







总结
互联网大厂比较喜欢的人才特点:对技术有热情,强硬的技术基础实力;主动,善于团队协作,善于总结思考。无论是哪家公司,都很重视高并发高可用技术,重视基础,所以千万别小看任何知识。面试是一个双向选择的过程,不要抱着畏惧的心态去面试,不利于自己的发挥。同时看中的应该不止薪资,还要看你是不是真的喜欢这家公司,是不是能真的得到锻炼。其实我写了这么多,只是我自己的总结,并不一定适用于所有人,相信经过一些面试,大家都会有这些感触。
**另外本人还整理收藏了2021年多家公司面试知识点以及各种技术点整理 **
下面有部分截图希望能对大家有所帮助。

| 姓名(术语) | 简介 |
| — | — |
| B树 | 多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中; |
| B-树 | 就是B树(没想到吧) |
| B+树 | 在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中; |
| B*树 | 在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3; |
秘闻;
- 因为B树的原英文名称为B-tree,而国内很多人喜欢把B-tree译作B-树,所以人们可能会以为B-树是一种树,而B树又是另一种树。而事实上是,B-tree就是指的B树。
💨什么是AVL树❓
- 平衡二叉树,一般是用平衡因子差值决定并通过旋转来实现,左右子树树高差不超过1,那么和红黑树比较它是严格的平衡二叉树,平衡条件非常严格(树高差只有1),只要插入或删除不满足上面的条件就要通过旋转来保持平衡。由于旋转是非常耗费时间的。我们可以推出AVL树适合用于插入删除次数比较少,但查找多的情况。
💨什么是红黑树❓
- 平衡二叉树,通过对任何一条从根到叶子的简单路径上各个节点的颜色进行约束,确保没有一条路径会比其他路径长2倍,因而是近似平衡的。所以相对于严格要求平衡的AVL树来说,它的旋转保持平衡次数较少。用于搜索时,插入删除次数多的情况下我们就用红黑树来取代AVL。
💨什么是二叉搜索树❓
举个例子,二叉搜索树来作为索引的案例:
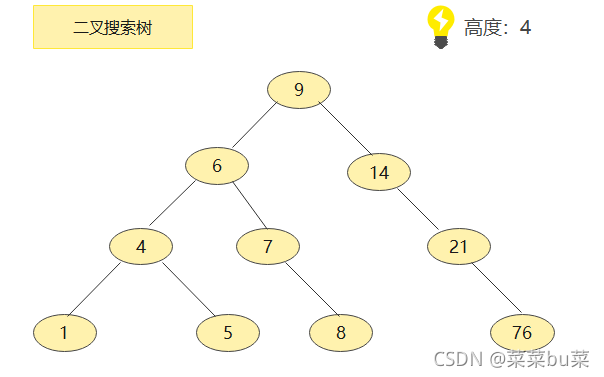
现在来查找节点为5的节点,来看看需要几步:
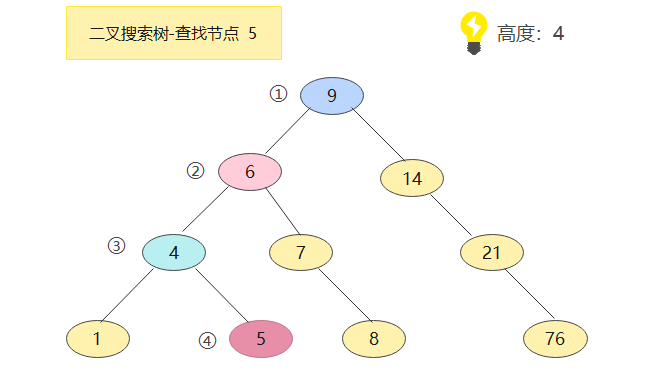
没错,一共四步,但是要注意,一般索引是在内存中执行的,所以价格很昂贵!!在最坏的情况下磁盘读写次数==二叉搜索树的高度,这在实际应用中肯定是不行的,所以基于此,诞生了B树*(多路平衡树)来减少数的高度,那么🔻
💨什么是B树(多路平衡树)❓
B树其实最开始源于的是二叉树,二叉树是只有左右孩子的树,当数据量越大的时候,二叉树的节点越多,那么当从根节点搜索的时候,影响查询效率。所以如果这些节点存储在外存储器中的话,每访问一个节点,相当于进行了一次I/O操作。前面说过,为了减少磁盘的 I/O 操作才有的B树,那么来看下B树有什么特点:
还是上面那个问题,来看下B树怎么个解决方案:
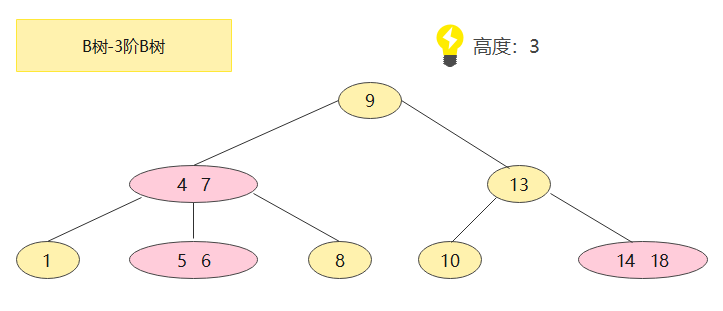
ps:K被称为B树的阶,K的值取决于磁盘页(内存的最小存储单位)的大小
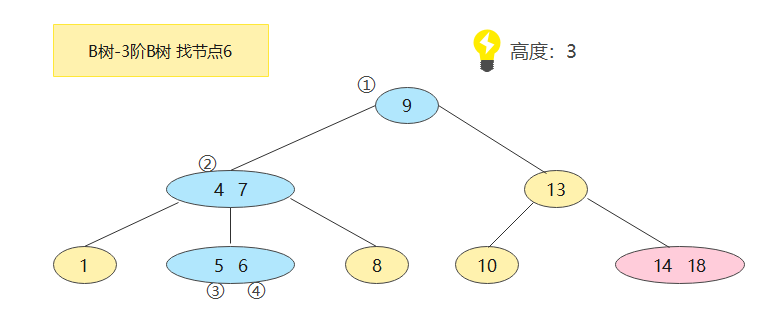
假设搜索节点6,步骤:
-
①定位到根节点(9),6比9小,所以在左子树找
-
②定位到节点(4,7),6在4、7中间,所以在中间子树找
-
③定位到(5,6),6比5大,所以和该节点的右边比较
-
④找到,over
可以看出,在B树里面的比较次数也很多,但是❗减少了I/O操作,因为B树可以减少树的高度,也就减少了磁盘读写次数,在实际应用场景,B树对性能的提升非常明显。
最后,大家可能之前都知道B树的特点,现在应该会更好理解(m是树的高度,k是树的阶):
-
1.根结点至少有两个子节点。
-
2.每个中间节点都包含k-1个元素和k个孩子,其中 m/2 <= k <= m 。
-
3.每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m。
-
4.所有的叶子结点都位于同一层。
-
5.每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划。

前面说了这么多,到这里才步入主题,先来调查一下…

经过菜菜调查发现,B+树的出现带来了这些优点:
1)B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B
树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了;
2)B+树查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当;
3)B+树便于范围查询(最重要的原因,范围查找是数据库的常态)
B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低;
B+树最大的性能问题在于会产生大量的随机IO,主要存在以下两种缺点:
- 主键不是有序递增的,导致每次插入数据产生大量的数据迁移和空间碎片;
- 即使主键是有序递增的,大量写请求的分布仍是随机的;
看下B+树长什么样子
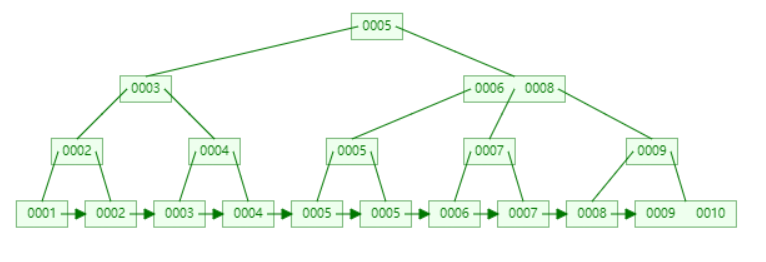
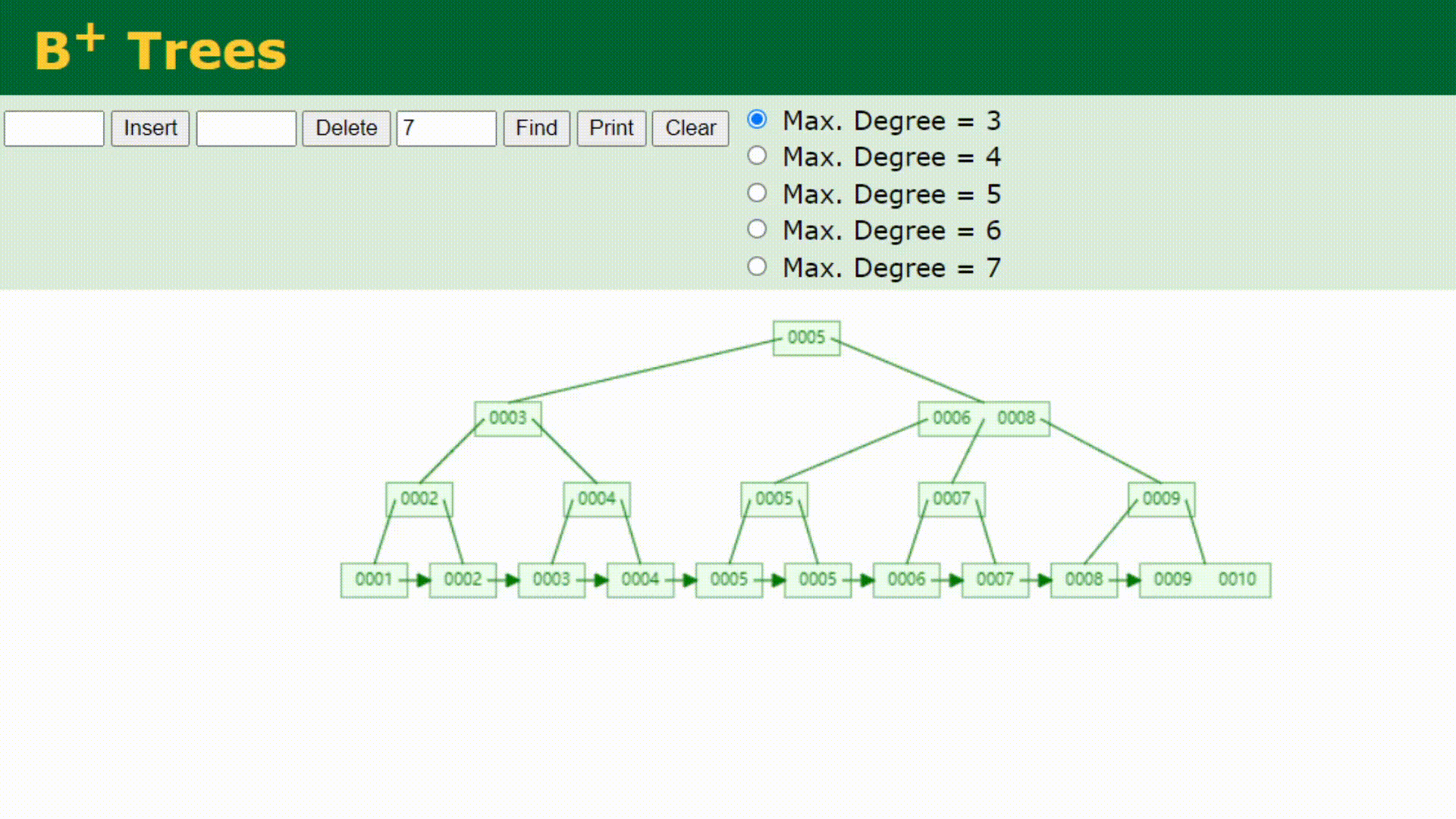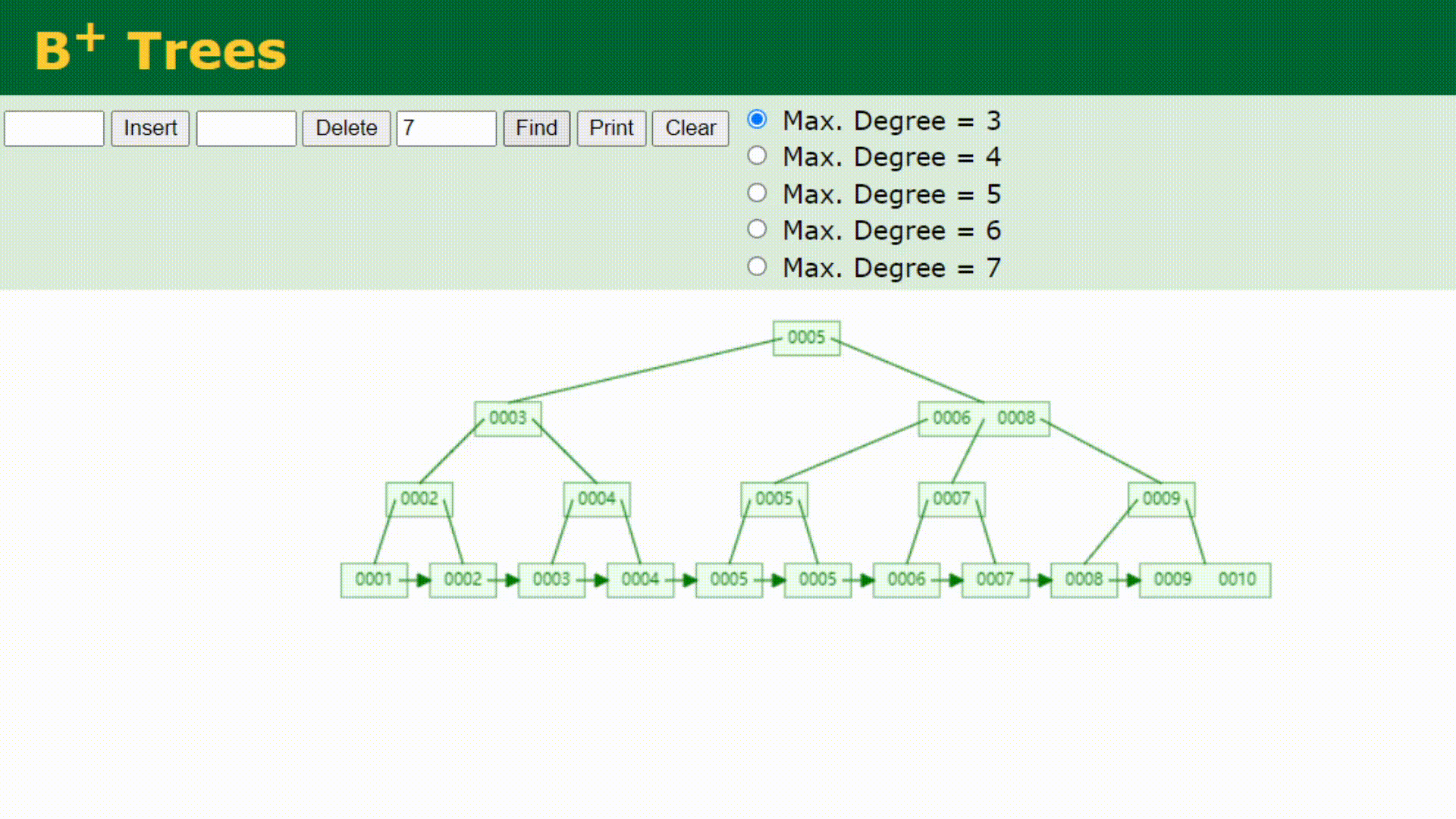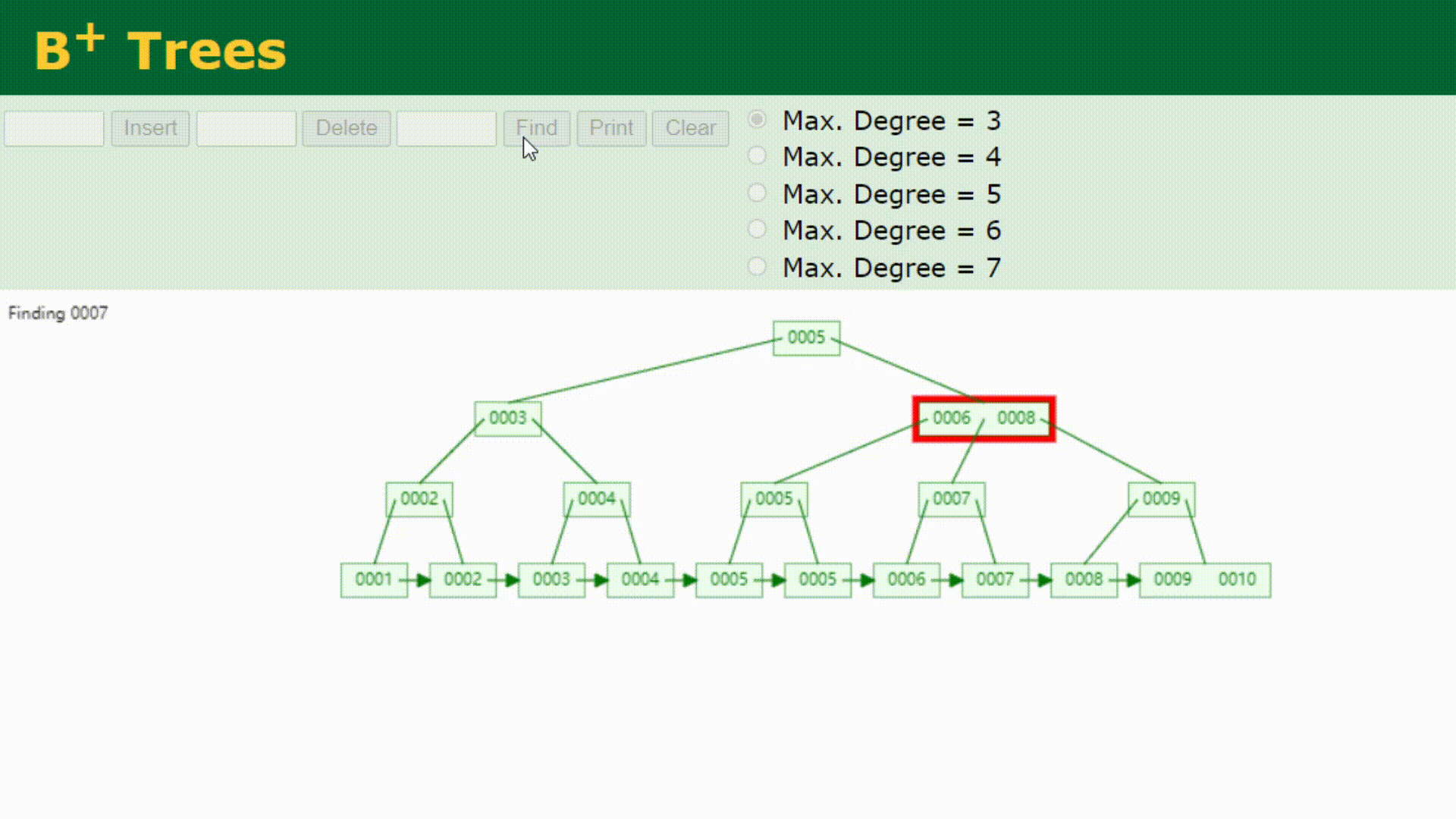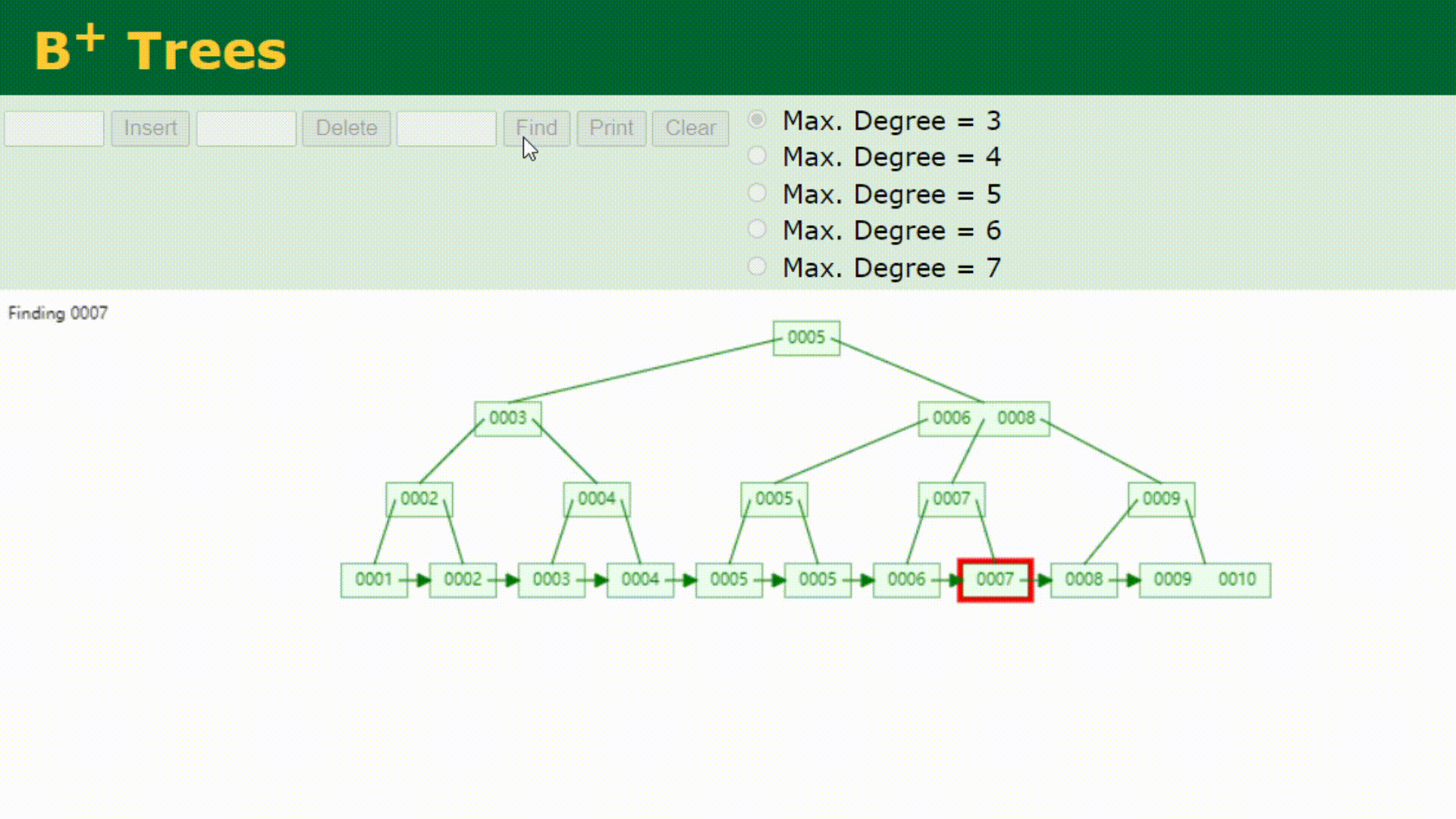
如果要查找0007的话,查找方式如下
并且,为什么MySQL数据库索引选择使用B+树?
B+树的节点只存储索引key值,具体信息的地址存在于叶子节点的地址中。这就使以页为单位的索引中可以存放更多的节点。减少更多的I/O支出。因此,B+树成为了数据库比较优秀的数据结构,MySQL中MyIsAM和InnoDB都是采用的B+树结构。不同的是前者是非聚集索引,后者主键是聚集索引。
看下B+树的顺序查找:
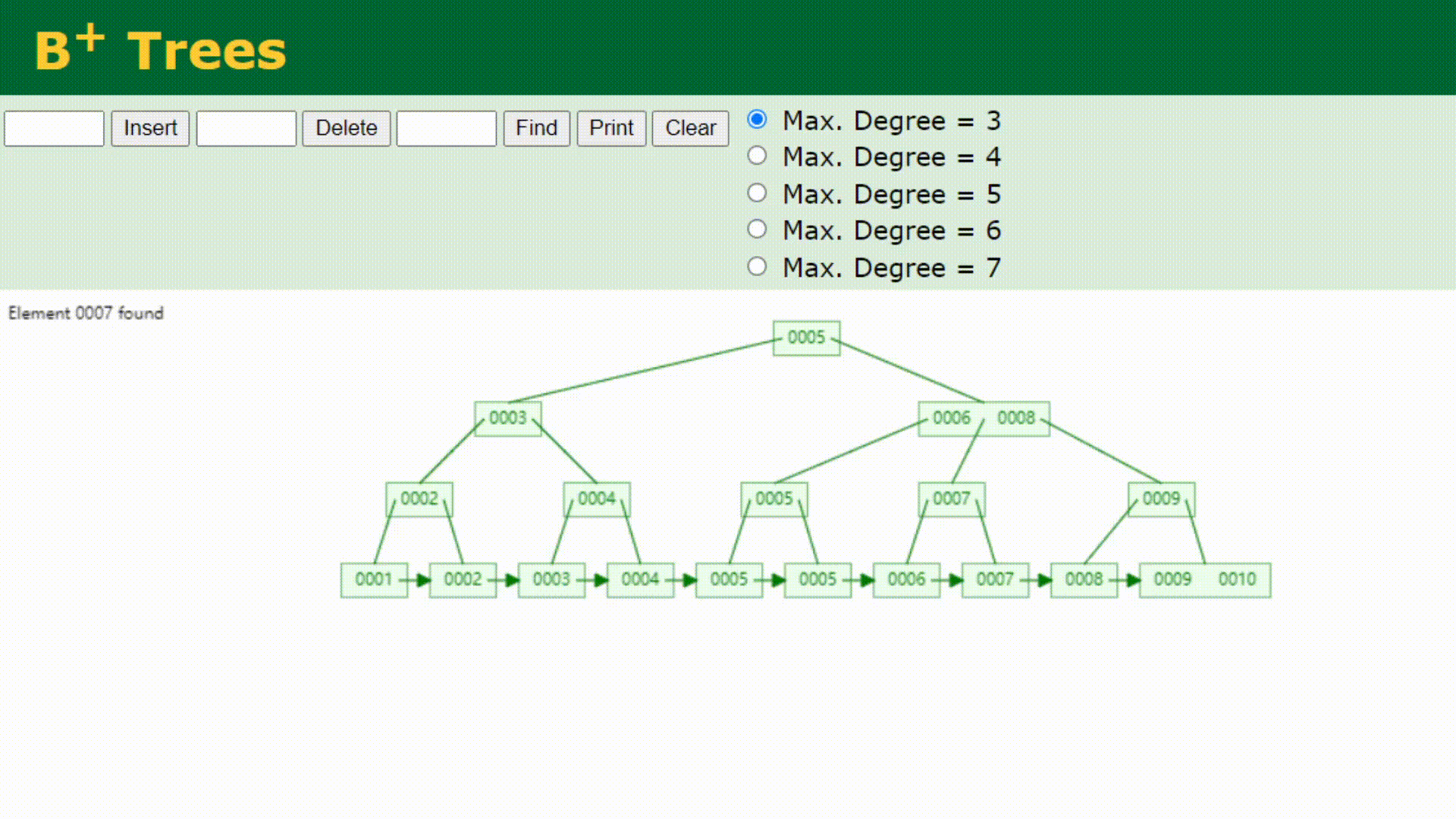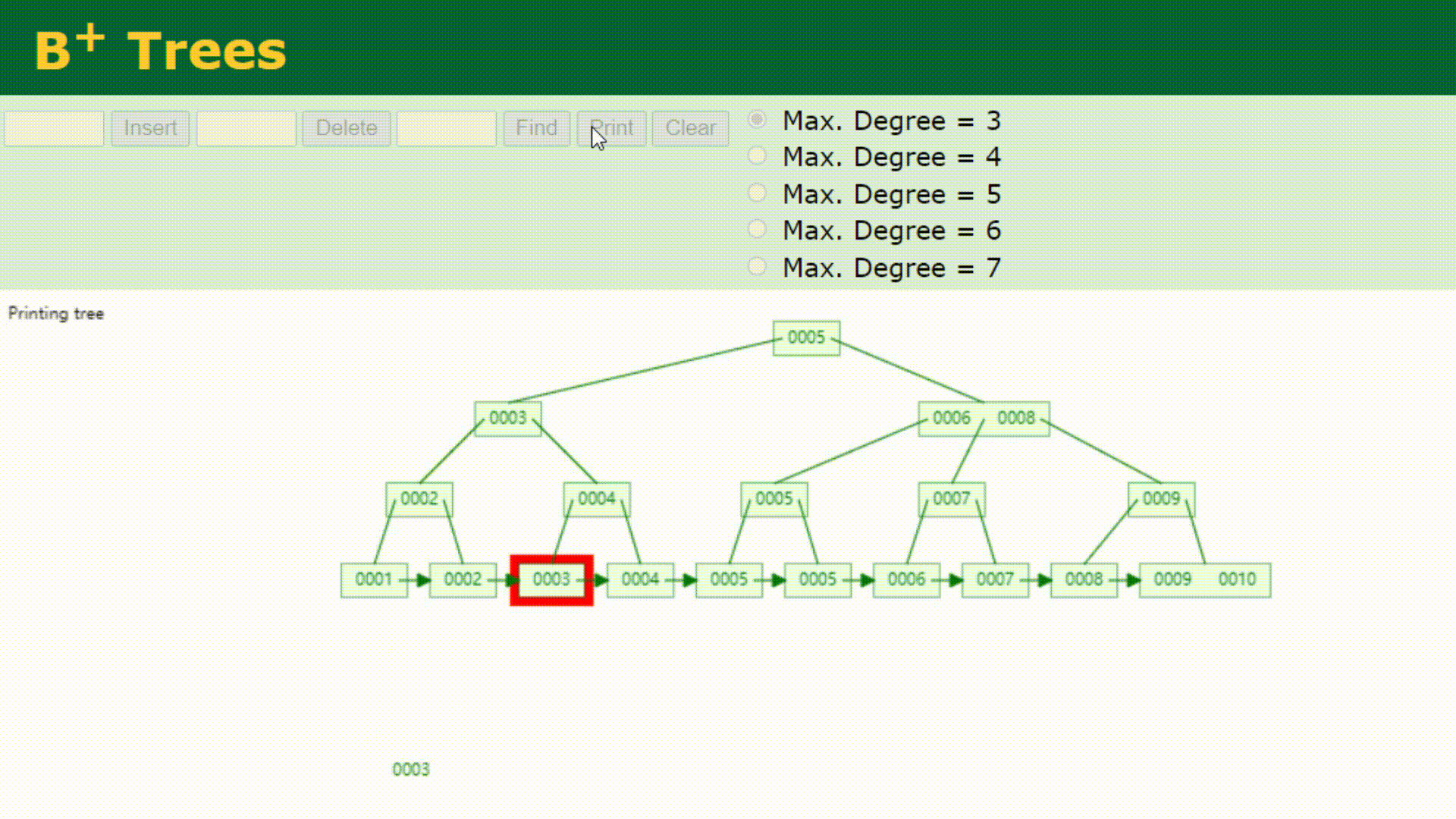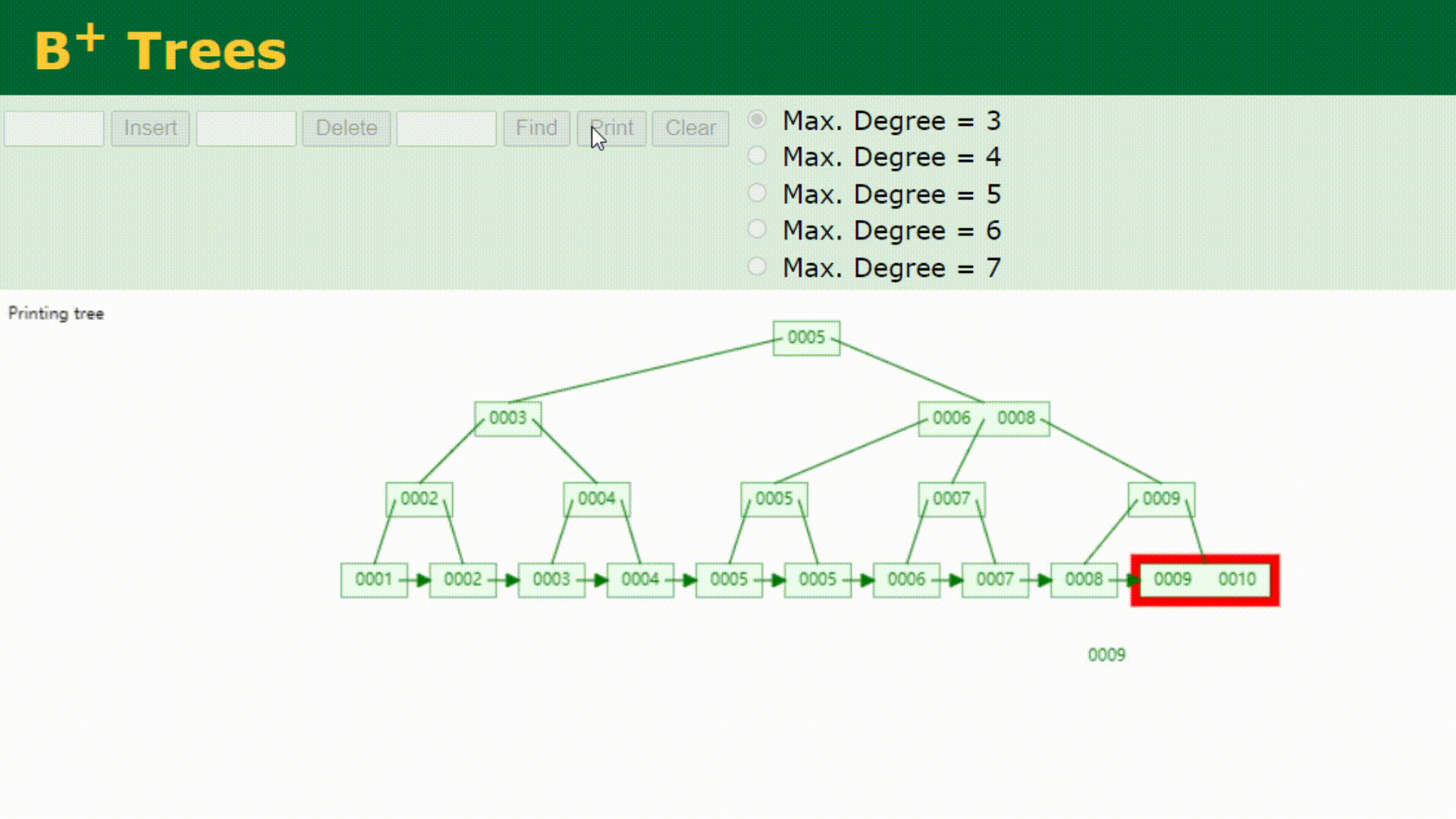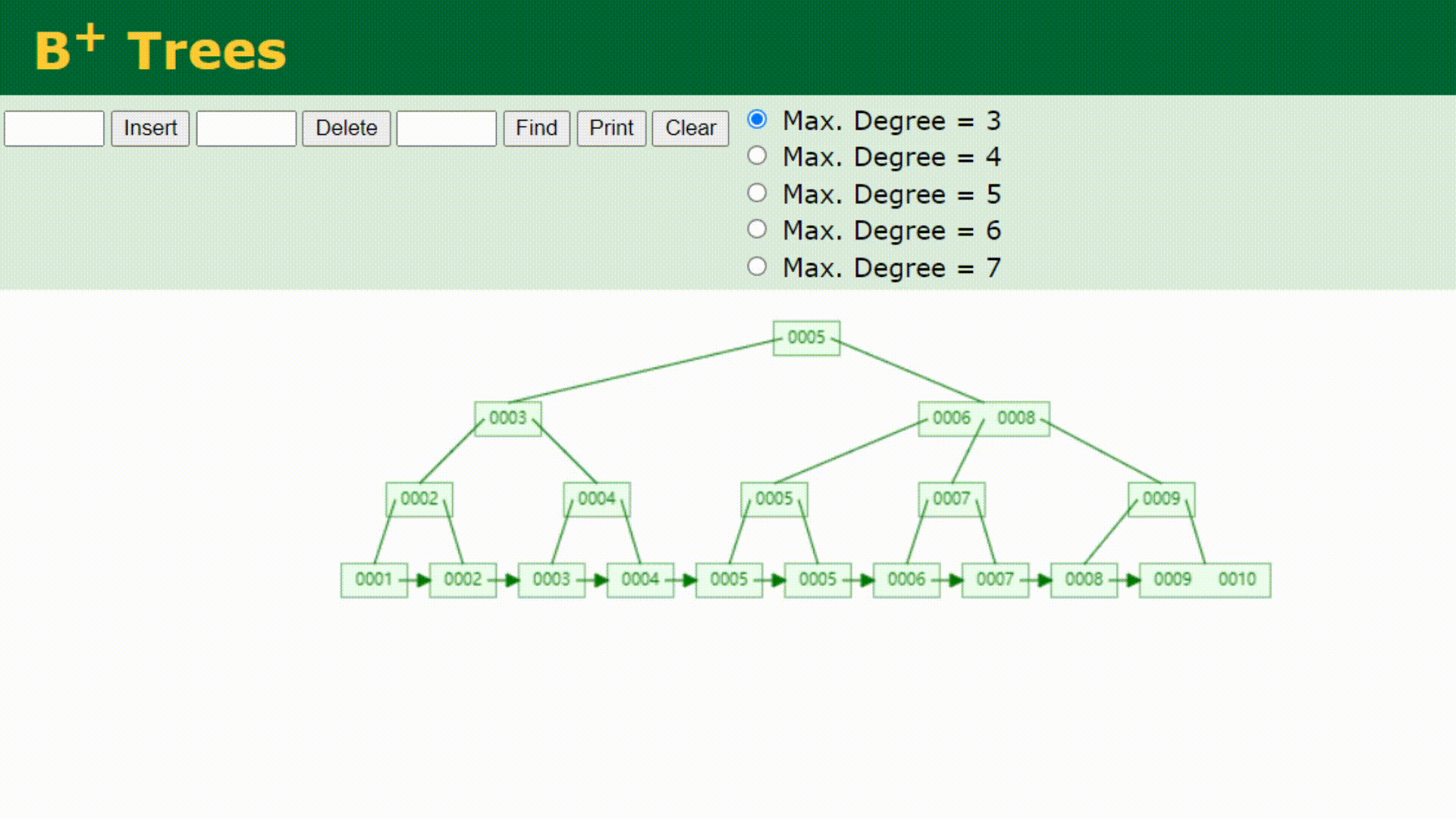
B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。B+树支持range-query(区间查询)非常方便,而B树不支持。
B+ 树通常用于数据库和操作系统的文件系统中。
NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入。
先看下百度的回答:
B_树是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;B_树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2)。
B*树是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针:
找的网图(大佬莫怪)
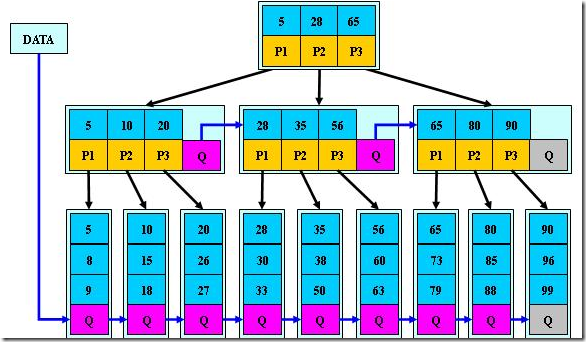
B+树和B*树的区别是啥?
- B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
面试资料整理汇总


这些面试题是我朋友进阿里前狂刷七遍以上的面试资料,由于面试文档很多,内容更多,没有办法一一为大家展示出来,所以只好为大家节选出来了一部分供大家参考。
面试的本质不是考试,而是告诉面试官你会做什么,所以,这些面试资料中提到的技术也是要学会的,不然稍微改动一下你就凉凉了
在这里祝大家能够拿到心仪的offer!
动一下你就凉凉了
在这里祝大家能够拿到心仪的offer!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









