








网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
从摘要报告中,您可以看到有关测试的统计信息 – 它有意义吗?寻找平均响应时间,错误,命中率/秒。
一旦你的脚本准备好了,通过删除任何Debug / Dummy Samplers并删除脚本侦听器来清理它。
如果您使用监听器(例如“保存对文件的响应”),请确保您不使用任何路径!如果是监听器或CSV数据集配置,请确保不使用本地使用的路径。而是仅使用文件名,就好像它与脚本位于同一文件夹中一样。
如果您使用自己专有的JAR文件,请务必上传它。
如果您使用多个线程组(或不是默认线程组),请确保在将值上载到BlazeMeter之前设置这些值。
第3步:BlazeMeter SandBox测试
如果这是你的第一个测试,你应该检讨这个文章,了解如何在BlazeMeter创建测试。
SandBox它实际上是任何具有多达300个用户的测试,并且使用一个控制台最多只需50分钟。
SandBox的配置允许您测试脚本和后端,以确保BlazeMeter的一切正常。
要做到这一点,首先,按下灰色按钮:JMeter引擎我想要完全控制!完全控制您的测试参数。
您可能遇到的常见问题包括:
防火墙 – 确保您的环境对BlazeMeter CIDR列表(正在不更新)开放并将它们列入白名单
确保存在所有测试文件,例如CSV,JAR,JSON,User.properties等
确保您没有使用任何路径
如果仍然遇到问题,请查看日志中的错误(您应该可以下载整个日志)。
SandBox配置可以是:
引擎:仅限控制台(一个控制台,0个引擎)
主题:50-300
加速:20分钟
迭代:测试永远持续下去
持续时间:30-50分钟
这将允许您在加速期间获得足够的数据(如果您在那里遇到一些问题),您将能够分析结果以确保脚本按预期执行。
您应该查看Waterfall / WebDriver选项卡以查看请求是否正常。此时你不应该得到任何错误(除非你的意图)。
您应该观察监控选项卡以查看使用了多少内存和CPU – 这将帮助您完成步骤4,同时您将尝试设置每个引擎的用户数。
第4步:设置每个引擎的用户数量
既然我们确信剧本在BlazeMeter中完美运行,我们需要弄清楚我们可以将多少用户应用于一个引擎。
如果您可以使用SandBox数据来确定,那太好了!
在这里,我将为您提供一种方法来解决这个问题,而无需回顾SandBox测试数据。
将测试配置设置为:
线程数:500
加速40分钟
迭代:永远
持续时间:50分钟
接下来,使用一个控制台和一个引擎。
运行测试并通过Monitoring选项卡监控测试引擎。
如果您的引擎没有达到75%的CPU利用率或85%的内存使用率(可以忽略一次峰值):将线程数更改为700并再次运行测试。提高线程数,直到获得1000个线程或60%的CPU /内存使用量。
如果您的引擎超过了75%的CPU利用率或85%的内存使用率(可以忽略一次峰值):查看您第一次达到75%的时间点,然后查看您当时有多少用户。再次运行测试; 而不是500的增加,把你从上一次测试中获得的用户数量。
这一次,在实际测试中加入你想要的加速(5-15分钟是一个很好的开始)并将持续时间设置为50分钟。
确保在整个测试过程中不要超过75%的CPU或85%的内存使用率。
为了安全起见,您可以更安全地减少每个引擎10%的线程数。
第5步:设置并测试您的群集
我们现在知道一个引擎可以获得多少线程。在这一步结束时,我们将知道一个集群(测试)可以获得的用户数量。
群集是一个逻辑容器,只有一个控制台和0-14个引擎。即使您可以使用超过14个引擎创建测试,它实际上会创建两个集群(您可以看到将增加的控制台数量)并克隆您的测试。
每个控制台最多14个引擎基于BlazeMeter自己的测试,以确保控制台可以处理14个引擎的压力,这会产生大量数据需要处理。
因此,在此步骤中,我们将从步骤4开始测试并仅更改发动机的数量并将其提升至14。对最终测试(1,2,3等)小时的全长进行测试。测试运行时,请转到监控选项卡并验证:没有一个引擎通过75%的CPU或85%的内存限制。
找到您的控制台标签。如果您将转到“日志”选项卡 – >“网络信息”并查找控制台的专用IP,则可以找到其名称。它不应达到75%的CPU或85%的内存限制。
如果您的控制台达到了该限制,请减少引擎数并再次运行,直到控制台处于这些限制范围内。
在此步骤结束时,您知道:
您将拥有的每个群集的用户
您将达到的每个群集的点击次数
在负载结果图下的聚合表中查找其他统计信息,以获取有关群集吞吐量的更多信息。
第6步:使用主/从功能达到最大CC目标
我们已经到了最后阶段。
我们知道脚本正在运行,我们知道一个引擎可以维持多少用户,并且我们知道我们可以从一个群集获得多少用户。
我们假设我们有这些值:
一个引擎可以拥有500个用户
该集群将有12个引擎
我们的目标是进行50k测试
因此,要做到这一点,我们需要创建50,000 (500 * 12)= 8.3个集群。
我们可以使用8个集群的12个引擎(48K)和一个集群,其中有4个引擎(另外2个)。但是,最好像这样分散负载:
我们将使用10代替每个集群12个引擎,因此我们将从每个集群获得10 * 500 = 5K,并且需要10个集群才能达到50k。
这将有助于我们:
不保持两种不同的测试类型
过简单地复制现有的集群,我们可以增长5k(5k比6k更常见)
如果需要,我们可以随时添加更多。
我们现在准备用50k用户创建我们的最终主/从测试:将测试名称从“我的产品测试”更改为“我的产品测试 – 从属1”。
因此,我们回到第5步中的测试,在高级测试属性下,我们将其从Standalone更改为Slave。
按保存,我们现在有九个奴隶和一个主人中的第一个。
回到你的“我的产品测试-slave 1.”
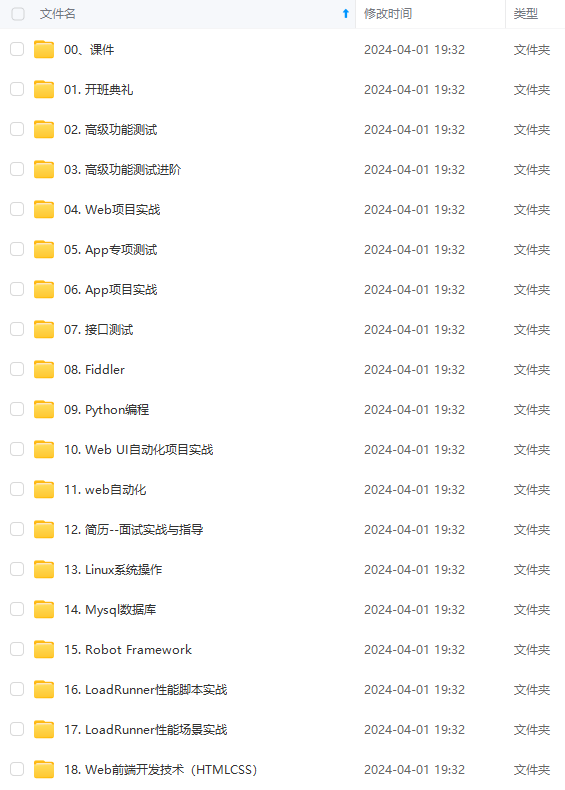
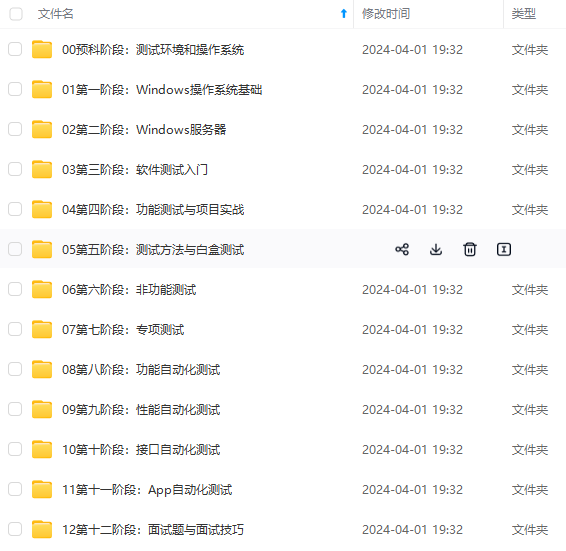
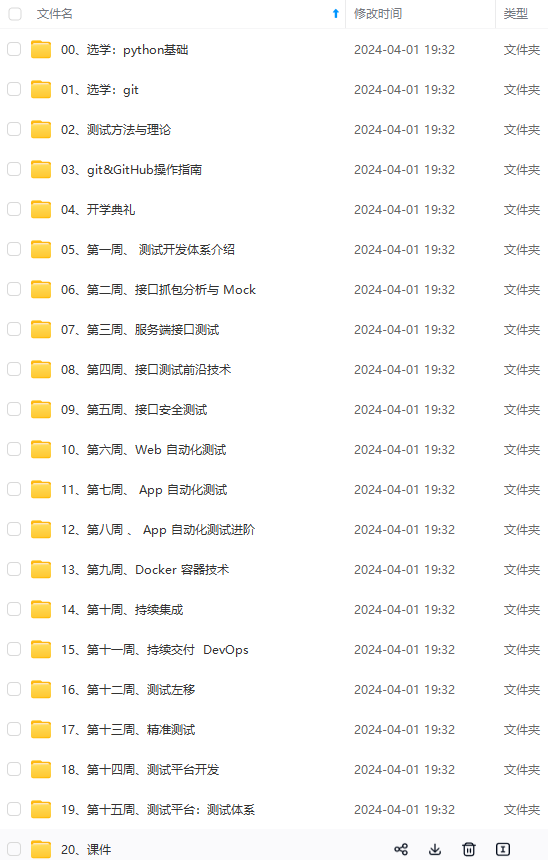
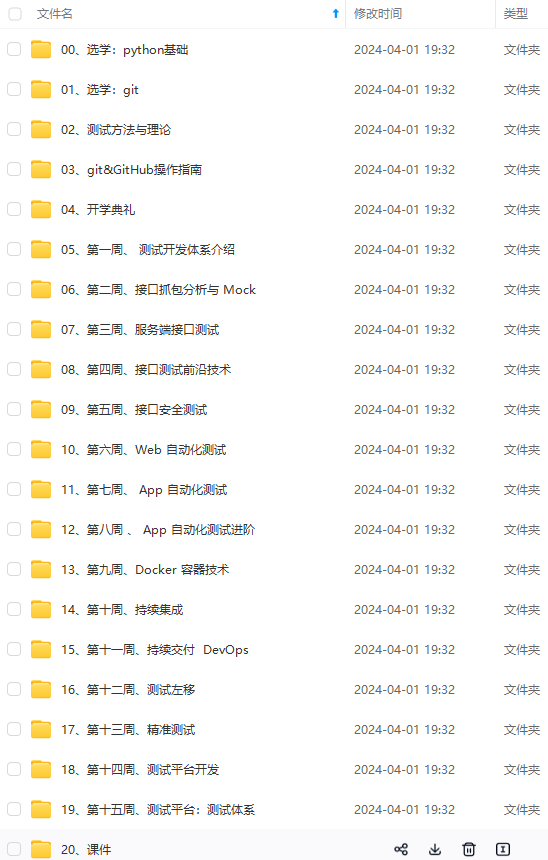
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
.(img-XGAw4ewX-1715572781285)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









