






一、Hadoop 入门必备知识
1.Hadoop 发展历程与生态系统为什么选择 Hadoop?
Hadoop诞生于2005年,最初是Apache Nutch搜索引擎项目的一部分。2006年,Doug Cutting将Nutch的分布式文件系统(NDFS)和MapReduce分离出来,形成了独立的Hadoop项目。经过多年发展,Hadoop已经成为大数据领域的核心框架,其生态系统包含了HDFS、MapReduce、YARN、Hive、HBase、Spark等众多组件。
2.适用场景与核心优势
Hadoop适用于处理海量数据的存储和计算需求,具有以下核心优势:
- 高可靠性:通过数据冗余和自动故障恢复保证数据安全
- 高扩展性:可以轻松扩展到数百台服务器
- 高效性:分布式计算框架支持并行处理大量数据
- 低成本:可以运行在普通硬件上,降低IT基础设施成本
3.Hadoop 3.x 新特性解析
Hadoop 3.x相比之前的版本有以下重要改进:
- HDFS:支持Erasure Coding(纠删码),减少数据冗余开销
- YARN:引入了Resource Director和Federation等特性
- 性能提升:优化了内存管理和IO操作
4.hadoop介绍
Hadoop 分为三部分 : Common、HDFS 、Yarn、MapReduce(有点过时了)
Hadoop生态圈:除了hadoop技术以外,还有hive、zookeeper、flume、sqoop、datax、azkaban等一系列技术。
Hadoop 是 道格·卡丁 本身他是Lucene的创始人。
Lucene 其实是一个jar包。
检索现在主流的是Solr以及ES(Elastic Search)。
比如现在每一个网站,都有一个检索的输入框,底层技术: Solr (稍微有点过时了) , ES (正在流行中)
首先面临的问题是:海量数据如何存储?
根据谷歌推出的三篇论文:
BigTable -- HBase
GFS -- HDFS
MapReduce -- MapReduce
并将这些技术统称为 Hadoop (Logo 大象)。
Hadoop的三个版本:
Apache 版本(开源版本) 3.3.1 非常的新了
Cloudera 版本--商⽤版(道格·卡丁) CDH
Hortonworks --hadoop的代码贡献者在这家公司非常的多。
现在各个大公司都在推出自己的大数据平台--> 大数据平台开发工程师
DataLight --> 国产的CDH平台

二、搭建前准备
全分布模式:必须至少有三台以上的Linux
前期准备工作:
1、准备三台服务器
我们先准备一台,之后再克隆即可
1) 设置静态IP
第一步:vi /etc/sysconfig/network-scripts/ifcfg-ens33
第二步:输入i 进入编辑模式
第三步:修改内容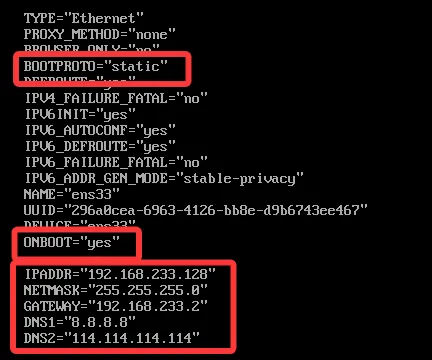
第四步:摁 esc 退出编辑模式
第五步:shift+ : 都是英文的 输入 wq! 强制保存并退出
第六步:systemctl restart network 重启网络2)安装jdk
1、创建一个文件夹,用于存放安装包 /opt/modules
mkdir -p /opt/modules --以后存放安装包
mkdir -p /opt/installs --以后存放解压后的软件 2、上传文件(安装包)
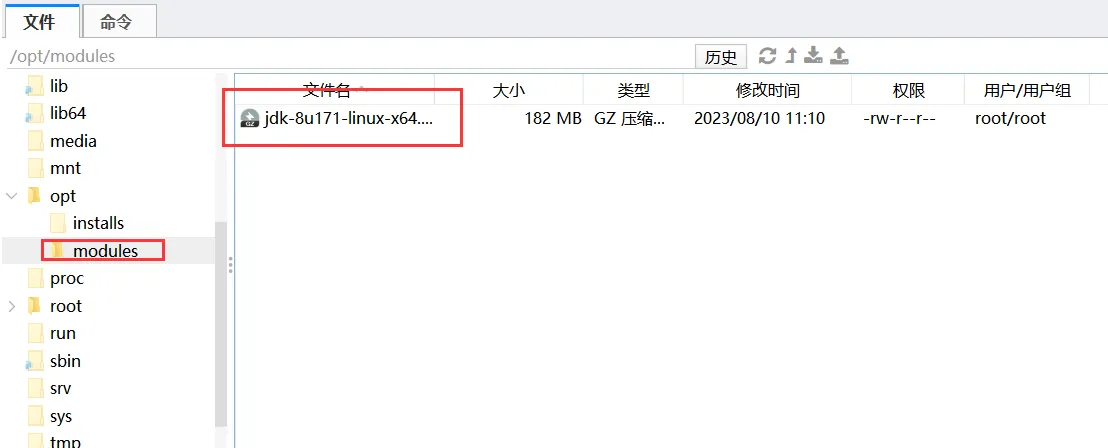
3、解压该软件
将软件解压到/opt/installs
tar -zxvf jdk-8u171-linux-x64.tar.gz -C /opt/installs/4、重命名
1、进入文件夹 cd /opt/installs
2、进行重命名 mv jdk1.8.0_171 jdk5、配置环境变量
vi /etc/profile
export JAVA_HOME=/opt/installs/jdk
export PATH=$PATH:$JAVA_HOME/bin
在文件的最后追加,不要删除别人的任何配置。6、刷新配置文件,让配置文件生效
source /etc/profile7、验证配置是否生效

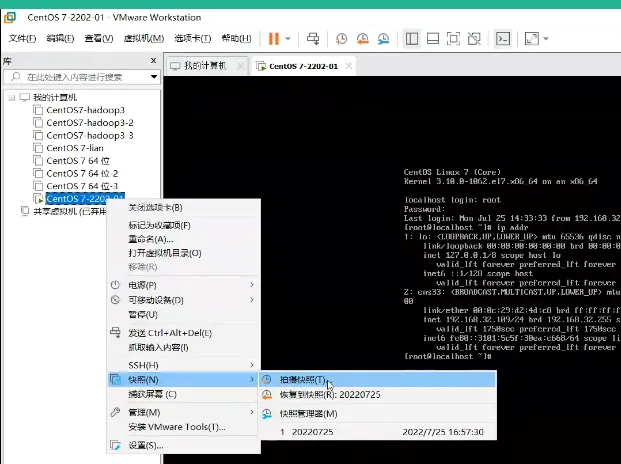
三、给系统拍个照(快照)
快照就是将来可以恢复,以及可以clone(克隆) 的基础,记得先关机, 再克隆。
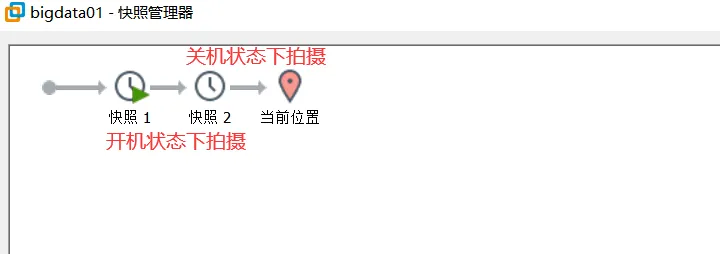
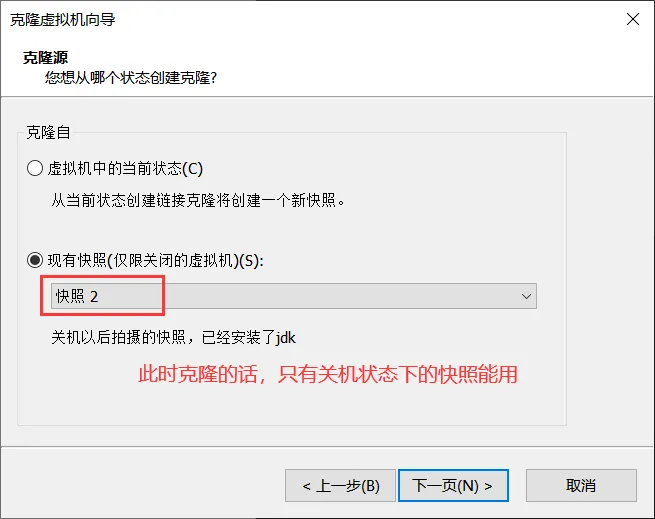
1、克隆完之后对两台电脑 进行静态ip设置
设置静态IP
第一步:vi /etc/sysconfig/network-scripts/ifcfg-ens33
第二步:输入i 进入编辑模式
第三步:修改内容
第四步:摁 esc 退出编辑模式
第五步:shift+ : 都是英文的 输入 wq! 强制保存并退出
第六步:systemctl restart network 重启网络ok现在三台虚拟机都已经设置好静态ip,而且已经安装好jdk接下来我们就要进入分布式搭建了。
四、完全分布式搭建之HDFS
1.安装前准备
1) 修改主机名
vi hostname
bigdata01#根据自己来设置主机名,我是bigdata01。三台都要设置我的分别为,bigdata01,bigdata02,bigdata03。
2)修改映射文件hosts
vi /etc/hosts
192.168.32.128 bigdata01
192.168.32.129 bigdata02
192.168.32.130 bigdata033)进行远程拷贝每台都要映射
scp -r /etc/hosts root@bigdata02:/etc/
scp -r /etc/hosts root@bigdata03:/etc/4)三台虚拟机间要进行免密登录
ssh-copy-id bigdata01
ssh-copy-id bigdata02
ssh-copy-id bigdata03
每台都需要5)第一台安装hadoop
1、上传
2、解压
tar -zxvf hadoop-3.3.1.tar.gz -C /opt/installs/
3、重命名
cd /opt/installs/
mv hadoop-3.3.1 hadoop
4、开始配置环境变量
vi /etc/profile
export HADOOP_HOME=/opt/installs/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5、刷新配置文件
source /etc/profile
6、验证hadoop命令是否可以识别
hadoop version安装完第一台不要着急拷贝因为我们还要修改配置文件。
6)关闭了防⽕墙
systemctl status firewalld
查看防火墙是否关闭
如果没有关闭执行
systemctl stop firewalld 关闭防火墙
systemctl disable firewalld 禁止开机自启7)修改linux的⼀个安全机制
vi /etc/selinux/config
注意修改⾥⾯的第二个SELINUX=disabled2.修改配置文件
修改bigdata01配置文件
路径:/opt/installs/hadoop/etc/hadoop
core-site.xml
<configuration>
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端⼝9000 hadoop2.x时代默认端⼝8020 hadoop3.x时 代默认端⼝ 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的⼀个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/installs/hadoop/tmp</value>
</property>
</configuration>hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondarynamenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata02:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata01:9870</value>
</property>
</configuration>hadoop-env.sh
export JAVA_HOME=/opt/installs/jdk
# Hadoop3中,需要添加如下配置,设置启动集群⻆⾊的⽤户是谁
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root修改workers
bigdata01
bigdata02
bigdata03删除 bigdata01 下的 hadoop 下的 logs 以及 tmp 文件
rm -rf /opt/installs/hadoop/logs /opt/installs/hadoop/tmp修改完了第一台的配置文件,开始分发到其他两台上去。
假如以前没有将bigdata01上的hadoop 拷贝给 02 和 03
那么就远程拷贝:
scp -r /opt/installs/hadoop/ root@bigdata02:/opt/installs/
scp -r /opt/installs/hadoop/ root@bigdata03:/opt/installs/
拷贝环境变量:
scp -r /etc/profile root@bigdata02:/etc/
scp -r /etc/profile root@bigdata03:/etc/
在02 和 03 上刷新环境变量 source /etc/profile格式化namenode 【bigdata01】
hdfs namenode -format启动hdfs
只在第一台电脑上启动
start-dfs.sh启动后jps,看到
| bigdata01 | bigdata02 | bigdata03 |
| namenode | secondaryNameNode | x |
| datanode | datanode | datanode |
web访问:namenode 在哪一台,就访问哪一台。http://bigdata01:9870
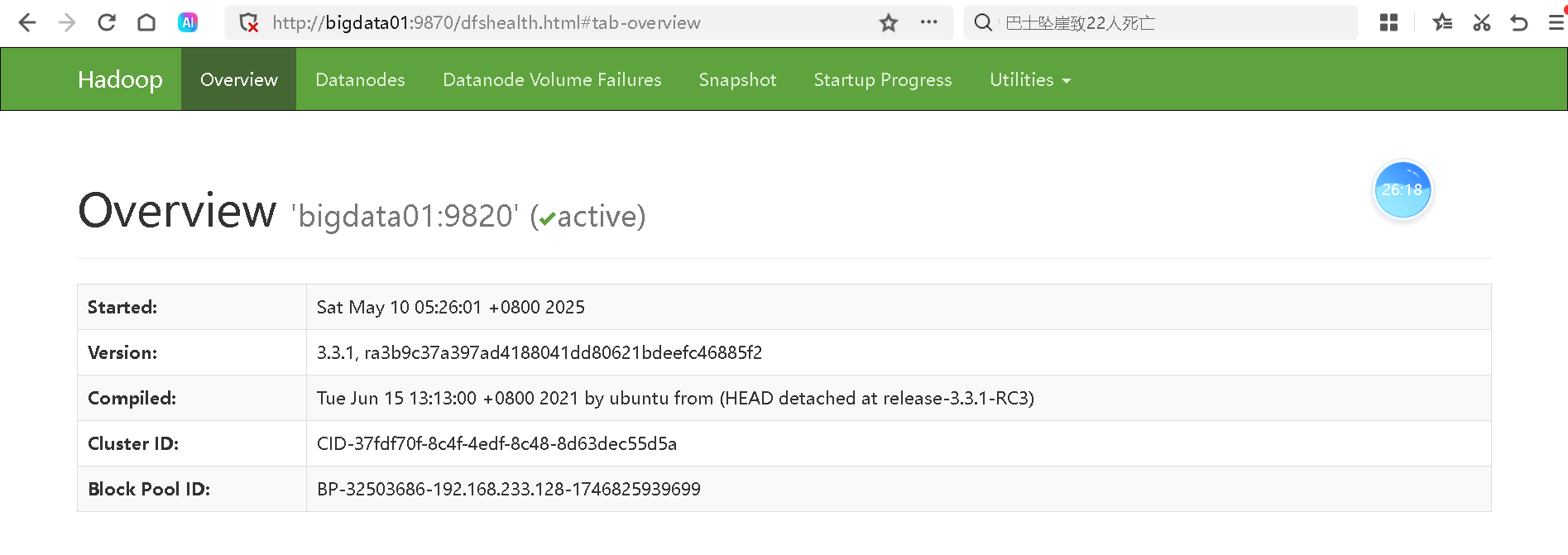
总结:
1、start-dfs.sh 在第一台启动,不意味着只使用了第一台,而是启动了集群。
stop-dfs.sh 其实是关闭了集群
2、一台服务器关闭后再启动,上面的服务是需要重新启动的。
这个时候可以先停止集群,再启动即可。也可以使用单独的命令,启动某一个服务。
hadoop-daemon.sh start namenode # 只开启NameNode
hadoop-daemon.sh start secondarynamenode # 只开启SecondaryNameNode
hadoop-daemon.sh start datanode # 只开启DataNode
hadoop-daemon.sh stop namenode # 只关闭NameNode
hadoop-daemon.sh stop secondarynamenode # 只关闭SecondaryNameNode
hadoop-daemon.sh stop datanode # 只关闭DataNode3、namenode 格式化有啥用
相当于在整个集群中,进行了初始化,初始化其实就是创建文件夹。创建了什么文件夹:
logs tmp
你的hadoop安装目录下。cd /opt/installs/hadoop
ls
你会发现创建了logs tmp文件



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









