







最后
即使是面试跳槽,那也是一个学习的过程。只有全面的复习,才能让我们更好的充实自己,武装自己,为自己的面试之路不再坎坷!今天就给大家分享一个Github上全面的Java面试题大全,就是这份面试大全助我拿下大厂Offer,月薪提至30K!
我也是第一时间分享出来给大家,希望可以帮助大家都能去往自己心仪的大厂!为金三银四做准备!
一共有20个知识点专题,分别是:
Dubbo面试专题

JVM面试专题

Java并发面试专题

Kafka面试专题

MongDB面试专题

MyBatis面试专题

MySQL面试专题

Netty面试专题

RabbitMQ面试专题

Redis面试专题

Spring Cloud面试专题

SpringBoot面试专题

zookeeper面试专题

常见面试算法题汇总专题

计算机网络基础专题

设计模式专题

现在假设由于某种原因,employee-producer公开的服务会抛出异常。我们在这种情况下使用Hystrix定义了一个回退方法。这种后备方法应该具有与公开服务相同的返回类型。如果暴露服务中出现异常,则回退方法将返回一些值。
7、什么是Hystrix断路器?我们需要它吗?
由于某些原因,employee-consumer公开服务会引发异常。在这种情况下使用Hystrix我们定义了一个回退方法。如果在公开服务中发生异常,则回退方法返回一些默认值。
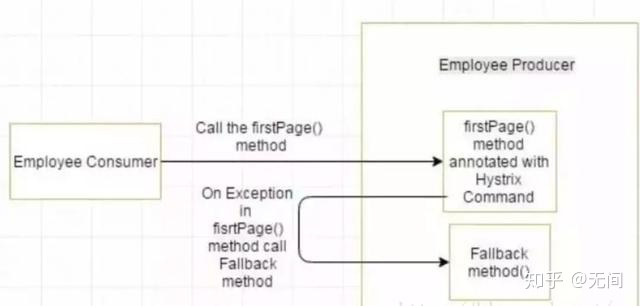
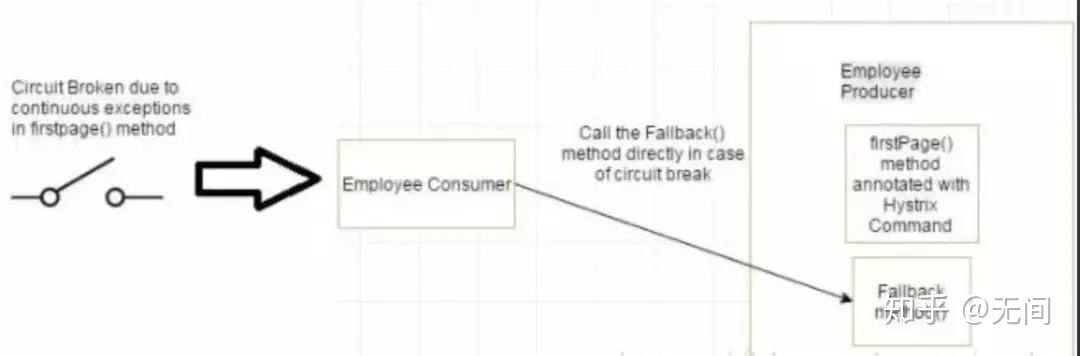
如果firstPage method() 中的异常继续发生,则Hystrix电路将中断,并且员工使用者将一起跳过firtsPage方法,并直接调用回退方法。断路器的目的是给第一页方法或第一页方法可能调用的其他方法留出时间,并导致异常恢复。可能发生的情况是,在负载较小的情况下,导致异常的问题有更好的恢复机会 。
8、项目中zuul常用的功能
-
提供动态路由
-
提供安全、鉴权处理
-
跨域处理
-
全局动态路由的hystrix(熔断、降级、限流)处理
9、服务网关的作用
-
简化客户端调用复杂度,统一处理外部请求。
-
数据裁剪以及聚合,根据不同的接口需求,对数据加工后对外。
-
多渠道支持,针对不同的客户端提供不同的网关支持。
-
遗留系统的微服务化改造,可以作为新老系统的中转组件。
-
统一处理调用过程中的安全、权限问题。
Spring Cloud中的网关有:Zuul和Spring Cloud Gateway,最新版本中推荐使用后者。
10、ribbon和feign区别
-
Ribbon添加maven依赖 spring-starter-ribbon 使用@RibbonClient(value=“服务名称”) 使用RestTemplate调用远程服务对应的方法。
-
feign添加maven依赖 spring-starter-feign 服务提供方提供对外接口 调用方使用 在接口上使用@FeignClient(“指定服务名”)
Ribbon和Feign的区别:
Ribbon和Feign都是用于调用其他服务的,不过方式不同。
-
启动类使用的注解不同,Ribbon用的是@RibbonClient,Feign用的@EnableFeignClients。
-
服务的指定位置不同,Ribbon是在@RibbonClient注解上声明,Feign则是在定义抽象方法的接口中使用@FeignClient声明。
-
调用方式不同,Ribbon需要自己构建http请求,模拟http请求然后使用RestTemplate发送给其他服务,步骤相当繁琐。
Feign则是在Ribbon的基础上进行了一次改进,采用接口的方式,将需要调用的其他服务的方法定义成抽象方法即可,
不需要自己构建http请求。不过要注意的是抽象方法的注解、方法签名要和提供服务的方法完全一致。
11、ribbon的负载均衡策略
-
RoundRobinRule: 轮询策略,Ribbon以轮询的方式选择服务器,这个是默认值。所以示例中所启动的两个服务会被循环访问;
-
RandomRule: 随机策略,也就是说Ribbon会随机从服务器列表中选择一个进行访问;
-
BestAvailableRule: 最大可用策略,即先过滤出故障服务器后,选择一个当前并发请求数最小的;
-
WeightedResponseTimeRule: 带有加权的轮询策略,对各个服务器响应时间进行加权处理,然后在采用轮询的方式来获取相应的服务器;
-
AvailabilityFilteringRule: 可用过滤策略,先过滤出故障的或并发请求大于阈值的一部分服务实例,然后再以线性轮询的方式从过滤后的实例清单中选出一个;
-
ZoneAvoidanceRule: 区域感知策略,先使用主过滤条件(区域负载器,选择最优区域)对所有实例过滤并返回过滤后的实例清单,依次使用次过滤条件列表中的过滤条件对主过滤条件的结果进行过滤,判断最小过滤数(默认1)和最小过滤百分比(默认0),最后对满足条件的服务器则使用RoundRobinRule(轮询方式)选择一个服务器实例。
12、简述什么是CAP,并说明Eureka包含CAP中的哪些?
**CAP理论:**一个分布式系统不可能同时满足C (一致性),A(可用性),P(分区容错性).由于分区容错性P在分布式系统中是必须要保证的,因此我们只能从A和C中进行权衡.
Eureka 遵守 AP
-
Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,神域的节点依然可以提供注册和查询服务。
-
而Eureka的客户端在向某个Eureka 注册或查询是如果发现连接失败,则会自动切换至其他节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查的信息可能不最新的不保证强一致性)。
13、Eureka和zookeeper都可以提供服务注册与发现的功能,请说说两个的区别?
-
Zookeeper保证了CP(C:一致性,P:分区容错性)
-
Eureka保证了AP(A:高可用)
-
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的信息,但不能容忍直接down掉不可用。也就是说,服务注册功能对高可用性要求比较高,但zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新选leader。问题在于,选取leader时间过长,30 ~ 120s,且选取期间zk集群都不可用,这样就会导致选取期间注册服务瘫痪。在云部署的环境下,因网络问题使得zk集群失去master节点是较大概率会发生的事,虽然服务能够恢复,但是漫长的选取时间导致的注册长期不可用是不能容忍的。
-
Eureka保证了可用性,Eureka各个节点是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点仍然可以提供注册和查询服务。而Eureka的客户端向某个Eureka注册或发现时发生连接失败,则会自动切换到其他节点,只要有一台Eureka还在,就能保证注册服务可用,只是查到的信息可能不是最新的。除此之外,Eureka还有自我保护机制,如果在15分钟内超过85%的节点没有正常的心跳,那么Eureka就认为客户端与注册中心发生了网络故障,此时会出现以下几种情况:
-
Eureka不在从注册列表中移除因为长时间没有收到心跳而应该过期的服务。
-
Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其他节点上(即保证当前节点仍然可用)。
-
当网络稳定时,当前实例新的注册信息会被同步到其他节点。
因此,Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像Zookeeper那样使整个微服务瘫痪。
14、什么是 Spring Cloud Bus?我们需要它吗?
Spring Cloud Bus通过轻量消息代理连接各个分布的节点。这会用在广播状态的变化(例如配置变化)或者其他的消息指令。Spring Cloud Bus的一个核心思想是通过分布式的启动器对Spring Boot应用进行扩展,也可以用来建立一个多个应用之间的通信频道。
考虑以下情况:我们有多个应用程序使用 Spring Cloud Config 读取属性,而 Spring Cloud Config 从GIT 读取这些属性。
下面的例子中多个员工生产者模块从 Employee Config Module 获取 Eureka 注册的财产。
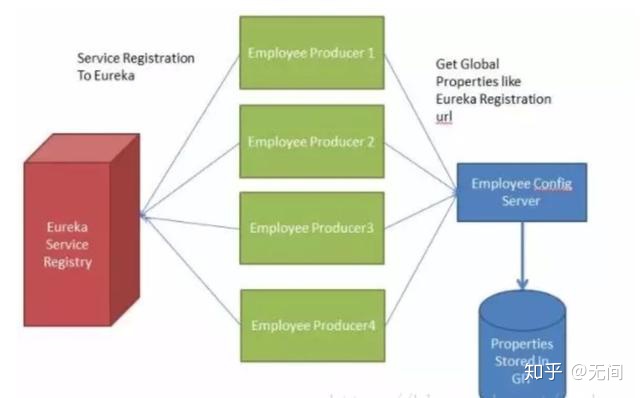
如果假设 GIT 中的 Eureka 注册属性更改为指向另一台 Eureka 服务器,会发生什么情况。在这种情况 下,我们将不得不重新启动服务以获取更新的属性。
总目录展示
该笔记共八个节点(由浅入深),分为三大模块。
高性能。 秒杀涉及大量的并发读和并发写,因此支持高并发访问这点非常关键。该笔记将从设计数据的动静分离方案、热点的发现与隔离、请求的削峰与分层过滤、服务端的极致优化这4个方面重点介绍。
一致性。 秒杀中商品减库存的实现方式同样关键。可想而知,有限数量的商品在同一时刻被很多倍的请求同时来减库存,减库存又分为“拍下减库存”“付款减库存”以及预扣等几种,在大并发更新的过程中都要保证数据的准确性,其难度可想而知。因此,将用一个节点来专门讲解如何设计秒杀减库存方案。
高可用。 虽然介绍了很多极致的优化思路,但现实中总难免出现一些我们考虑不到的情况,所以要保证系统的高可用和正确性,还要设计一个PlanB来兜底,以便在最坏情况发生时仍然能够从容应对。笔记的最后,将带你思考可以从哪些环节来设计兜底方案。
篇幅有限,无法一个模块一个模块详细的展示(这些要点都收集在了这份《高并发秒杀顶级教程》里),麻烦各位转发一下(可以帮助更多的人看到哟!)


由于内容太多,这里只截取部分的内容。
存中…(img-qwVi78FH-1715127625437)]
由于内容太多,这里只截取部分的内容。















 272
272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









