







最后
无论是哪家公司,都很重视基础,大厂更加重视技术的深度和广度,面试是一个双向选择的过程,不要抱着畏惧的心态去面试,不利于自己的发挥。同时看中的应该不止薪资,还要看你是不是真的喜欢这家公司,是不是能真的得到锻炼。
针对以上面试技术点,我在这里也做一些分享,希望能更好的帮助到大家。



首先,找到6的位置,走过的路径为 h1->3->3->4,发现应该插入到4和7之间,插入之:

然后,建立竖线,即向下的指针,一共有三层,因为超过了当前最高层级,所以,头节点也要相应地往上增加一层,如下:
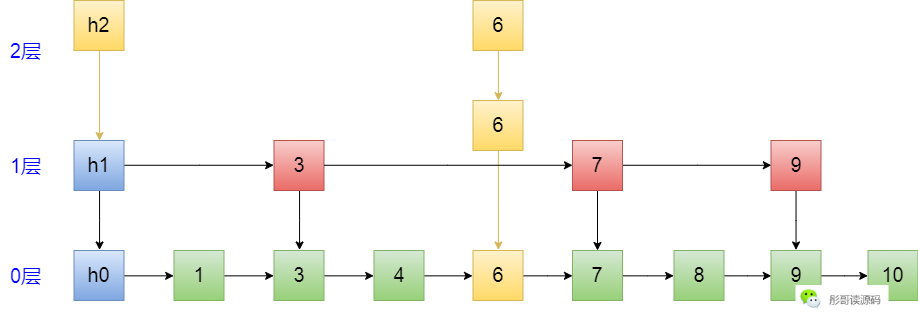
此时,横向的指针是一个都没动的。
最后,修正横向的指针,即 h2->6、3->6、6->7,修正完成则表示插入元素成功:
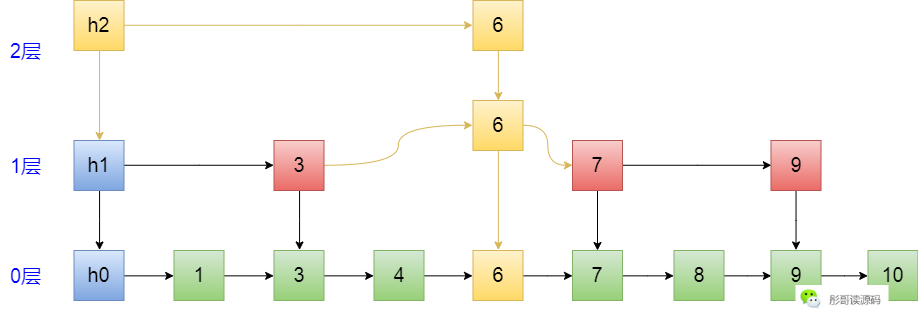
这就是插入元素的整个过程,Show You the Code:
/**
-
添加元素
-
不能添加相同的元素
-
@param value
*/
public void add(T value) {
System.out.println(“添加元素:\u6b22\u8fce\u5173\u6ce8\u516c\u4f17\u53f7\u5f64\u54e5\u8bfb\u6e90\u7801\uff0c\u83b7\u53d6\u66f4\u591a\u67b6\u6784\u3001\u57fa\u7840\u3001\u6e90\u7801\u597d\u6587\uff01”);
if (value == null) {
throw new NullPointerException();
}
Comparator cmp = this.comparator;
// 第一步:先找到前置的索引节点
Node preIndexNode = findPreIndexNode(value, true);
if (preIndexNode.value != null && cmp.compare(preIndexNode.value, value) == 0) {
return;
}
// 第二步:加入到链表中
Node q, n, t;
int c;
for (q = preIndexNode;😉 {
n = q.next;
if (n == null) {
c = 1;
} else {
c = cmp.compare(n.value, value);
if (c == 0) {
return;
}
}
if (c > 0) {
// 插入链表节点
q.next = t = new Node<>(value, n);
break;
}
q = n;
}
// 决定索引层数,每次最多只能比最大层数高1
int random = ThreadLocalRandom.current().nextInt();
// 倒数第一位是0的才建索引
if ((random & 1) == 0) {
int level = 1;
// 从倒数第二位开始连续的1
while (((random >>>= 1) & 1) != 0) {
level++;
}
HeadIndex oldHead = this.head;
int maxLevel = oldHead.level;
Index idx = null;
// 如果小于或等于最大层数,则不用再额外建head索引
if (level <= maxLevel) {
// 第三步1:先连好竖线
for (int i = 1; i <= level; i++) {
idx = new Index<>(t, idx, null);
}
} else {
// 大于了最大层数,则最多比最大层数多1
level = maxLevel + 1;
// 第三步2:先连好竖线
for (int i = 1; i <= level; i++) {
idx = new Index<>(t, idx, null);
}
// 新建head索引,并连好新head到最高node的线
HeadIndex newHead = new HeadIndex<>(oldHead.node, oldHead, idx, level);
this.head = newHead;
idx = idx.down;
}
// 第四步:再连横线,从旧head开始再走一遍遍历
Index qx, r, d;
int currentLevel;
for (qx = oldHead, currentLevel=oldHead.level;qx != null;) {
r = qx.right;
if (r != null) {
// 如果右边的节点比value小,则右移
if (cmp.compare(r.node.value, value) < 0) {
qx = r;
continue;
}
}
// 如果目标层级比当前层级小,直接下移
if (level < currentLevel) {
qx = qx.down;
} else {
// 右边到尽头了,连上
idx.right = r;
qx.right = idx;
qx = qx.down;
idx = idx.down;
}
currentLevel–;
}
}
}
删除元素
====
经过了上面的插入元素的全过程,删除元素相对来说要容易了不少。
同样地,首先,找到要删除的元素,从链表中删除。
然后,修正向右的索引,修正了向右的索引,向下的索引就不用管了,相当于从整个跳表中把向下的那一坨都删除了,等着垃圾回收即可。
其实,上面两步可以合成一步,在寻找要删除的元素的同时,就可以把向右的索引修正了。
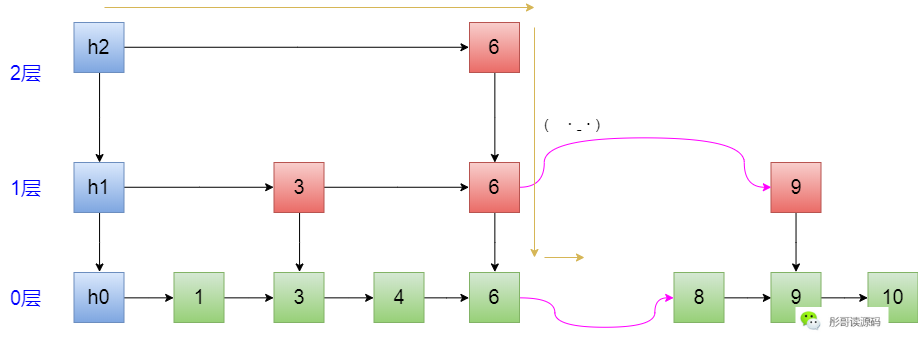
以下图为例,此时,要删除7这个元素:
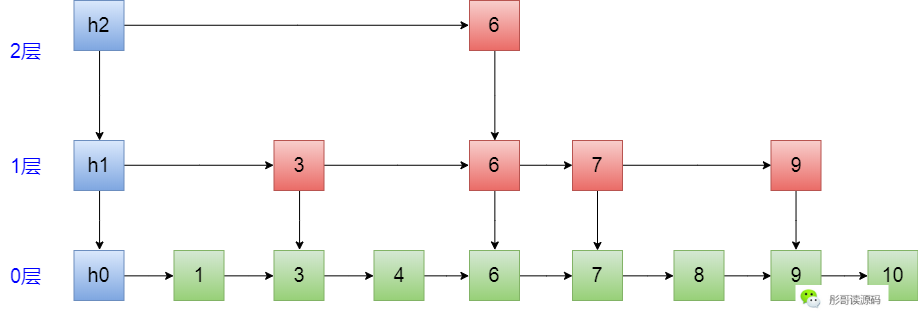
首先,寻找删除的元素的路径:h2->6->6,到这里的时候,正好看到右边有个7,把它干掉:
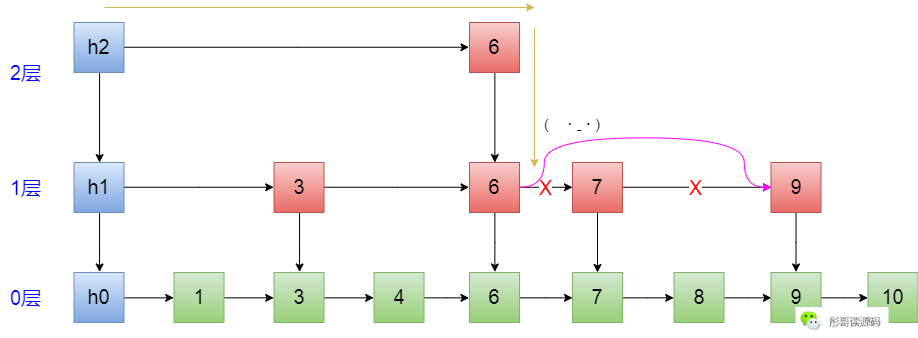
然后,继续往下,走到了绿色的6这里,再往后按链表的方式删除元素,这个大家都会了:
OK,给出删除元素的代码(查看完整代码,关注公主号彤哥读源码回复skiplist领取):
/**
-
删除元素
-
@param value
*/
public void delete(T value) {
System.out.println(“删除元素:\u6b22\u8fce\u5173\u6ce8\u516c\u4f17\u53f7\u5f64\u54e5\u8bfb\u6e90\u7801\uff0c\u83b7\u53d6\u66f4\u591a\u67b6\u6784\u3001\u57fa\u7840\u3001\u6e90\u7801\u597d\u6587\uff01”);
if (value == null) {
throw new NullPointerException();
} Index q = this.head;
Index r, d; Comparator cmp = this.comparator;
Node preIndexNode; // 第一步:寻找元素
for(;😉 {
r = q.right;
if (r != null) {
// 包含value的索引,正好有
if (cmp.compare(r.node.value, value) == 0) {
// 纠正:顺便修正向右的索引
q.right = r.right;
}
// 如果右边的节点比value小,则右移
if (cmp.compare(r.node.value, value) < 0) {
q = r;
continue;
}
}
d = q.down;
// 如果下面的索引为空了,则返回该节点
if (d == null) {
preIndexNode = q.node;
break;
}
// 否则,下移
q = d;
}
// 第二步:从链表中删除
Node p = preIndexNode;
Node n;
int c;
for (;😉 {
n = p.next;
if (n == null) {
return;
}
c = cmp.compare(n.value, value);
if (c == 0) {
// 找到了
p.next = n.next;
return;
}
if (c > 0) {
// 没找到
return;
}
// 后移
p = n;
}
}
OK,到这里,跳表的通用实现就完事了,其实,你也可以发现,这里还是有一些可以优化的点的,比如right和next指针为什么不能合二为一呢?向下的指针能不能跟指向Node的指针合并呢?
为了尝试解决这些问题,彤哥又自己研究了一种实现,这种实现不再区分头索引节点、索引节点、普通节点,把它们全部合并成一个,大家都是一样的,并且,我将它运用到了HashMap的改造中,来看看吧。
彤哥独家实现
======
因为,正好要改造HashMap,所以,关于彤哥的独家实现,我会与HashMap的改造一起来讲解,新的HashMap,我们称之为SkiplistHashMap(前者),它不同于JDK中现有的ConcurrentSkipListMap(后者),前者是一个HashMap,时间复杂度为O(1),后者其实不是HashMap,它只是跳表实现的一种Map,时间复杂度为O(log n)。
另外,我将Skip和List两个单词合成一个了,这是为了后面造一个新单词——Skiplistify,跳表化,-ify词缀结尾,什么化,比如,treeify树化、heapify堆化。
好了,开始SkiplistHashMap的实现,Come On!
数据结构
====
让我们分析一下SkiplistHashMap,首先,它有一个数组,其次,出现冲突的时候先使用链表来存储冲突的节点,然后,达到一定的阈值时,将链表转换成跳表,所以,它至少需要以下两大种节点类型:
普通节点,单链表结构,存储key、value、hash、next等,结构简单,直接给出代码:
/**
-
链表节点,平凡无奇
-
@param
-
@param
*/
static class Node<K extends Comparable, V> {
int hash;
K key; V value; Node<K, V> next; public Node(int hash, K key, V value, Node<K, V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}}
跳表节点,在通用实现中跳表节点分成了三大类:头索引节点、索引节点、普通节点,让我们仔细分析一下。
继续下面的内容,请先忘掉上面的三种节点,否则你是很难看懂的,trust me!
还是先拿一张图来对照着来:
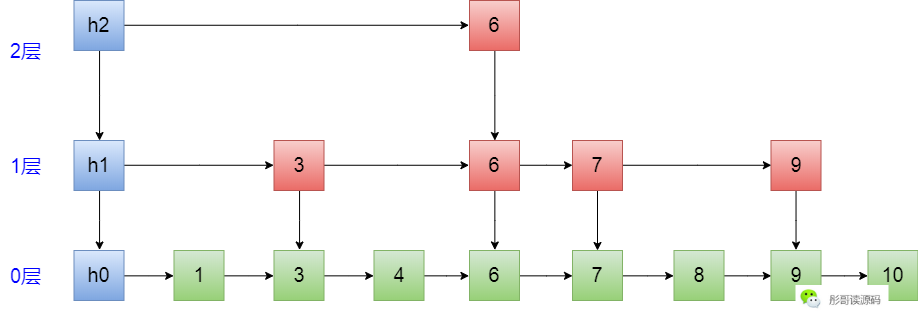
首先,我们把这张图压扁,是不是就只有一个一个的节点连成一条线了,也就是单链表结构:
static class SkiplistNode<K extends Comparable, V> {
int hash;
K key; V value; Node<K, V> next;
}
然后,随便找一个节点,把它拉起来,比如3这个元素,首先,它有一个高度,这里它的高度为2,并且,每一层的这个3都有一个向右的指针(忘掉之前的三种节点类型),对不对,所以,这里把next废弃掉,变成nexts,记录每一层的这个3的下一个元素是谁:
static class SkiplistNode<K extends Comparable, V> {
int hash;
K key; V value; int maxLevel;
Node<K, V>[] nexts;}
OK,不知道你理解了没有,我们试着按这种数据结构重画上面的图:
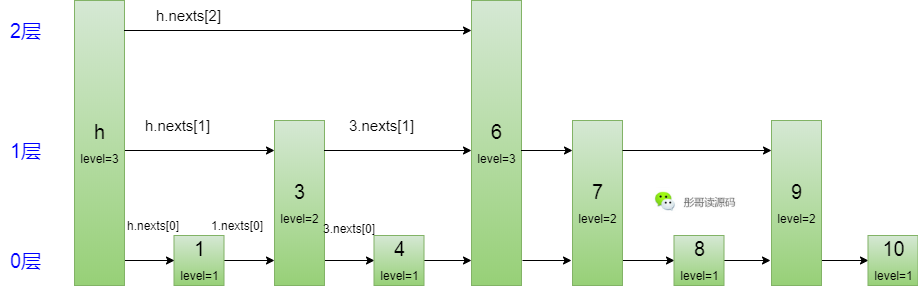
通过这种方式,就把上面三种类型的节点成功地变成了一个大节点,这个节点是有层高的,且每层都有一个向右的指针。
让我们模拟一下查找的过程,比如,要查询8这个元素,只需要从头节点的最高层,往右到6这个节点,6在2层向右为空了,所以转到1层,向右到7这个节点,7再向右看一下,是9,比8大,所以7向下到0层,再向右,找到8,所以,整个走过的路径为:h(2)->6(2)->6(1)->7(1)->7(0)->8(0)。
好了,原理讲完了,让我们看实现,先来个简单的。
跳表的查询元素
=======
不再区分索引节点和普通节点后,一切都将变得简单,无脑向右,再向下,再向右即可,代码也变得非常简单。
public V findValue(K key) {
int level = this.maxLevel;
SkiplistNode<K, V> q = this;
int c;
// i–控制向下
for (int i = (level - 1); i >= 0; i–) {
while (q.nexts[i] != null && (c = q.nexts[i].key.compareTo(key)) <= 0) {
if (c == 0) {
// 找到了返回
return q.nexts[i].value;
}
// 控制向右
q = q.nexts[i];
}
}
return null;
}
跳表的添加元素
=======
添加元素,同样变得要简单很多,一切尽在注释中,不过,彤哥写这篇文章的时候才发现下面的代码中有个小bug,看看你能不能发现^^
// 往跳表中添加一个元素(只有头节点可调用此方法)
private V putValue(int hash, K key, V value) {
// 1. 算出层数
int level = randomLevel();
// 2. 如果层数高出头节点层数,则增加头节点层数
if (level > maxLevel) {
level = ++maxLevel;
SkiplistNode<K, V>[] oldNexts = this.nexts;
SkiplistNode<K, V>[] newNexts = new SkiplistNode[level];
for (int i = 0; i < oldNexts.length; i++) {
newNexts[i] = oldNexts[i];
}
this.nexts = newNexts;
}
SkiplistNode<K, V> newNode = new SkiplistNode<>(hash, key, value, level);
// 3. 修正向右的索引
// 记录每一层最右能到达哪里,从头开始
SkiplistNode<K, V> q = this; // 头
int c;
// 好好想想这个双层循环,先向右找到比新节点小的最大节点,修正之,再向下,再向右
for (int i = (maxLevel - 1); i >= 0; i–) {
while (q.nexts[i] != null && (c = q.nexts[i].key.compareTo(key)) <= 0) {
if (c == 0) {
V old = q.nexts[i].value;
q.nexts[i].value = value;
return old;
}
q = q.nexts[i];
}
if (i < level) {
newNode.nexts[i] = q.nexts[i];
q.nexts[i] = newNode;
}
}
return null;
}
private int randomLevel() {
int level = 1;
int random = ThreadLocalRandom.current().nextInt();
while (((random>>>=1) & 1) !=0) {
level++;
}
return level;
}
好了,关于SkiplistHashMap中跳表的部分我们就讲这么多,需要完整源码的同学可以关注个人公主号彤哥读源码,回复skiplist领取哈。
下面我们再来看看SkiplistHashMap中的查询元素和添加元素。
SkiplistHashMap查询元素
===================
其实,跳表的部分搞定了,SkiplistHashMap的部分就非常简单了,直接上代码:
public V get(K key) {
int hash = hash(key);
int i = (hash & (table.length - 1));
Node<K, V> p = table[i]; if (p == null) {
return null;
} else {
if (p instanceof SkiplistNode) {
return (V) ((SkiplistNode)p).findValue(key);
} else {
do {
if (p.key.equals(key)) {
return p.value;
} } while ((p=p.next) != null);
} } return null;
}
SkiplistHashMap添加元素
===================
添加元素参考HashMap的写法,将添加过程分成以下几种情况:
-
未初始化,先初始化;
-
数组对应位置无元素,直接放入;
-
数组对应位置有元素,又分成三种情况:如果是SkipListNode类型,按跳表类型插入元素如果该位置元素的key值正好与要插入的元素的key值相等,说明是重复元素,替换后直接返回否则,按链表类型插入元素,且插入元素后判断是否要转换成跳表
-
插入元素后,判断是否需要扩容
上代码如下:
/**
- 添加元素:
总结
虽然我个人也经常自嘲,十年之后要去成为外卖专员,但实际上依靠自身的努力,是能够减少三十五岁之后的焦虑的,毕竟好的架构师并不多。
架构师,是我们大部分技术人的职业目标,一名好的架构师来源于机遇(公司)、个人努力(吃得苦、肯钻研)、天分(真的热爱)的三者协作的结果,实践+机遇+努力才能助你成为优秀的架构师。
如果你也想成为一名好的架构师,那或许这份Java成长笔记你需要阅读阅读,希望能够对你的职业发展有所帮助。

SkiplistHashMap添加元素
===================
添加元素参考HashMap的写法,将添加过程分成以下几种情况:
-
未初始化,先初始化;
-
数组对应位置无元素,直接放入;
-
数组对应位置有元素,又分成三种情况:如果是SkipListNode类型,按跳表类型插入元素如果该位置元素的key值正好与要插入的元素的key值相等,说明是重复元素,替换后直接返回否则,按链表类型插入元素,且插入元素后判断是否要转换成跳表
-
插入元素后,判断是否需要扩容
上代码如下:
/**
- 添加元素:
总结
虽然我个人也经常自嘲,十年之后要去成为外卖专员,但实际上依靠自身的努力,是能够减少三十五岁之后的焦虑的,毕竟好的架构师并不多。
架构师,是我们大部分技术人的职业目标,一名好的架构师来源于机遇(公司)、个人努力(吃得苦、肯钻研)、天分(真的热爱)的三者协作的结果,实践+机遇+努力才能助你成为优秀的架构师。
如果你也想成为一名好的架构师,那或许这份Java成长笔记你需要阅读阅读,希望能够对你的职业发展有所帮助。
[外链图片转存中…(img-gGnsO2dn-1715430386020)]















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









