







写在最后
还有一份JAVA核心知识点整理(PDF):JVM,JAVA集合,JAVA多线程并发,JAVA基础,Spring原理,微服务,Netty与RPC,网络,日志,Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,设计模式,负载均衡,数据库,一致性哈希,JAVA算法,数据结构,加密算法,分布式缓存,Hadoop,Spark,Storm,YARN,机器学习,云计算…


针对上述场景,增加两个事务消息的方式解决一致性问题,系统A通过发送事务消息的方式与系统B和系统C进行交互
具体实现过程:
-
发送退款的事务消息
-
新增退款记录,状态为:处理中
-
Commit退款事务消息
提供MQ事务callback
退款callback查询
-
有退款记录且为处理中则Commit
-
其他则Rollback
发送短信callback查询
-
有退款记录且成功则Commit
-
其他则Rollback
退款同步Job
查询退款记录表中处理中的记录,调用系统B的退款查询接口 同步状态 其中退款成功处理:
-
发送短信的事务消息
-
更新退款记录为成功
-
Commit短信事务消息
相关理论
二阶段提交


二阶段提交是解决分布式事务问题的重要理论基础,但也存在着明显的问题:
-
阻塞问题,参与者将协议消息发送给协调器后,它将阻塞直到收到提交或回滚,只能依赖协调者的超时机制
-
协调者单点问题,如果协调者出现故障,则某些参与者将一直无法收到提交或回滚的消息。
为了解决二阶段提交出现的问题,又有了三阶段提交(Three-phase commit):
-
解决阻塞问题:将2PC中的第一阶段一分为二,提供了一个CanCommit阶段,此阶段并不锁定资源,这样可以大幅降低了阻塞概率
-
解决单点问题:在参与者这边也引入了超时机制
DTP Model
X / Open分布式事务处理DTP(Distributed Transaction Processing)模型是一种软件体系架构,已经成为事实上的事务模型组件的行为标准。它允许多个应用程序共享由多个资源管理器提供的资源,并允许其工作被协调为全局事务。

ApplicationProgram(AP) 应用程序定义了事务边界并指定构成事务的操作
ResourceManager(RM) 资源管理器用来管理我们需要访问的共享资源,我们可以将它理解为关系数据库、文件存储系统、消息队列、打印机等
TransactionManagger™ 事务管理器是一个独立的组件,他为事务分配标识符并监视事务的执行情况,负责事务完成和故障恢复
CommunicationResourceManager(CRM) 通信资源管理器控制一个或多个 TM domain 之间分布式应用的通信。
XA Specification
XA规范是X/Open关于分布式事务处理 (DTP)的规范。规范描述了全局的事务管理器与局部的资源管理器之间的接口。XA规范的目的是允许多个资源(如数据库,应用服务器,消息队列,等等)在同一事务中访问,这样可以使ACID属性跨越应用程序而保持有效。XA使用两阶段提交来保证所有资源同时提交或回滚任何特定的事务。
XA规范描述了资源管理器要支持事务性访问所必需做的事情。

TCC


saga

在 Saga 模式下,分布式事务内有多个参与者,每一个参与者都是一个冲正补偿服务,需要用户根据业务场景实现其正向操作和逆向回滚操作。
分布式事务执行过程中,依次执行各参与者的正向操作,如果所有正向操作均执行成功,那么分布式事务提交。如果任何一个正向操作执行失败,那么分布式事务会去退回去执行前面各参与者的逆向回滚操作,回滚已提交的参与者,使分布式事务回到初始状态。

Saga 模式下分布式事务通常是由事件驱动的,各个参与者之间是异步执行的,Saga 模式是一种长事务解决方案。
Saga模式的优势是:
-
一阶段提交本地数据库事务,无锁,高性能;
-
参与者可以采用事务驱动异步执行,高吞吐;
-
补偿服务即正向服务的“反向”,易于理解,易于实现;
缺点:
- Saga 模式由于一阶段已经提交本地数据库事务,且没有进行“预留”动作,所以不能保证隔离性。
开源项目
seata
Seata 是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。支持AT、TCC、SAGA、XA四种模式,对微服务框架支持友好。
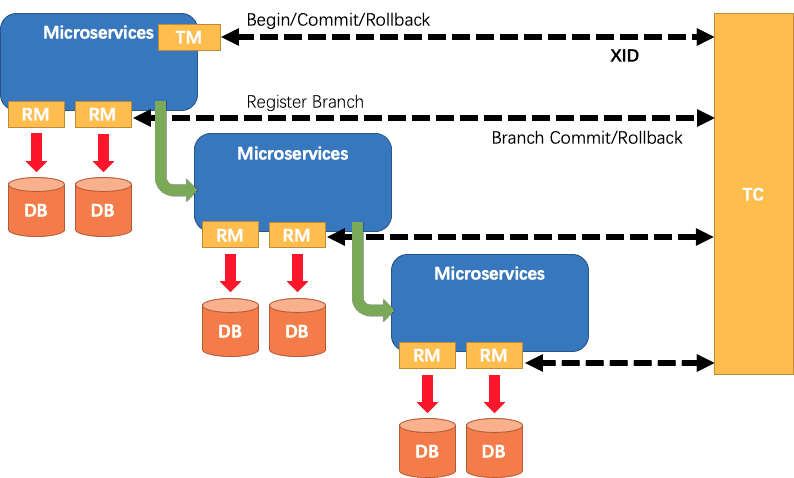
如下图所示,Seata 中有三大模块,分别是 TM、RM 和 TC。 其中 TM 和 RM 是作为 Seata 的客户端与业务系统集成在一起,TC 作为 Seata 的服务端独立部署。
TC - 事务协调者 维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM - 事务管理器 定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM - 资源管理器 管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
在 Seata 中,分布式事务的执行流程:
-
TM 开启分布式事务(TM 向 TC 注册全局事务记录);
-
按业务场景,编排数据库、服务等事务内资源(RM 向 TC 汇报资源准备状态 );
-
TM 结束分布式事务,事务一阶段结束(TM 通知 TC 提交/回滚分布式事务);
-
TC 汇总事务信息,决定分布式事务是提交还是回滚;
-
TC 通知所有 RM 提交/回滚 资源,事务二阶段结束;
AT模式
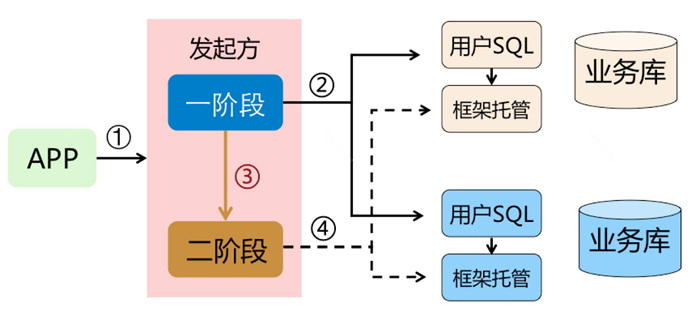
AT 模式是一种无侵入的分布式事务解决方案。在 AT 模式下,用户只需关注自己的“业务 SQL”,用户的 “业务 SQL” 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。 二阶段:提交异步化,非常快速地完成。回滚通过一阶段的回滚日志进行反向补偿。
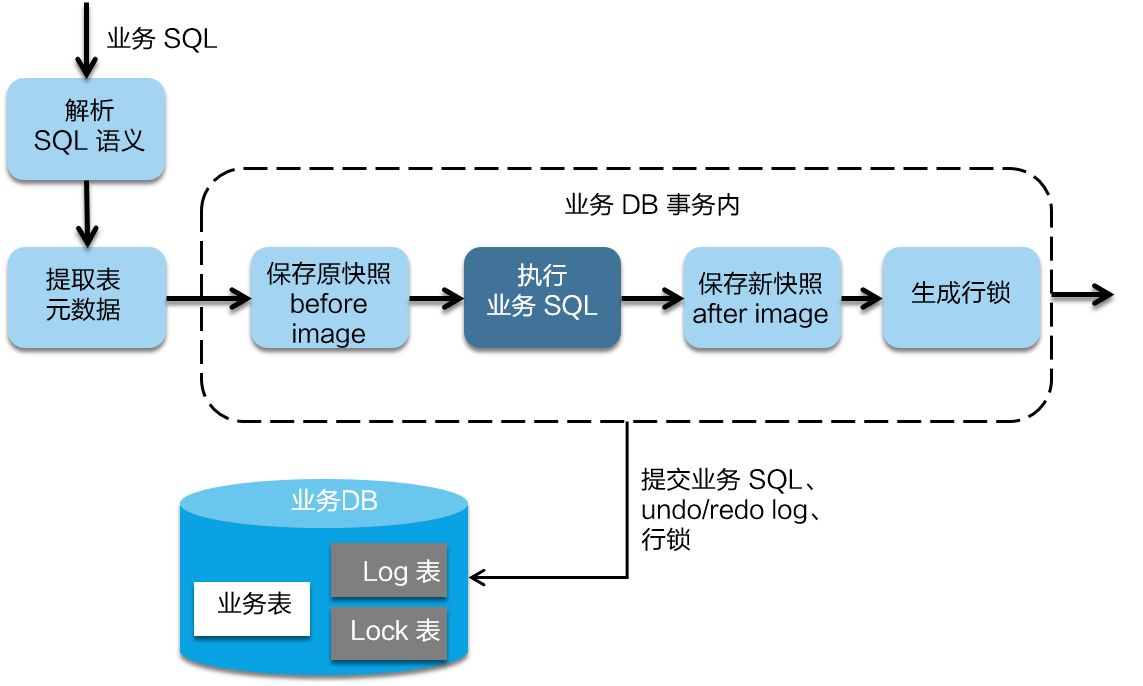
在一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
TCC模式

一个分布式的全局事务,整体是 两阶段提交 的模型。全局事务是由若干分支事务组成的,分支事务要满足 两阶段提交 的模型要求,即需要每个分支事务都具备自己的:
一阶段 prepare 行为 二阶段 commit 或 rollback 行为
TCC 模式,不依赖于底层数据资源的事务支持:
-
一阶段 prepare 行为:调用 自定义 的 prepare 逻辑。
-
二阶段 commit 行为:调用 自定义 的 commit 逻辑。
-
二阶段 rollback 行为:调用 自定义 的 rollback 逻辑。
所谓 TCC 模式,是指支持把 自定义 的分支事务纳入到全局事务的管理中。
Saga模式
目前SEATA提供的Saga模式是基于状态机引擎来实现的,机制是:
最后
各位读者,由于本篇幅度过长,为了避免影响阅读体验,下面我就大概概括了整理了




…(img-Yxl6Gqqp-1715658356071)]
[外链图片转存中…(img-qmsLRAZs-1715658356071)]
[外链图片转存中…(img-JD8wxoht-1715658356071)]















 826
826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









