







 本文介绍了如何使用Python爬虫技术,通过分析网页源代码找到图片链接(objURL),并利用正则表达式提取,实现批量下载百度图片。重点讲解了获取网页、解析内容和保存图片到本地的步骤。
本文介绍了如何使用Python爬虫技术,通过分析网页源代码找到图片链接(objURL),并利用正则表达式提取,实现批量下载百度图片。重点讲解了获取网页、解析内容和保存图片到本地的步骤。
接着,把页面切换成传统翻页版(flip),因为这样有利于我们爬取图片!
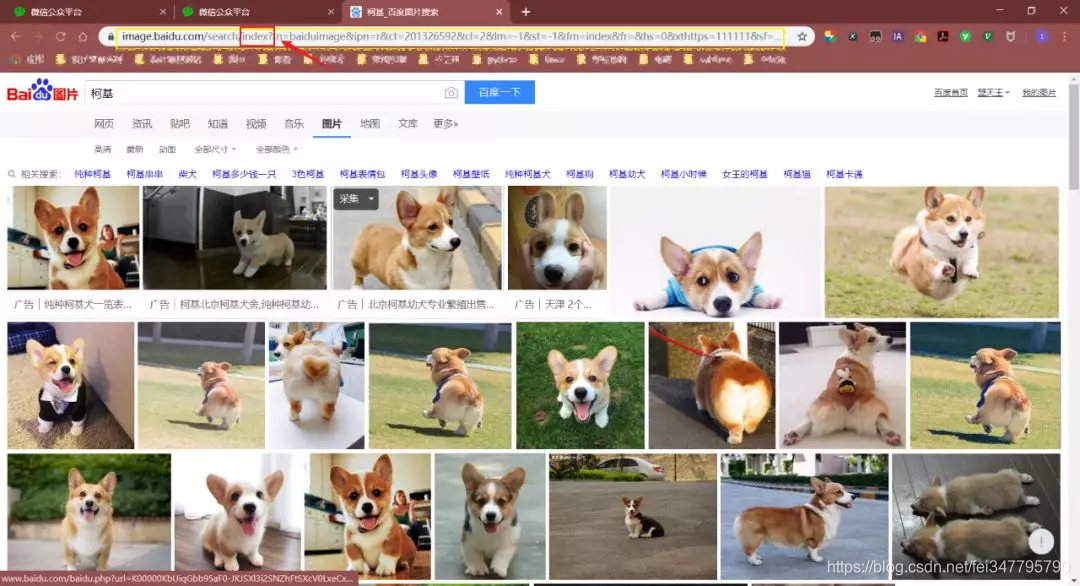
对比了几个url发现,pn参数是请求到的数量。通过修改pn参数,观察返回的数据,发现每页最多只能是60个图片。
注:gsm参数是pn参数的16进制表达,去掉无妨
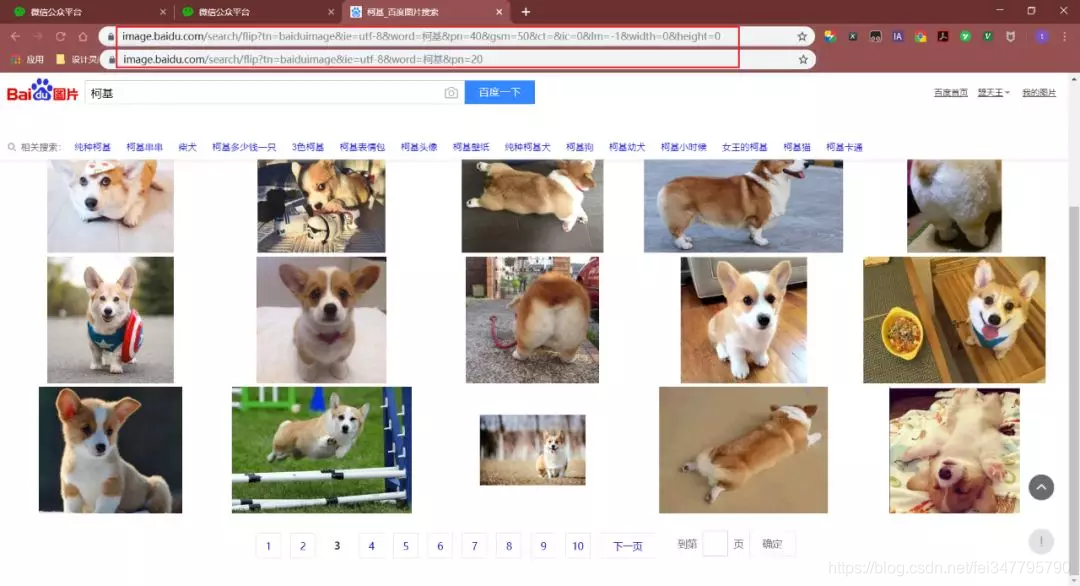
然后,右键检查网页源代码,直接(ctrl+F)搜索 objURL
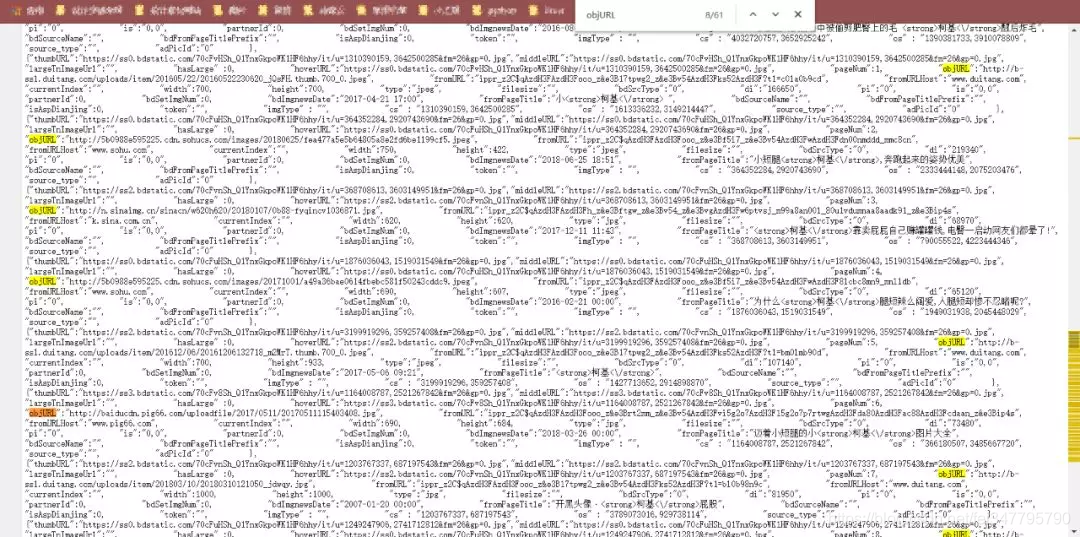
这样,我们发现了需要图片的url了。
现在,我们要做的就是将这些信息爬取出来。
注:网页中有objURL,hoverURL…但是我们用的是objURL,因为这个是原图
那么,如何获取objURL?用正则表达式!
那我们该如何用正则表达式实现呢?其实只需要一行代码…
results = re.findall(‘“objURL”:“(.*?)”,’, html)
1.获取图片url代码:
获取图片url连接
def get_parse_page(pn,name):
for i in range(int(pn)):
1.获取网页
print(‘正在获取第{}页’.format(i+1))
百度图片首页的url
name是你要搜索的关键词
pn是你想下载的页数
url = ‘https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%s&pn=%d’ %(name,i*20)
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4843.400 QQBrowser/9.7.13021.400’}
发送请求,获取相应
response = requests.get(url, headers=headers)
html = response.content.decode()
print(html)
2.正则表达式解析网页
“objURL”:“http://n.sinaimg.cn/sports/transform/20170406/dHEk-fycxmks5842687.jpg”
results = re.findall(‘“objURL”:“(.*?)”,’, html) # 返回一个列表
根据获取到的图片链接,把图片保存到本地
save_to_txt(results, name, i)
2.保存图片到本地代码:
保存图片到本地
def save_to_txt(results, name, i):
j = 0
在当目录下创建文件夹
if not os.path.exists(‘./’ + name):
os.makedirs(‘./’ + name)
下载图片
for result in results:
print(‘正在保存第{}个’.format(j))
try:
pic = requests.get(result, timeout=10)
time.sleep(1)
except:
print(‘当前图片无法下载’)
j += 1
continue
可忽略,这段代码有bug
file_name = result.split(‘/’)
file_name = file_name[len(file_name) - 1]
文末有福利领取哦~
👉一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉二、Python必备开发工具

👉三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末领读者福利)

👉五、Python练习题
检查学习结果。

👉六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









