v;
}
下面是关于freelist的申请,和freelist和block\_list的维护有关的代码
// [intobject.c]
static PyIntObject *
fill_free_list(void)
{
PyIntObject *p, *q;
/* 申请大小为sizeof(PyIntBlock)的内存空间,并链接到已有的block list中 */
p = (PyIntObject *) PyMem_MALLOC(sizeof(PyIntBlock));
((PyIntBlock *)p)->next = block_list;
block_list = (PyIntBlock *)p;
/* 将PyIntBlock中的PyIntObject数组——objects转变成单向链表*/
p = &((PyIntBlock *)p)->objects[0];
q = p + N_INTOBJECTS;
while (–q > p)
q->ob_type = (struct _typeobject *)(q-1); /* 上一段代码中所提到的不合适的地方
Py_TYPE(q) = NULL;
return p + N_INTOBJECTS - 1;
}
这样,freelist会指向可以分配内存的地址,但是如果由之前分配的PyIntObject被释放了,freelist需要将被释放的地址重新使用才可以,这个是通过PyIntObect的析构函数来实现的
// [intobject.c]
static void
int_dealloc(PyIntObject *v)
{
if (PyInt_CheckExact(v)) { // 如果不是派生类这么执行,保证freelist的完整性
v->ob_type = (struct _typeobject *)free_list;
free_list = v;
}
else // 如果是派生类,则执行正常的析构流程
v->ob_type->tp_free((PyObject *)v);
}
## Python中的字符串对象
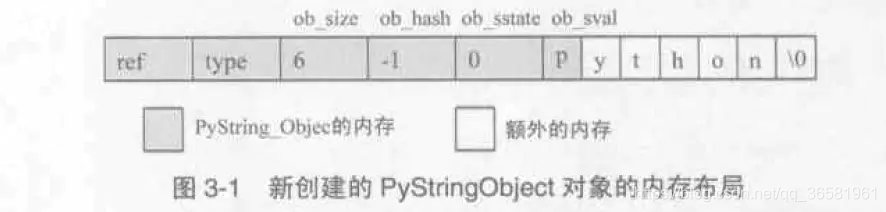
### PyStringObject和PyString\_Type
//[stringobject.h]
typedef struct{
PyObject_VAR_HEAD
long ob_shash;
int ob_sstate;
char ob_sval[1];
} PyStringObject;
//[stringobject.c]
PyTypeObject PyString_Type = {
PyObject_HEAD_INIT(&PyType_Type)
0,
“str”,
sizeof(PyStringObject), // basic size
sizeof(char), //itemsize
// …
}
>
> * `ob_sval`指的是一段长度为ob\_size+1个字节的内存,必须满足ob\_sval[ob\_size] == ‘\0’
> * `ob_shash`是`缓存`的该对象的`hash`值
> * `ob_sstate`标记了该对象是否已经经过intern机制的处理
>
>
>
### 创建PyStringObject对象
//[stringobject.c]
// 从原生字符串创建
PyObject* PyString_FromString(const char *str) {
register size_t size;
register PyStringObejct *op;
size = strlen(str);
if (size > PY_SSIZE_T_MAX) {
return NULL;
}
if (size == 0 && (op = nullstring )!= NULL) { // intern机制: 和下面的一个分支都是为了缓存特定的对象,一个是空字符串,一个是单个字符字符串,第一次使用后会存在,之后不必再次创建PyObject对象(这些对象之前都被初始化成了NULL)
return (PyObject \*) op;
}
if (size == 1 && (op = characters[\*str & UCHAR_MAX]) != NULL) {
return (PyObject \*) op;
}
op = (PyStringObject \*)PyObject\_MALLOC(sizeof(PyStringObject) + size); // 加上包含'\0'的额外内存
PyObject\_INIT\_VAR(ob, &PyString_Type, size);
op->ob_shash=-1;
op->ob_sstate=SSTATE_NOT_INTERNED;
memcpy(op->ob_sval, str, size+1);
if (size==0) {
PyObject \*t = (PyObject \*) op;
PyString\_InternInPlace(&t);
op = (PyStringObject \*) t;
nullstring = op;
} else if (size == 1) {
PyObject \*t = (PyObject \*) op;
PyString\_InternInPlace(&t);
op = (PyStringObject \*) t;
characters[\*str & UCHAR_MAX] = op;
}
return (PyObejct \*) op;
}
### 字符串对象的intern机制
//[stringobject.c]
void PyString_InternInPlace(PyObject **p) {
register PyStringObject *s = (PyStringObject *)(*p);
PyObject *t;
if (!PyString_CheckExact(s)) return;
if (PyString_CHECK_INTERNED(s)) return;
if (interned == NULL) {
interned = PyDict_New();
}
t = PyDict_GetItem(interned, (PyObject *) s);
if (t) {
Py_INCREF(t);
Py_DECREF(*p);
*p = t;
return;
}
PyDict_SetItem(interned, (PyObject *)s, (PyObject *)s);
s->ob_refcnt -= 2; // 减去key 和 value的引用
PyString_CHECK_INTERNED(s) = SSTATE_INTERNED_MORTAL; // 当析构时会根据这个属性,做出在interned中删除的操作
}
>
> characters 是静态变量static PyStringObject \*characters[UCHAR\_MAX+1]; 开始都是NULL指针
> = join字符串效率比 + 好, 因为PyStringObject 是不可变对象(varObject只是因为是变长的),两者申请内存不同
> join 计算所有 PyStringObject 的size 得出需要分配的内存,一次分配
> = 而concat(+) 需要分配n-1次内存,并且伴有析构
>
>
>
## python中的List对象
// [listobject.h]
typedef struct{
PyObject_VAR_HEAD
PyObject **ob_item; // list[0] 实际就是ob_item[0]
int allocated; // 类似cap, 而ob_size是当前的元素数量
} PyListObject;
实际的操作和c++ vector类似略。有一个比较特别的是free\_list的维护
// [listobject.c]
// list只有这一个创建入口
PyObject* PyList_New(int size) {
PyListObject *op;
size_t nbytes;
nbytes = size * sizeof(PyObject *);
if (nbytes / sizeof(PyObject *) != (size_t) size)
return PyErr_NoMemory();
if (num_free_lists) {
num_free_lists–; //记录当前free_lists的最大值
op = free_lists[num_free_lists];
_Py_NewReference((PyObejct *) op);
} else {
op = PyObject_GC_New(PyListObject, &PyList_Type);
}
if (size <=0)
op->ob_item = NULL;
else {
op->ob_item = (PyObject **) PyMem_MALLOC(nbytes);
memset(op->ob_item, 0, nbytes);
}
op->ob_size=size;
op->allocated = size;
return (PyObject *) op;
}
define MAXFREELISTS 80
static PyListObject *free_lists[MAXFREELISTS];
static int num_free_lists=0;
// 创建和更新是在释放PyListObject时候维护的
static void list_dealloc(PyListObject *op){
int i;
if (op->ob_item!=NULL) {
i=op->ob_size;
while (–i>=0) {
Py_XDECREF(op->ob_item[i]);
}
PyMem_FREE(op->ob_item);
}
if (num_free_lists < MAXFREELISTS && PyList_CheckExact(op))
free_lists[num_free_lists++] = op; //保存当前释放元素的list
else
op->ob_type->tp_free((PyObject *) op);
}
## python中的Dict对象
实现是散列表,采用二次探针解决冲突
//[dictobject.h]
typedef struct{
Py_ssize_t me_hash;
PyObejct *me_key;
Pyobject *me_value;
} PyDictEntry;
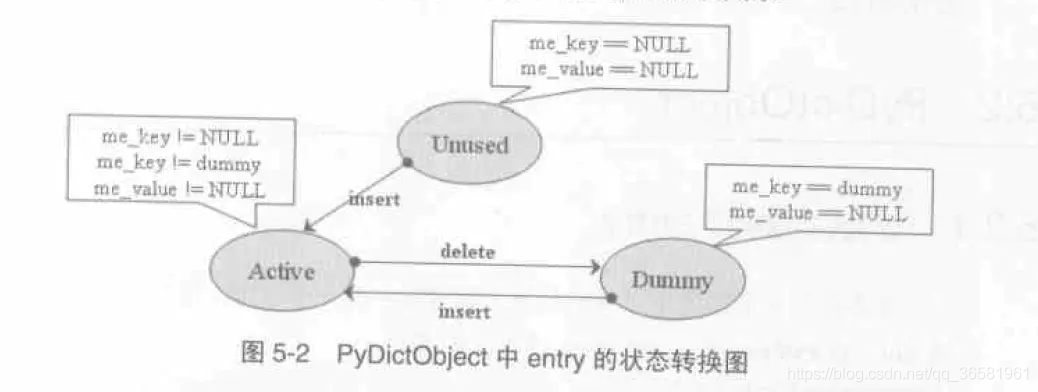
`entry` 会有三种状态 dummy状态是探测连上的元素伪删除后的状态
//[dictobject.h]
#define PyDict_MINSIZE 8
typedef struct _dictobject PyObject;
struct _dictobject{
PyObject_HEAD
Py_ssize_t ma_fill; // active + dummy个数
Py_ssize_t ma_used; // active
Py_ssize_t ma_mask; // 所有的entry个数,之所以这样命名因为hash值会和这个值取&
PyDictEntry *ma_table; // entry数量小于8个时会指向 ma_smalltable
PyDictEntry *(*ma_lookup) (PyDictObject *mp. PyObject *key, long hash);
PyDictEntry ma_smalltable[PyDict_MINSIZE];
}
其他包括缓冲池之类的会和list类似,lookup这块会多点东西。
python提供了两种搜索策略,一个lookdict一个lookdict\_string
//[dictobhect.c]
static dictentry* lookdict(dictobject *mp, PyObejct *key, register long hash){
/** 返回永远不是NULL,而是一个me_value为NULL的entry可以直接被使用, 如果没找到但是有dummy的entry会返回这个dummy
*/

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









