






基础知识
主要使用了AdaBoost算法,随机森林,网格搜索验证。
AdaBoost:
(使用时导入sklearn的子模块ensemble,调用AdaBoostClassifier或者AdaBoostRegressor)
基础语法如下:
AdaBoostClassifier(base_estimator=None, n_estimator=200, learning_rate=0.05, algorithm='SAMME.R', random_state=None)
AdaBoostRegressor(base_estimator=None, n_estimator=200, learning_rate=0.05, loss='linear', random_state=None)
其中bsae_estimator是基础分类器,默认是分类决策树(CART);
n_estimator是估计器个数;
learning_rate是步长;
algorithm指定分类器算法,一般使用SAMME.R;
random_state是随机数种子;
loss是损失函数,一般选‘linear’(线性), 'square'(平方), 'exponential'(指数).
随机森林:
(使用时导入sklearn的子模块ensemble,调用RandomForestClassifier或者RandomForestRegressor)
基础语法:
RandomForestClassifier(n_estimator=100, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False, class_weight=None)
RandomForestRegressor(n_estimator=100, criterion='mse', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False)
n_estimator:决策树个数.
criterion:分割字段的使用的度量标准.
max_depth:每颗决策树的最大深度,默认不限制.
min_samples_split:继续分割的最小样本量,默认2.
min_samples_leaf:叶节点的最小样本量,默认1.
min_weight_fraction_leaf:叶节点的最小样本权重,默认不考虑.
max_features:每颗决策树包含的最多分割字段,默认全部.
max_leaf_nodes:最大叶节点个数,默认不限制.
min_impurity_decrease:是否继续分割的最小不纯度值.
bootstrap:是否对原数据bootstrap抽样,默认True,默认0.
oob_score:是否使用bootstrap抽样没有抽中的样本计算泛化误差,默认False.
n_jobs:CPU个数,默认1.
random_state:随机数种子,默认None.
verbose:是否输出日志,默认不输出.
warm_start:是否基于上一次训练结果,默认False.
class_weight:指定因变量之间权重,默认None.
应用实战
我们以信用卡违规数据为例,数据来自UCI网站--Default of Credit Card Clients,链接:Default of Credit Card Clients - UCI Machine Learning Repository
其中共3k条数据,23个变量,下载后第一行为为衍生变量名,第二行为原始变量名。第一列为ID,最后一列是default payment next month(本文中为了方便手动改为了y.) ,值只有0和1,其中0表示没违约,1表示违约。
(虽然数据集中的数据总是干净完整的,但也需要提前看一下,避免存在某行数据类型不同导致错误)
下面是常规六步走:读入数据,拆分数据,构建模型,模型拟合,模型预测,输出结果。(数据不干净,不完整的情况下先进行数据清洗)
###导入第三方包###
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import model_selection
from sklearn import ensemble
from sklearn import metrics第一步:读入数据
ps:skiprow=1表示跳过第一行读入,默认读入后第一行作为表头,否则使用header=none.
###读取数据###
credit1 = pd.read_excel(r'D:\lenovo\Desktop\default of credit card clients.xls',skiprows=1)
count=credit1.y.value_counts()
print(count)
out:
0 23364
1 6636第二步:数据拆分,使用sklearn中的model_selection下的train_test_split.
###定义x和y###
X=credit1.iloc[:,1:-1]#(iloc指index location)行全部包括,列从第二列到倒数第二列
y=credit1.y
###数据拆分###
X_train,X_test,y_train,y_test=model_selection.train_test_split(X,y,test_size=0.25,random_state=1234)第三步:构建模型,先使用的是AdaBoost算法,在sklearn的子模块ensemble中的AdaBoostClassifier或AdaBoostRegressor.
ps:接下来的代码都比较少,就放一起啦。
###模型拟合###
AdaBoost1.fit(X_train,y_train)
###测试集预测###
pred=AdaBoost1.predict(X_test)
###输出预测结果###
print('模型的准确率为:\n',metrics.accuracy_score(y_test,pred))
print('模型的评估报告为:\n',metrics.classification_report(y_test,pred))
out:
模型的准确率为:
0.8125333333333333
模型的评估报告为:
precision recall f1-score support
0 0.83 0.96 0.89 5800
1 0.68 0.32 0.44 1700
accuracy 0.81 7500
macro avg 0.75 0.64 0.66 7500
weighted avg 0.80 0.81 0.79 7500计算ROC曲线中的AUC值,判断拟合效果。
###画ROC曲线和计算AUC###
y_score=AdaBoost1.predict_proba(X_test)[:,1]
fpr,tpr,threshold=metrics.roc_curve(y_test,y_score)
roc_auc=metrics.auc(fpr,tpr)
# print('%.2f'%roc_auc) 不画ROC曲线也可以
plt.stackplot(fpr,tpr,color='steelblue',alpha=0.5)
plt.text(0.5,0.3,'ROC curve(area=%.2f)'%roc_auc)
plt.show() 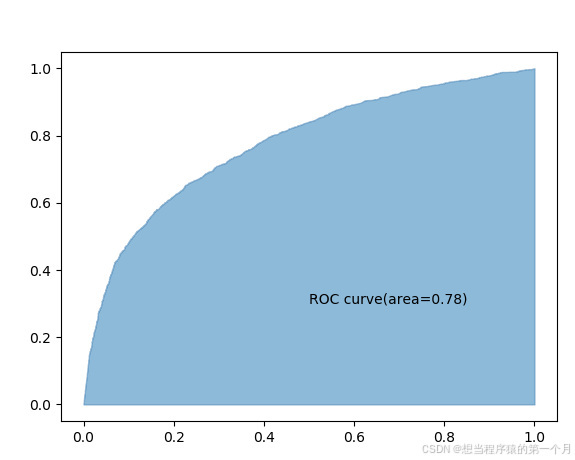
这里可以看出来虽然AUC大于0.5,但实际拟合效果并不好,下面使用交叉验证法寻找最优参数。AdaBoost的基础分类器默认是CART(分类决策树),因此可以通过预剪枝改善分类器效果,例如控制树的最大深度,中间节点和叶结点的最小样本量。此外,AdaBoost本身对于每一个分类器有权重,可以调整权重改善拟合效果。
先对CART调参,使用GridSearchCV:
######预测效果不好,下面进行调参######
###先做特征筛选###
importance=pd.Series(AdaBoost1.feature_importances_,index=X.columns)
importance.sort_values().plot(kind='barh')
plt.show()
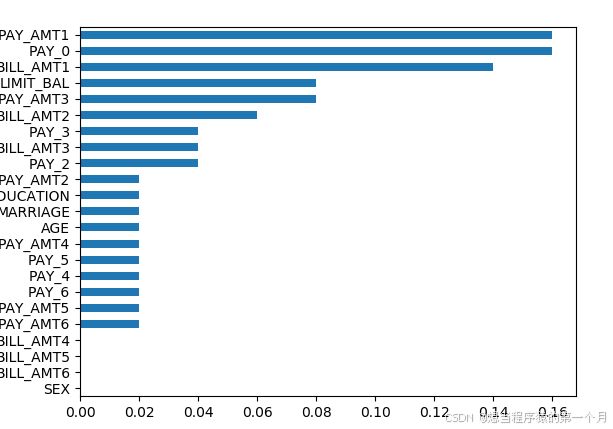
可以看出有些变量对结果基本没有影响,我们筛选出影响较大的变量,重新作为拟合的数据。
credit2=list(importance[importance>0.02].index)
###选择决策树的深度###
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
max_depth=[2,3,4,5,6,7]
params1={'base_estimator__max_depth':max_depth}
base_model=GridSearchCV(estimator=ensemble.AdaBoostClassifier(base_estimator=DecisionTreeClassifier()),param_grid=params1,scoring='roc_auc',cv=5,n_jobs=4,verbose=1)
base_model.fit(X_train[credit2],y_train)
pred2=base_model.predict(X_test[credit2])
print(base_model.best_params_)#得到最佳的决策树深度是2
print(base_model.best_score_)#得到最大AUC是0.76
out:
{'base_estimator__max_depth': 2}
0.7603441783466154再对Adaboost算法调参
###对AdaBoost算法调参###
params2={'n_estimators':[100,200,300,400],'learning_rate':[0.01,0.05,0.1,0.2]}
base_model2=GridSearchCV(estimator=ensemble.AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=2)),param_grid=params2,scoring='roc_auc',cv=5,n_jobs=4,verbose=1)
base_model2.fit(X_train[credit2],y_train)
pred3=base_model2.predict(X_test[credit2])
print(base_model2.best_params_)#得到最佳的估计器个数是200,最佳步长是0.05
print(base_model2.best_score_)#最大的AUC是0.77
out:
{'learning_rate': 0.05, 'n_estimators': 200}
0.7703272055262776基于上面的参数,再次构建函数并进行模型拟合和预测
###在最佳参数下再次构建AdaBoost模型###
AdaBoost2=ensemble.AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=2),n_estimators=200,learning_rate=0.05)
AdaBoost2.fit(X_train[credit2],y_train)
pred4=AdaBoost2.predict(X_test[credit2])
print('模型的准确率为:',metrics.accuracy_score(y_test,pred4))
out:
模型的准确率为: 0.8156可以看出模型的准确率从81.25%提升到81.56%,虽然提升了,但并不多。说明使用AdaBoost算法处理这个数据集可能不太合适,下面尝试使用随机深林。又是收悉的六步法,前三步前面写过了,我们下面只写后三步。
###构建随机深林###
RF=ensemble.RandomForestClassifier(n_estimators=200,random_state=1234)
###模型拟合###
RF.fit(X_train,y_train)
###模型预测###
RF_pred=RF.predict(X_test)
print('模型的准确率:',metrics.accuracy_score(y_test,RF_pred))
print('模型的评估报告:',metrics.classification_report(y_test,RF_pred))
out:
模型的准确率: 0.8108
模型的评估报告: precision recall f1-score support
0 0.84 0.94 0.88 5800
1 0.64 0.37 0.47 1700
accuracy 0.81 7500
macro avg 0.74 0.66 0.68 7500
weighted avg 0.79 0.81 0.79 7500随机森林的准确率只有81.08%,相比之下,还是AdaBoost算法更好。多尝试使用其他不同的算法,也许能找到更优算法,作者后面如果找到了,再来这里补充。
哈哈,今天又尝试了GBDT算法。
下面尝试使用GBDT算法(用到了上面代码中的变量)
###使用GBDT算法###
#先利用网格搜索方法寻找最佳参数
learning_rate=[0.01,0.05,0.1,0.2]
n_estimator=[100,200,300,400]
max_depth=[3,4,5,6]
params3={'learning_rate':learning_rate,'n_estimators':n_estimator,'max_depth':max_depth}
base_model3=GridSearchCV(estimator=ensemble.GradientBoostingClassifier(),param_grid=params3,scoring='roc_auc',n_jobs=4, cv=5,verbose=1)
base_model3.fit(X_train[credit2],y_train)
print(base_model3.best_params_)
print(base_model3.best_score_)
out:
{'n_estimators': 100, 'learning_rate': 0.1, 'max_depth': 4}
0.7743071314340877这里搜索量较大,为了方便后面代码的执行(减小计算量),基于最佳参数再次构建模型。
#基于最佳参数构建GBDT模型并进行预测
GBDT=ensemble.GradientBoostingClassifier(loss='exponential', learning_rate=0.1, n_estimators=100, max_depth=4)
GBDT.fit(X_train[credit2],y_train)
pred5=GBDT.predict(X_test[credit2])
print('模型准确率为:',metrics.accuracy_score(y_test,pred5))
print('模型评估报告为:',metrics.classification_report(y_test,pred5))
y_score3=GBDT.predict_proba(X_test[credit2])[:,1]
auc=metrics.roc_auc_score(y_test,y_score3)
print('AUC为:','%.2f'%auc)
out:
模型准确率为: 0.8138666666666666
模型评估报告为: precision recall f1-score support
0 0.83 0.95 0.89 5800
1 0.67 0.35 0.46 1700
accuracy 0.81 7500
macro avg 0.75 0.65 0.67 7500
weighted avg 0.80 0.81 0.79 7500
AUC为: 0.78可以看出,准确率为81.38%,依旧不是很高呀。

















 965
965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









